
【LangChain入门 8 】基于RAG实现文档检索与问答
我们需要一个地方来存储和索引我们的分割(splits),以便后续可以对其进行搜索。如果你想构建能够对私有数据或模型介质日期后引入的数据进行推理的人工智能应用,你需要用特定信息来增强模型的知识。大语言模型可以对广泛的主题进行推理,但它们的知识仅限于训练时截止日期前公开的数据。检索适当信息,并将其插入模型提示的过程被称为检索增强生成(RAG)。:ChatModel使用包含问题和检索到的数据的提示来生成
·
一、RAG基本概念
1.1 RAG(检索增强生成)是什么
RAG是一种用额外数据增强大语言模型知识的技术。
大语言模型可以对广泛的主题进行推理,但它们的知识仅限于训练时截止日期前公开的数据。
如果你想构建能够对私有数据或模型介质日期后引入的数据进行推理的人工智能应用,你需要用特定信息来增强模型的知识。
检索适当信息,并将其插入模型提示的过程被称为检索增强生成(RAG)。
LangChain有许多组件旨在帮助构建问答应用,以及更广泛的RAG应用。
1.2 RAG工作流
一个典型的RAG应用有两个主要组成部分
- 索引: 从数据源获取数据并建立索引的管道(pipeline)。这通常在离线状态下进行
- 检索和生成:实际的RAG链,在运行时接收用户查询,从索引中检索相关数据,然后将其传递给模型
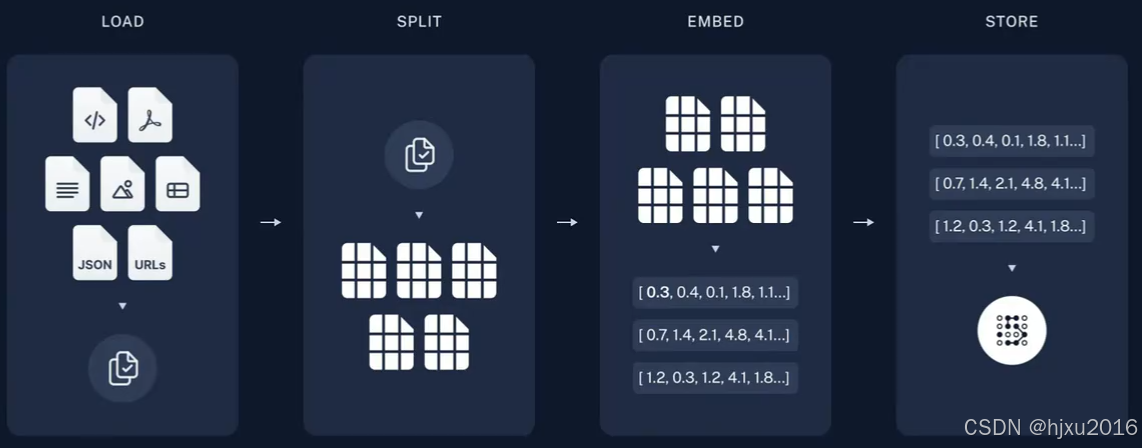
从原始数据到答案的最常见完整顺序如下:
- 加载(Load):首先我们需要加载数据,这是通过文档加载器 Document Loaders完成
from langchain_community.document_loaders import PyPDFLoader
from pyparsing import dblQuotedString
# 文档加载器
loader = PyPDFLoader("/mnt/pyCharmPro/《考勤管理制度(更新草案)》.pdf")
doc1 = loader.load()
print(len(doc1))
- 分割(Split):文本分割器Text splitters将大型文档(Documents)分成更小的块(chunks)。这对于索引数据和将其传递给模型都很有用,因为大块数据更难搜索,而且不适合模型有限的上下文窗口。
# 文档分割器
from langchain.text_splitter import CharacterTextSplitter
# 分割实例化对象
text_splitter = CharacterTextSplitter(
separator="", # 分割文本的字符或字符串
chunk_size=6, # 每个文本块的最大长度
chunk_overlap=2 # 文本块的重叠字符数
)
# 对一句话进行分割
result = text_splitter.split_text("天气不错\n可以出去玩了")
print(result)
- 存储(Store):我们需要一个地方来存储和索引我们的分割(splits),以便后续可以对其进行搜索。 这通常使用向量存储VectoreStore和嵌入模型(Embeddings model)来完成
# 持久化数据
# chroma 是个本地的向量数据库,他提供的一个 persist_directory 来设置持久化目录进行持久化。读取时,只需要调取 from_document 方法加载即可。
docsearch = Chroma.from_documents(spliter, embed, persist_directory="./vector_store")
docsearch.persist()
# 加载数据
#
docsearch = Chroma(persist_directory="./vector_store", embedding_function=embed)
- 检索(Retrieve):给定用户输入,使用检索器Retriever从存储中检索相关的文本片段
# 6. 文档检索器
from langchain_community.vectorstores import FAISS
# 将数据存入向量存储
db = FAISS.from_documents(spliter, embed)
# 通过向量存储初始化检索器
retriever = db.as_retriever(search_kwargs={"k": 3})
result = retriever.invoke("工作时间安排是什么?")
print(result)
- 生成(Fenerate):ChatModel使用包含问题和检索到的数据的提示来生成答案
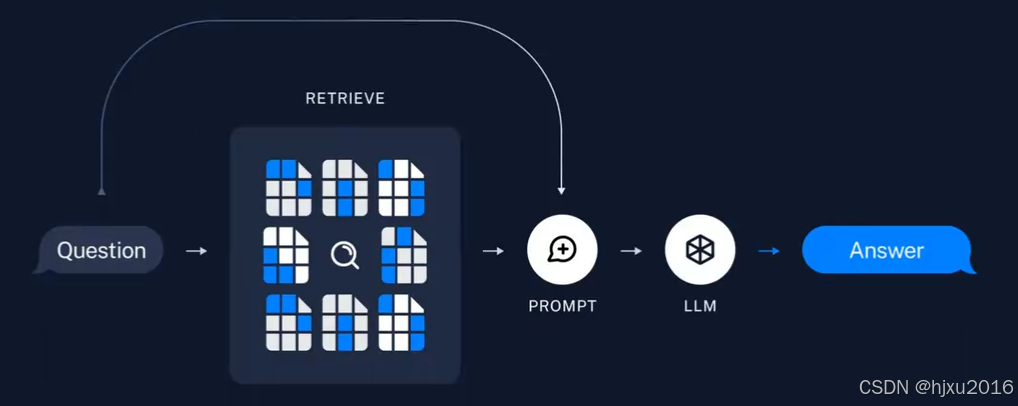
1.3 文档问答实现流程
一个RAG文档问答程序的APP主要有以下流程
- 用户在RAG客户端上传一个txt文件
- 服务器端接收客户端文件,存储在服务端
- 服务器端程序对文件进行读取
- 对文件内容进行拆分,防止一次性塞给Embedding模型超token限制
- 把Embedding后的内容存储在向量数据库,生成检索器
- 程序准备就绪,允许用户进行提问
- 用户提出问题,大模型调用检索器检索文档,把相关片段找出来后,组织后,回复用户。
二、简易版的文档检索
这里仅仅搜索最相近的向量,仅有文本搜索的功能
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain_ollama import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
# 1. 文档加载器
loader = PyPDFLoader("/mnt/pyCharmPro/《考勤管理制度(更新草案)》.pdf")
doc1 = loader.load()
# 2. 分割实例化对象
# text_splitter = CharacterTextSplitter(
# separator="", # 分割文本的字符或字符串
# chunk_size=100, # 每个文本块的最大长度
# chunk_overlap=10 # 文本块的重叠字符数
# )
# 更强大的分割工具
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n"," ", "."], # 分割文本的字符或字符串
chunk_size=100, # 每个文本块的最大长度
chunk_overlap=10 # 文本块的重叠字符数
)
spliter = text_splitter.split_documents(doc1)
# 3. 初始化 emdedding
embed = OllamaEmbeddings(model="deepseek-r1:7b")
# 4. 使用Chroma库来创建一个文档搜索索引,将数据存入向量存储
vectore_store = Chroma.from_documents(spliter, embed) # 返回的是一个vectorstore
# 5. 相似度匹配
query = "工作时间是多少"
result = vectore_store.similarity_search(query)
print(len(result))
# 通过向量存储初始化检索器
retriever = vectore_store.as_retriever(search_kwargs={"k": 3})
result = retriever.invoke("工作时间安排是什么?")
print(result)
三、使用RetrievalQA 实现文档问答
除了文档检索外,还结合的大语言模型进行了增强。
因此还需要设计提示词
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_ollama import ChatOllama
llm = ChatOllama(model="deepseek-r1:7b")
# Create QA chain
# Create custom prompt template
template = """
问题: {question}
完全照抄{context}的内容来回答问题:"""
PROMPT = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs={"prompt": PROMPT}
)
response = qa_chain.invoke("每天的工作时长是多少?")
print(response)

一站式 AI 云服务平台
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)