
EfficientNetV2结构讲解( Smaller Models and Faster Training)
EfficientNetV2结构讲解
文章目录
1.论文地址
1.https://arxiv.org/abs/2104.00298
2.EfficientNetV2的提出
(1)EfficientNetV1存在的问题
A.当训练图片的尺寸很大时,训练的速度很慢;
从这张表可以看到,EfficientNet-B6在不同的batch size和不同的图片尺寸上训练的结果;可对比可以看到:
(1)当图片的大小为image_size=512,在TPUv3单核上,batch_size=32时,每秒可以推理42张图片;而当batch size=128时直接导致内存溢出(OOM=Out Of Memory);
(2)而当图片的大小为image_size=380,在TPUv3单核上,batch_size=32时,每秒可以推理76张图片;而这两种情况下最后在Top-1上的准确率差不多。
(3)当图片的大小为image_size=512,在V100单GPU上,batch_size=32时,每秒可以推理29张图片;而当batch size=24时直接导致内存溢出(OOM=Out Of Memory);
(4)而当图片的大小为image_size=380,在V100单GPU上,batch_size=32时,每秒可以推理37张图片;而这两种情况下最后在Top-1上的准确率差不多。
思考:可是为什么图片的尺寸越大,训练的速度越慢呢?
解释:因为图片的尺寸变大将导致访问内存量增加,但是GPU/TPU的总的内存容量是固定的,所以不得不使用更小的batch size来替代,所以batch size减小了,训练的速度也就慢了下来。但是从上面的结果来看,较小的图片和较大的图片训练的最终结果差不多,并且较小的图片训练速度也快很多的情况下,所以没有必要增大图片的。
B.在浅层网络中使用Depthwise Convlutions时,速度会很慢;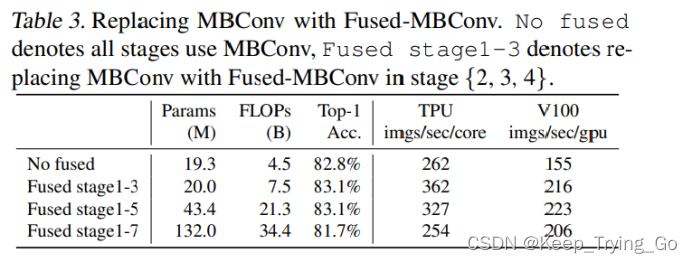
从这张表可以看到:
(1)当使用Fused-MBConv使用在stage1-3阶段的时候,在TPU/GPU上的训练速度明显提升了很多,参数量有一点增加,FLOPs也增加了一些,并且准确率还有一点提升;
(2)当使用Fused-MBConv使用在stage1-5阶段的时候,在TPU/GPU上的训练速度相比于替换stage1-3降了(但是还是比不使用Fused-MBConv快很多),参数量明显增加,FLOPs也明显增加,准确率没有提升;
(3)但是当使用Fused-MBConv使用在stage1-7阶段的时候,在TPU/GPU上的训练速度比原来还慢,参数量明显增加,FLOPs也明显增加,准确率也降低了;
所以总结上述:并不是一味的替换的越多越好,而是要在使用Fused-MBConv和不使用Fused-MBConv之间做一个权衡;作者使用神经网络架构搜索得到替换stage1-3最好。
思考:可是为什么在浅层网络中使用Depthwise Convlutions时,速度会很慢呢?
解释:虽然使用深度卷积(Depthwise Convlutions)比使用标准卷积(standard)的参数量要少,但是使用深度卷积却不能很好的利用现代加速器;所以提出Fused-MBConv可以很好被使用在移动端和服务端加速器,取代了深度卷积和1x1卷积。
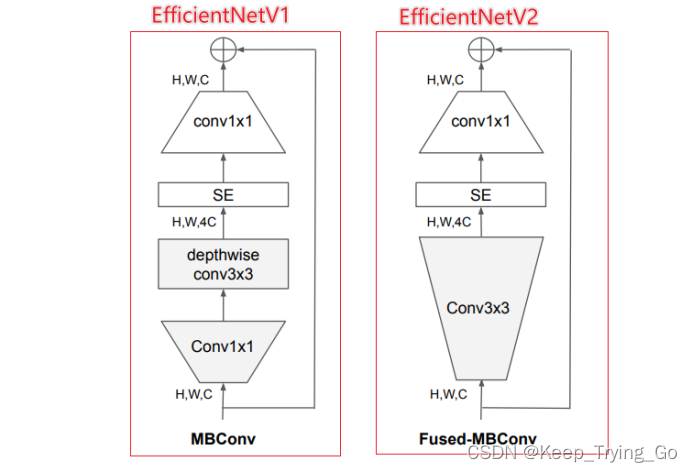
C.同等的放大每个stage是次优的。
在EfficientNetV1中对于所有的层都是使用同样的复合缩放尺寸规则,但是EfficientNetV2不再这样做,而是进行改进,不使用统一的复合缩放尺寸规则,而是随着训练越往后,不断的增加层(layers)的量,但是在这个结构中我们也使用逐步学习的方式来缩放图片的大小,会导致内存访问量增加,训练速度变慢,所以这里采用限制缩放最大图片和最小图片的规则。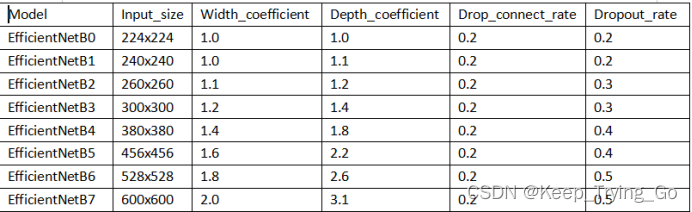
为什么同等的放大每个stage是次优的呢?
解释:每个stage深度和宽度都是相同缩放的,可是每个stage对于网络的训练速度以及参数量的贡献并不是相同的,所以不能直接使用同等缩放的方式。
(2)提出理由
之前提出的模型都比较庞大,并且参数量大,虽然EfficientNetV1的提出具有显著的提高,但是模型的速度不够快和参数量还是不够小。所以在EfficientNetV1基础上改进之后,EfficientNetV2更快,更轻量化,并且准确率也达到了最高。
主要的改进:
(1)引入新的网络,网络的训练速度以及参数量上都比之前的网络都要好;
(2)提出了逐步学习的方法,根据训练的图片尺寸动态的调整正则化,提升训练的速度,准确率;
(3)与之前的网络相比,该网络提升的训练速度快11倍,参数量少6.8倍。
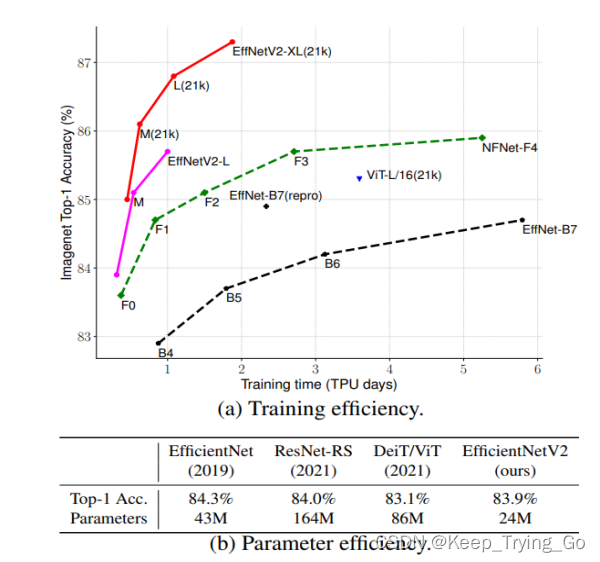
解释:从上面的图表可以看出,改进之后的EfficientNetV2模型更快,更轻量化,在Top-1的准确率上,比之前的EfficientNetB7准确率还要高,速度还要快;和其他模型相比较,在Top-1上准确率差不多的情况下,EfficientNetV2的参数量明显要少很多,速度是其他模型的5-11倍,参数量是其他模型的6.8分之一。
3.EfficientNetV2使用的方法
(1)使用Fused-MBConv模块;
(2)提出了一种新的提高模型的方法,就是使用逐步学习的方法,自适应的调整正则化,为了更快的训练模型并且达到更好的准确率。
4.逐步学习方式(渐进式学习方式)
(1)提出原因
由于图片的大小对于训练的效果至关重要,所有想通过在训练期间动态的改变图片的大小来提升训练的效果,但是如果动态的改变图片的大小的话会导致准确率车下降,所以提出逐步学习的方式。
(1)首先假设准确率的下降是由于不平衡的正则化导致的;(2)动态的改变图片大小的同时也动态的调整正则化;(3)更大的模型需要使用更强的正则化(Dropout和数据增强),防止过拟合;(4)更小的图片使用更小的网络和更弱的正则化。
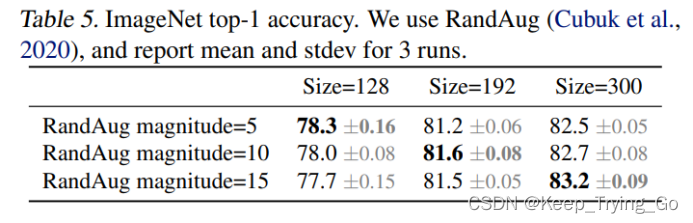
在假设的前提下进行模型训练的对比,正则化随着改变图片的大小进行调整;可以看到此表,随着图片的大小不断的增加,同时正则化增强,准确率也在不断的提高。
(2)逐步学习方式的实现


(3)结果对比
对比了基准模型和使用逐步学习之后的模型的效果:图片大小从224逐渐增加到380.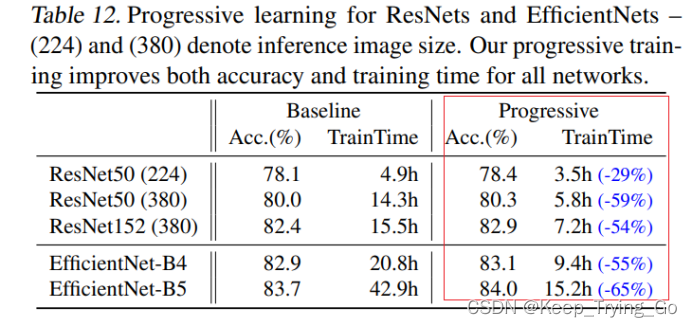
可以看到使用逐步学习的方式之后的所有模型比基准模型训练的更快,并且准确率还有一点提升。有点值得注意的是ResNet50在小的图片尺寸(224)上训练的时间被限制了。不管怎么样,使用了逐步学习方式之后的模型训练的时间都缩短了,提高了训练的效率。
自适应正则化调整:根据图片的大小动态的调整正则化
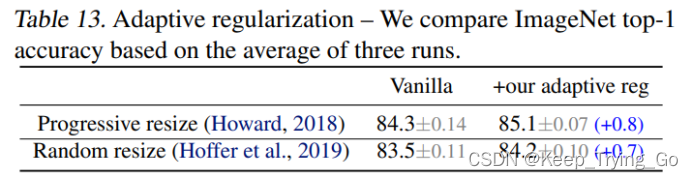
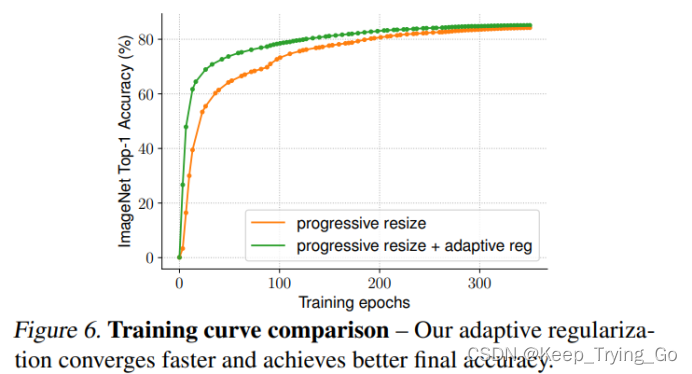
可以看到在使用逐步裁剪和自适应正则化的情况下,效果才是最好的。
5.EfficientNetV2结构
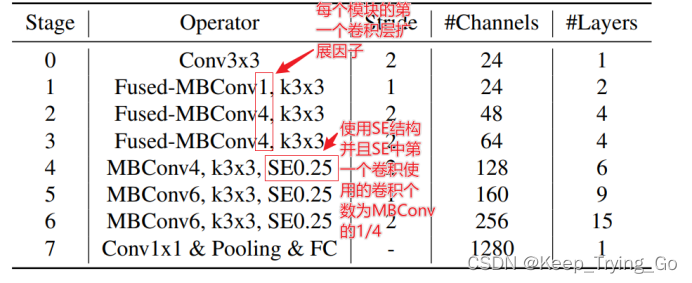
与EfficientNetV1相比改进:
(1)将Fused-MBConv与MBConv同时使用;
(2)使用较小的expansion ratio;
(3)使用的卷积核大小更小(EfficientNetV1中使用了5x5的卷积);
(4)移除了EfficientNetV1中最后一个stage为1的。
6.实验结果对比
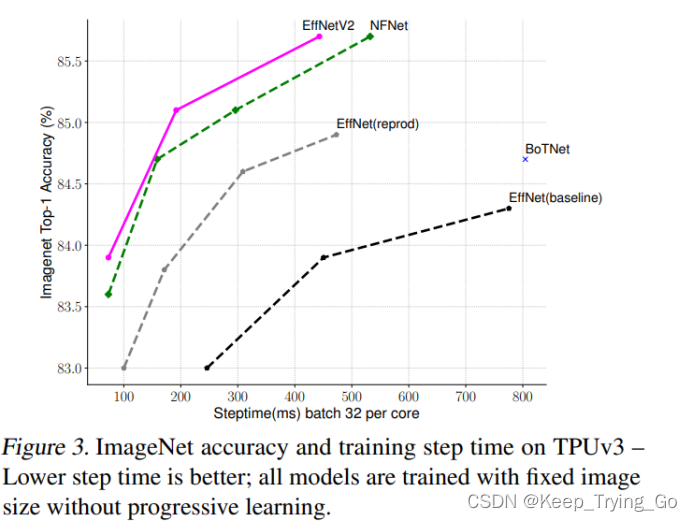
这里的EfficientNetv2固定了图片的大小,没有使用逐步学习的方式(便于对比);其中EfficientNet是被用于训练推理原始图片大小;另一个是被用于训练比原始小30%的图片;所有的模型都是训练350代,但是NFNets除外(训练360代);可以发现EfficientNetV2还是表现最好的模型(速度和精度的权衡),比其他最近的一些模型都更快。从下面的表可以看出。
(1)使用逐步学习(渐进式学习)的方法
EfficientNetV2对比目前在Imagenet数据集上训练对好的所有模型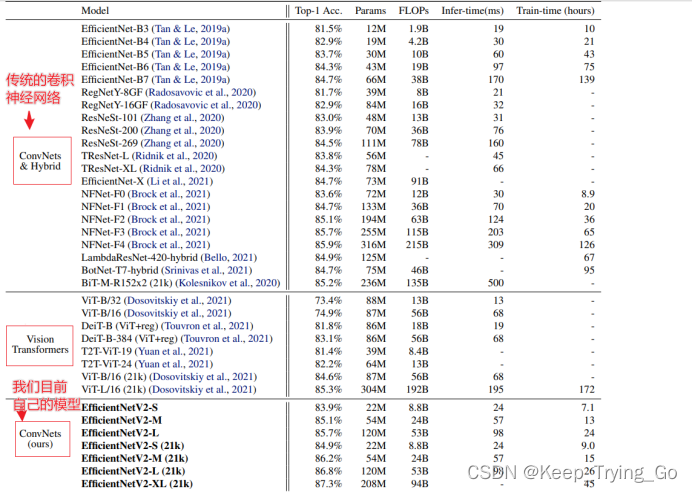
(1)可以看到EfficientNetV2-XL(21k)的Top-1准确率达到了87.3%,是这个表所有模型的准确率最高的,但同时参数量208M也是不小的,训练时间相比于传统的一些卷积神经网络也快了很多,相比于Vision Transformers更快。
(2)EfficientNetV2-S和EffficientNet-B5在Top-1上准确率相当的情况下,参数量和FLOPs也比EffficientNet-B5少。
(3)EfficientNetV2-S(21k)与ResNeSt-269在Top-1上准确率也相当的情况下,参数量和FLOPs也比ResNeSt-269少了很多,当然还有很多的其他比较。可以看到EfficientNetV2模型确实更快,更小了,更高效。
注:
ImageNet ILSVRC2012数据集:包含128万张训练图片和5万张验证集图片1000个类别;
ImageNet21k数据集:包含1300万张训练集图片(没有划分训练集和测试集图片),21841个类别,最后随机的从中抽取10万张图片进行验证。
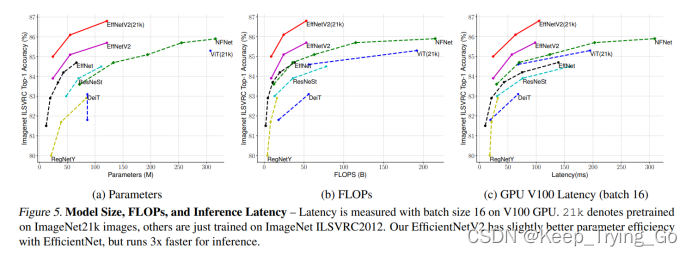
分别从参数量,FLOPs和在GPU V100上的推理延迟时间比较了EfficientNetV2比其他模型更快,更小,更高效。
(2)迁移学习的效果
在ImageNet ILSVRC2012.数据集上进行训练,最后分别泛化到四个数据集:CIFAR-10, CIFAR-100, Flowers and Cars.
(1)微调使用更小的batch size 512;
(2)使用更小的初始化学习率learning rate 0.001;
(3)对于所有的模型固定训练10000 steps;
(4)禁止使用权重衰减和使用简单的裁剪方式进行数据增强;
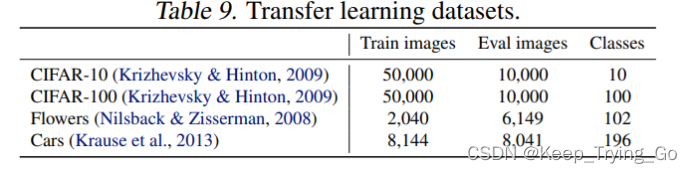
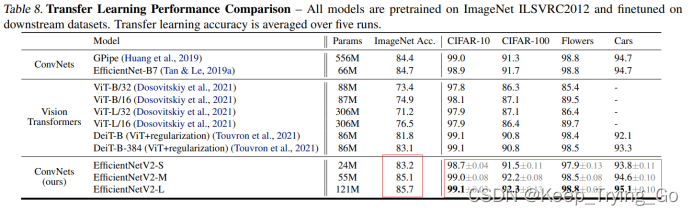
最后的结果是:在所有的数据集上,所有的模型迁移学习之后都比之前的ConvNets和Vision Transformers都要好,在EfficientNetV2-L 比之前的 GPipe/EfficientNets上升0.6% 比ViT/DeiT models上升1.5% .说明了EfficientNetv2可以很好的泛化到ImageNet数据集上。
(3)EfficientNetV2和EfficientNetV1对比学习
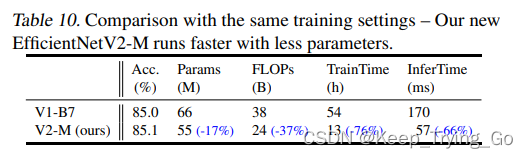
这张表对比了EffficientNetV1与EffficientNetV2在使用逐步学习方式的情况下,将原来的需要139个小时的训练时间缩短到只要54个小时,并且准确率还有提升。
(1)EffficientNetV2模型比EffficientNetV1模型的参数量少了近17%;(2)在FLOPs上比EffficientNetV1少了近37%;(3)在训练速度上比EffficientNetV1快了76%;(4)在推理速度上比EffficientNetV1快了66%。
在没有使用逐步学习,准确率,参数量和FLOPs差不多的情况下,为了提高训练的速度,通过缩小模型得到EfficientNetV2-S(使用了EffficientNetV1的复合缩放)。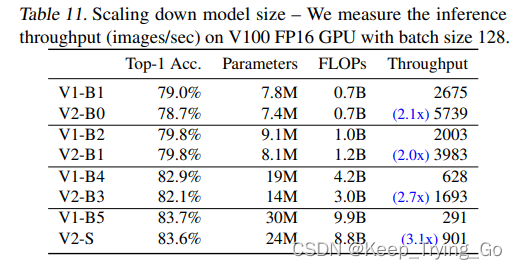
此表对比了EffficientNetV1的B0-B5和EffficientNetV2各个模型进行相应的推理速度的对比(在相同的硬件环境下):可以看到在准确率相同的情况下,EffficientNetV2比EffficientNetV1推理速度都要快,最快的达到3.1倍,并且参数量都要少。
7.Tensorflow2.6.0实现网络结构
https://blog.csdn.net/Keep_Trying_Go/article/details/125173651

一站式 AI 云服务平台
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)