
云原生之k8s1.22版本高可用部署
本文为k8s爱好者学习入门部署文章,后期会不断更新发布,有兴趣的大佬可以一起探讨
kunernetes1.22高可用集群
Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具做任何集群管理。
我们在做master高可用时节点个数至少3个,三个master节点的配置可以提供一定的容错能力。在两个节点出现故障的情况下,第三个节点仍然可以正常工作,保证集群的控制平面不会完全瘫痪。
- 环境准备
| 角色 | 地址 | 系统版本 | 集群版本 | 安装软件 |
|---|---|---|---|---|
| Master01 | 172.16.229.28 | centos7.9 | 1.22.2 | kubeadm、kubelet、kubectl、docker、nginx、keepalived |
| Master02 | 172.16.229.29 | centos7.9 | 1.22.2 | kubeadm、kubelet、kubectl、docker、nginx、keepalived |
| Master03 | 172.16.229.30 | centos7.9 | 1.22.2 | kubeadm、kubelet、kubectl、docker、nginx、keepalived |
| Node-1 | 172.16.229.31 | centos7.9 | 1.22.2 | kubeadm、kubelet、kubectl、docker |
| Node-2 | 172.16.229.32 | centos7.9 | 1.22.2 | kubeadm、kubelet、kubectl、docker |
| VIP | 172.16.229.10 | VIP | VIP | VIP |
1.所有机器做本地解析并相互解析
2.所有机器设置为静态ip
3.所有机器关闭防火墙和selinux
4.关闭swap交换分区
# swapoff -a
# sed -i 's/.*swap.*/#&/' /etc/fstab
5.所有节点安装docker
6.所有节点同步时间
安装docker
# yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
# yum install -y yum-utils device-mapper-persistent-data lvm2 git
# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# yum install docker-ce -y
启动并设置开机启动
#注:在目前k8s版本1.20以后将原来的cgroupfs驱动程序修改成了systemd来为容器做资源限制,故此需要将docker的驱动程序修改为systemd。(所有节点)
[root@master ~]# cat /etc/docker/daemon.json
{
"exec-opts":["native.cgroupdriver=systemd"]
}
重启docker
使用kubeadm部署Kubernetes
在所有节点安装kubeadm和kubelet:
配置源
# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
所有节点:
1.安装最新版本
# yum makecache fast
# yum install -y kubelet kubeadm kubectl ipvsadm ipset
=========================================
2.安装对应版本
[root@k8s-master ~]# yum install -y kubelet-1.22.2-0.x86_64 kubeadm-1.22.2-0.x86_64 kubectl-1.22.2-0.x86_64 ipvsadm ipset
2.加载ipvs相关内核模块
如果重新开机,需要重新加载(可以写在 /etc/rc.local 中开机自动加载)
# modprobe ip_vs
# modprobe ip_vs_rr
# modprobe ip_vs_wrr
# modprobe ip_vs_sh
# modprobe nf_conntrack_ipv4
3.编辑文件添加开机启动
# vim /etc/rc.local
# chmod +x /etc/rc.local
重启服务器
4.配置:
配置转发相关参数,否则可能会出错
# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
vm.swappiness=0
EOF
5.使配置生效
# sysctl --system
6.如果net.bridge.bridge-nf-call-iptables报错,加载br_netfilter模块
# modprobe br_netfilter
# sysctl -p /etc/sysctl.d/k8s.conf
7.查看是否加载成功
# lsmod | grep ip_vs
ip_vs_sh 12688 0
ip_vs_wrr 12697 0
ip_vs_rr 12600 0
ip_vs 141092 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 133387 2 ip_vs,nf_conntrack_ipv4
libcrc32c 12644 3 xfs,ip_vs,nf_conntrack
查看kubeadm版本
# yum list --showduplicates kubeadm --disableexcludes=kubernetes
配置启动kubelet(所有节点)
1.配置kubelet使用pause镜像
获取docker的systemd
# DOCKER_CGROUPS=$(docker info | grep 'Cgroup' | cut -d' ' -f4)
# echo $DOCKER_CGROUPS
=================================
配置变量:
[root@k8s-master ~]# DOCKER_CGROUPS=`docker info |grep 'Cgroup' | awk ' NR==1 {print $3}'`
[root@k8s-master ~]# echo $DOCKER_CGROUPS
systemd
这个是使用国内的源。-###注意我们使用谷歌的镜像--操作下面的第3标题
2.配置kubelet的cgroups
# cat >/etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=$DOCKER_CGROUPS --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause-amd64:3.1"
EOF
3.配置kubelet的cgroups
# cat >/etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=$DOCKER_CGROUPS --pod-infra-container-image=k8s.gcr.io/pause:3.5"
EOF
启动
# systemctl daemon-reload
# systemctl enable kubelet && systemctl restart kubelet
在这里使用 # systemctl status kubelet,你会发现报错误信息;
10月 11 00:26:43 node1 systemd[1]: kubelet.service: main process exited, code=exited, status=255/n/a
10月 11 00:26:43 node1 systemd[1]: Unit kubelet.service entered failed state.
10月 11 00:26:43 node1 systemd[1]: kubelet.service failed.
运行 # journalctl -xefu kubelet 命令查看systemd日志才发现,真正的错误是:
unable to load client CA file /etc/kubernetes/pki/ca.crt: open /etc/kubernetes/pki/ca.crt: no such file or directory
#这个错误在运行kubeadm init 生成CA证书后会被自动解决,此处可先忽略。
#简单地说就是在kubeadm init 之前kubelet会不断重启。
负载均衡部署
所有Master节点安装Nginx、Keepalived
1.配置nginx的官方yum源
[root@master01 ~]# cat /etc/yum.repos.d/nginx.repo
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[root@master01 ~]# yum install -y nginx keepalived
开始配置nginx代理master的api-server组件
[root@master01 ~]# vim /etc/nginx/nginx.conf #在http快上方添加四层代理
...
stream {
upstream apiserver {
server 172.16.229.28:6443 weight=5 max_fails=3 fail_timeout=30s;
server 172.16.229.29:6443 weight=5 max_fails=3 fail_timeout=30s;
server 172.16.229.30:6443 weight=5 max_fails=3 fail_timeout=30s;
}
server {
listen 8443;
proxy_pass apiserver;
}
}
http {
[root@master01 ~]# mv /etc/nginx/conf.d/default.conf /etc/nginx/conf.d/default.conf.bak
[root@master01 ~]# systemctl start nginx
[root@master01 ~]# systemctl enable nginx
配置keepalived高可用
[root@master01 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.229.10/24
}
}
[root@master01 ~]# systemctl start keepalived
[root@master01 ~]# systemctl enable keepalived
[root@master02 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.229.10/24
}
}
[root@master02 ~]# systemctl start keepalived
[root@master02 ~]# systemctl enable keepalived
[root@master03 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.229.10/24
}
}
[root@master03 ~]# systemctl start keepalived
[root@master03 ~]# systemctl enable keepalived
特别说明
所有机器都必须有镜像
每次部署都会有版本更新,具体版本要求,运行初始化过程失败会有版本提示
kubeadm的版本和镜像的版本必须是对应的
阿里仓库下载
准备k8s1.22.2 所需要的镜像
[root@master]# kubeadm config images list --kubernetes-version=v1.22.2
使用以下命令从阿里云仓库拉取镜像-----可选
[root@master]# kubeadm config images pull --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers --cri-socket=unix:///var/run/cri-dockerd.sock
[root@k8s-master ~]# cat pull.sh
#!/usr/bin/bash
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.22.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.22.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.8.4
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.0-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5
下载完了之后需要将aliyun下载下来的所有镜像打成k8s.gcr.io/kube-controller-manager:v1.20.2这样的tag
[root@k8s-master ~]# cat tag.sh
#!/usr/bin/bash
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.22.2 k8s.gcr.io/kube-controller-manager:v1.22.2
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.2 k8s.gcr.io/kube-proxy:v1.22.2
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.2 k8s.gcr.io/kube-apiserver:v1.22.2
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.22.2 k8s.gcr.io/kube-scheduler:v1.22.2
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.8.4 k8s.gcr.io/coredns/coredns:v1.8.4
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.0-0 k8s.gcr.io/etcd:3.5.0-0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 k8s.gcr.io/pause:3.5
版本号不用变
配置master节点
在其中一台master节点上面操作即可
--control-plane-endpoint= 指定vip+nginx的端口
[root@master01 ~]# kubeadm init --kubernetes-version=v1.22.2 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=172.16.229.28 --control-plane-endpoint=172.16.229.10:8443 --ignore-preflight-errors=Swap
[init] Using Kubernetes version: v1.22.2
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 26.0.0. Latest validated version: 20.10
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master01] and IPs [10.96.0.1 172.16.229.28 172.16.229.10]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master01] and IPs [172.16.229.28 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master01] and IPs [172.16.229.28 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 10.507989 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.22" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master01 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: 51rolq.qfofvjoz41t8ch1t
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 172.16.229.10:8443 --token 51rolq.qfofvjoz41t8ch1t \
--discovery-token-ca-cert-hash sha256:2f8521a52b3c9e8a929effac7a6547d8b9c2db3a5ddc67f240b41b6ad16a339f \
--control-plane #做为主节点组成高可用集群时使用
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.16.229.10:8443 --token 51rolq.qfofvjoz41t8ch1t \
--discovery-token-ca-cert-hash sha256:2f8521a52b3c9e8a929effac7a6547d8b9c2db3a5ddc67f240b41b6ad16a339f #node节点加入集群使用的
#按照上面的信息提示,对应的步骤即可
#上面初始化完成master01节点之后会提示你在master节点或node节点执行对应的命令来将master节点或node节点加入k8s集群
#注意:这段kubeamd join命令的token只有24h,24h就过期,需要执行kubeadm token create --print-join-command 重新生成token,但是
#要注意,重新生成的加入集群命令默认是node节点角色加入的,如果新节点是作为master角色加入集群,需要在打印出来的命令后面添加--control-plane 参数再执行。
[root@master01 ~]# mkdir -p $HOME/.kube
[root@master01 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master01 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
master02与master03加入集群
1.在master02、master03节点上创建目录,用户存放证书
[root@master02 ~]# mkdir /etc/kubernetes/pki/etcd -p
[root@master03 ~]# mkdir /etc/kubernetes/pki/etcd -p
2.在master01节点上,将master01节点上的证书拷贝到master02、master03节点上
[root@master01 ~]# scp -rp /etc/kubernetes/pki/ca.* master02:/etc/kubernetes/pki/
[root@master01 ~]# scp -rp /etc/kubernetes/pki/sa.* master02:/etc/kubernetes/pki/
[root@master01 ~]# scp -rp /etc/kubernetes/pki/front-proxy-ca.* master02:/etc/kubernetes/pki/
[root@master01 ~]# scp -rp /etc/kubernetes/pki/etcd/ca.* master02:/etc/kubernetes/pki/etcd/
[root@master01 ~]# scp -rp /etc/kubernetes/admin.conf master02:/etc/kubernetes/
[root@master01 ~]# scp -rp /etc/kubernetes/pki/ca.* master03:/etc/kubernetes/pki/
[root@master01 ~]# scp -rp /etc/kubernetes/pki/sa.* master03:/etc/kubernetes/pki/
[root@master01 ~]# scp -rp /etc/kubernetes/pki/front-proxy-ca.* master03:/etc/kubernetes/pki/
[root@master01 ~]# scp -rp /etc/kubernetes/pki/etcd/ca.* master03:/etc/kubernetes/pki/etcd/
[root@master01 ~]# scp -rp /etc/kubernetes/admin.conf master03:/etc/kubernetes/
3.由上面初始成功的信息提示,复制粘贴命令到master02、master03节点执行即可
master02操作:
[root@master02 ~]# kubeadm join 172.16.229.10:8443 --token 51rolq.qfofvjoz41t8ch1t \
> --discovery-token-ca-cert-hash sha256:2f8521a52b3c9e8a929effac7a6547d8b9c2db3a5ddc67f240b41b6ad16a339f \
> --control-plane
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 26.0.0. Latest validated version: 20.10
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master02] and IPs [10.96.0.1 172.16.229.29 172.16.229.10]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master02] and IPs [172.16.229.29 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master02] and IPs [172.16.229.29 127.0.0.1 ::1]
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/admin.conf"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
The 'update-status' phase is deprecated and will be removed in a future release. Currently it performs no operation
[mark-control-plane] Marking the node master02 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master02 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
[root@master02 ~]# mkdir -p $HOME/.kube
[root@master02 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master02 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
master03操作:
[root@master03 ~]# kubeadm join 172.16.229.10:8443 --token 51rolq.qfofvjoz41t8ch1t \
> --discovery-token-ca-cert-hash sha256:2f8521a52b3c9e8a929effac7a6547d8b9c2db3a5ddc67f240b41b6ad16a339f \
> --control-plane
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 26.0.0. Latest validated version: 20.10
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master03] and IPs [10.96.0.1 172.16.229.30 172.16.229.10]
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master03] and IPs [172.16.229.30 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master03] and IPs [172.16.229.30 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/admin.conf"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
The 'update-status' phase is deprecated and will be removed in a future release. Currently it performs no operation
[mark-control-plane] Marking the node master03 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master03 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
[root@master03 ~]# mkdir -p $HOME/.kube
[root@master03 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master03 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
Node-1与Node-2加入到集群
#node节点直接执行命令即可,不需要做什么配置
#在node-1、node-2节点执行下面命令
[root@node-1 ~]# kubeadm join 172.16.229.10:8443 --token 51rolq.qfofvjoz41t8ch1t \
> --discovery-token-ca-cert-hash sha256:2f8521a52b3c9e8a929effac7a6547d8b9c2db3a5ddc67f240b41b6ad16a339f
......
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
[root@node-2 ~]# kubeadm join 172.16.229.10:8443 --token 51rolq.qfofvjoz41t8ch1t \
> --discovery-token-ca-cert-hash sha256:2f8521a52b3c9e8a929effac7a6547d8b9c2db3a5ddc67f240b41b6ad16a339f
......
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
检查集群
以上,就创建了3个master节点+2个node节点的k8s集群,在任意一个master节点检查集群:
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 NotReady control-plane,master 20m v1.22.2
master02 NotReady control-plane,master 5m56s v1.22.2
master03 NotReady control-plane,master 5m9s v1.22.2
node-1 NotReady <none> 2m10s v1.22.2
node-2 NotReady <none> 117s v1.22.2
[root@master01 ~]# kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://172.16.229.10:8443 #监听集群的ip+端口
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
配置使用网络插件
在一个主节点操作即可:
[root@master01 ~]# cd ~ && mkdir flannel && cd flannel
[root@master01 flannel]# ls
kube-flannel.yml
修改配置文件kube-flannel.yml:
[root@master01 flannel]# vim kube-flannel.yml
此处的ip配置要与上面kubeadm的pod-network一致,本来就一致,不用改
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
# 目前需要在kube-flannel.yml中使用--iface参数指定集群主机内网网卡的名称,否则可能会出现dns无法解析。容器无法通信的情况。
#需要将kube-flannel.yml下载到本地,
# flanneld启动参数加上--iface=<iface-name>
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.12.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=ens33
#- --iface=eth0
⚠️⚠️⚠️--iface=ens33 的值,是你当前的网卡,或者可以指定多网卡
启动:
[root@master01 flannel]# kubectl apply -f ~/flannel/kube-flannel.yml
[root@master01 flannel]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 22h v1.22.2
master02 Ready control-plane,master 21h v1.22.2
master03 Ready control-plane,master 21h v1.22.2
node-1 Ready <none> 21h v1.22.2
node-2 Ready <none> 21h v1.22.2
[root@master01 flannel]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-78fcd69978-q7t4c 1/1 Running 0 22h
coredns-78fcd69978-wzv22 1/1 Running 0 22h
etcd-master01 1/1 Running 3 (20h ago) 22h
etcd-master02 1/1 Running 1 (20h ago) 21h
etcd-master03 1/1 Running 1 (20h ago) 21h
kube-apiserver-master01 1/1 Running 3 (20h ago) 22h
kube-apiserver-master02 1/1 Running 1 (20h ago) 21h
kube-apiserver-master03 1/1 Running 2 (20h ago) 21h
kube-controller-manager-master01 1/1 Running 4 (20h ago) 22h
kube-controller-manager-master02 1/1 Running 1 (20h ago) 21h
kube-controller-manager-master03 1/1 Running 1 (20h ago) 21h
kube-proxy-2g5pj 1/1 Running 1 (20h ago) 22h
kube-proxy-2p579 1/1 Running 3 (20h ago) 21h
kube-proxy-58g4q 1/1 Running 1 (20h ago) 21h
kube-proxy-jr4nv 1/1 Running 2 (20h ago) 21h
kube-proxy-z887s 1/1 Running 1 (20h ago) 21h
kube-scheduler-master01 1/1 Running 4 (20h ago) 22h
kube-scheduler-master02 1/1 Running 1 (20h ago) 21h
kube-scheduler-master03 1/1 Running 1 (20h ago) 21h
[root@master01 flannel]# kubectl get pod -n kube-flannel
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-96r5v 1/1 Running 0 29s
kube-flannel-ds-9x9sn 1/1 Running 0 29s
kube-flannel-ds-sp954 1/1 Running 0 29s
kube-flannel-ds-x68pp 1/1 Running 0 29s
kube-flannel-ds-zv9m9 1/1 Running 0 29s
查看:
# kubectl get pods --namespace kube-system
# kubectl get service
# kubectl get svc --namespace kube-system
只有网络插件也安装配置完成之后,才能会显示为ready状态
安装Metrics Server
Metrics Server 是 Kubernetes 内置的高效的容器资源指标来源。Metrics Server 可以帮助我们监控集群中节点和容器的资源使用情况。
下载地址,并查看对应的k8s使用的版本
https://github.com/kubernetes-sigs/metrics-server/
[root@master01 ~]# wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.7.1/components.yaml
[root@master01 ~]# vim components.yaml #修改配置文件
1、修改镜像:
registry.k8s.io/metrics-server/metrics-server:v0.7.1
修改为
registry.aliyuncs.com/google_containers/metrics-server:v0.7.1
2.禁用证书验证,在134行左右添加
spec:
containers:
- args:
- --kubelet-insecure-tls #禁用证书验证
- --cert-dir=/tmp
- --secure-port=10250
[root@master01 ~]# kubectl apply -f components.yaml
[root@master01 ~]# kubectl get pod -n kube-system -o wide | grep metrics-server
metrics-server-5c58655c68-pl4dt 1/1 Running 0 104s 10.244.4.2 node-2 <none> <none>
查看集群内部的资源使用
1.查看node节点的内存与cpu的使用
[root@master01 ~]# kubectl top nodes node-1
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node-1 183m 9% 489Mi 56%
2.查看pod的内存与cpu的使用
[root@master01 ~]# kubectl top pod -A
3.查看使用cpu最高的pod
[root@master01 ~]# kubectl top pod --sort-by=cpu -A
部署DASHBOARD应用
注意:最后部署成功之后,因为有5种方式访问dashboard:我们这里只使用Nodport方式访问
1. Nodport方式访问dashboard,service类型改为NodePort
2. loadbalacer方式,service类型改为loadbalacer
3. Ingress方式访问dashboard
4. API server方式访问 dashboard
5. kubectl proxy方式访问dashboard
1.下载yaml文件:
可以自己下载,也可以使用子目录中的内容自己创建
[root@kub-k8s-master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
将名称空间修改为默认system
[root@kub-k8s-master ~]# sed -i '/namespace/ s/kubernetes-dashboard/kube-system/g' recommended.yaml
2.下载镜像
由于yaml配置文件中指定的镜像
三台机器都下载
[root@kub-k8s-master ~]# docker pull kubernetesui/dashboard:v2.7.0
[root@kub-k8s-master ~]# docker pull kubernetesui/metrics-scraper:v1.0.8
3.修改yaml文件
NodePort方式:为了便于本地访问,修改yaml文件,将service改为NodePort 类型:
[root@kub-k8s-master ~]# vim recommended.yaml
...
30 ---
31
32 kind: Service
33 apiVersion: v1
34 metadata:
35 labels:
36 k8s-app: kubernetes-dashboard
37 name: kubernetes-dashboard
38 namespace: kube-system
39 spec:
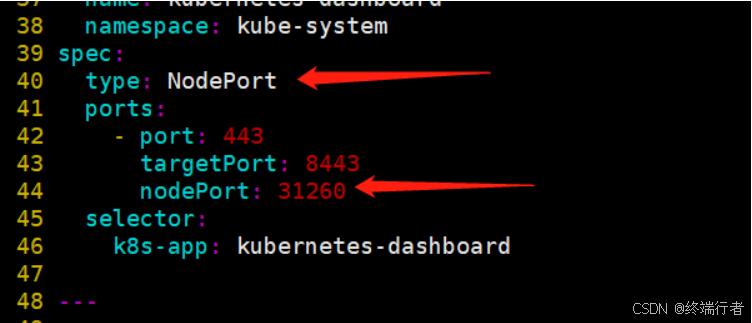
40 type: NodePort #增加type: NodePort
41 ports:
42 - port: 443
43 targetPort: 8443
44 nodePort: 31260 #增加nodePort: 31260
45 selector:
46 k8s-app: kubernetes-dashboard
47
48 ---
4.创建应用:
[root@kub-k8s-master ~]# kubectl apply -f recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
查看Pod 的状态为running说明dashboard已经部署成功:
[root@master01 ~]# kubectl get pod --namespace=kube-system -o wide | grep dashboard
dashboard-metrics-scraper-7c857855d9-kh2gz 1/1 Running 0 9s 10.244.0.2 master01 <none> <none>
kubernetes-dashboard-5bdbb67675-vzcx9 1/1 Running 0 9s 10.244.2.2 master03 <none> <none>
Dashboard 会在 kube-system namespace 中创建自己的 Deployment 和 Service:
[root@master01 ~]# kubectl get deployment kubernetes-dashboard --namespace=kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
kubernetes-dashboard 1/1 1 1 37s
[root@master01 ~]# kubectl get service kubernetes-dashboard --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.102.184.169 <none> 443:31260/TCP 52s
5.访问dashboard
官方参考文档:
https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/#accessing-the-dashboard-ui
查看service,TYPE类型已经变为NodePort,端口为31620
[root@kub-k8s-master ~]# kubectl get service -n kube-system | grep dashboard
kubernetes-dashboard NodePort 10.108.97.179 <none> 443:31260/TCP 101s
查看dashboard运行在那台机器上面
[root@kub-k8s-master ~]# kubectl get pods -n kube-system -o wide
通过浏览器访问:https://master:31620
因为我的应用运行在master上,又是NodePort方式,所以直接访问master的地址
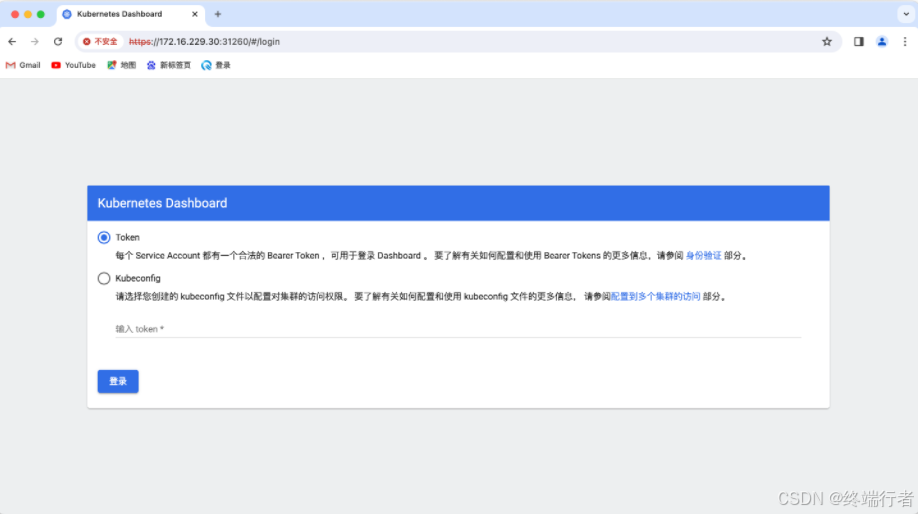
Dashboard 支持 Kubeconfig 和 Token 两种认证方式,这里选择Token认证方式登录:
上面的Token先空着,不要往下点,接下来制作token
创建登录用户
官方参考文档:
https://github.com/kubernetes/dashboard/wiki/Creating-sample-user
创建dashboard-adminuser.yaml:
[root@kub-k8s-master ~]# vim dashboard-adminuser.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
执行yaml文件:
[root@kub-k8s-master ~]# kubectl create -f dashboard-adminuser.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
说明:上面创建了一个叫admin-user的服务账号,并放在kube-system命名空间下,并将cluster-admin角色绑定到admin-user账户,这样admin-user账户就有了管理员的权限。默认情况下,kubeadm创建集群时已经创建了cluster-admin角色,直接绑定即可。
查看admin-user账户的token
[root@kub-k8s-master ~]# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
Name: admin-user-token-d2hnw
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: f2a2fb2d-fa04-4535-ac62-2d8779716175
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 11 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjBUc19ucm9qbW1zOHJzajhJd2M2bndpWENQSDRrcHRYY3RpWGlMcEhncEUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWQyaG53Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJmMmEyZmIyZC1mYTA0LTQ1MzUtYWM2Mi0yZDg3Nzk3MTYxNzUiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.f-nhR31D2yMXRvjfM7ZzaKcwOEg_3HYNyxQFioqTO3rKcD6cfLZeOZfZlqrxcrHbcclCsNvIR5ReccKE8GqBJcAcAHZZVSpY9pivtfaU08_VlyQxU4ir3wcCZeeJyAeqEjGhxWJVuouQ-zoofImbaa7wKvSIoEr1jnlOP1rQb51vbekZvDCZue03QBcBRB_ZMfObfLDGI8cuVkYZef9cWFQlI4mEL4kNqHAbmSdJBAVS_6MmF0C1ryIXbe_qM_usm6bsawDsBK8mpuDrXJUU5FBI-rW8qUuZ8QrE_vjRuJkjp5iNCrNd_TyBxWX2jBziMmrWKqofZnGN6ZiqvTAJ8w
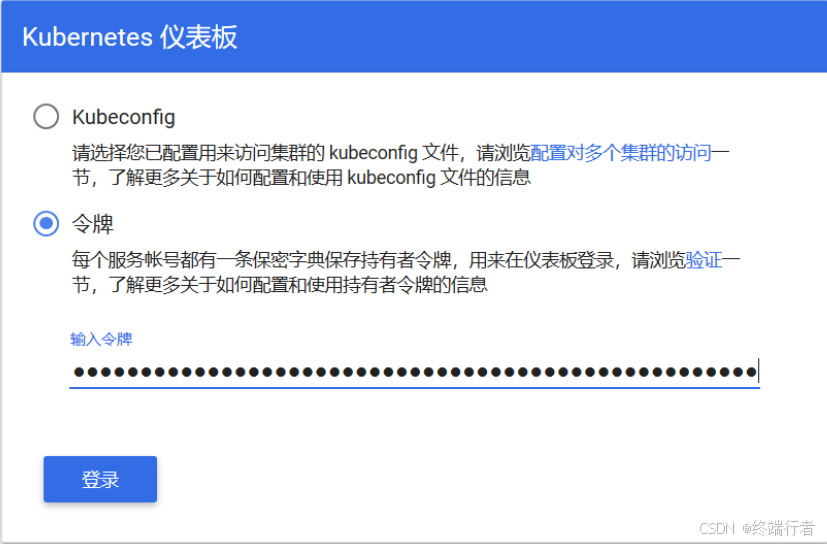
把获取到的Token复制到登录界面的Token输入框中:
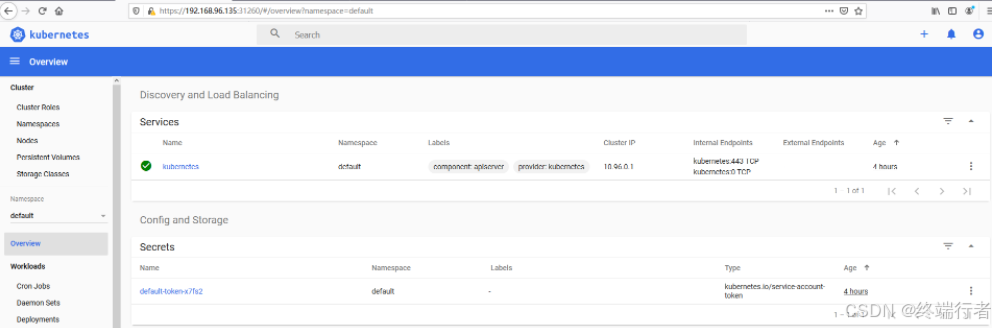
成功登陆dashboard:
使用Dashboard
Dashboard 界面结构分为三个大的区域:
1.顶部操作区,在这里用户可以搜索集群中的资源、创建资源或退出。
2.左边导航菜单,通过导航菜单可以查看和管理集群中的各种资源。菜单项按照资源的层级分为两类:Cluster 级别的资源 ,Namespace 级别的资源 ,默认显示的是 default Namespace,可以进行切换
3.中间主体区,在导航菜单中点击了某类资源,中间主体区就会显示该资源所有实例,比如点击 Pods。

一站式 AI 云服务平台
更多推荐



 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)