
golangd\pycharm-ai免费代码助手安装使用gpt4-免费使用--[推荐]
golangd-ai免费代码助手安装使用目前GPT4以及gpt的大规模使用,如何快速掌握以及在ide中快速使用的办法,今天安装一款golangd编辑器的插件已经使用。
补充的ai助手代码:
新的代码助手,效果比较明显;
免费好用的AI编程助手 Fitten Code - 支持VS Code、PyCharm、Intellj、Visual Studio (fittentech.com)
https://code.fittentech.com/ 
安装后就是可以代码查询了,其余的在代码中查询使用,中文效果比较好
golangd-ai免费代码助手安装使用,pycharm可以使用,估计只要是xx的ide都是可以使用这个插件
目前GPT4以及gpt的大规模使用,如何快速掌握以及在ide中快速使用的办法,今天安装一款golangd编辑器的插件已经使用
1.Bito 在pycharm,golangd中都是可以使用
2.CodeGeex支持goalngd,pycharm,vscode等、中文支持比较好
最主要上述插件都是免费,简单注册就是可以使用,也不涉及“合理上网”事项,国内完全可以使用
3.新的代码工具地址,中文检索,支持比较多
https://www.claudeai.ai/zh-CN一、安装以及使用
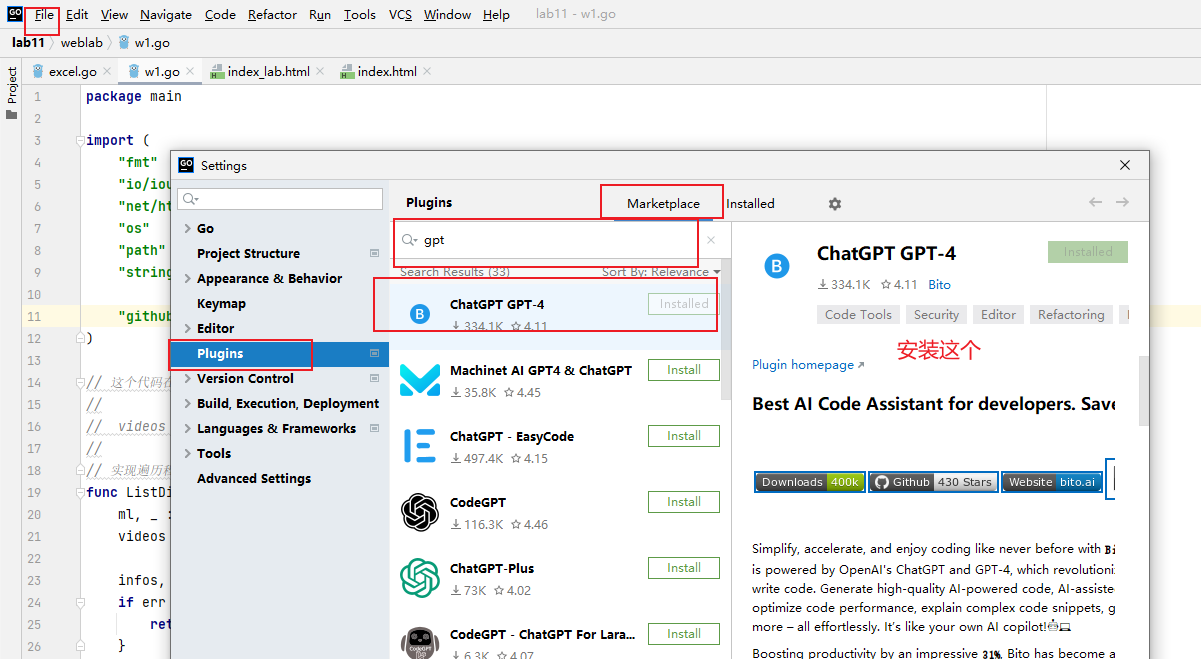
1.在golangd中安装插件的办法
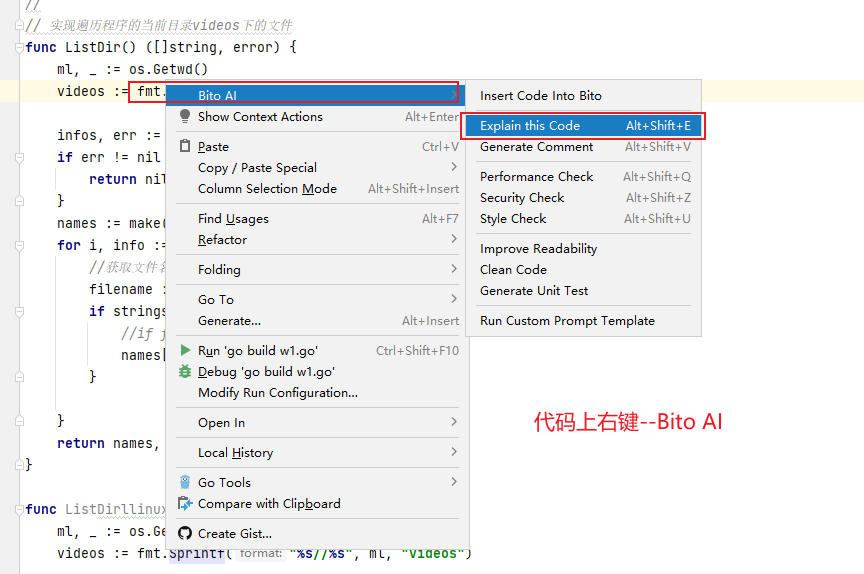
2.AI助手使用步骤:

3.用邮箱注册--免费,填写邮箱后,让你到你的邮箱中,有个验证码,把验证码填入页面即可注册成功。
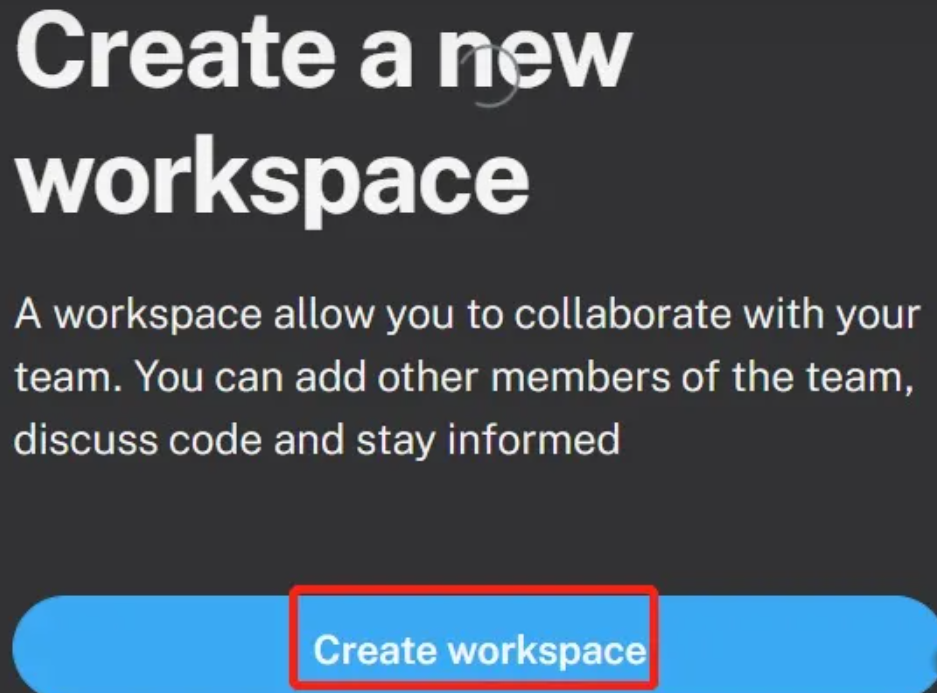
4.创建工作区间
5.跳过不必要的步骤:
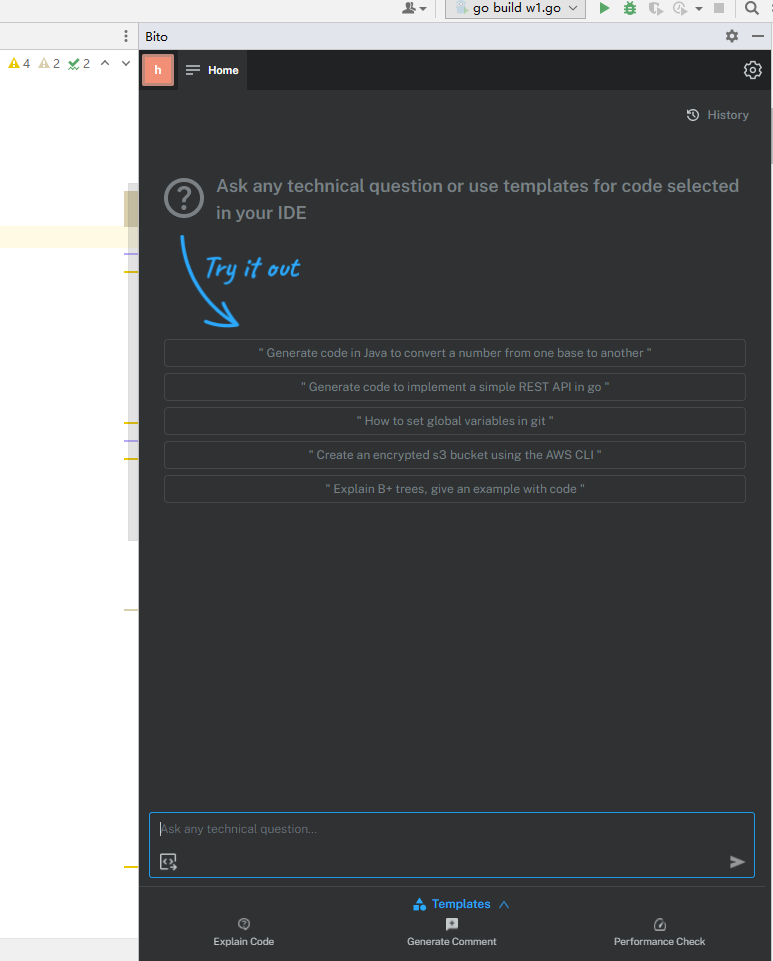
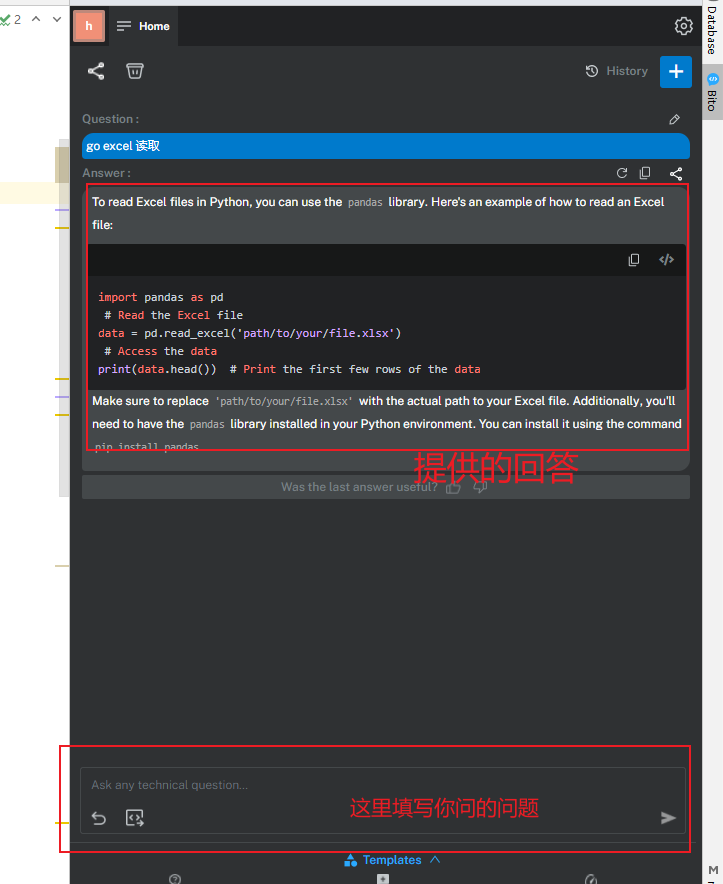
6.经常使用的方式
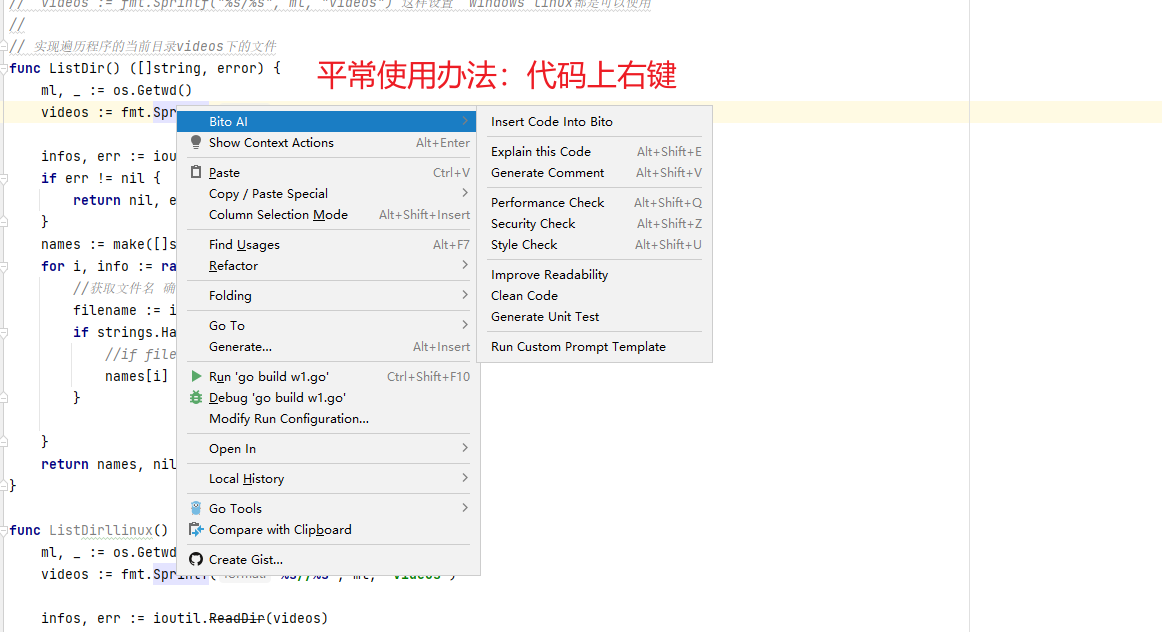
insert code into bito 将代码插入位元
explain this code 解释这段代码
generate comment 产生评论
二、常用功能
1.代码问题咨询,可以在这里咨询代码问题,让BITO给你写代码==常用的功能
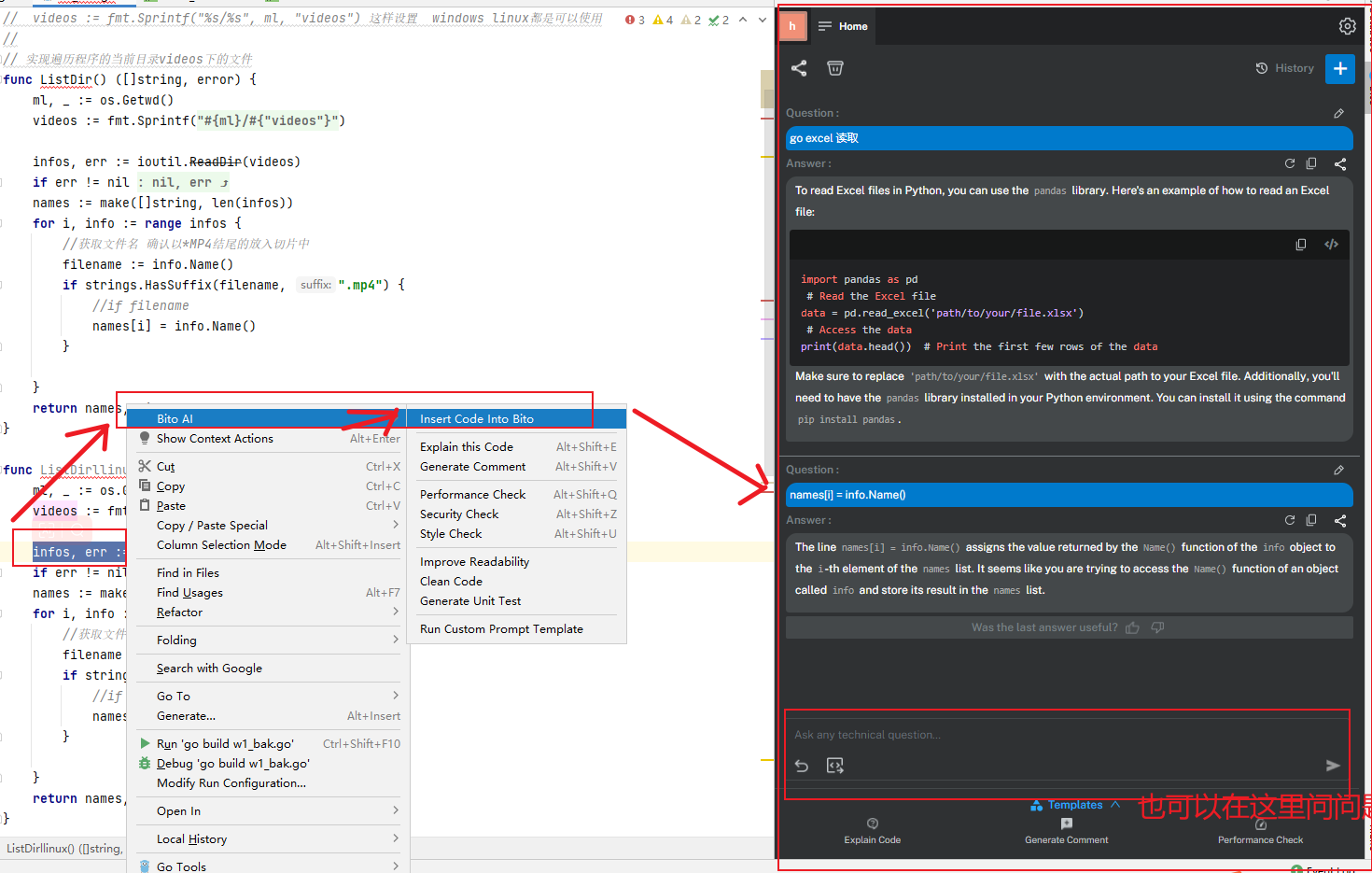
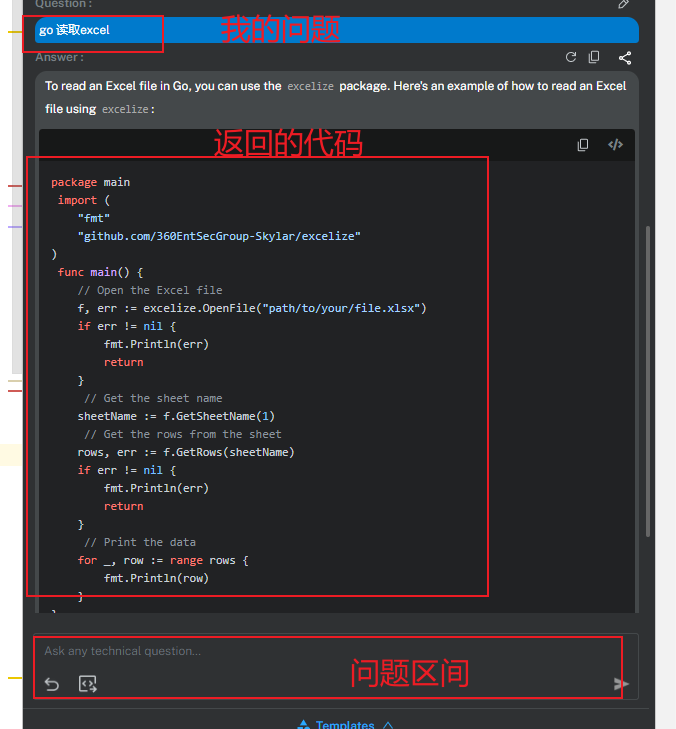
2.解释代码意思
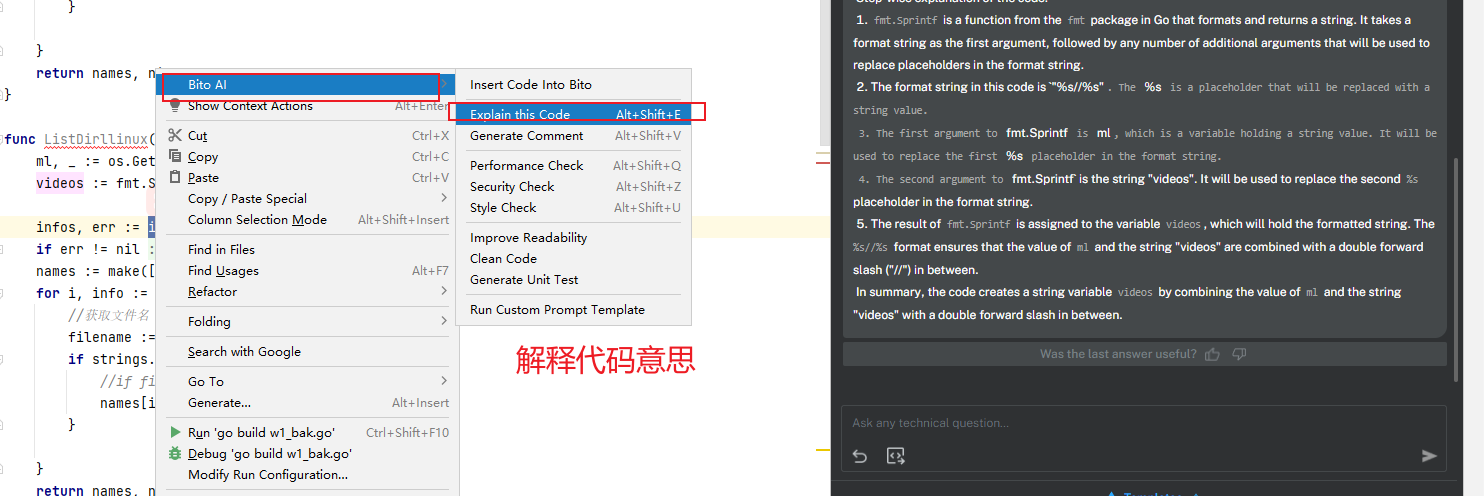
3.下面的功能都是功能性能检测,后续有时间在进行研究,重点是研究好上面的两个功能。
三、CodeGeeX - 免费的AI编程助手 - CodeGeeX
https://codegeex.cn/zh-CN最主要是免费,免费,免费
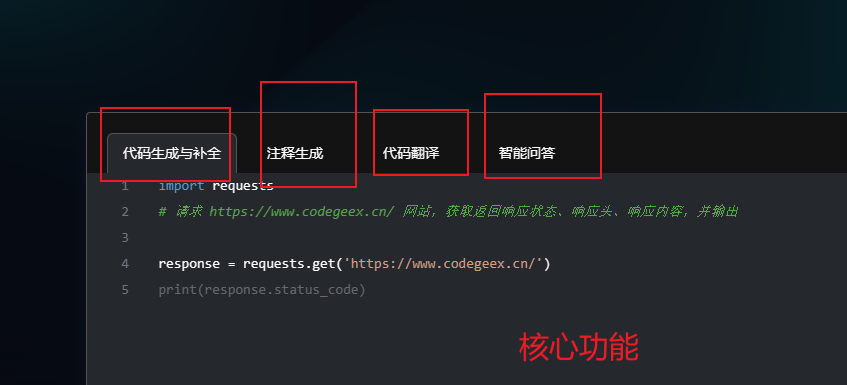
特色功能;
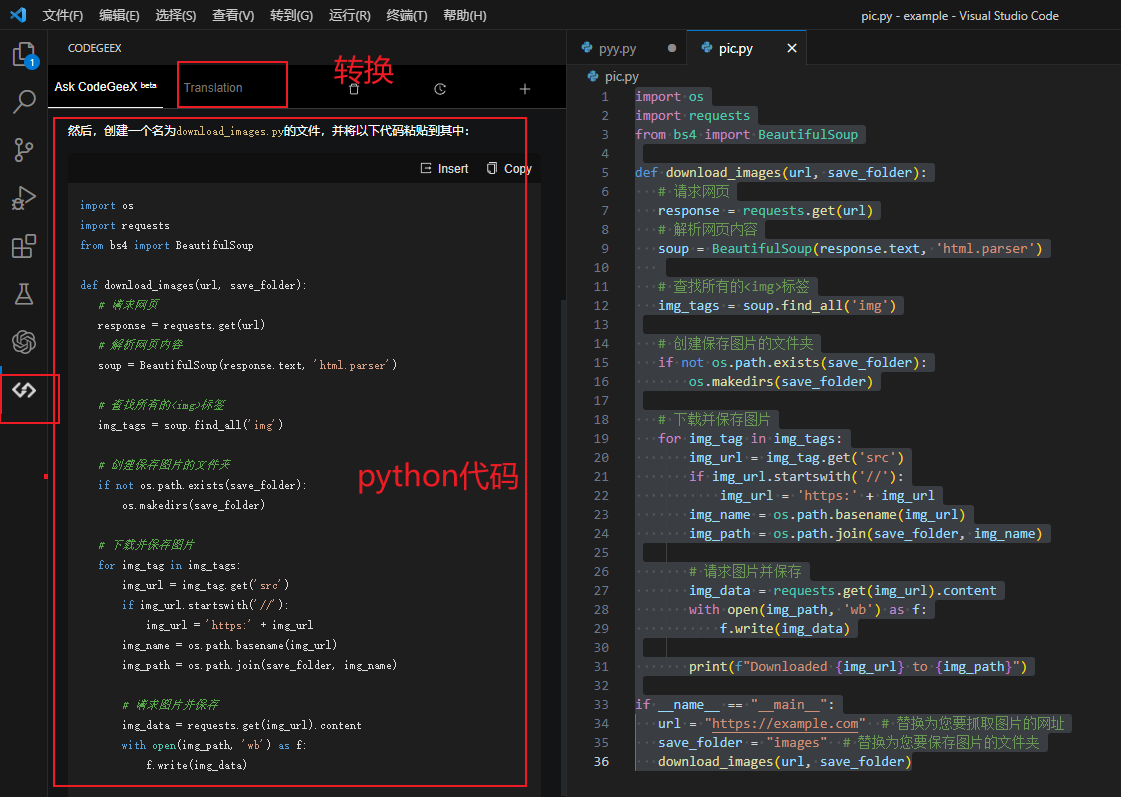
代码转换,我平时喜欢python代码,但是python编译成包文件不行,如果能转换成golang代码是不是很好呢,他就是有这个功能
我的python代码如下
import os
import requests
from bs4 import BeautifulSoup
def download_images(url, save_folder):
# 请求网页
response = requests.get(url)
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有的<img>标签
img_tags = soup.find_all('img')
# 创建保存图片的文件夹
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 下载并保存图片
for img_tag in img_tags:
img_url = img_tag.get('src')
if img_url.startswith('//'):
img_url = 'https:' + img_url
img_name = os.path.basename(img_url)
img_path = os.path.join(save_folder, img_name)
# 请求图片并保存
img_data = requests.get(img_url).content
with open(img_path, 'wb') as f:
f.write(img_data)
print(f"Downloaded {img_url} to {img_path}")
if __name__ == "__main__":
url = "https://example.com" # 替换为您要抓取图片的网址
save_folder = "images" # 替换为您要保存图片的文件夹
download_images(url, save_folder)vscode上转换的步骤
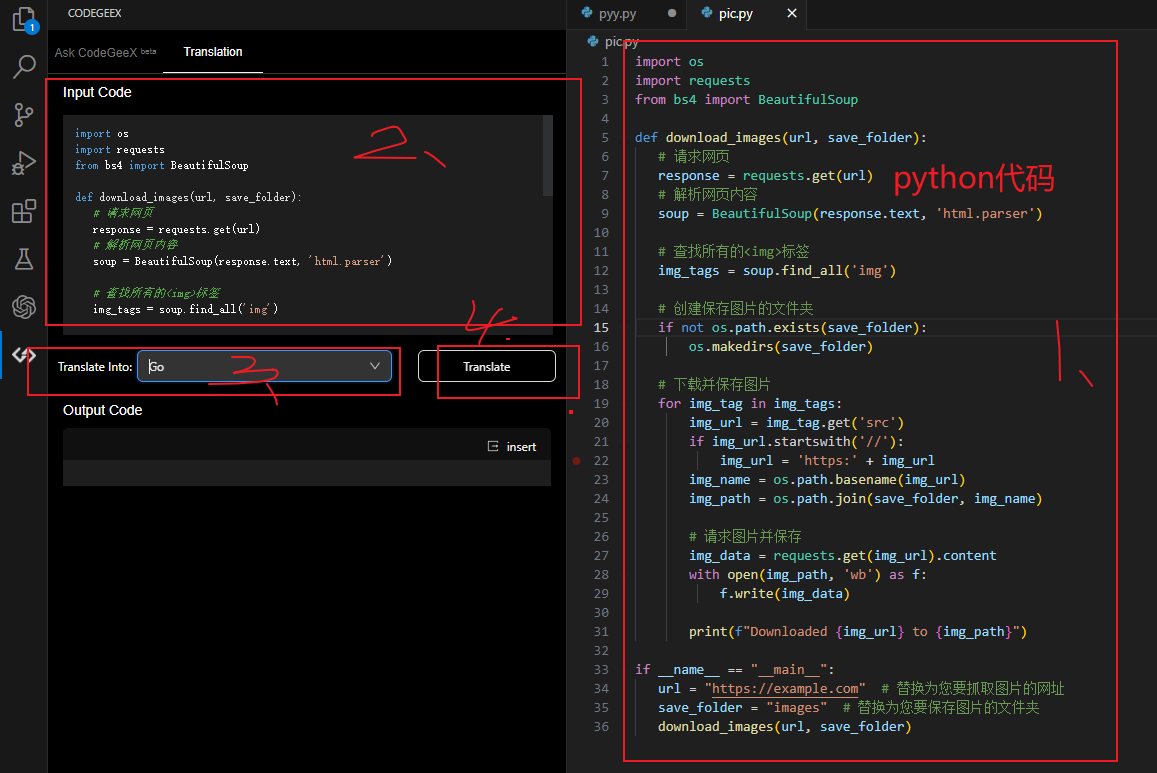
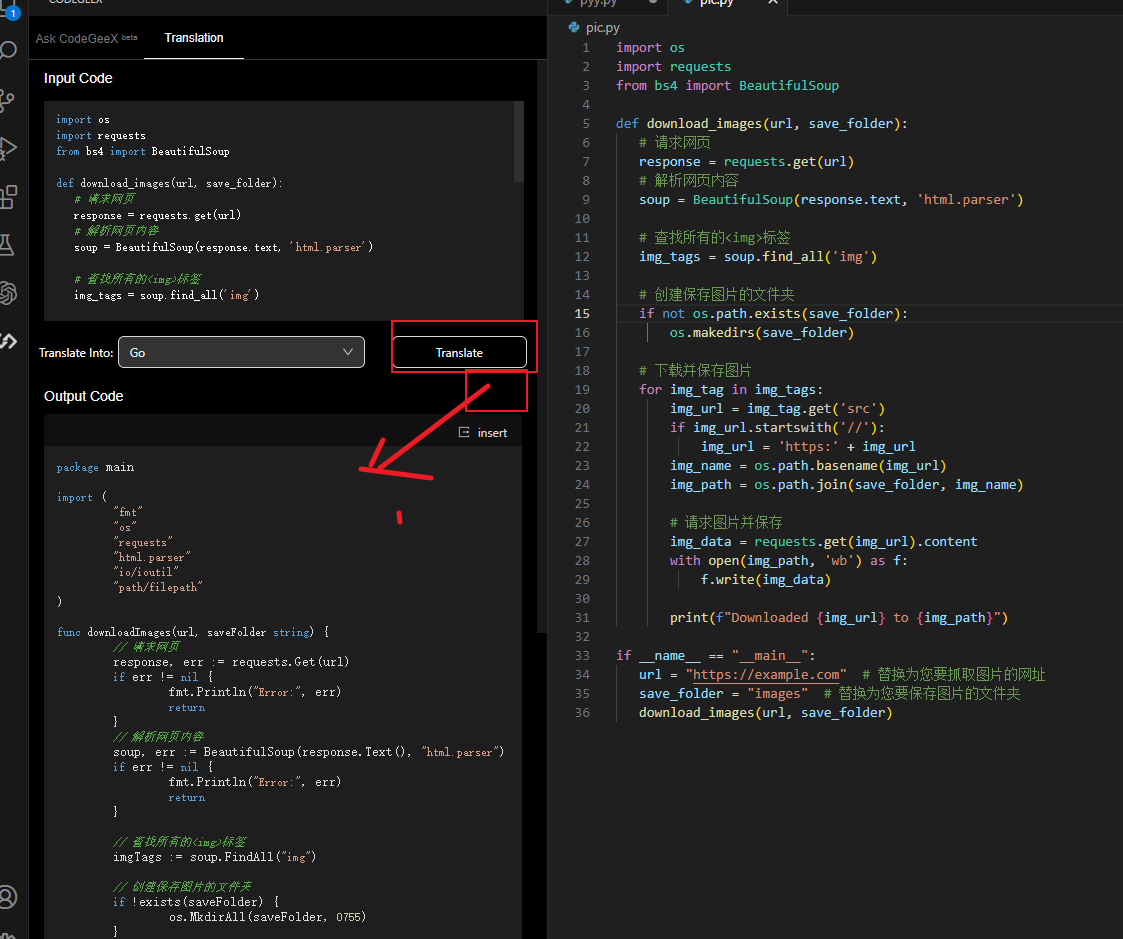
生成的golang代码
package main
import (
"fmt"
"io/ioutil"
"os"
"path/filepath"
"requests"
"html.parser"
)
func downloadImages(url, saveFolder string) {
// 请求网页
response, err := requests.Get(url)
if err != nil {
fmt.Println("Error:", err)
return
}
// 解析网页内容
soup, err := BeautifulSoup(response.Text(), "html.parser")
if err != nil {
fmt.Println("Error:", err)
return
}
// 查找所有的<img>标签
imgTags := soup.FindAll("img")
// 创建保存图片的文件夹
if !exists(saveFolder) {
os.MkdirAll(saveFolder, 0755)
}
// 下载并保存图片
for _, imgTag := range imgTags {
imgUrl := imgTag.Get("src")
if imgUrl[:1] == "//" {
imgUrl = "https:" + imgUrl
}
imgName := filepath.Base(imgUrl)
imgPath := filepath.Join(saveFolder, imgName)
// 请求图片并保存
imgData, err := requests.Get(imgUrl).Content()
if err != nil {
fmt.Println("Error:", err)
continue
}
err = ioutil.WriteFile(imgPath, imgData, 0644)
if err != nil {
fmt.Println("Error:", err)
continue
}
fmt.Printf("Downloaded %s to %s\n", imgUrl, imgPath)
}
}
func exists(path string) bool {
_, err := os.Stat(path)
return !os.IsNotExist(err)
}
func BeautifulSoup(content string, parser string) (*BeautifulSoup, error) {
var parserFunc BeautifulSoupParser
switch parser {
case "html.parser":
parserFunc = html.Parser(content)
default:
return nil, fmt.Errorf("unsupported parser: %s", parser)
}
return &BeautifulSoup{parserFunc}, nil
}
type BeautifulSoupParser interface {
Parse(string) *html.Node
}
type BeautifulSoup struct {
parserFunc BeautifulSoupParser
}
func (b *BeautifulSoup) FindAll(tag string) []*html.Node {
return b.parserFunc.FindAll(tag, nil)
}
func main() {
url := "https://example.com" // 替换为您要抓取图片的网址
saveFolder := "images" // 替换为您要保存图片的文件夹
downloadImages(url, saveFolder)
}

一站式 AI 云服务平台
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)