
BrainStat:一个用于全脑统计和多模态特征关联的工具箱
神经影像数据分析和解释需要结合多学科的共同努力,不仅依赖于统计方法,而且越来越多地依赖于与其他脑源性特征相关的关联,如基因表达、组织学数据、功能和认知结构。在这里,我们介绍了BrainStat,它是一个工具箱,包括(i)在体素空间和皮层空间的神经影像数据集中的单变量和多变量线性模型,以及(ii)死后基因表达和组织学的空间图谱,基于任务的功能磁共振成像元分析,以及几个常见静息态功能磁共振成像大脑皮层
1. 摘要
神经影像数据分析和解释需要结合多学科的共同努力,不仅依赖于统计方法,而且越来越多地依赖于与其他脑源性特征相关的关联,如基因表达、组织学数据、功能和认知结构。在这里,我们介绍了BrainStat,它是一个工具箱,包括(i)在体素空间和皮层空间的神经影像数据集中的单变量和多变量线性模型,以及(ii)死后基因表达和组织学的空间图谱,基于任务的功能磁共振成像元分析,以及几个常见静息态功能磁共振成像大脑皮层模板在内的多模态特征关联。统计和特征关联结合成一个关键的工具箱简化了分析过程并加速了跨模态研究。工具箱用Python和MATLAB实现,这两种编程语言在神经影像和神经信息学领域中广泛使用的。BrainStat是公开提供的,并包括一个可扩展的文件。
2. 引言
神经影像可以在全脑范围内测量个体的大脑形态、微结构、功能和功能连接。通过越来越多的强大的图像处理技术,这些数据可以纳入标准化的参考空间,包括体素空间,如常用的MNI152空间、皮层表面基础空间,如fsaverage,MNI152表面,或grayordinates以及一些脑区分割模板。将神经影像数据注册到一个公共空间,我们能够允许应用统计分析在每个测量单位进行统计检验,包括的单变量广义线性模型和混合效应模型。通常,这种分析需要使用多种工具和程序来进行,减少了分析流程的可重复性并增加了人为错误的风险。在当前的论文中,我们提出了BrainStat,一个统一的工具箱,可以在一个统一的、透明的和开源的框架中实现这些分析。
神经影像研究的高级分析工作流程越来越依赖于以前获得的多种影像模式和非影像的数据集的可用性。当映射到与神经影像测量相同的参考框架时,这些数据集可以用于神经影像结果的背景化研究,并帮助解释和验证结果。例如,结果可能在已经建立的大脑功能架构中进行解释,如基于静息态功能磁共振成像内在功能社区或功能梯度。另一种常见的背景化方法是使用Neurosynth、NiMARE或BrainMap进行自动元分析。这些工具提供了对可能的数千项先前发表的功能磁共振成像研究进行荟萃分析的能力。将一个统计图谱与一个与认知术语相关的大脑激活地图的数据库联系起来,即所谓的元分析解读。因此,提供了一种定量的方法来推断与空间统计模式相关的可信认知过程。最后,将转录组学和组织学的死后数据集映射到一个共同的神经影像空间,使神经影像发现与基因表达和微观结构模式联系起来。这些发现可以提供关于大脑中分子和细胞特性的信息,这些特性在空间上与观察到的统计地图共同变化。通过结合这些特征关联技术,可以推断出神经影像学检查结果的功能、组织学和遗传学相关性。BrainStat提供了一个集成的解码引擎来执行这些多模态特性关联。
我们的工具箱有一个用Python和MATLAB并行实现的工具箱,这是神经影像研究领域中两种常见的编程语言。因此,BrainStat的一个关键设计选择是为了最大限度地同质化实现,从而提高工具的可访问性,并帮助用户在没有先验编程专业知识的情况下学习一种或两种编程语言。BrainStat依赖于一个简单的面向对象框架来简化分析工作流程。这个工具箱可以在https: //github.com/MICA-MNI/BrainStat上公开获得,还有一些文档可以在https://brainstat.readthedocs.io/上获得。我们将工具箱划分为两个主要模块:统计模块和背景化模块(图1)。在本文的其余部分中,我们描述了如何执行图1中所示的分析。
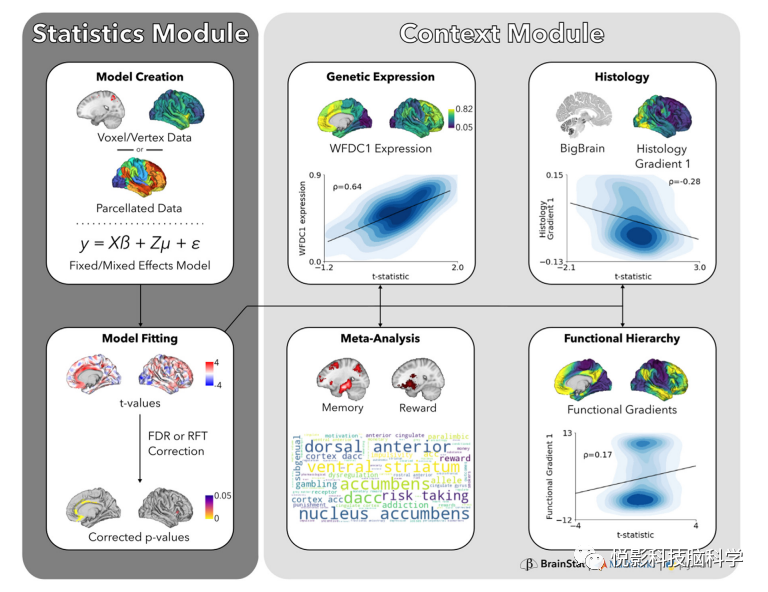
图1. BrainStat工作流程。工作流程被分为一个统计模块(深灰色)用于固定和混合效应线性模型,一个背景化模块(浅灰色)用于与外部数据集上下文化结果。要使用统计模块,用户必须提供体素、顶点或包裹水平的数据,必须指定固定或混合效果模型,并且必须指定模型对比度。一旦指定了这些,BrainStat计算t值并修正模型的p值。t值图或任何其他大脑图可以用于上下文模块,将统计结果与任务功能磁共振元分析的标记嵌入,并建立功能层次、遗传表达和组织学标记。
3. 统计模块
统计模块建立在SurfStat的基础上,这是一个经典但不维护的MATLAB包,用于实现固定和混合效应线性模型。为了在BrainStat实现中创建和拟合这样的模型,用户提供了一个主题×区域×响应变量的矩阵以及一个使用直观的模型公式框架创建的预测模型。这种方法允许将固定/随机效应直接定义为主要感兴趣的变量或控制协变量,促进了横向分析和纵向分析。对于混合效应模型建模,BrainStat使用了g侧规范,这样它就可以容纳多个随机效应作为独立效应,目前的拟合是通过严格的最大似然估计进行的。
为了比较感兴趣的变量(如健康/疾病、年龄)的影响,必须指定一个对比变量。BrainStat可以处理单变量或多变量响应变量数据,并提供两种广泛用于多重比较校正的分析选项,即错误发现率和随机场模型。错误发现率控制了数据中的特征变量(即顶点、体素、包裹)的假阳性比例,而随机场理论修正了曾经报告假阳性发现的概率(包括在峰值点水平和在团簇水平)。
为了说明统计模块,我们下载了微结构信息连接组学(MICAMICs)数据集中的70名被试的皮层厚度和人口统计学数据,其中12人是扫描两次的(图2A)。我们创建了一个线性模型,以年龄和性别以及它们的交互效应作为固定效应,被试作为随机效应(图2B)。这些都是使用固定效应和混合效应类(命名为如它可能包含随机和固定效应)来设置的。接下来,我们将对比数据定义为年龄,即正t值表示皮层厚度随着年龄的增长而减少。该模型采用单尾检验拟合皮层厚度数据。图2C绘制了由随机场理论得到的t值、聚类p值和峰值p值,以及经过错误发现率校正得到的顶点p值。我们发现,在MICAMICs数据集中,年龄对基于团簇水平的皮层厚度有影响。但在随机场理论中,这些团簇中没有显著的顶点级峰值,并且在顶点水平上没有边际显著性。这表明年龄对皮层厚度的影响覆盖了很宽的区域,而不是局部病灶。虽然我们在这个例子中使用了一个自由的团簇水平阈值(p<0.01),但我们通常建议使用一个更严格的阈值(p<0.001),特别是当使用很少的空间平滑的数据时。
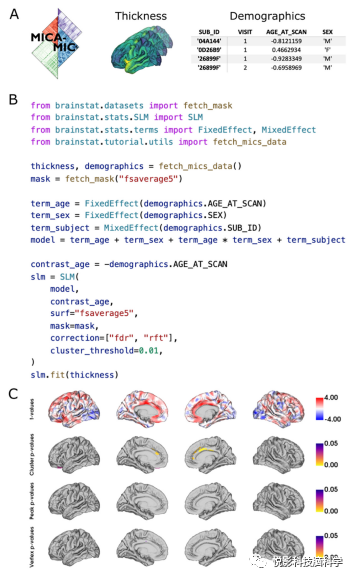
图2.拟合年龄对皮层厚度影响的固定效应一般线性模型的Python代码。(A)BrainStat包含的MICA-MICS数据集包含皮层厚度和人口统计学数据。人口统计学数据包含散列的被试ID(SUB_ID)、扫描次数、年龄z分数(AGE_AT_SCAN)和性别(SEX)。(B)我们创建了一个以𝒀=𝒊𝒏𝒕𝒆𝒓𝒄𝒆𝒑𝒕+𝒂𝒈𝒆+𝒔𝒆𝒙+𝒂𝒈𝒆∗𝒔𝒆𝒙+𝒓𝒂𝒏𝒅𝒐𝒎(𝒔𝒖𝒃𝒋𝒆𝒄𝒕)的形式的线性模型。请注意,默认情况下,截距将包含在模型中。第三,我们用年龄初始化模型的对比数据,并要求用随机场理论校正的p值(即“RFT”),以及用错误发现率校正的p值(即“FDR”)。最后,我们将该模型与皮层厚度数据进行了拟合。(C)负t值(蓝色)表示皮层厚度随年龄的增长而减少,而正t值(红色)表示皮层厚度随年龄的增长而增加。随机场理论(RFT)校正(团簇水平阈值p<0.01)以及通过错误发现率(FDR)校正得到的顶点水平p值(p<0.05)的结果显示了显著的峰值和聚类方面的p值(p<0.05)。为了简洁起见,我们省略了图形绘图代码。这个模型的Python和MATLAB代码,以及绘制这些图形的代码,可以在补充的Jupyter和实时脚本中找到。
任何拟合模型的质量和鲁棒性都可以在皮层上的每个顶点/包裹上进行评估,对于一个特定的顶点/包裹,或对于一个顶点/包裹的组合进行评估。为了检验数据的正态性,我们的质量控制函数输出残差的直方图和残差与正态分布的理论分位数值的q-q图。偏度和峰度的顶点或分段测量,表征了整个皮层的残差分布,也被映射到大脑表面。
4. 背景化模块
背景化模块允许计算具有多模态神经特征的统计映射的二元相关性。根据0.3.6版本,背景化模块可以链接到:(i)基于任务的功能磁共振成像荟萃分析,(ii)来自静息态功能磁共振成像的功能梯度,(iii)死后基因表达,以及(iv)死后组织学/细胞结构(图1)。使得可以与特定术语相关的任务功能磁共振成像元分析之间的关联。以及与功能梯度关联,这是一种表示功能连接体的低维方法。转录组学子模块从艾伦人脑图谱中提取基因表达。最后,组织学子模块从BigBrain中获得,这是一种人脑细胞结构的三维重建。这些子模块都支持通用的皮层表面模板,以及任何可行的自定义分割。总的来说,它们为关于微观和宏观大脑组织方面的统计结果的富集分析铺平了道路。
4.1 荟萃分析解码
BrainStat的荟萃分析解码子模块使用来自Neurosynth和NiMARE的数据,根据其认知关联的统计地图(通过先前基于任务的功能MRI发现的荟萃分析得出)。简而言之,我们为许多(认知)术语创建了一个荟萃分析激活图,这些图可能与给定的统计图相关联,以确定与它们之间关系最强的术语。这种方法可以识别与先前发表的大量基于任务的功能神经成像研究中使用的认知术语的间接关联,而不依赖于在同一队列中获得的认知任务。事实上,荟萃分析解码已经被几个小组用来评估他们的神经成像发现的认知关联。
对于基于术语的荟萃分析Neurosynth数据库中的每个术语,我们计算了哪些研究使用的术语的频率至少为1000个单词中的1个(NiMARE中的默认参数)。接下来,使用NiMARE中实现的多层核密度卡方分析来计算这些标签的元分析图。对于任何用户提供的基于表面的统计映射,我们将从表面到体素空间插值映射。最后,对于数据库中的每一个荟萃分析图,我们计算荟萃分析图和统计图之间的体素级皮尔逊相关性。图3显示了用之前计算的t-统计量图的元分析项检索相关性的一个例子。

图3. 荟萃分析解码。(A)使用NiMARE工具箱和Neurosynth数据库,我们为Neurosynth数据库中的每个特征名称获得了特征图。我们展示了一个术语“记忆”和“奖励”的关联映射示例。(B)示例Python代码,用于计算t统计图和Neurosynth数据库中的每个术语之间的相关性,并将这些相关性绘制成一个词云图。(C)从图3B中的代码中生成的词云图。
4.2 静息态模态
静状态下的大脑的功能结构被描述为一组连续的维度,称为梯度。这些梯度突出了区域之间的逐渐过渡,可以通过评估与其他标记物的关系,将发现嵌入到人类大脑的功能结构中。先前的研究使用功能梯度评估大脑功能结构与高级认知的关系,海马亚区连接、淀粉样蛋白表达和衰老、微结构组织、大脑系统发育变化和疾病状态的改变。
BrainStat中包含的功能梯度来自于HCP S1200版本的重采样平均功能连接矩阵并转换到fsaverage5表面(以降低计算复杂度)。随后计算了连接体的梯度。使用BrainSpace的以下参数:余弦相似度核函数、扩散映射嵌入、alpha=0.5、稀疏性=0.9和扩散时间=0。计算第一个功能梯度和t-统计图之间相关性的示例代码如图4所示。我们发现这两幅地图之间存在较低的斯皮尔曼相关性(𝜌=0.17)。然而,为了检验这种相关性的显著性,我们需要纠正数据中的空间自相关,BrainStat中包括三种校正方法,即自旋测试、莫兰光谱随机化和变量匹配。

图4. 与功能梯度的关联。(A)用于计算和绘制t统计图和第一个功能梯度的相关性的Python代码。为了简洁起见,我们省略了皮层表面绘图代码。(B)第一个功能梯度绘制在大脑表面。(C) t-统计图和第一个功能梯度相关性的核密度图。
4.3 基因表达
艾伦的人类脑图谱是一个包含微阵列基因表达数据的数据库,其中超过2万个基因来自于6名成人供体的死后组织样本。该资源可用于获得神经成像数据和分子因素之间的关联,从而深入了解产生解剖和连接组标记的机制。例如,这些数据可用于研究遗传因素与功能连接关联,解剖结构连接性关联,以及疾病中连连接的改变。BrainStat的遗传解码模块利用abagen工具箱来计算给定分割的遗传表达数据。abagen的默认参数遵循已建立的指南,并执行以下程序。首先,它使用alleninf软件包(https://github.com/chrisgorgo/alleninf)提供的坐标,获取并所有6个供体的组织样本的MNI152坐标。接下来,它将对探针进行基于强度的过滤,以删除它们不超过背景噪音的探针。随后,对于索引同一基因的探针,它选择了在供体间差异稳定性最高的探针。然后将组织样本与分割方案中的区域进行匹配。每个样本的表达值和每个样本的表达值使用比例稳健sigmoid归一化函数进行归一化。最后,每个区域内的样本在每个供体内平均,然后在各个供体内平均。有关具有非默认参数的过程的详细信息,请参考基本文档(https://abagen.readthedocs.io/)。在Python中,BrainStat直接调用abagen,因此所有参数都可以被修改。在MATLAB中,在MATLAB不可用的地方,我们包含了为许多常见的分割方案预先计算的基因表达矩阵。在图5中,我们展示了一个获取先前定义的功能图谱的遗传表达的例子,并将输出与t-统计图相关联。从这个模块得到的表达式可以用于进一步的分析,例如通过推导基因表达的主成分,并将其与以前导出的统计图进行比较。
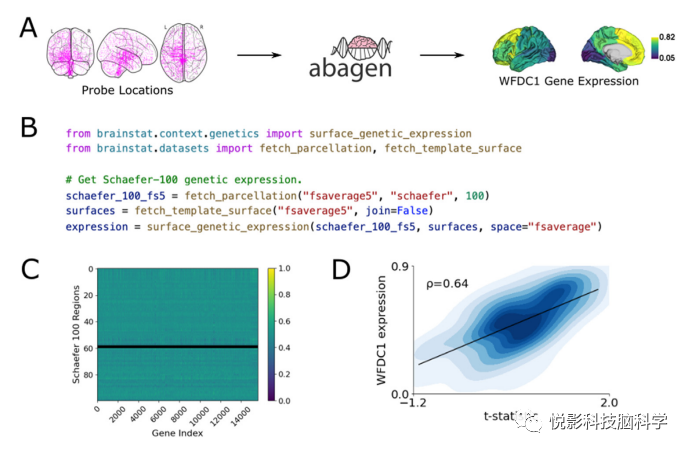
图5.与基因表达的关联。(A) BrainStat利用艾伦脑科学研究所提供的艾伦人脑图谱的数据,并用abagen进行处理,获得数千个基因的转录水平。图中显示了所有探针的位置以及一个基因(WFDC1)单个基因在100个功能定义区域内的表达。(B)基于表面分割的遗传表达式的Python代码。(C)遗传表达矩阵描述了所有包裹中所有解析基因的遗传表达。黑色的行表示没有样本的区域。(D)t-统计量图与WFDC1基因表达的相关性。
4.4 组织学
BigBrain图谱是一个切片和细胞体染色的人类大脑的三维重建。它具有20微米的数字化各向同性分辨率,是第一个公开可获得的全脑三维组织学数据集。因此,它非常适合于将神经成像标记物与组织学特性联系起来。例如,该资源可用于交叉验证MRI衍生的微观结构发现,基于组织学特性定义感兴趣的区域,或将连接组标记与微观结构联系起来。组织学子模块旨在简化神经成像发现与BigBrain数据集的集成。该子模块使用了来自大脑图谱采样的表面,在整个皮层地幔的50个不同深度。这些剖面的协方差,也称为微观结构剖面协方差,通过对平均强度剖面的偏相关校正来计算。细胞结构变化的主轴是使用具有默认参数的BrainSpace从微观结构轮廓协方差中计算出来的。这其中的一个例子如图6所示。我们发现第一特征向量与t-统计量图之间存在𝜌=-0.28的相关性。
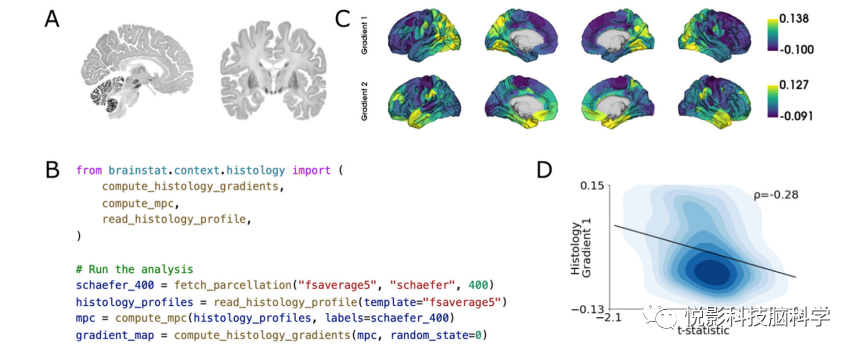
图6.与组织学标记物的关联。(A)从大脑图谱中选择矢状面和冠状面切片。(B)计算Schaefer-400分割的微观结构剖面协方差梯度的Python代码。(C)梯度来自于大脑图谱的微观结构剖面协方差。(D)t-统计图的散点图和微观结构剖面协方差的第一个梯度的相关性。
4.5 运行时间评估
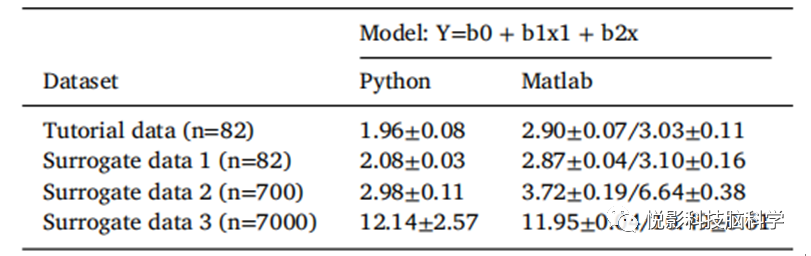
尽管目前在Matlab和Python中都是一个单线程实现,但BrainStat严重依赖于矩阵乘法,并允许快速计算,即使在分析更大的数据集时也是如此。作为一个例子,我们对我们的测试数据进行了一系列的实验,并使用bootstrap方法来扩大模拟数据集来评估计算时间(表1)。
表1.运行时间评估。以解决Python/Matlab代码的通用线性模型的时间为秒。该脚本包括定义术语(这里指年龄,性别),拟合模型(这里指M= 1 + Age + Sex),构建对比矩阵(这里指-年龄),以及多重比较校正(通过错误发现率和随机场理论)。数据表示在fsaverage5表面(20484个顶点)。计算已经在MacBook Pro上运行(2.9 GHZ四核英特尔i7,16 GB内存,Matlab R2022a和Python 3.9),显示了相同模型运行10次的平均运行时间。
5. 讨论
脑影像数据的分析需要进行单变量和多变量统计推断的工具,并且越来越多地利用来自多种资源的数据来促进重要结果的解释和背景化。尽管神经影像领域已经提供了许多工具来执行个体分析步骤,但目前还没有统一统计推断和背景化方法的软件包。事实上,以前的一些工具允许对神经影像数据进行统计分析,包括Matlab中的SPM(https://www.fil.ion.ucl.ac.uk/spm/),SurfStat以及Python中的nilearn(https://nilearn.github.io/)等。此外,多种资源允许将发现的背景化,包括neuromaps(https://github.com/netneurolab/neuromaps)和Enigma工具箱(https://enigma-toolbox.readthedocs.io/)。BrainStat是唯一的(i)结合了统计分析和背景化的工具,以及(ii)在Python和Matlab中实现的工具,旨在进一步促进和巩固分析工作流,作为一个完全开放的访问工具。我们希望这种并行实施将促进在该领域工作的分析师和研究人员的教学和培训。值得注意的是,工具箱的模块化设置允许相互独立地运行统计和背景化分析。此外,BrainStat还补充了一个全面和易于遵循的在线文档,为新手和专家用户提供了一个进入脑成像数据的集成分析的入口。
线性模型是神经影像推理的核心技术。许多常见的单变量和多变量统计分析,包括t检验、F检验、多元线性回归和(M)AN(C)OVA,都可以被认为是一般线性模型的特殊情况。因此,一般线性模型的使用在神经影像学文献中广泛存在。尽管它们很普遍,但它们的实施并非微不足道。BrainStat的统计模块旨在为神经成像数据提供一个灵活的多元线性建模框架。本文的重点是介绍由BrainStat提供的可能性,并概述了工具箱的关键功能的一个可访问的教程。因此,我们举例说明使用混合效应模型来测试年龄对皮层厚度的影响。然而,考虑到线性模型的多功能性,可以在同一框架内指定大量不同的模型。对比度的灵活规范简化了拟合模型的测试,工具箱进一步提供了初始质量控制函数来验证模型的假设和模型的拟合。
近年来,使用外部数据集对MRI衍生结果的背景化的情况有所增加。这些数据集可以利用其独特的优势,如前所未有的空间分辨率的BigBrain组织图谱,大量的任务功能磁共振成像研究包括在Neurosynth荟萃分析数据库,和死后人类大脑基因表达信息聚合的人类大脑图谱。这些外部数据集允许对大脑组织进行更全面的研究,并可能促进我们对大脑组织的基本原理的理解。先前的研究已经使用这些数据集来将任务荟萃分析、基因表达和组织学与形态、功能和连接组学标记物联系起来。尽管有许多软件包可以实现这些分析,但这些通常是独立分布的,它们的集成需要专业知识,通常需要熟练使用特定的编程语言,因为通常没有跨语言实现。BrainStat将这些工具结合到一个统一的多语言框架中,从而增加了它们的可访问性,并简化了神经成像研究的分析过程。值得注意的是,虽然背景化模块与BrainStat派生的输出一起工作,但也可以在其他结果(从其他统计软件包或简单的大脑特征图中获得的结果)上运行该工具。总的来说,上下文模块的功能和数据集为关于微观和宏观大脑组织方面的研究发现的富集分析铺平了道路。最终,我们希望减少这些技术的进入障碍,减少人为错误的机会,从而加速神经成像领域的跨模态研究。
在目前的实现中,BrainStat实现了针对微尺度(即转录组和组织学)和功能(如功能磁共振成像荟萃分析和静息态脑网络)特征进行背景化的工作流程。这允许用户在基础和临床神经成像中采用越来越流行的分析方法。值得注意的是,一般来说,背景化关联分析的应用并不一定意味着对大脑组织的微观和宏观属性之间,以及结构和功能之间的关联的定向性的任何假设。事实上,微观尺度-宏观尺度关联以及结构-功能关系在人类大脑中仍然是一个高度活跃的研究课题,往往表明不同领域之间存在复杂的双向关系。
对于基于任务的荟萃分析解码,目前实现的nimatat接口,它在体素(即MNI152)空间中执行荟萃分析推理。这种方法的一个潜在限制是,表面到体素的转换本身并不会导致皮层带内的密集表示。因此,BrainStat使用带线性或最近邻插值的带填充方法来生成给定表面映射的基于体素的近似,然后在NiMARE中进行交叉引用。选择这一步是为了避免生成(可能进化的)NiMARE数据库的基于表面的克隆。此外,我们还想强调,对BrainStat的未来更新可以利用元分析解码方法和工具的持续进展,以提高可靠性和可解释性。例如,使用潜在狄利克雷分配(LDA)使用基于主题的荟萃分析来确定研究的荟萃分析样本,可以为每个荟萃分析图提供更广泛的术语集,解决基于术语的元分析方法的缺点,特别是单个术语的冗余和模糊性。特别是,广义对应LDA(GC-LDA)被建议添加空间和语义约束,提供了一个更微妙的功能解码。从Neurosynth数据库扩展而来的, NeuroQuery数据库包含了更广泛的词汇表和更丰富的研究文本表示,从而增加了将大脑激活与当前研究内容联系起来的细微差别和准确性。
理论和实证研究已经证明了可复制性在科学中的重要性。开放获取数据集的扩散和软件可能通过允许其他人使用相同的数据和程序重做实验,以及减少分析中的人为误差。BrainStat可能有助于这一过程。通过将统计处理和多域特性关联统一到跨两种编程语言的单个包中,生成的代码将需要更少的定制和技术专业知识。此外,BrainStat可能会增加在缺乏建立这类综合管道的机构专业知识的地方的研究人员获得所有这些方法的机会。鼓励研究人员和用户为不断增强BrainStat工具箱的功能和范围做出贡献。我们鼓励寻求帮助的用户将他们的问题发布到GitHub问题页面(https:// github.com/MICA-MNI/BrainStat/issues)。类似地,通过GitHub拉动请求(https://github.com/MICA-MNI/BrainStat/pulls)支持来自世界各地用户的新分析方法的集成,并可以成为未来发布的一部分。

一站式 AI 云服务平台
更多推荐



 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)