
Prometheus -- 打造云原生监控系统,轻松实现智能告警
Prometheus 作为现代监控系统的代表,是容器化和云原生架构中广泛应用的监控解决方案。易于部署和扩展,适用于各种监控场景。灵活的标签系统和强大的查询语言 PromQL。
博客内容总结于B站–林哥Linux
Prometheus是什么
Prometheus 和 Zabbix 都是两种流行的监控解决方案,都有各自的特点和适用场景。
Prometheus专为微服务和云原生架构设计,提供了强大的数据收集、查询和可视化功能。Zabbix 则在传统 IT 基础设施监控中表现出色。
架构概览
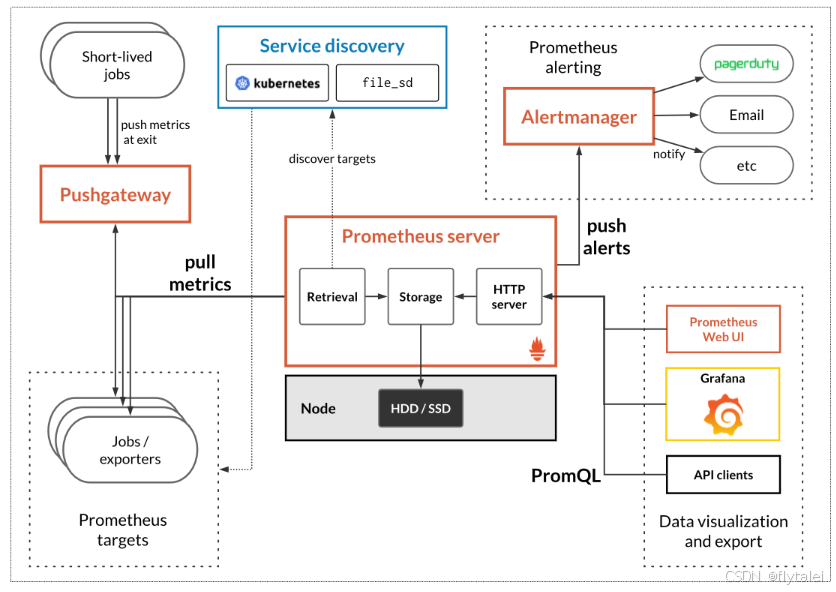
Prometheus 的架构设计为一个独立运行的时间序列数据库(Time Serices Database),
核心组件
Prometheus主要包括以下组件:
1.'Prometheus Server':
负责定期从指定的目标(如服务器、应用)中拉取监控数据,存储在本地'时间序列数据库'中。
2.'Exporters':
每个服务都有相应的 Exporter,通常以 HTTP 端点的方式暴露服务的指标(如 CPU 使用率、内存占用),
收集监控样本数据,并以符合 Prometheus 的数据格式进行展示。
例如:
MySQL exporter 从MySQL数据库中采集各种性能指标,如查询性能、连接数、缓存命中率等
Redis Exporter 监控Redis实例的性能和状态,包括内存使用、客户端连接数、命令统计等
Node Exporter 收集Linux和其他类Unix系统的硬件和操作系统指标:CPU、内存、磁盘、网络使用情况等
Cadvisor 通常用于Kubernetes环境中,监控容器的资源消耗、性能以及状态。
3.'Alertmanager':
用于管理和发送报警。当满足预设报警条件时,会触发报警通知。
4.'Pushgateway':
用于处理短时任务的监控数据,这些任务运行时间短且可能结束时无法直接被 Prometheus 拉取。
可以使用中间网关推送给Prometheus时间序列,
5.'客户端库':
Prometheus 提供多种语言的客户端库(如 Go、Java、Python 等),允许开发者在应用代码中嵌入自定义监控指标。
6.'Web UI 和 Grafana':
Prometheus 自带基本的 Web UI 以查询数据和简单可视化,
Grafana 是更流行的第三方可视化工具,可以展示 Prometheus 的监控数据,生成丰富的监控仪表盘。
安装prometheus
使用docker compose安装prometheus,这里git clone的是林哥Linux的gitee仓库,快去Star吧。
git clone https://gitee.com/linge365/docker-prometheus.git

docker-compose up -d
root@k8s-master1:/data/docker-prometheus# docker-compose up -d
Creating network "dockerprometheus_monitoring" with driver "bridge"
Creating volume "dockerprometheus_prometheus_data" with default driver
Creating volume "dockerprometheus_grafana_data" with default driver
Pulling node_exporter (prom/node-exporter:v1.5.0)...
v1.5.0: Pulling from prom/node-exporter
22b70bddd3ac: Pull complete
....
Digest: sha256:39c642b2b337e38c18e80266fb14383754178202f40103646337722a594d984c
Status: Downloaded newer image for prom/node-exporter:v1.5.0
Pulling alertmanager (prom/alertmanager:v0.25.0)...
v0.25.0: Pulling from prom/alertmanager
b08a0a826235: Pull complete
....
Digest: sha256:fd4d9a3dd1fd0125108417be21be917f19cc76262347086509a0d43f29b80e98
Status: Downloaded newer image for prom/alertmanager:v0.25.0
Pulling cadvisor (google/cadvisor:latest)...
latest: Pulling from google/cadvisor
ff3a5c916c92: Pull complete
....
Digest: sha256:815386ebbe9a3490f38785ab11bda34ec8dacf4634af77b8912832d4f85dca04
Status: Downloaded newer image for google/cadvisor:latest
Pulling prometheus (prom/prometheus:v2.37.6)...
v2.37.6: Pulling from prom/prometheus
4399114b4c59: Pull complete
225de5a6f1e7: Pull complete
Digest: sha256:92ceb93400dd4c887c76685d258bd75b9dcfe3419b71932821e9dcc70288d851
Status: Downloaded newer image for prom/prometheus:v2.37.6
Pulling grafana (grafana/grafana:9.4.3)...
9.4.3: Pulling from grafana/grafana
895e193edb51: Pull complete
....
Digest: sha256:76dcf36e7d2a4110c2387c1ad6e4641068dc78d7780da516d5d666d1e4623ac5
Status: Downloaded newer image for grafana/grafana:9.4.3
Creating alertmanager ...
Creating node-exporter ...
Creating cadvisor ...
Creating alertmanager
Creating node-exporter
Creating node-exporter ... done
Creating prometheus ...
Creating prometheus ... done
Creating grafana ...
Creating grafana ... done

web访问地址
| 应用 | 访问地址 | 备注 |
|---|---|---|
| prometheus | http://192.168.200.100:9090 | 无用户名和密码 |
| grafana | http://192.168.200.100:3000 | admin/ |
| altermanager | http://192.168.200.100:9093 | |
| node-exporter | http://192.168.200.100:9100/metrics |
prometheus
Grafana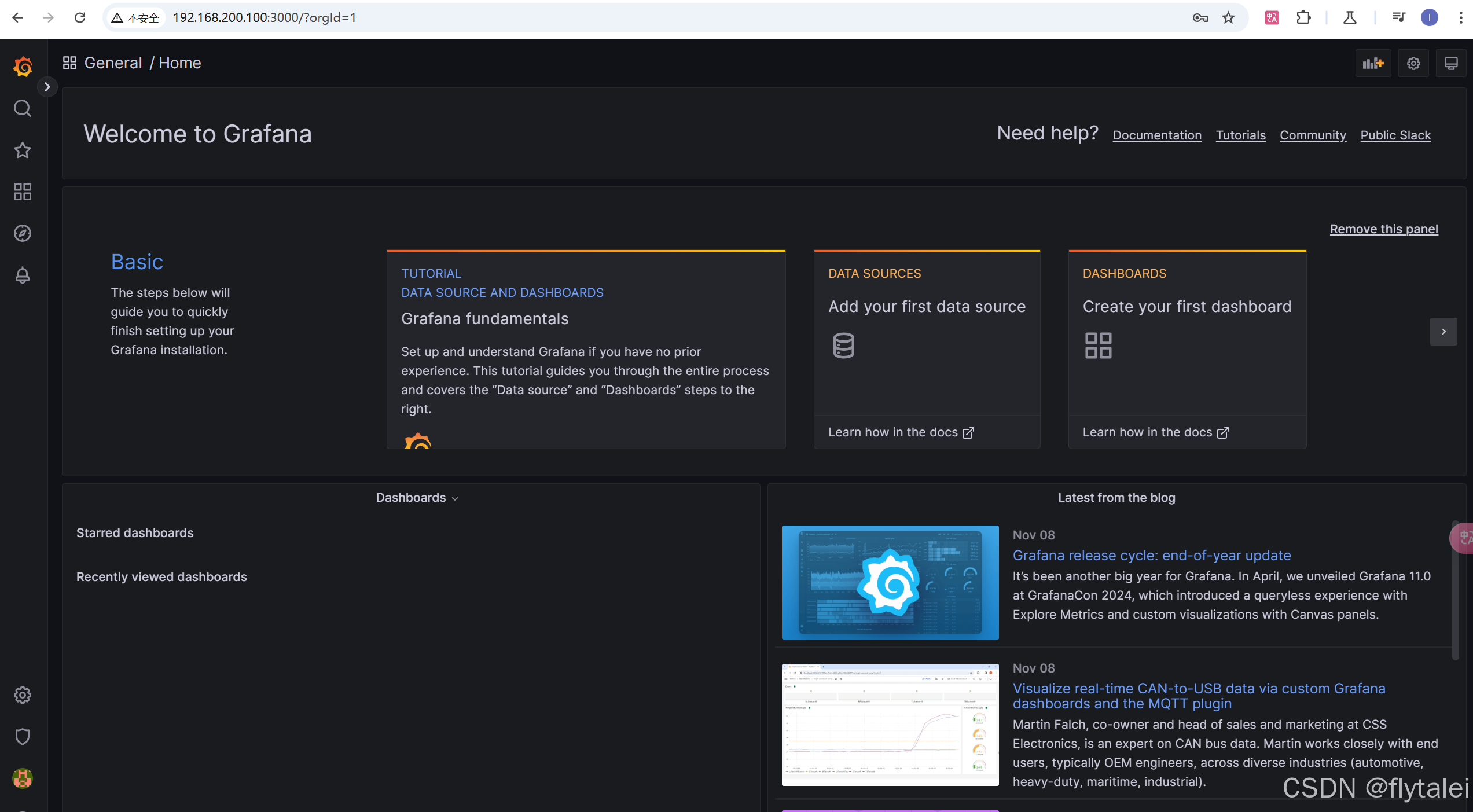
Alertmanager
node-exporter
Grafana添加Prometheus数据源
Grafana添加Prometheus数据源,监控 Node Exporter,也就是收集我192.168.200.100这台主机的CPU、内存、磁盘、网络使用情况。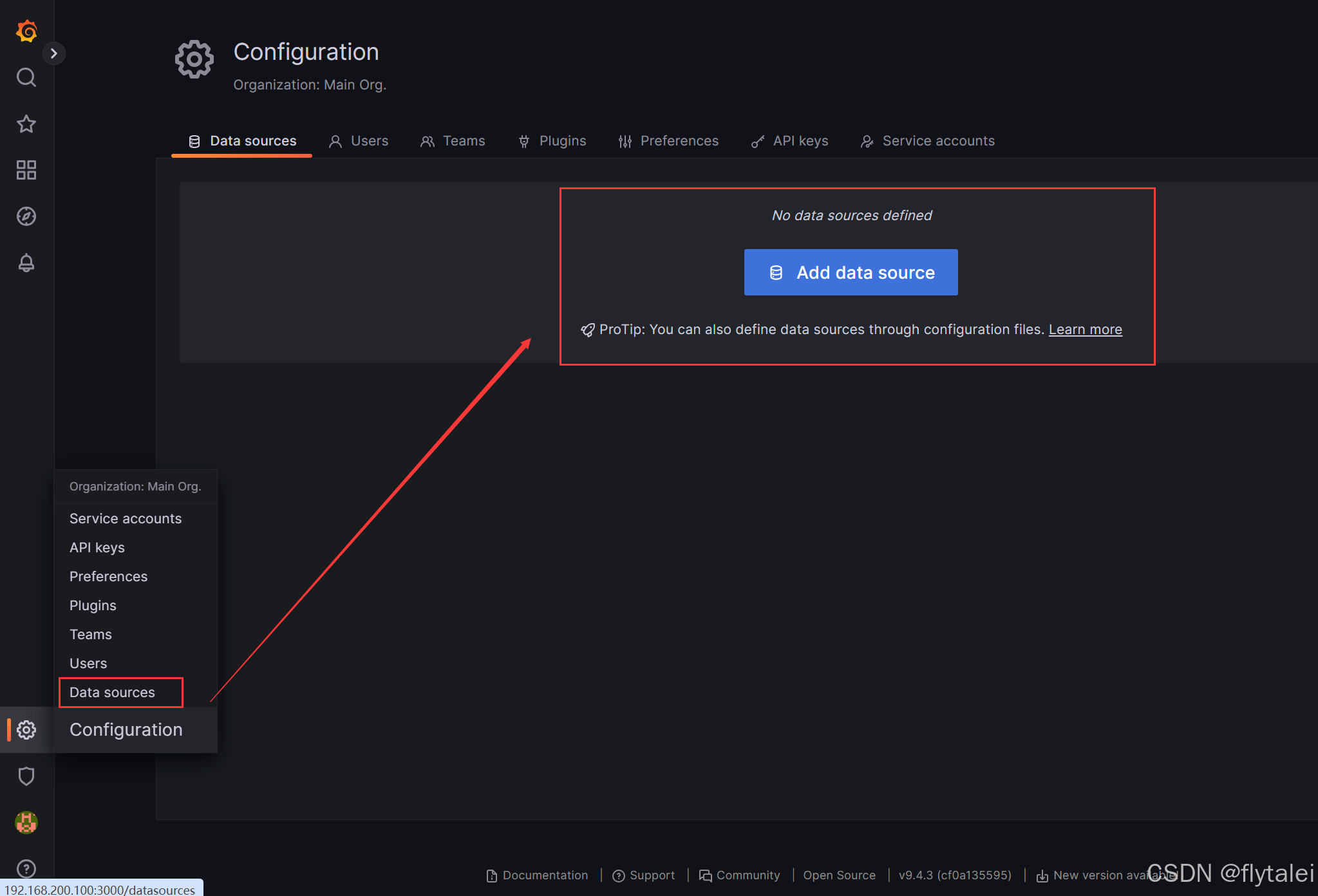
选择Prometheus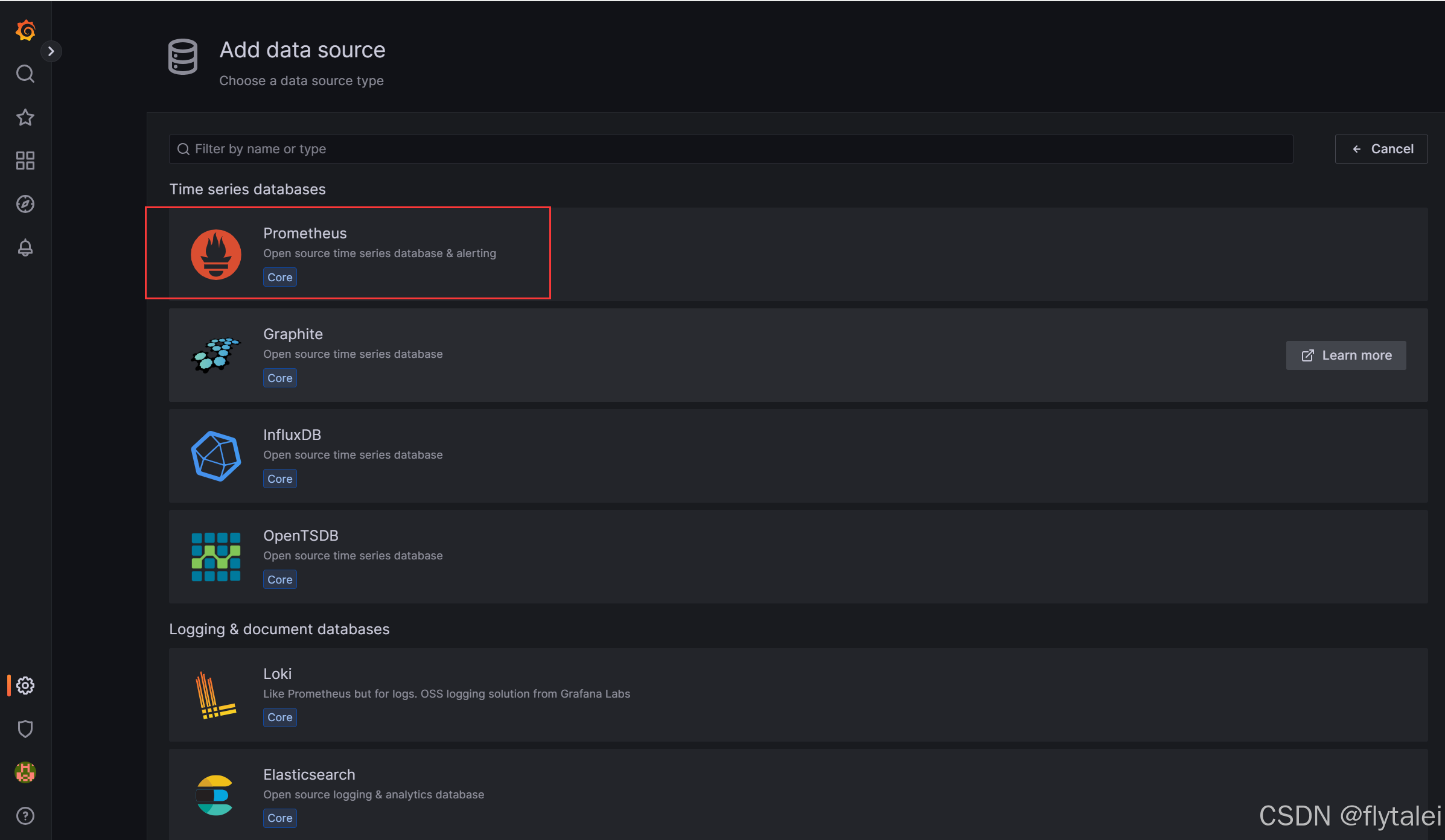
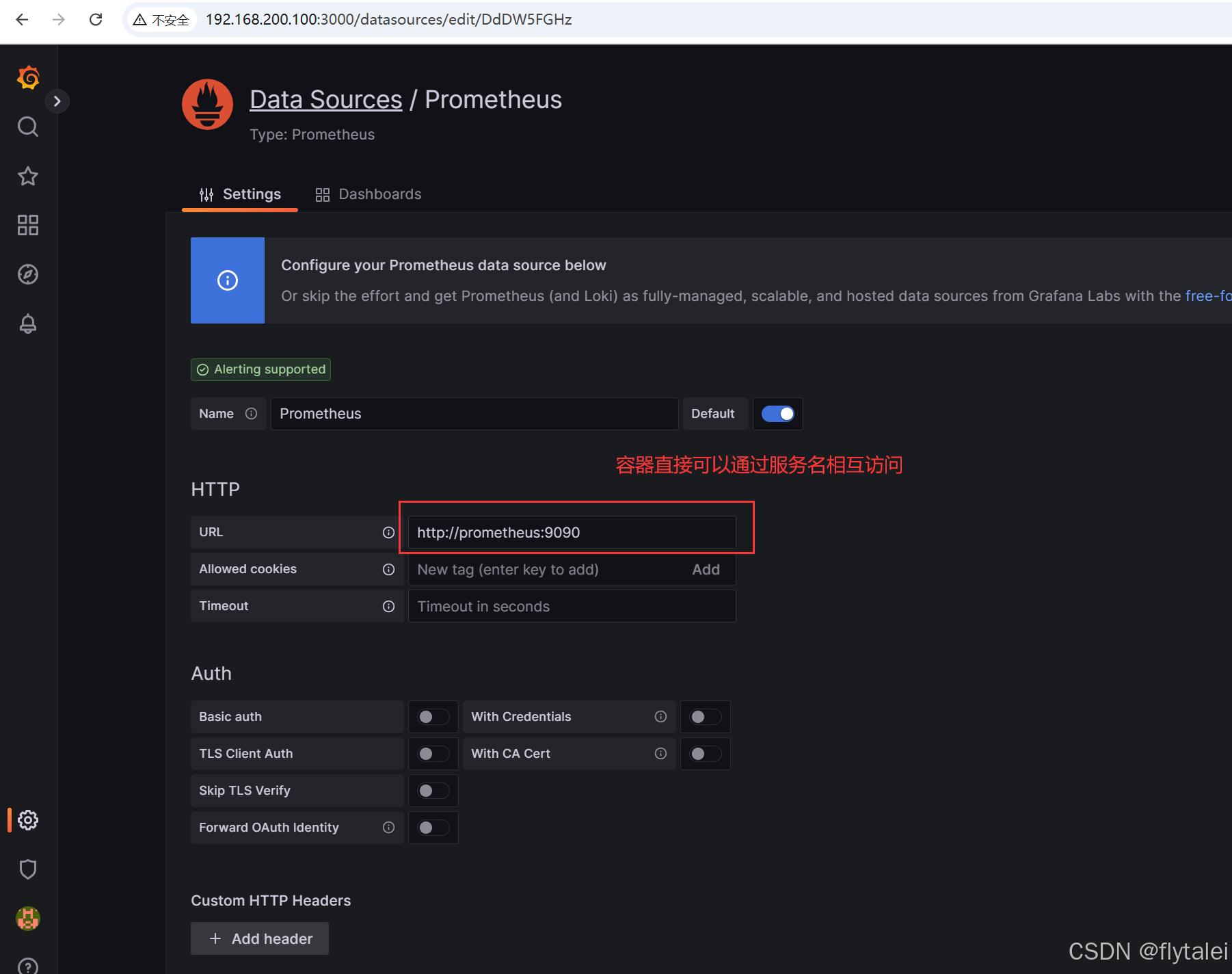
保存测试
保存之后的成功提示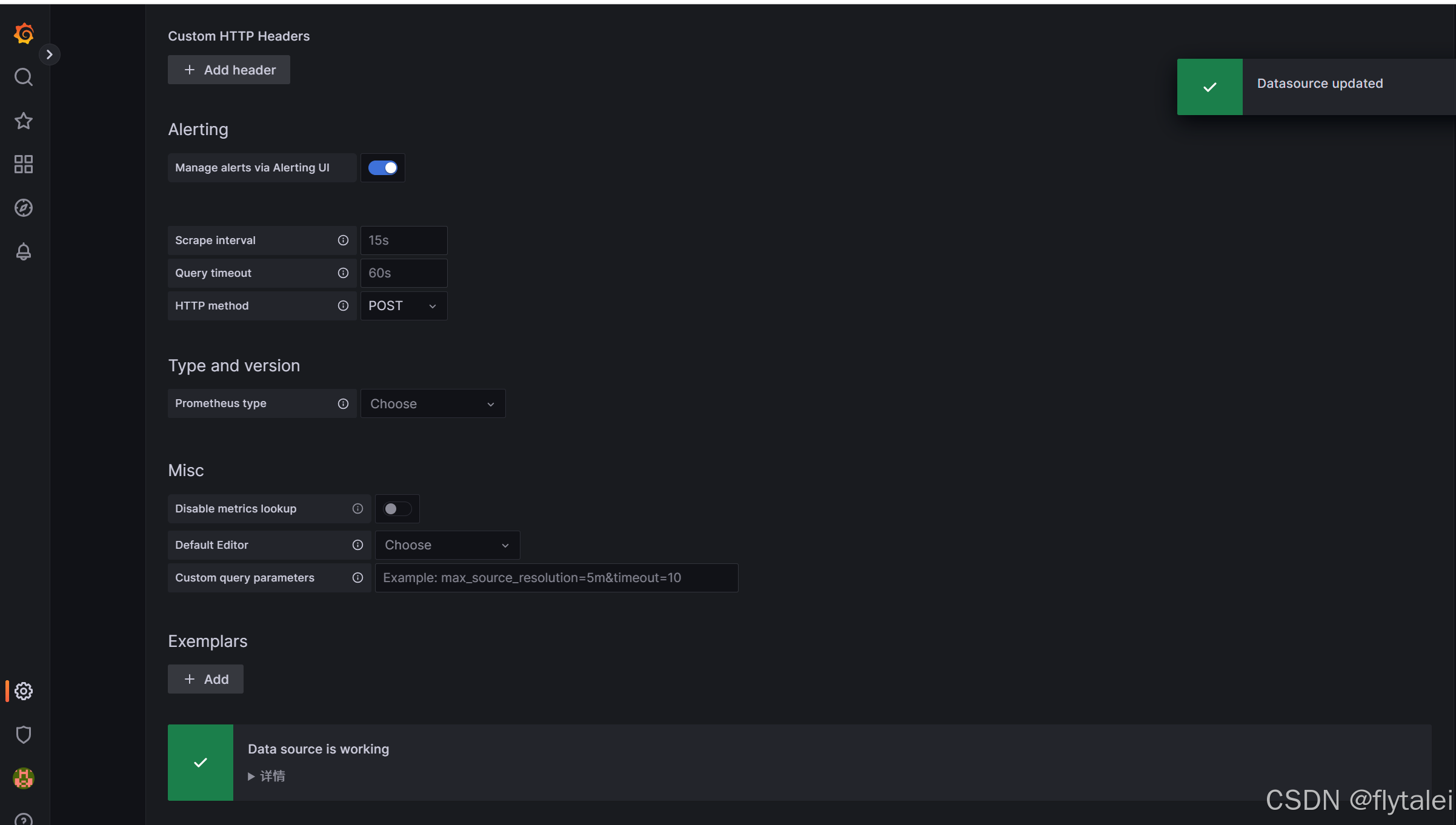
导入Dashbore
https://grafana.com/grafana/dashboards/1860-node-exporter-full/
拷贝ID
粘贴id后,点击Load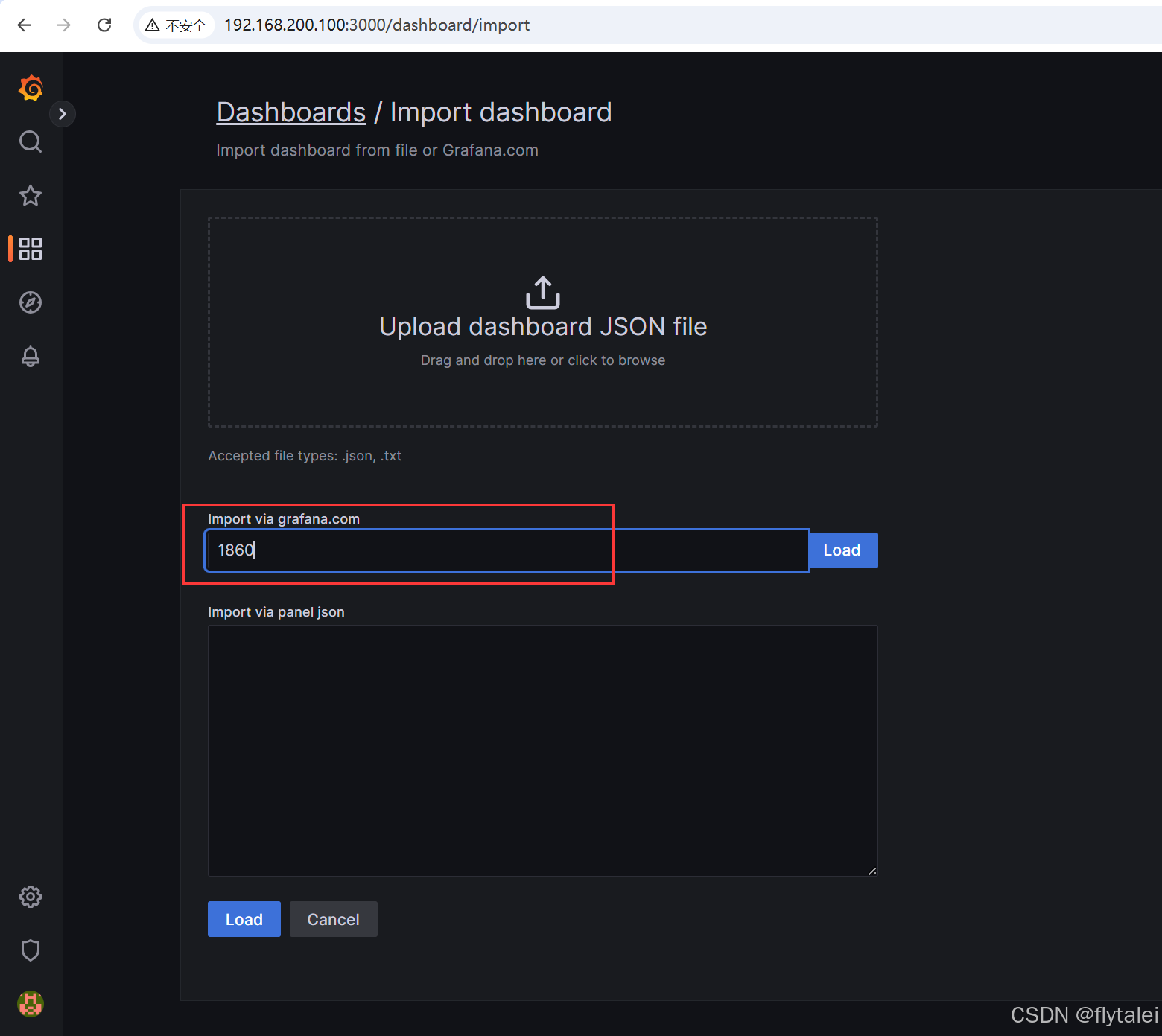
之后选择Prometheus之后点击import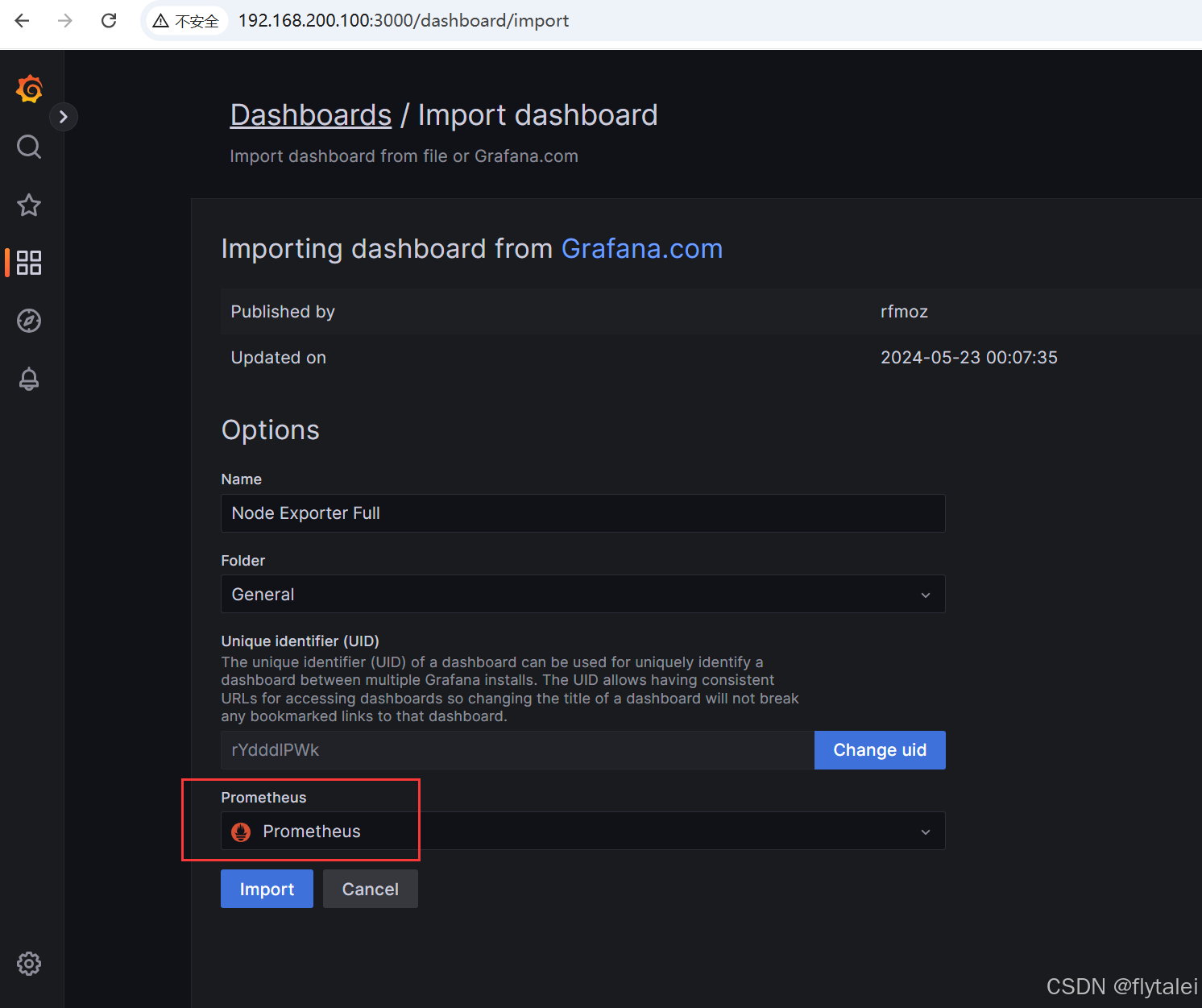
服务器的监控就配置成功啦。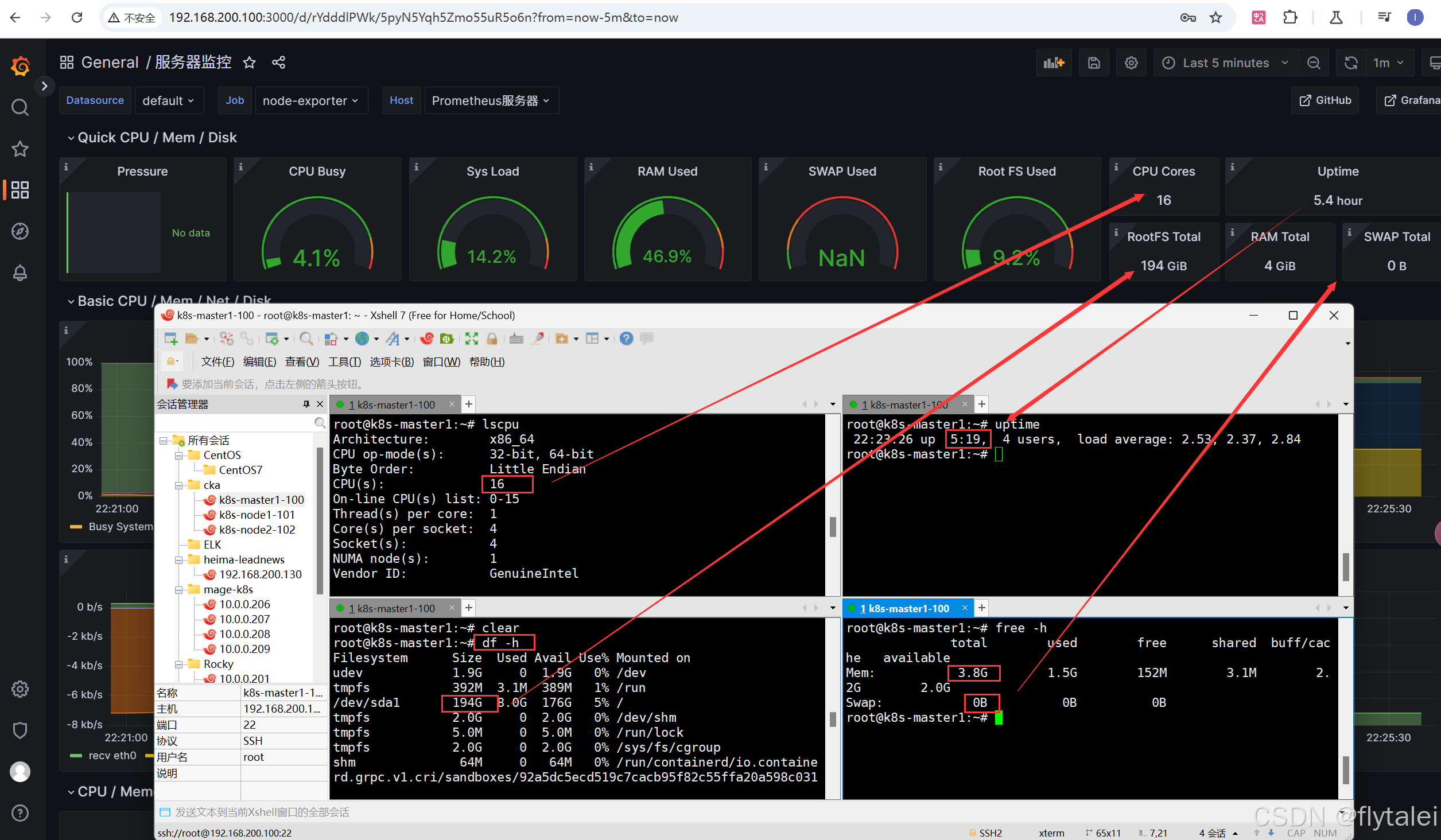
概念理解
1.时间序列
在 Prometheus 中,时间序列是监控和存储数据的核心概念。Prometheus 通过时间序列存储每个监控指标的变化情况,时间序列的独特设计使 Prometheus 能够高效地存储和分析监控数据。
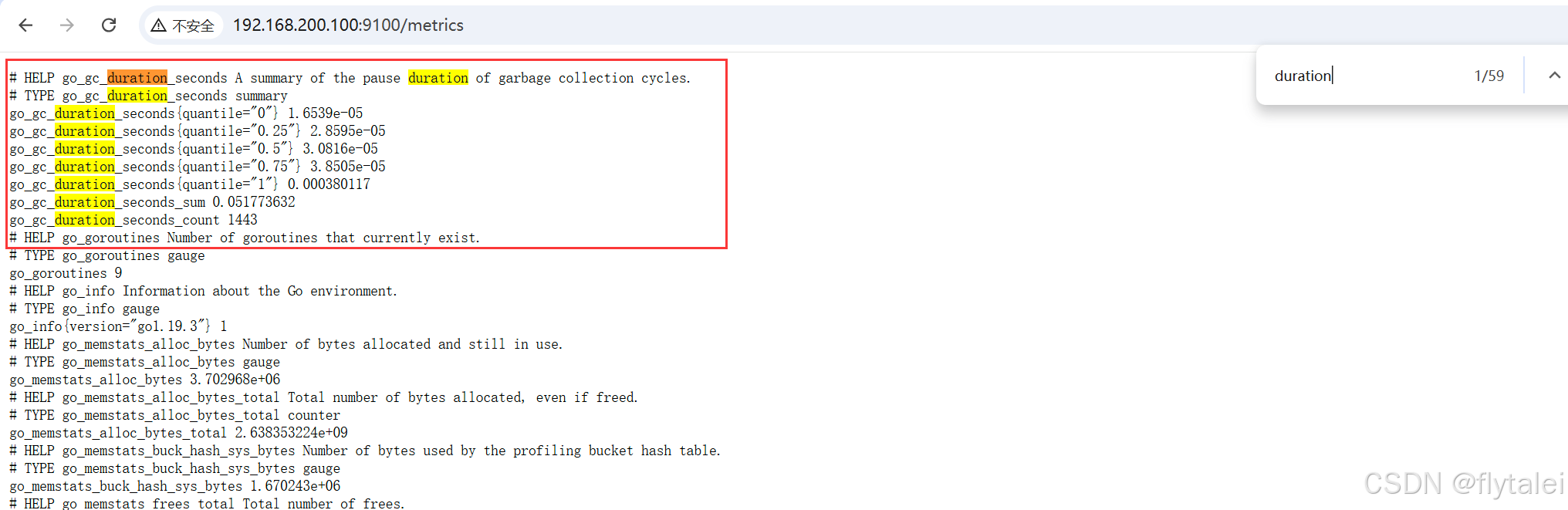
安装好prometheus后会暴露一个/metric的http服务如下截图(相等于安装好了prometheus_exporter),通过配置(默认会加上/metrics), Prometheus就可以采集到这个/metric里面所有监控样本数据。
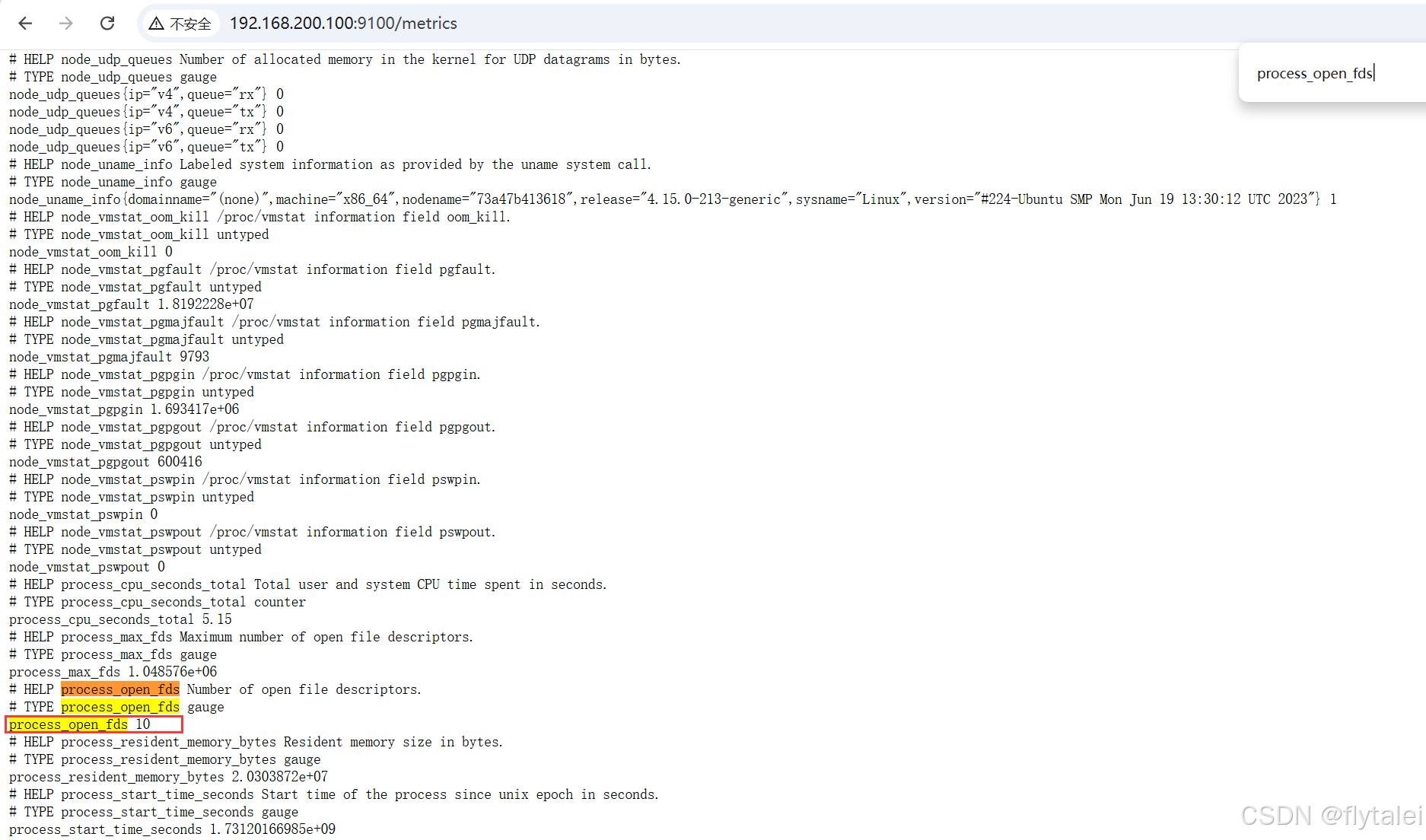
prometheus.yml的配置
# 全局配置
global:
scrape_interval: 15s # 将搜刮间隔设置为每15秒一次。默认是每1分钟一次。
evaluation_interval: 15s # 每15秒评估一次规则。默认是每1分钟一次。
# Alertmanager 配置
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
# 报警(触发器)配置
rule_files:
- "alert.yml"
# 搜刮配置
scrape_configs:
- job_name: 'prometheus'
# 覆盖全局默认值,每15秒从该作业中刮取一次目标
scrape_interval: 15s
static_configs:
- targets: ['localhost:9090']
- job_name: 'alertmanager'
scrape_interval: 15s
static_configs:
- targets: ['alertmanager:9093']
- job_name: 'cadvisor'
scrape_interval: 15s
static_configs:
- targets: ['cadvisor:8080']
labels:
instance: Prometheus服务器
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['node_exporter:9100']
labels:
instance: Prometheus服务器
2.Metric
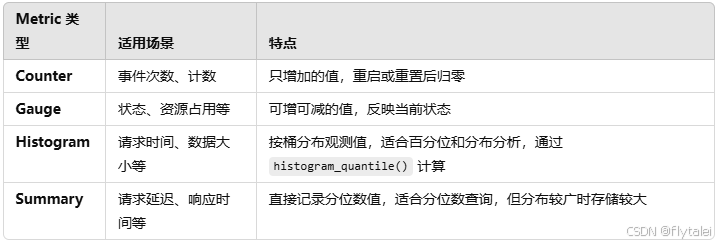
在 Prometheus 中,Metric(指标)类型定义了如何收集、存储和查询监控数据的格式和规则。
Prometheus 共有四种基本的 Metric 类型:
1.Counter(计数器)
2.Gauge(仪表盘)
3.Histogram(直方图)
4.Summary(摘要)
1. Counter(计数器)
计数器是一个只能增加的累积值,通常用于表示某些事件发生的次数,例如 HTTP 请求数量、错误发生次数等。计数器的值从零开始,只会增长,除非重启或重置。
示例
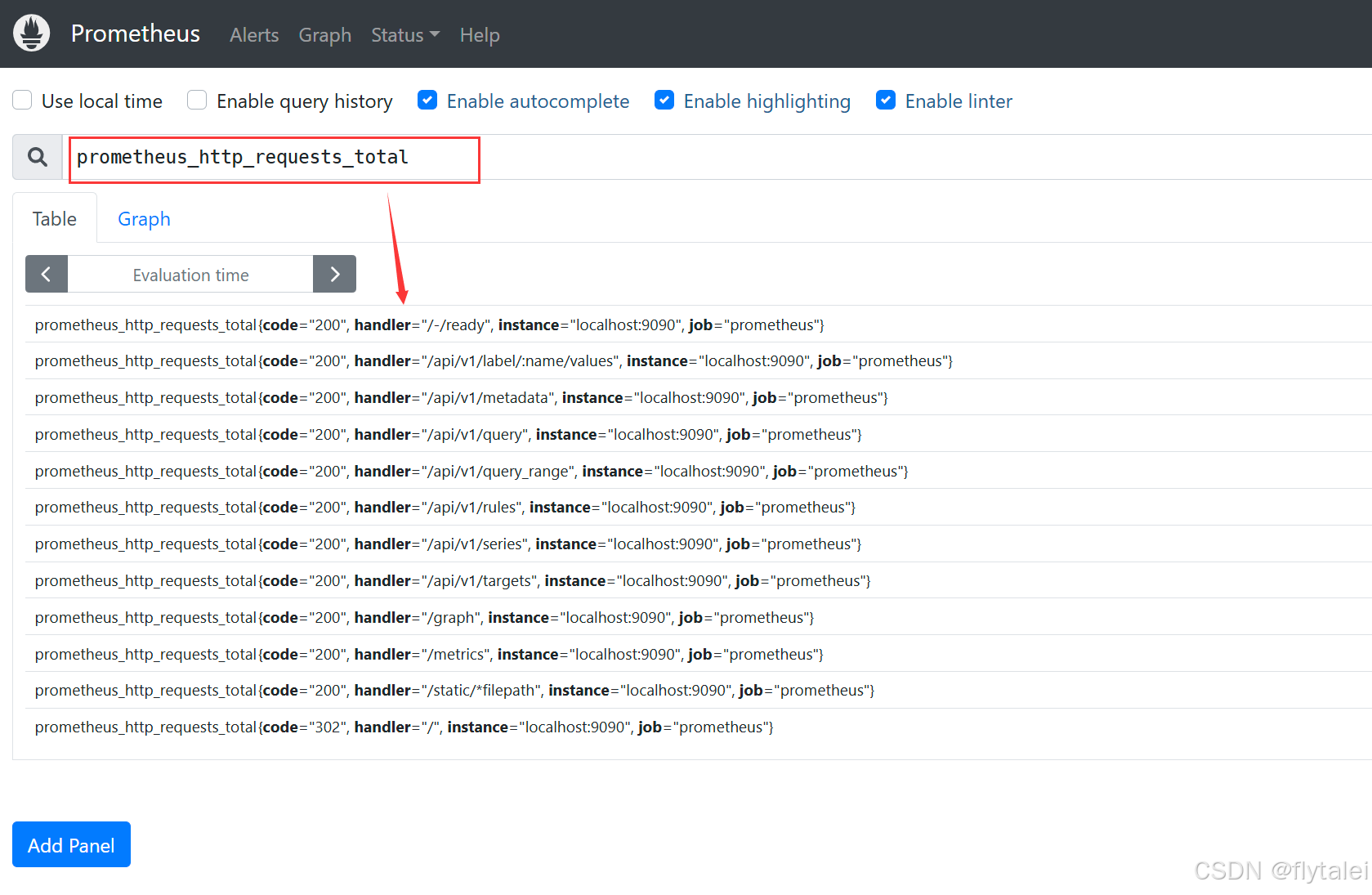
假设我们有一个指标 http_requests_total,用于统计 Web 服务器收到的 HTTP 请求总数:
http_requests_total{method="GET", handler="/home"} = 1250
http_requests_total{method="POST", handler="/login"} = 300
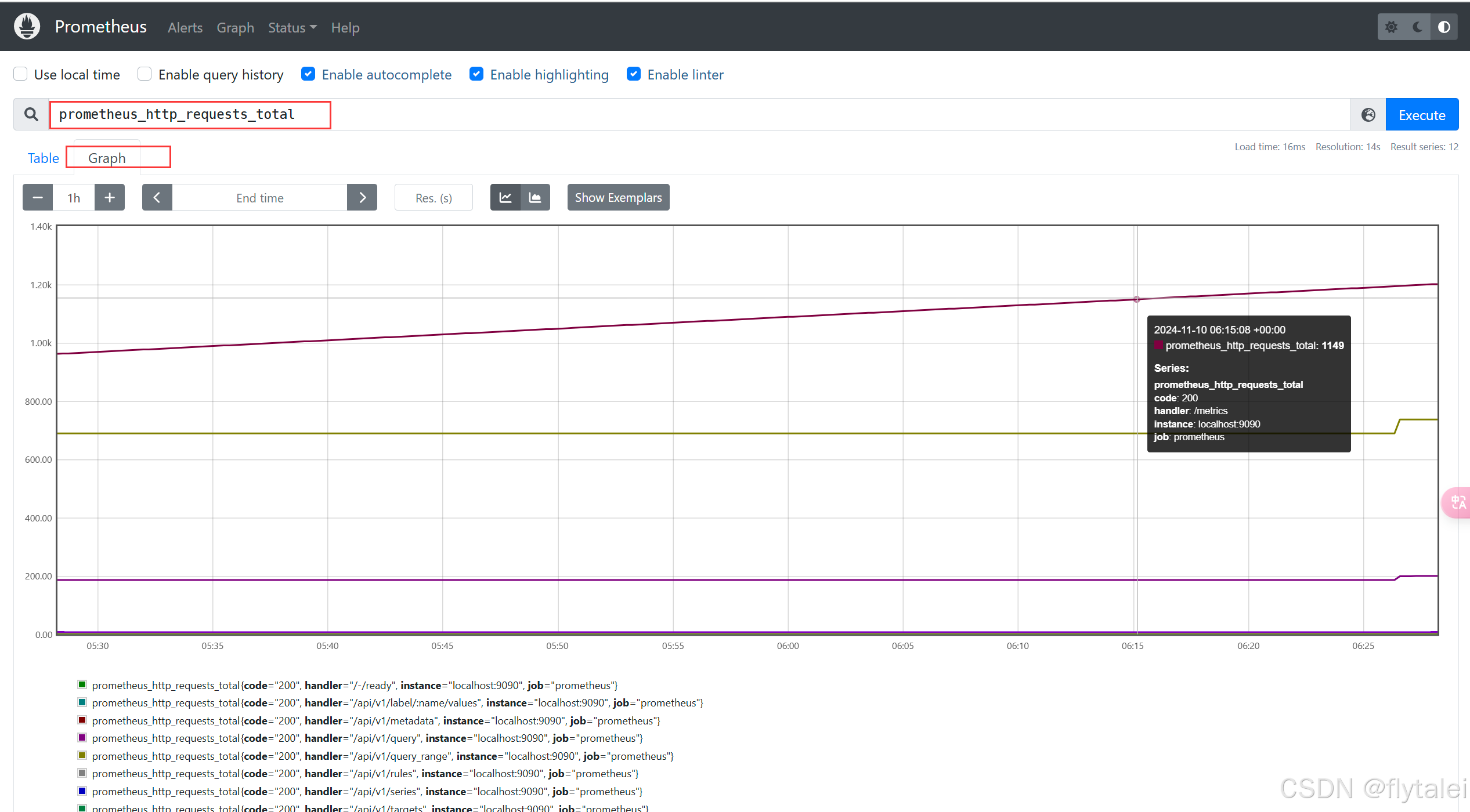
在该示例中,http_requests_total 计数了不同方法和处理程序的请求总数。每次有新的请求时,值会增加。Prometheus 可以使用这个计数器来计算每秒的请求增长率,例如:
rate(prometheus_http_requests_total[1m])
2. Gauge (可增可减仪表盘)
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。
常见指标如:
node_ memory_MemFree bytes(主机当前空闲的物理内存大小)、
node_memory_MemAvailable_bytes(可用内存大小)都是Gauge类型的监控指标。
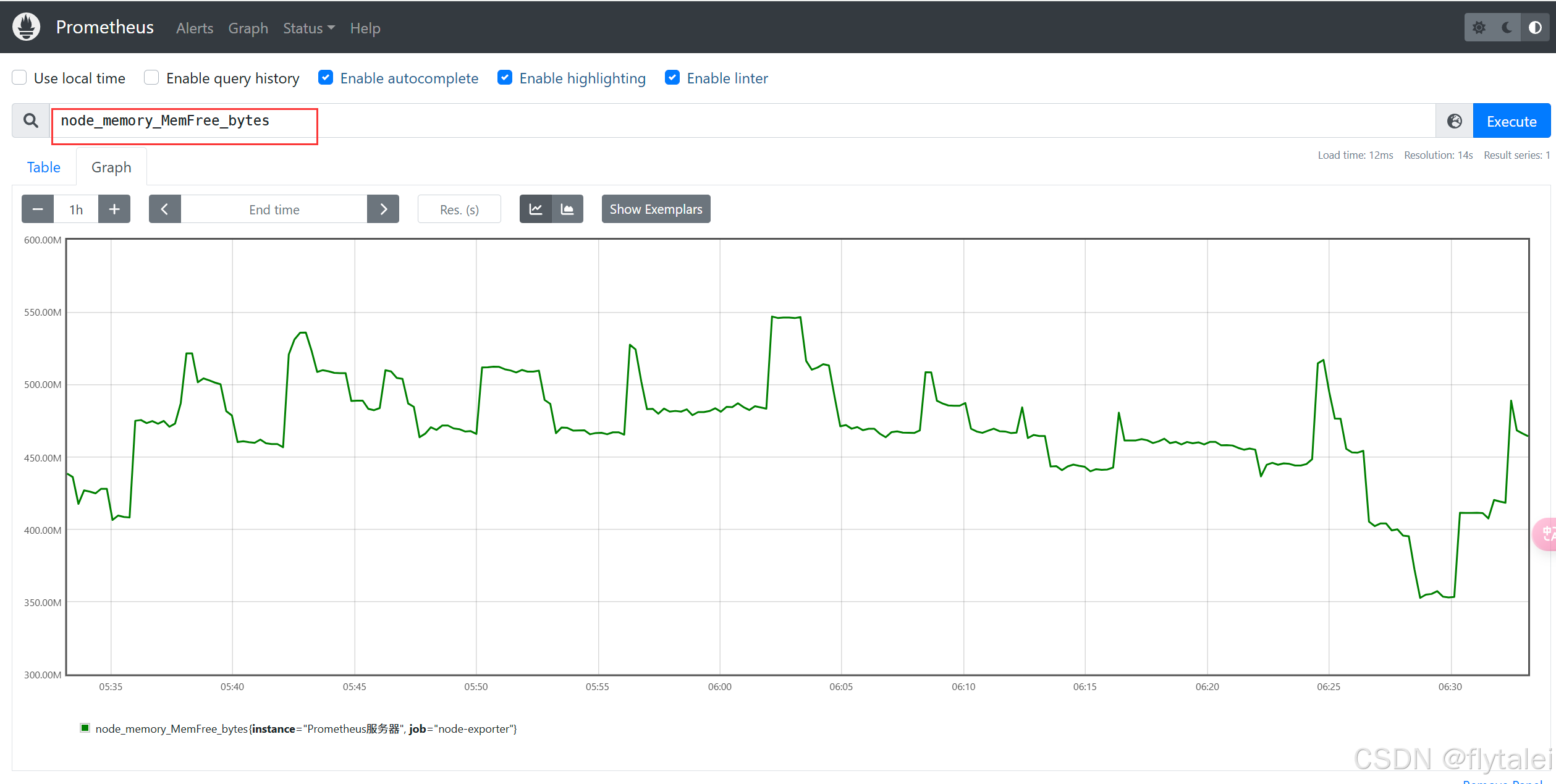
通过Gauge指标,通过PromQL可以直接查看系统的当前空闲物理内存大小:
node_memory_MemFree_bytes
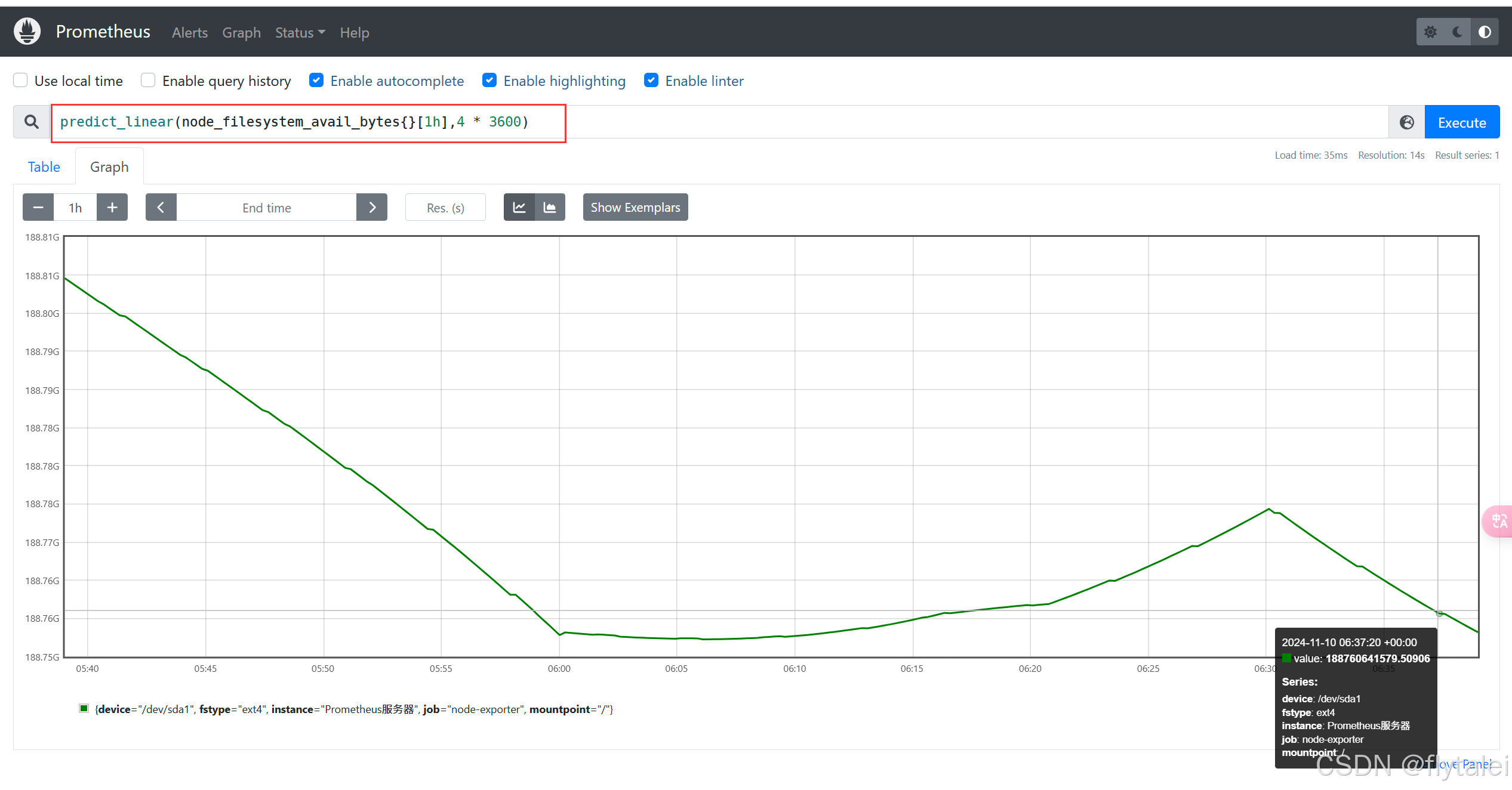
还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例如
预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear(node_filesystem_avail_bytes{}[1h],4 * 3600)
3. Histogram(直方图)
直方图用于将观测值(例如请求持续时间或响应大小)按范围划分成桶(buckets),统计每个范围内的观测数量。直方图适合用于分析请求的分布,例如多少请求的响应时间在 100 毫秒以下、多少请求在 1 秒以上等。
示例
假设有一个 http_request_duration_seconds 直方图指标,用于记录 HTTP 请求的持续时间。
配置的桶范围为 0.1s、0.5s、1s 等。
这个指标将记录在这些时间范围内的请求数量:
http_request_duration_seconds_bucket{le="0.1"} = 2400
http_request_duration_seconds_bucket{le="0.5"} = 4800
http_request_duration_seconds_bucket{le="1"} = 5600
http_request_duration_seconds_bucket{le="+Inf"} = 6000
在该示例中:
2400 表示响应时间在 0.1 秒以内的请求数量。
4800 表示响应时间在 0.5 秒以内的请求数量(包括在 0.1 秒以内的请求)。
6000 表示所有请求的数量(+Inf 表示无限大,即所有请求都包含在内)。
可以使用 histogram_quantile() 函数计算某个百分位的请求持续时间,例如,查询 90% 请求的持续时间在什么范围内:
histogram_quantile(0.9, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))
prometheus_tsdb_wal_fsync_duration_seconds
4. Summary(摘要)
摘要也用于观察值的统计,能够直接提供特定分位数(如 90%、95%、99%)的值,同时记录总请求数和请求值的总和。Summary 和 Histogram 的区别在于 Summary 直接记录了分位数,而 Histogram 则是通过桶计算分位数。
示例
假设有一个指标 http_request_duration_seconds(类型为 Summary),它记录了每个请求的持续时间,Prometheus 可以计算出不同分位数的请求时间:
http_request_duration_seconds{quantile="0.5"} = 0.3
http_request_duration_seconds{quantile="0.9"} = 1.2
http_request_duration_seconds{quantile="0.99"} = 2.5
http_request_duration_seconds_sum = 7500
http_request_duration_seconds_count = 6000
在该示例中:
quantile="0.5" 表示 50% 的请求持续时间小于等于 0.3 秒。
quantile="0.9" 表示 90% 的请求持续时间小于等于 1.2 秒。
quantile="0.99" 表示 99% 的请求持续时间小于等于 2.5 秒。
http_request_duration_seconds_sum 是请求持续时间的总和,用于计算平均请求时间。
http_request_duration_seconds_count 是总请求数。
通过这些分位数值,可以方便地了解请求延迟的分布情况。
3.Exporter
在 Prometheus 监控系统中,Exporter 是一种代理组件,用于将不同系统或服务的指标数据转换为 Prometheus 能够抓取的格式。Exporter 的作用是收集目标服务的指标数据并以 HTTP 接口提供出来,供 Prometheus 抓取并存储,以便进行实时监控和告警。
所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter。而Exporter的一个实例称为target,如下所示,Prometheus通过轮询的方式定期从这些target中获取样本数据: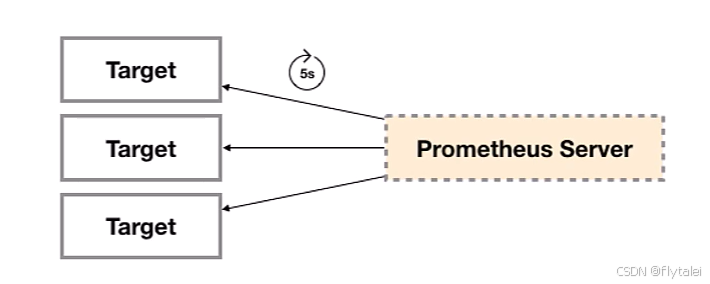
注:安装好Exporter后会暴露一个http://ip:端口/metrics的HTTP服务,通过Prometheus添加配置- targets: ['node_exporter:9100'] (默认会加上/metrics),Prometheus就可以采集到这个http://ip:端口/metrics里面所有监控样本数据
通过 Exporter,Prometheus 可以轻松对 Redis、MySQL、服务器性能等各类服务进行监控,满足复杂的监控需求并可进行告警配置。
Exporter的作用
1.'数据转换和暴露':
许多服务(如 Redis、MySQL、操作系统)本身不具备直接以 Prometheus 格式暴露指标数据的能力,
Exporter 会收集这些服务的内部指标(如系统性能、状态、资源使用情况等),并转换成 Prometheus 能读取的格式。
2.'隔离和保护目标服务':
通过 Exporter 提供数据,而不是让 Prometheus 直接访问服务,有助于隔离 Prometheus 和目标服务。
这样可以减小对目标服务的影响,且不容易因为 Prometheus 频繁抓取而影响服务性能。
3.'数据标准化':
Exporter 负责将不同格式和来源的数据统一为 Prometheus 的数据格式,
使 Prometheus 能够以一致的方式处理各种数据源。
4.'丰富的扩展性':
几乎所有流行的系统和服务都已有现成的 Exporter,可以快速部署并集成到 Prometheus 中,方便运维人员扩展监控能力。
Exporter 示例
以下是一些常见的 Exporter 及其具体作用和应用场景:
1. Node Exporter
作用:用于采集操作系统的各类指标,包括 CPU、内存、磁盘使用、网络流量等。
场景:适用于监控服务器的操作系统性能,广泛应用于 Linux 系统的监控。
示例: 安装 Node Exporter 后,可以获取服务器的 CPU 使用率、内存使用情况等数据。
Prometheus 配置好后可以定期抓取这些指标,实现服务器性能的监控和告警。
2. Redis Exporter
作用:收集 Redis 数据库的性能和状态数据,包括命中率、内存使用量、连接数等。
场景:适用于监控 Redis 数据库的性能,以确保缓存的正常工作和资源使用情况。
示例:配置 Redis Exporter 后,Prometheus 可以抓取 Redis 的命中率指标 (redis_keyspace_hits / (redis_keyspace_hits + redis_keyspace_misses))
并在 Grafana 中展示这些指标,帮助分析缓存的命中效果。
3. MySQL Exporter
作用:收集 MySQL 数据库的性能和资源使用指标,包括查询吞吐量、缓存命中率、连接数、慢查询数量等。
场景:用于监控 MySQL 数据库性能,适合数据库管理员了解数据库的健康状况。
示例: MySQL Exporter 可以收集 MySQL 的查询吞吐量指标 mysql_global_status_questions,
并在 Prometheus 中以时间序列的方式展示。可以在 Grafana 中设置报警规则,确保数据库负载在可控范围内。
4. Blackbox Exporter
作用:提供 HTTP、HTTPS、TCP、ICMP 等多种协议的探测功能,可以用于探测远程服务是否在线或延迟情况。
场景:适用于监控 Web 服务、API、端口等的可用性。
示例:Blackbox Exporter 可以配置 HTTP 探测,用于定期探测 Web 服务器是否可达并记录响应时间。
可以在 Prometheus 中设置告警规则,检测到网站不可用时及时发出通知。
5. cAdvisor
作用:专为 Docker 容器设计的 Exporter,负责收集容器的资源使用情况,如 CPU、内存、磁盘和网络指标。
场景:适用于监控 Kubernetes 或 Docker 中的容器资源使用情况,了解容器的运行状态。
示例: 部署 cAdvisor 后,Prometheus 可以收集容器的内存使用情况指标 container_memory_usage_bytes,
监控容器的内存消耗情况,防止内存不足导致容器重启或崩溃。
配置示例
以 Redis Exporter 为例,具体配置步骤如下:
1.部署 Redis Exporter:
部署 Redis Exporter: 安装 Redis Exporter 作为单独的服务或容器,并指向 Redis 实例,Redis Exporter 将在端口 9121 提供 Redis 指标。
docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter
2.Prometheus 配置
Prometheus 配置: 在 prometheus.yml 中添加抓取 Redis Exporter 的配置。
scrape_configs:
- job_name: 'redis'
static_configs:
- targets: ['localhost:9121']
3.查看指标:
启动 Prometheus 后,可以通过访问 http://localhost:9090/targets 查看 Redis Exporter 是否被 Prometheus 成功抓取。
监控 Redis
安装 redis
使用docker-compose安装redis
vim docker-compose.yaml
version: '3'
services:
redis:
image: redis:5
container_name: redis
command: redis-server --requirepass 123456 --maxmemory 512mb
restart: always
volumes:
- /data/redis/data:/data
ports:
- 6379:6379
docker-compose up -d

安装 redis exporter
这里我使用的是执行命令行的方法安装redis_exporter,也是林哥Linux做好的镜像上传到DockerHub上的。也可编写docker-compose安装。
docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter --redis.addr redis://192.168.200.100:6379 --redis.password '123456'

docker-compose安装
vim redis-exporter.yaml
访问redis_exporter
直接访问上面docker run之后的暴露出来的9121端口,就有Metrics连接
http://192.168.200.100:9121/
配置prometheus采取redis数据
在prometheus.yaml里加上下面的配置
- job_name: 'redis-exporter'
scrape_interval: 15s
static_configs:
- targets: ['192.168.200.100:9121']
labels:
vim prometheus.yaml
# 全局配置
global:
scrape_interval: 15s # 将搜刮间隔设置为每15秒一次。默认是每1分钟一次。
evaluation_interval: 15s # 每15秒评估一次规则。默认是每1分钟一次。
# Alertmanager 配置
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
# 报警(触发器)配置
rule_files:
- "alert.yml"
# 搜刮配置
scrape_configs:
- job_name: 'prometheus'
# 覆盖全局默认值,每15秒从该作业中刮取一次目标
scrape_interval: 15s
static_configs:
- targets: ['localhost:9090']
- job_name: 'alertmanager'
scrape_interval: 15s
static_configs:
- targets: ['alertmanager:9093']
- job_name: 'cadvisor'
scrape_interval: 15s
static_configs:
- targets: ['cadvisor:8080']
labels:
instance: Prometheus服务器
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['node_exporter:9100']
labels:
instance: Prometheus服务器
- job_name: 'redis-exporter'
scrape_interval: 15s
static_configs:
- targets: ['192.168.200.100:9121']
labels:
重新加载配置文件
curl -X POST http://localhost:9090/-/reload
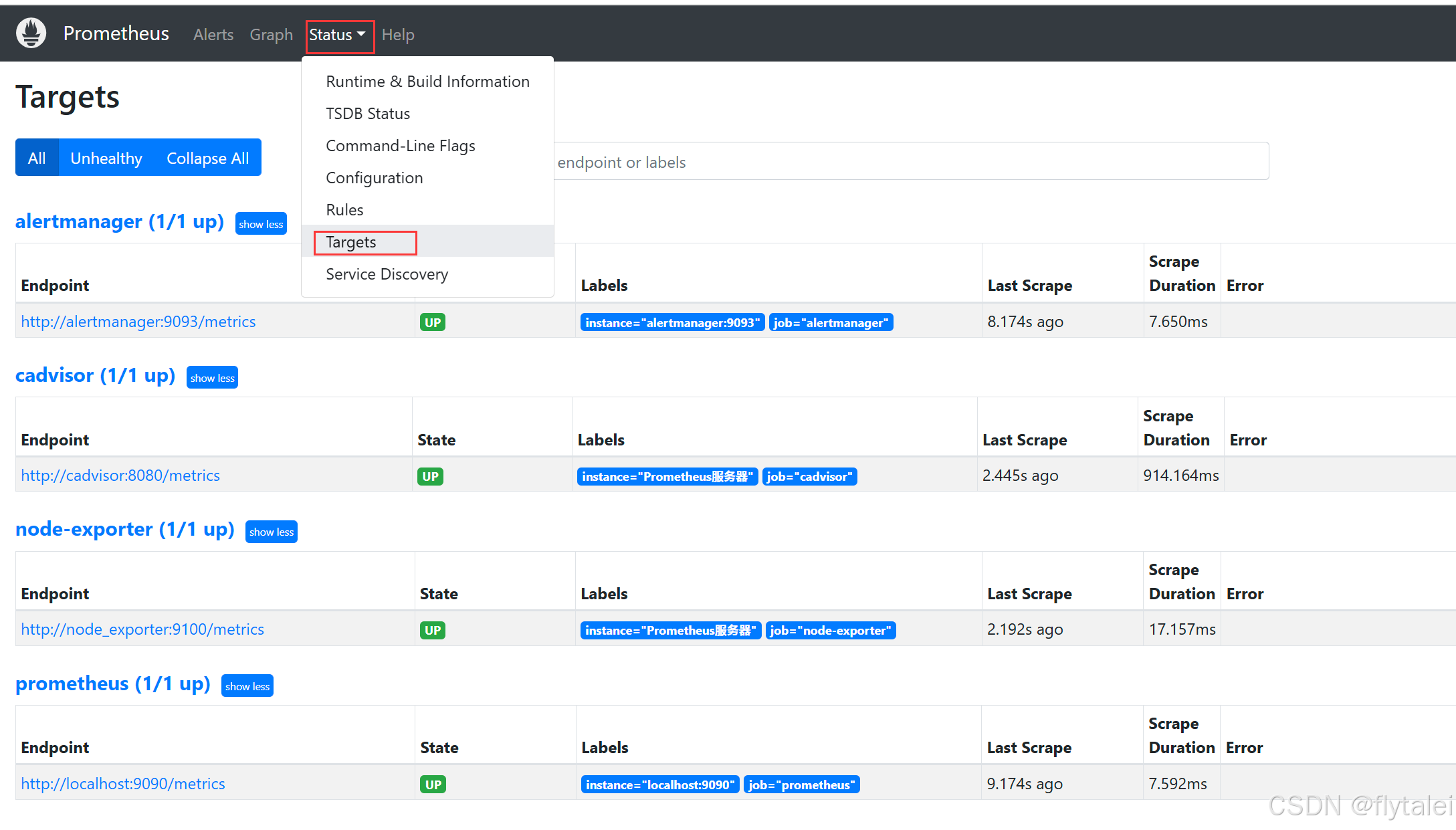
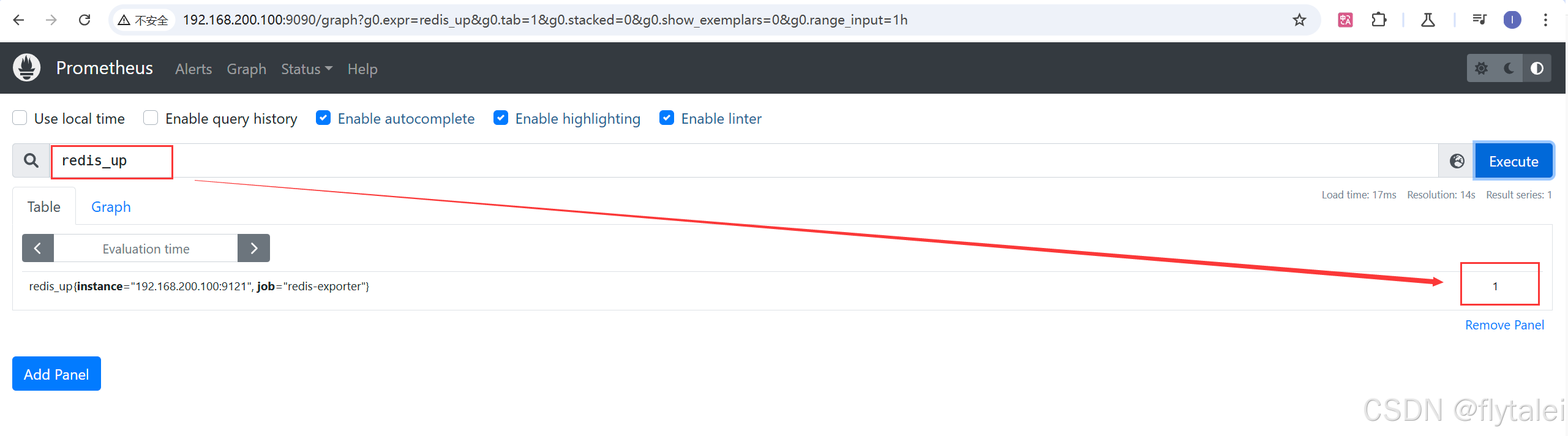
在Prometheus页面的Target菜单栏里,查看redis数据是否收集成功。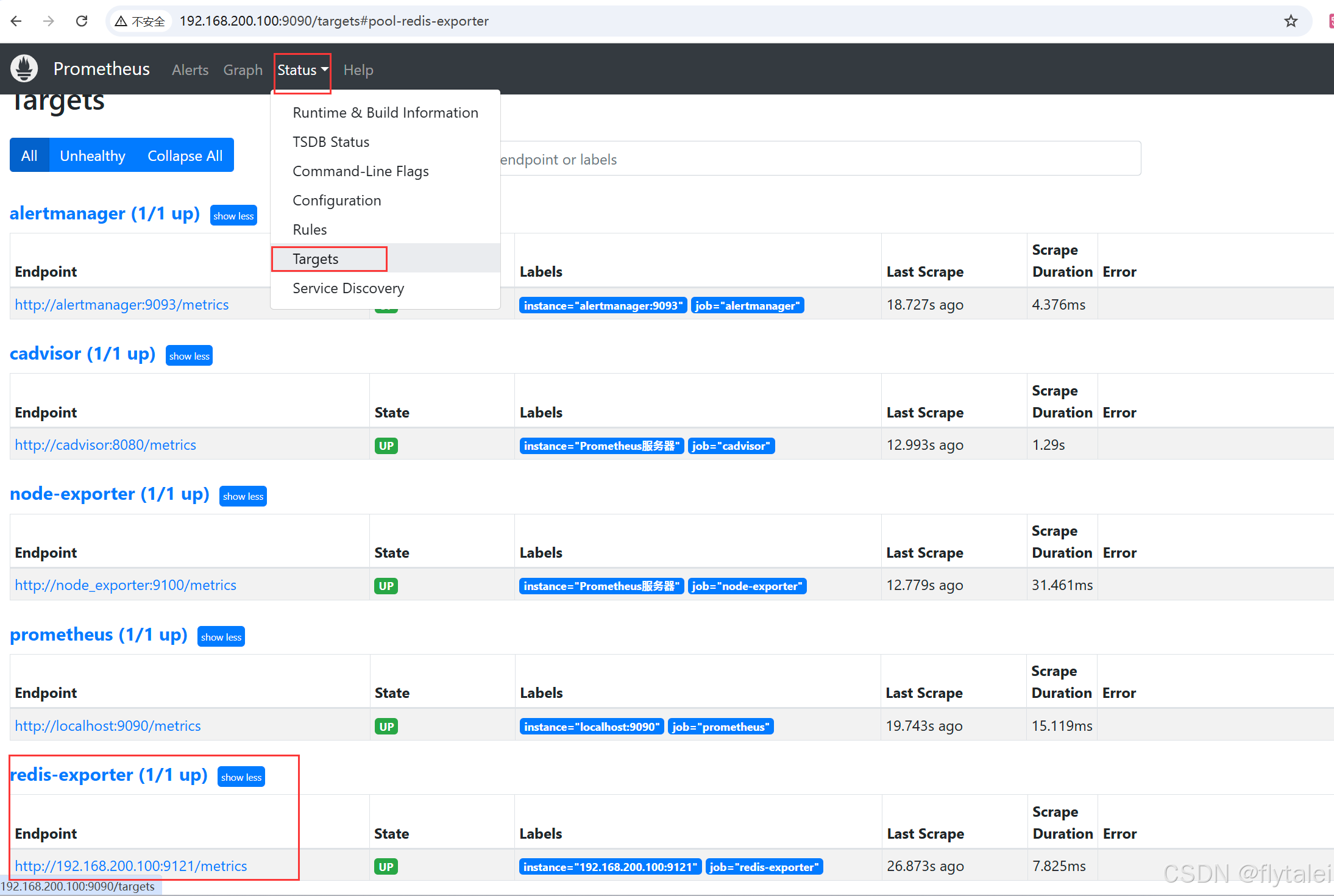
在输入框里搜索redis相关的,可以看到redis数据已经收集成功了。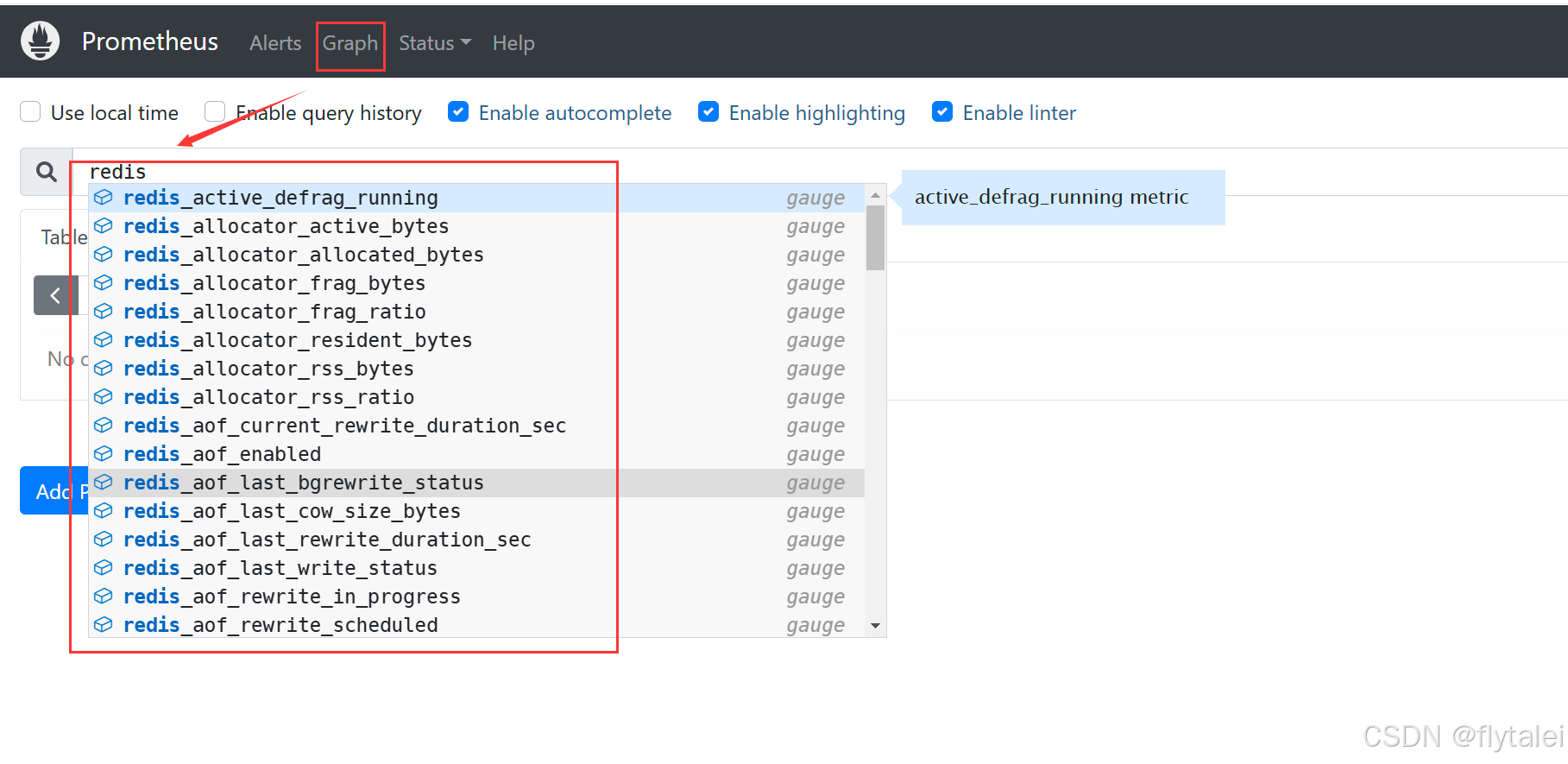
常用监控指标
这 10 个指标涵盖了 Redis 的 可用性、内存使用、缓存命中率、命令处理量 和 网络流量,是监控 Redis 健康状态和性能表现的核心数据。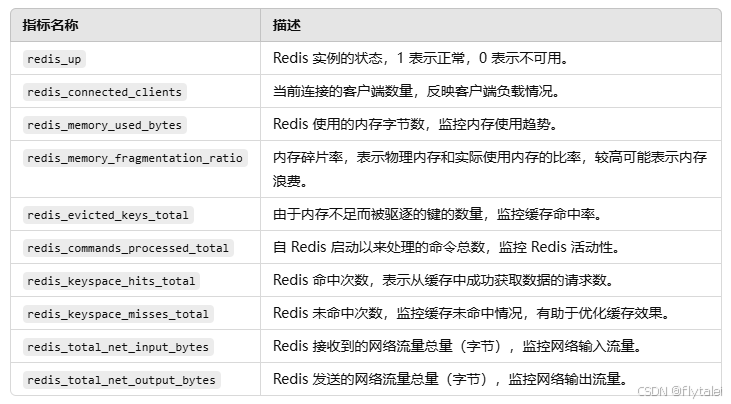
配置触发器
创建rules文件夹,分类以后创建的各个服务的触发器都放在prometheus/rules目录下。
mkdir prometheus/rules
在prometheus.yaml里配置扫描rules目录下的所有yml文件。
#报警(触发器)配置
rule_files:
- "alert.yml"
- "rules/*.yml"
在rules目录下创建redis.yaml文件
vim rules/redis.yaml
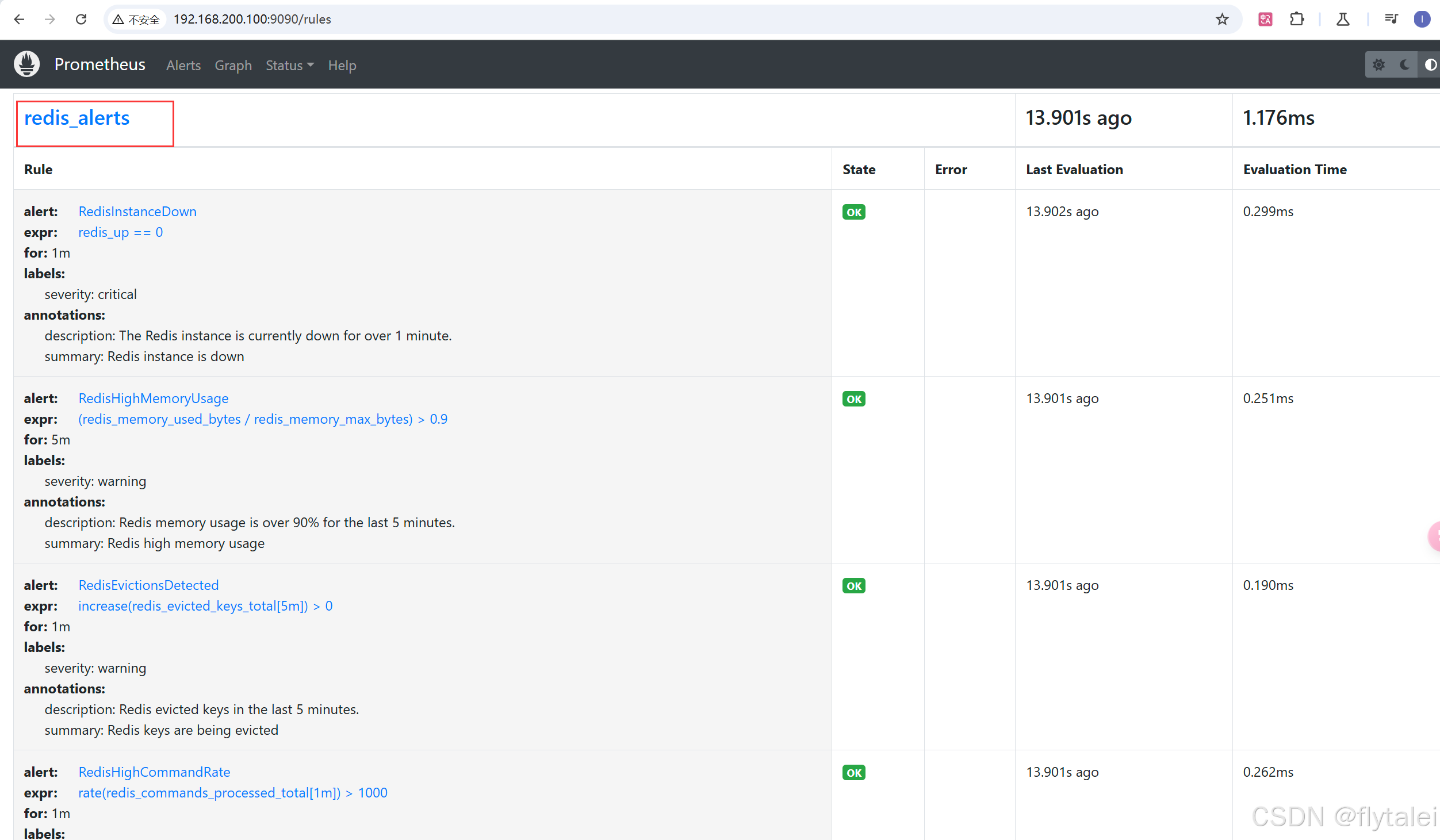
groups:
- name: redis_alerts
rules:
# 1. Redis 实例不可用
- alert: RedisInstanceDown
expr: redis_up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Redis instance is down"
description: "The Redis instance is currently down for over 1 minute."
# 2. Redis 内存使用率高
- alert: RedisHighMemoryUsage
expr: (redis_memory_used_bytes / redis_memory_max_bytes) > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "Redis high memory usage"
description: "Redis memory usage is over 90% for the last 5 minutes."
# 3. Redis 驱逐键数量增加
- alert: RedisEvictionsDetected
expr: increase(redis_evicted_keys_total[5m]) > 0
for: 1m
labels:
severity: warning
annotations:
summary: "Redis keys are being evicted"
description: "Redis evicted keys in the last 5 minutes."
# 4. Redis 命令处理速率异常
- alert: RedisHighCommandRate
expr: rate(redis_commands_processed_total[1m]) > 1000
for: 1m
labels:
severity: info
annotations:
summary: "Redis high command rate"
description: "Redis command rate exceeded 1000 commands per second."
# 5. Redis 客户端连接数过多
- alert: RedisHighConnectedClients
expr: redis_connected_clients > 500
for: 1m
labels:
severity: warning
annotations:
summary: "Redis high connected clients"
description: "Redis connected clients count is over 500."
检查配置
检测配置,看看是否有语法错误。可以看到如下提示,redis有5天规程创建成功。
docker exec -it prometheus promtool check config /etc/prometheus/prometheus.yml

需要再重新加载配置文件
curl -X POST http://localhost:9090/-/reload
检查触发器是否已触发
可以访问下面的连接
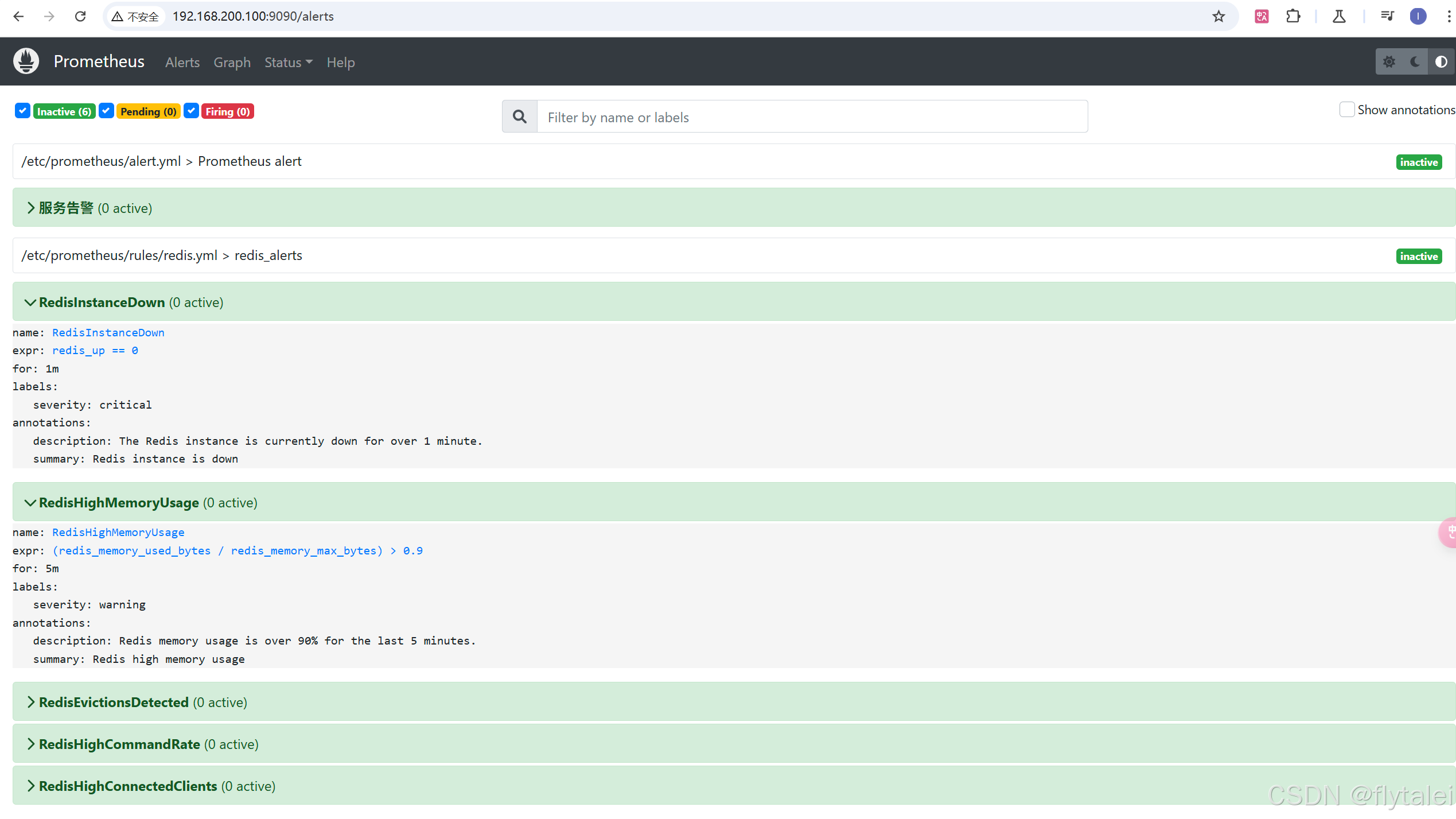
http://192.168.200.100:9090/alerts
http://192.168.200.100:9090/rules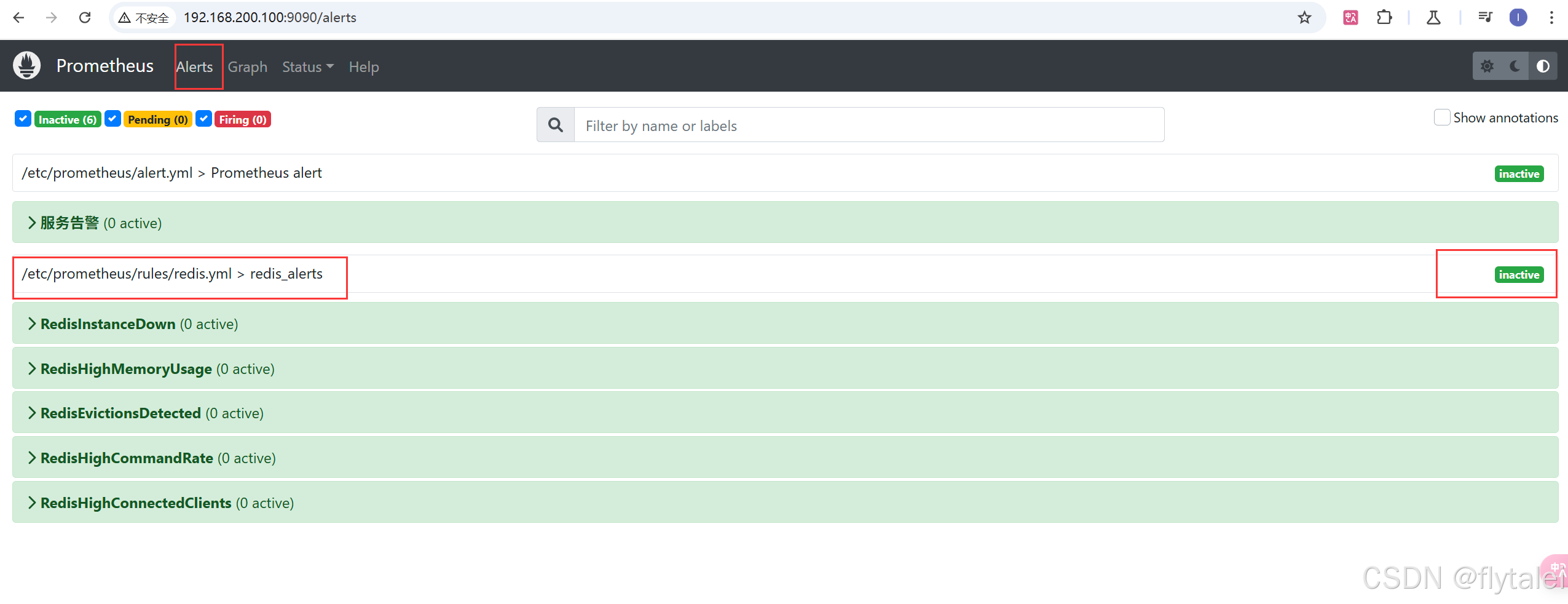
配置dashboard
Grafana官网有已经创建后的仪表盘模板,我们可以直接使用。只需要复制模板ID,在Grafana页面的Dashboards菜单的Import下load就好。
第一步:在下面的连接中找到Redis Dashboard的Copy ID to clipboard.
https://grafana.com/grafana/dashboards/11835-redis-dashboard-for-prometheus-redis-exporter-helm-stable-redis-ha/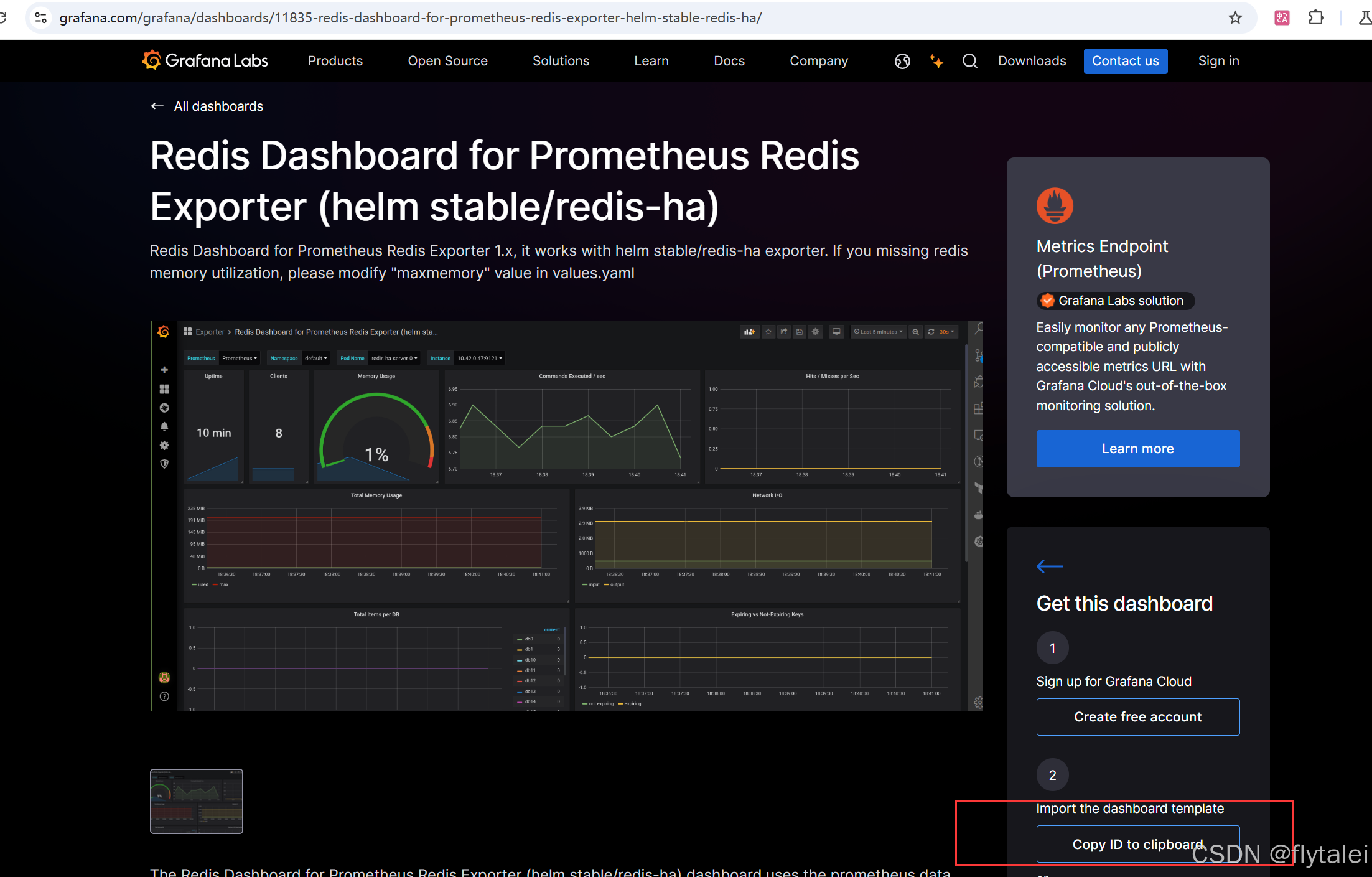
第二步:找到Dashboards的Import菜单。
第三步:粘贴第一步复制到的ID,然后Load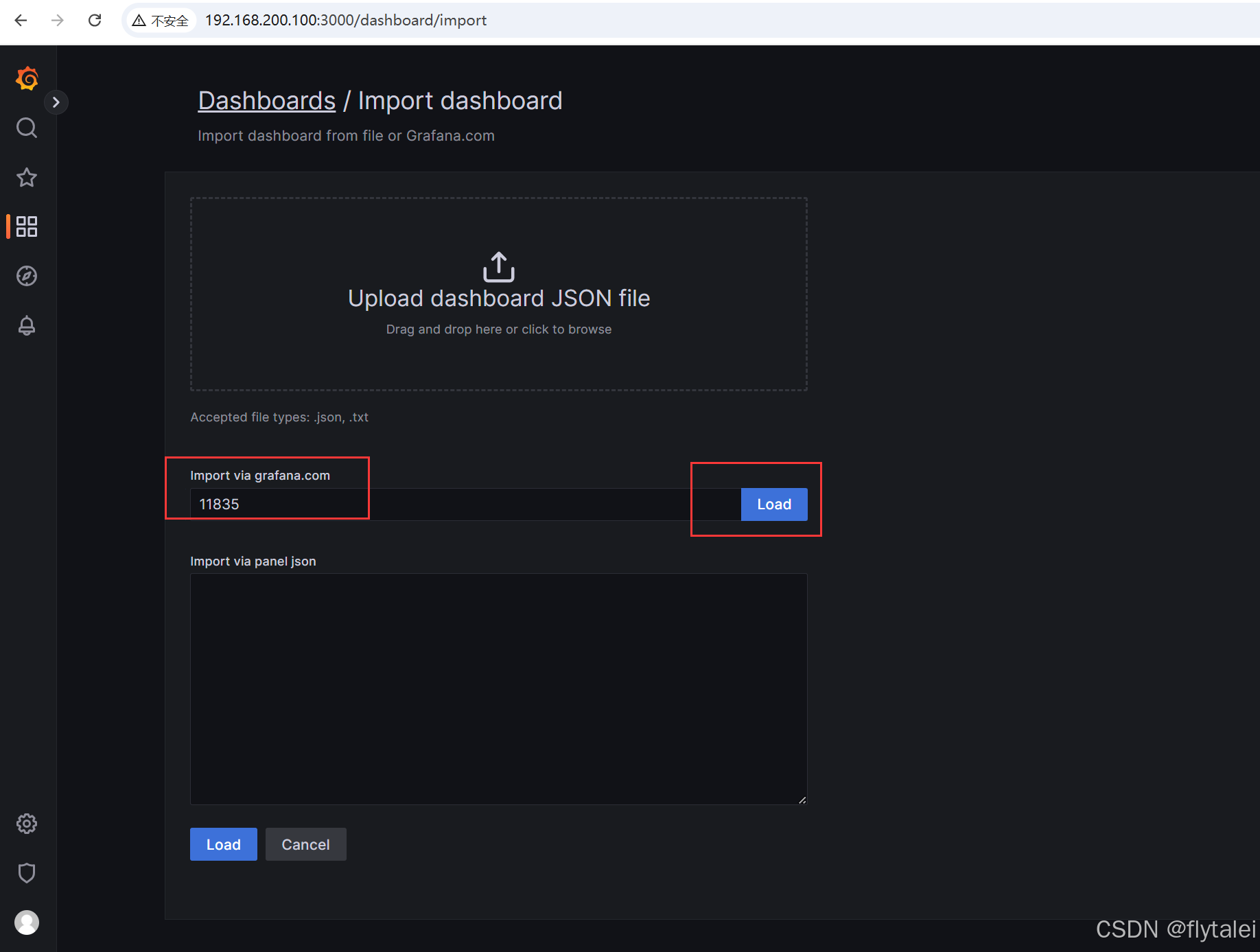
第四步:编译Options中的name,并关联Prometheus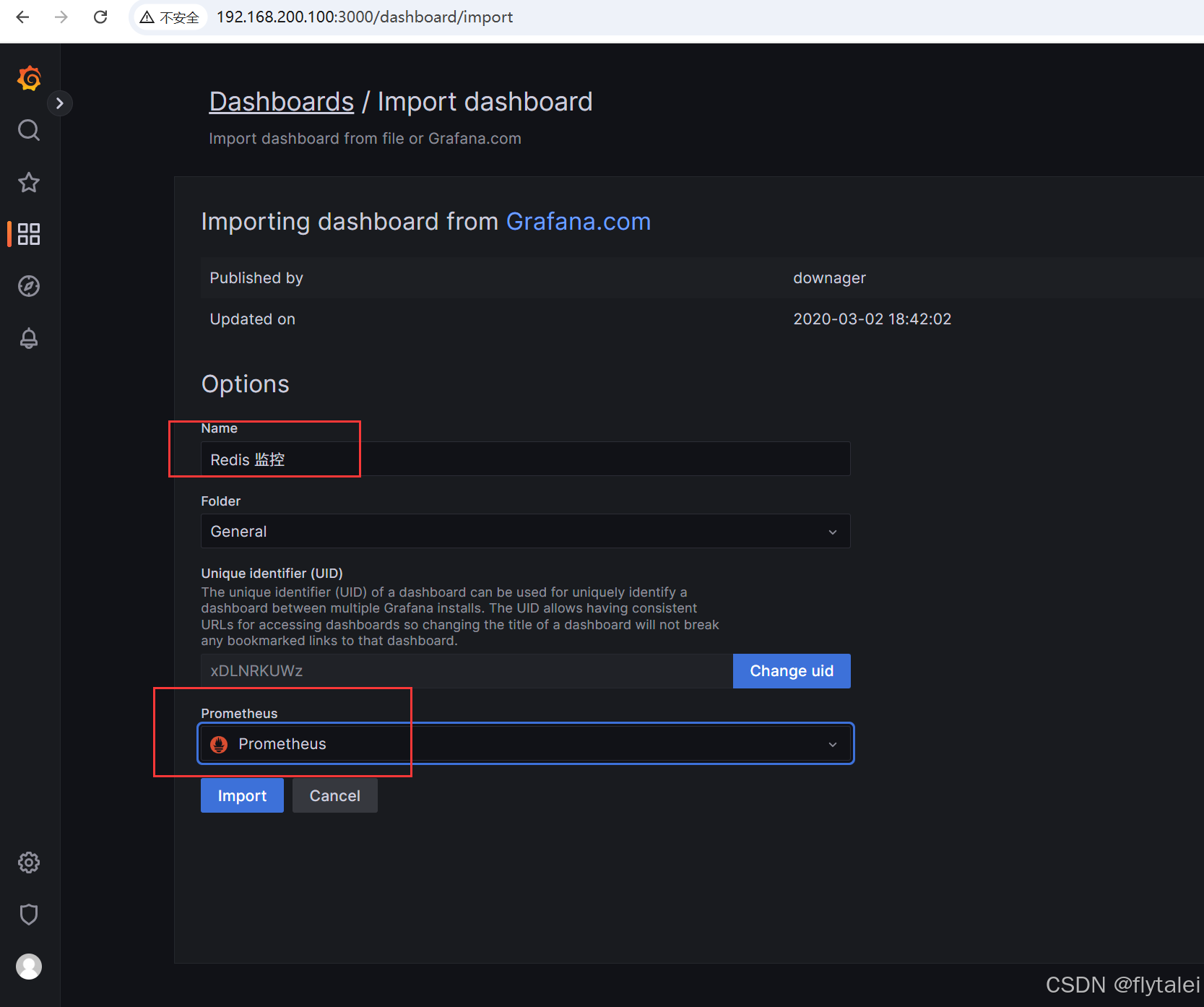
第五步:就成功啦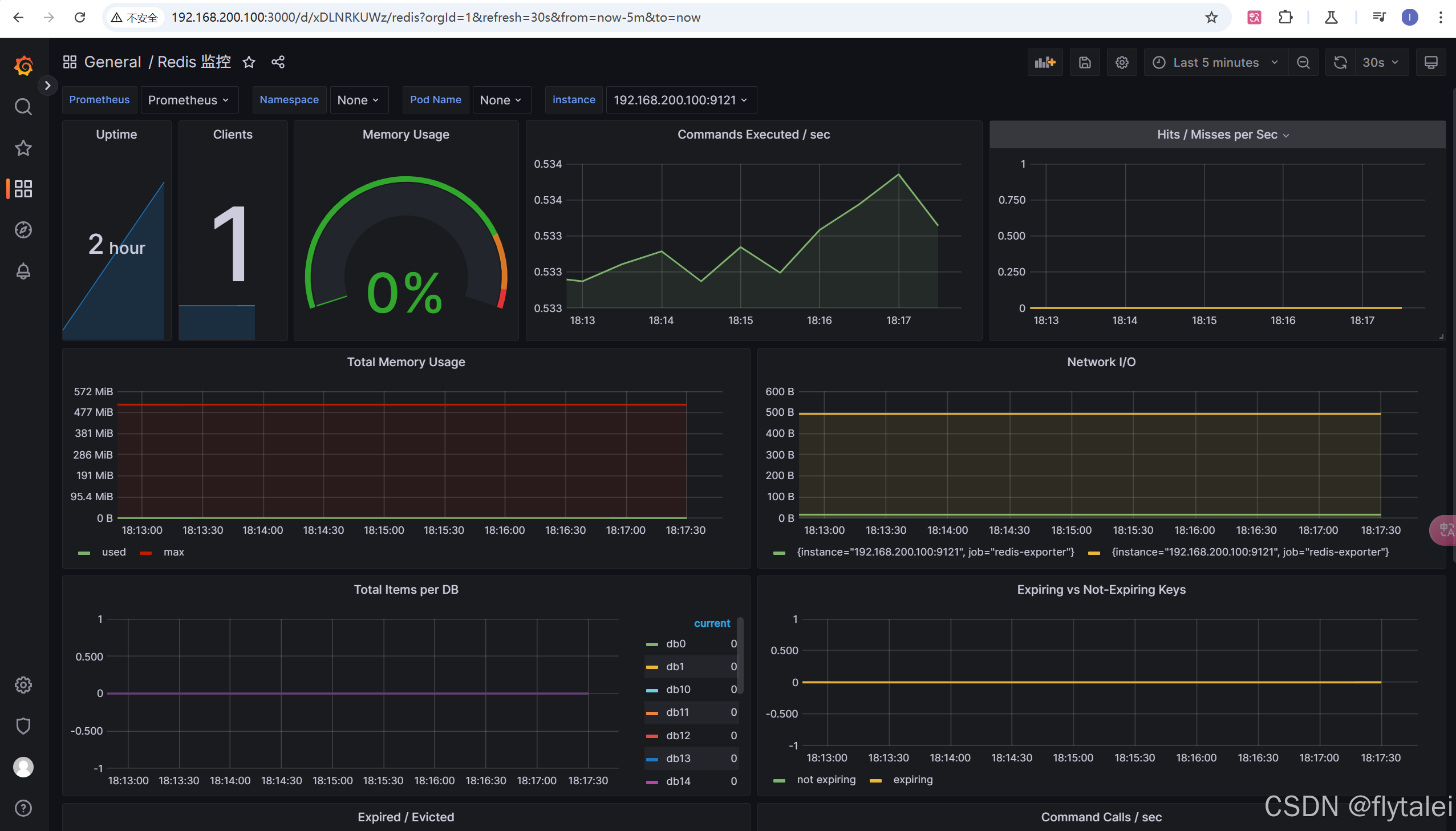
PromQL
PromQL(Prometheus Query Language)是 Prometheus 中的查询语言,用于在存储的时间序列数据中提取信息,生成统计数据,支持告警和数据可视化。它的强大功能包括时间序列过滤、聚合和操作,能够灵活地满足不同监控需求。
PromQL 的作用
PromQL 的作用
1.实时监控和告警:
通过 PromQL 编写条件查询生成告警规则,在异常情况出现时及时触发告警。
2.数据可视化:
在 Prometheus 自带的 UI、Grafana 等工具中,通过 PromQL 查询生成数据图表。
3.复杂聚合计算:
PromQL 支持多种聚合和计算函数,方便用户生成指标的汇总、计算比例等。
PromQL 的基本语法
PromQL 支持以下几种查询类型:
1.瞬时向量查询:
获取某一时间点的指标值。
2.范围向量查询:
获取一定时间范围内的指标序列。
3.聚合操作:
对指标数据进行聚合计算,如求平均值、最大值、最小值等。
PromQL 示例
示例 1:瞬时向量查询
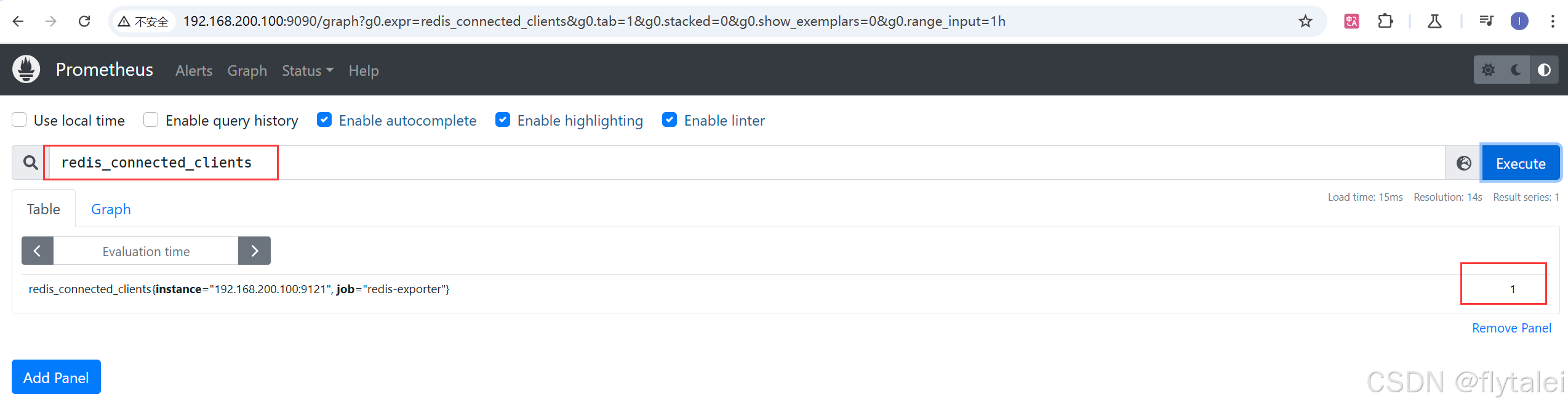
查询当前所有 Redis 实例的连接客户端数量:
redis_connected_clients
示例 2:范围向量查询
查询过去 5 分钟 Redis 命令处理总量的增量:
increase(redis_commands_processed_total[5m])
这里使用了 increase 函数和 [5m] 范围选择器,返回 Redis 在过去 5 分钟内处理的命令数量。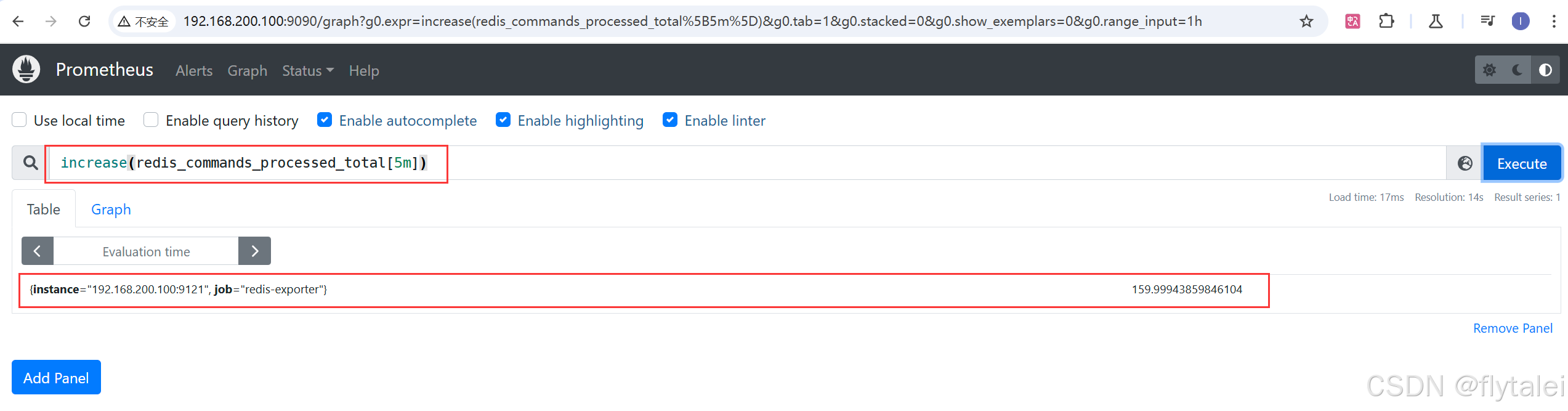
结果可能需要做单位转换。
Alertmanager和告警规则
Prometheus 的告警机制由 告警规则和Alertmanager 两部分组成。Prometheus 负责根据告警规则检测时间序列数据中的异常情况,生成告警信息并发送给 Alertmanager;Alertmanager 则负责告警的分组、抑制、静默、去重和通知。
Alertmanager配置概述
Alertmanager主要负责对Prometheus产生的告警进行统一处理。
在Alertmanager配置中一般会包含以下几个主要部分:
1.'全局配置(global)': 用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
2.'模板(templates)': 用于定义告警通知时的模板,如HTML模板,邮件模板等;
3.'告警路由(route)': 根据标签匹配,确定当前告警应该如何处理;
4.'接收人(receivers)': 接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
5.'抑制规则(inhibit_rules)': 合理设置抑制规则可以减少垃圾告警的产生
林哥Linux这里默认的alter.yaml配置如下
global:
#163服务器
smtp_smarthost: 'smtp.163.com:465'
#发邮件的邮箱
smtp_from: 'cdring@163.com'
#发邮件的邮箱用户名,也就是你的邮箱
smtp_auth_username: 'cdring@163.com'
#发邮件的邮箱密码
smtp_auth_password: 'your-password'
#进行tls验证
smtp_require_tls: false
route:
group_by: ['alertname']
#当收到告警的时候,等待group_wait配置的时间,看是否还有告警,如果有就一起发出去
group_wait: 10s
#如果上次告警信息发送成功,此时又来了一个新的告警数据,则需要等待group_interval配置的时间才可以发送出去
group_interval: 10s
#如果上次告警信息发送成功,且问题没有解决,则等待repeat_interva1配置的时间再次发送告警数据
repeat_interval: 10m
#全局报警组,这个参数是必选的
receiver: email
receivers:
- name: 'email'
#收邮件的邮箱
email_configs:
- to: '15820402924@163.com'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
Prometheus与Alertmanager关联
Prometheus把产生的告警发送给Alertmanager进行告警处理时,需要在Prometheus使用的配置文件中添加关联Alertmanager组件的对应配置内容。
1)编辑prometheus.yml文件加入关联Alertmanager组件的访问地址,示例如下:
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager: 9093']
2)添加监控Alertmanager,让Prometheus去收集Alertmanager的监控指标。
- job_name: 'alertmanager'
#覆盖全局默认值,每15秒从该作业中刮取一次目标‘’
scrape_interva1: 15s
static_configs:
- targets: ['alertmanager:9093'] #可以通过
3)重启prometheus
curl -X POST http://localhost:9090/-/reload
重启之后访问9090端口
看到alertmanager的state的状态为up说明配置成功。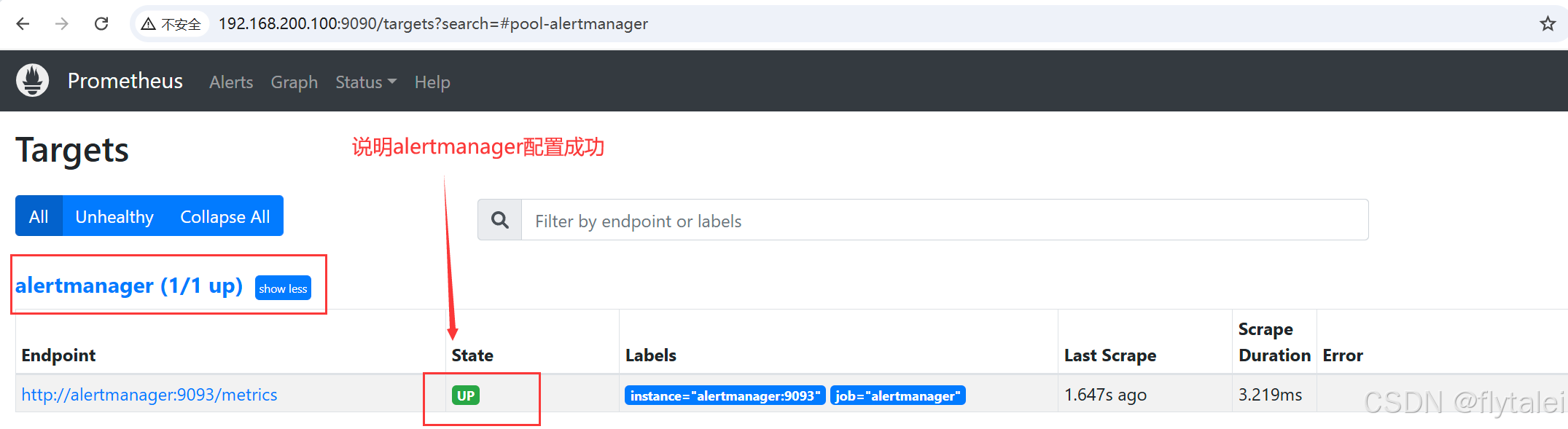
配置告警规则
先安装希望告警的服务,比如redis、mysql、linux主机node等,这里以告警linux主机为例。
Prometheus.yml添加配置
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['node_exporter: 9100']
labels:
instance: Prometheus服务器
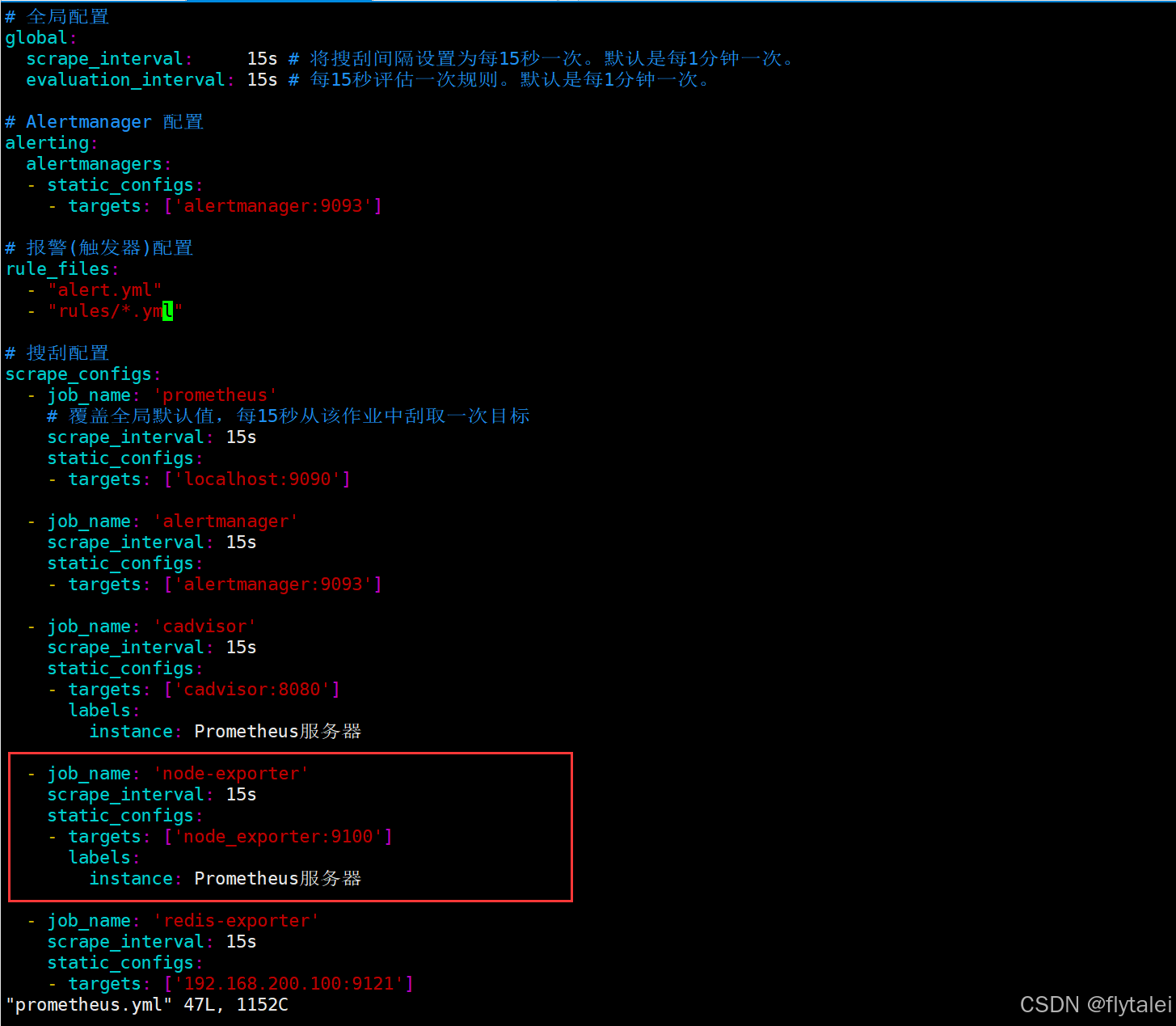
创建告警规则文件
在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。
一条告警规则主要由以下几部分组成:
1.alert: 告警规则的名称。
2.expr: 基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
3.for: 评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。
在等待期间新产生告警的状态为pending。
4.labels: 自定义标签,允许用户指定要附加到告警上的一组附加标签。
5.annotations: 用于指定一组附加信息,比如用于描述告警详细信息的文字等,
annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
vim prometheus/alert.yml
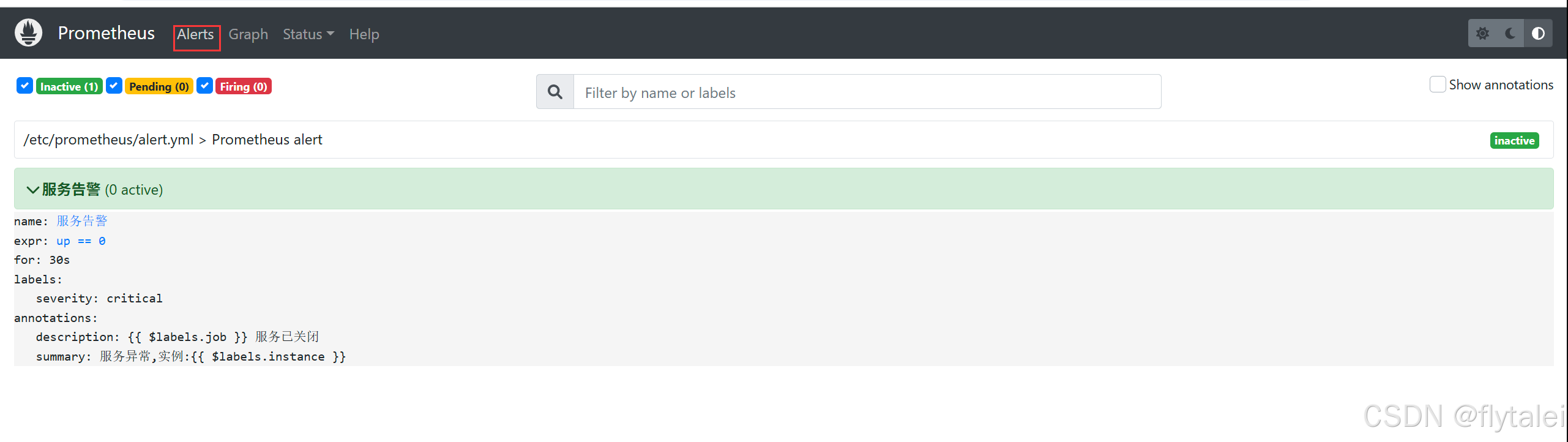
告警规则配置如下
groups:
- name: Prometheus alert
rules:
# 对任何实例超过30秒无法联系的情况发出警报
- alert: 服务告警
expr: up == 0
for: 30s
labels:
severity: critical
annotations :
summary: "服务异常,实例:{{ $labels.instance }}"
description: "{{ $labels.job } 服务己关闭"
- name: node-exporter
rules:
- alert: HostoutofMemory
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 2m
labels:
severity: warning
annotations:
summary: "主机内存不足,实例:{{ $1abels.instance }}"
description: "内容可用率<10%,当前值:{{ $value }}"
- alert: HostMemoryUnderMemoryPressure
expr: rate(node_vmstat_pgmajfault[1m]) > 1000
for: 2m
labels:
severity: warning
annotations:
summary: "内存压力不足,实例:{{ $labels.instance }}"
description: "节点内存压力大。,重大页面错误率高,当前值为:{{ $value }}"
- alert: HostUnusualTNetworkThroughputIn
expr: sum by (instance)(rate(node_network_receive_bytes_total[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations :
summary: "异常流入网络吞吐量,实例:{{ $labels.instance }} "
description: "网络流入流量> 100 MB/s,当前值:{{ $value }}"
- alert: HostUnusuaTNetworkThroughputout
....
加载配置
curl -X POST http://localhost:9090/-/reload
指定加载告警规则
为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
格式:
rule_files;
[ - <filepath_glob> ... ]
具体配置如下,如果不配置rule_files,告警规则是不会生效的。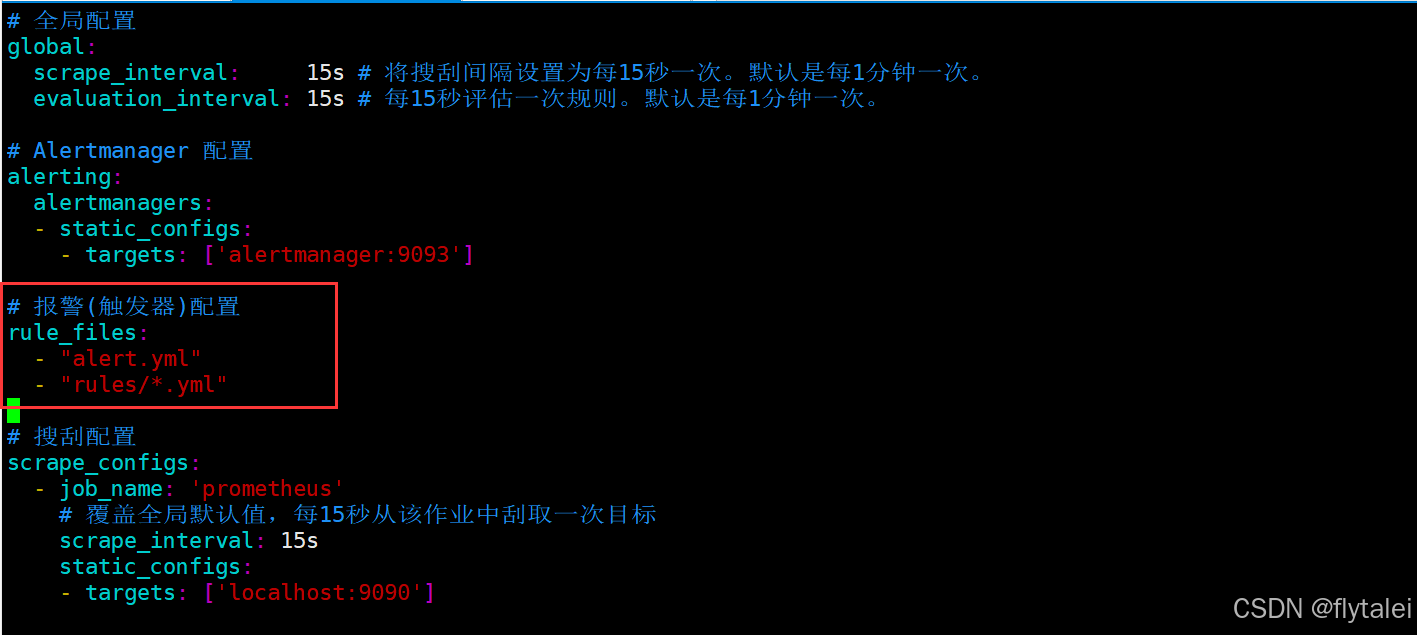
重新配置文件
curl -X POST http://localhost:9090/-/reload
查看告警状态
重启Prometheus后,用户可以通过Prometheus WEB界面中的Alerts菜单查看当前Prometheus 下的所有告警规则,以及其当前所处的活动状态。
同时对于已经pending或者firing的告警,Prometheus也会将它们存储到时间序列ALERTS杂中。
可以通过表达式,查询告警实例
alert{}
样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时,样本值则为0。
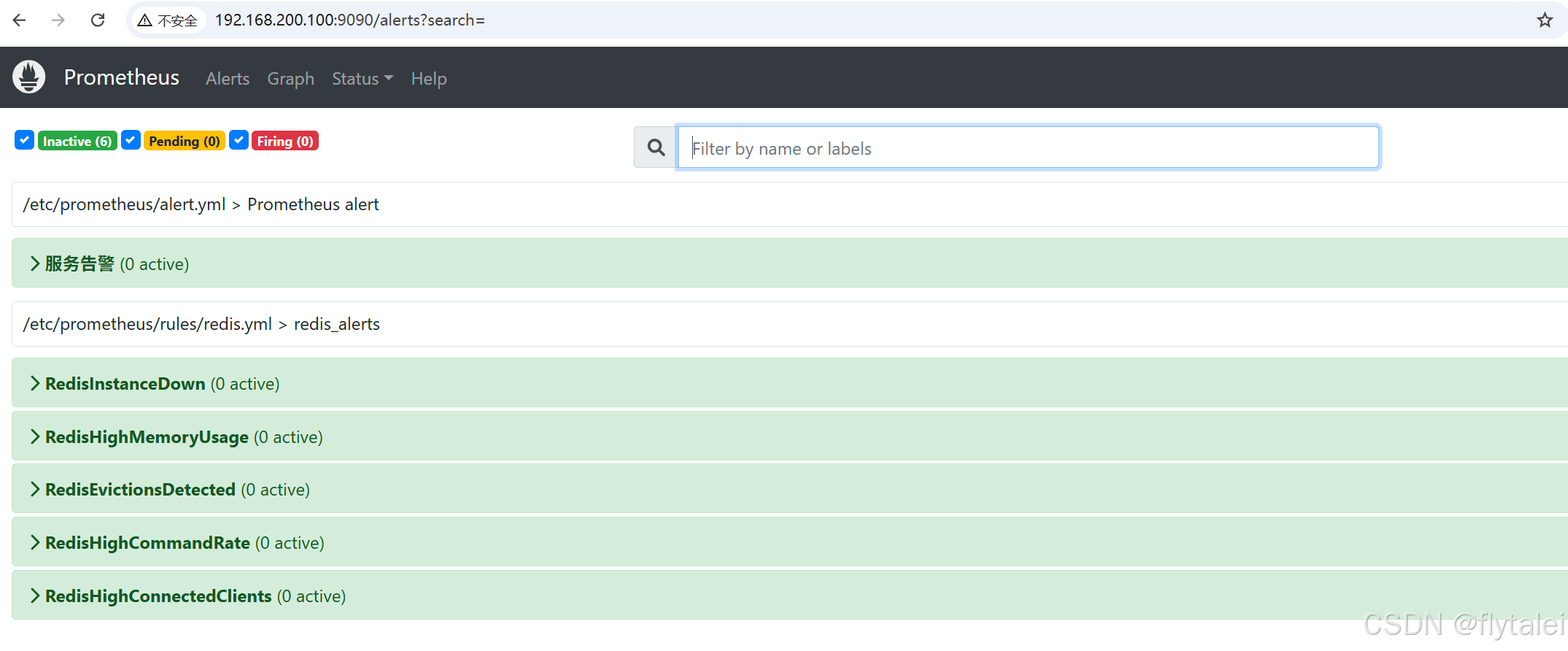
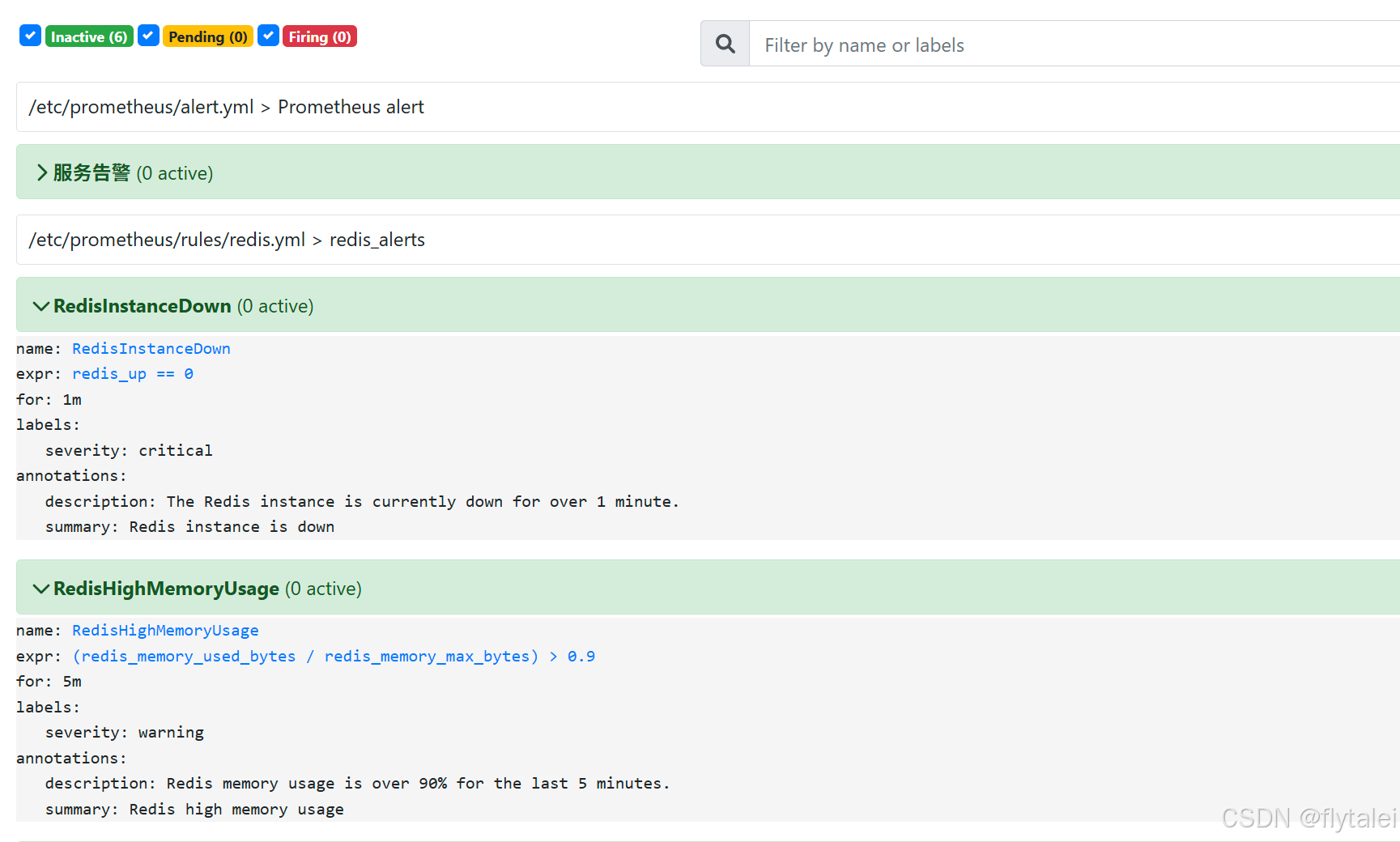
测试告警状态
当前redis容器运行正常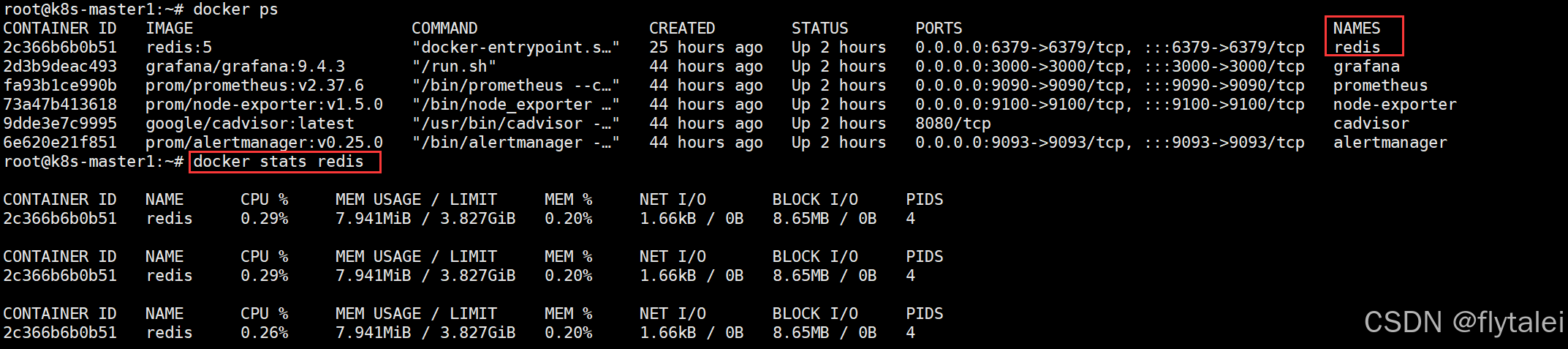
使用命令停掉redis容器
已经有服务告警了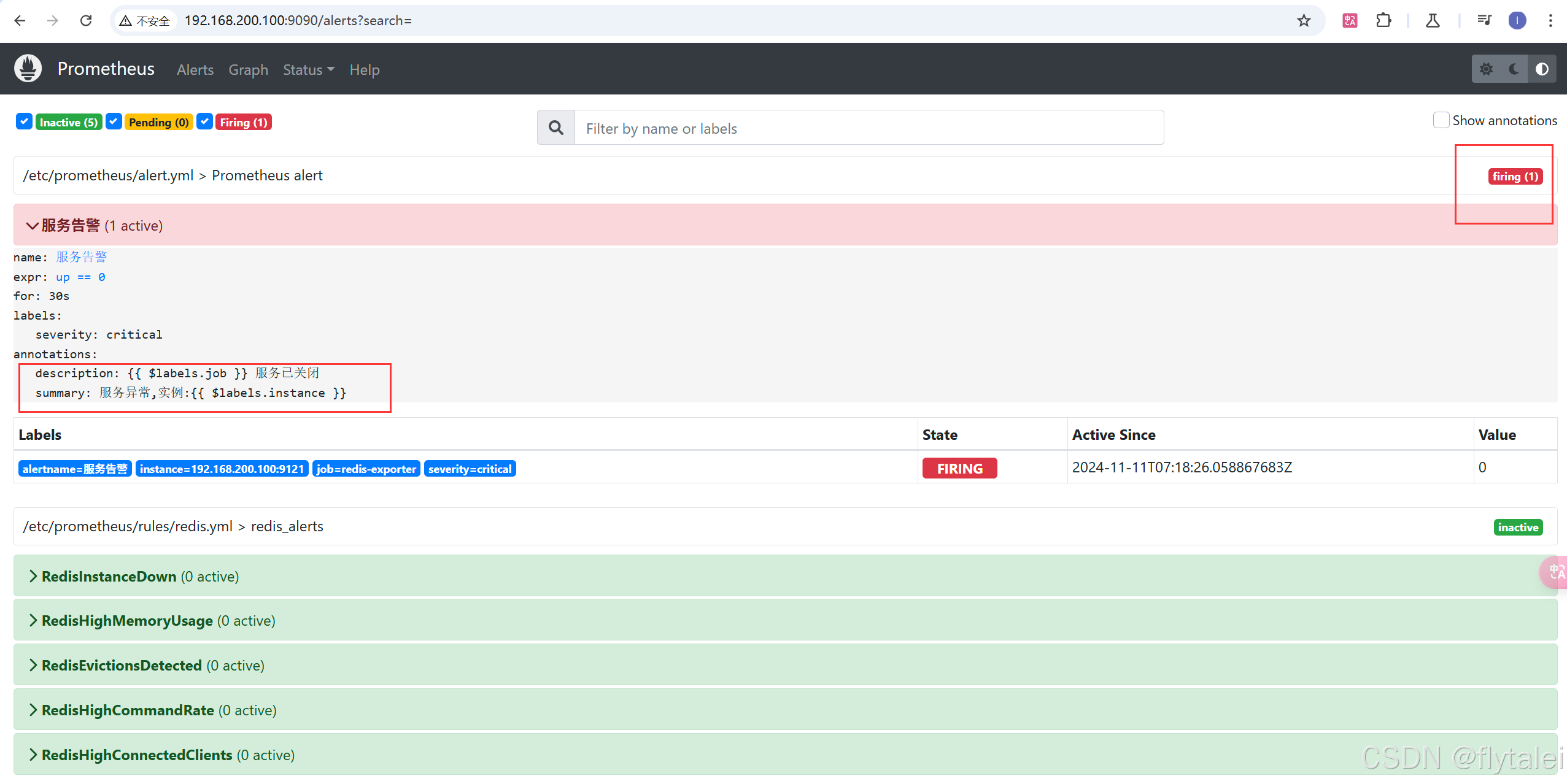
alert.yaml的配置
关闭了redis和node-exporter两个容器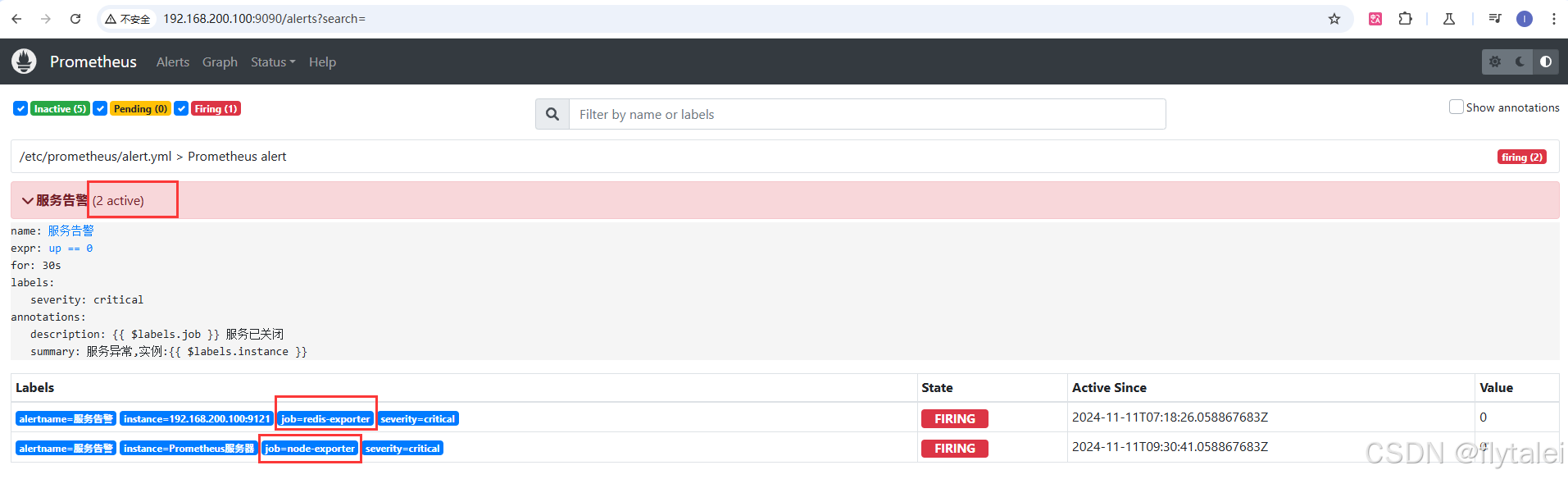
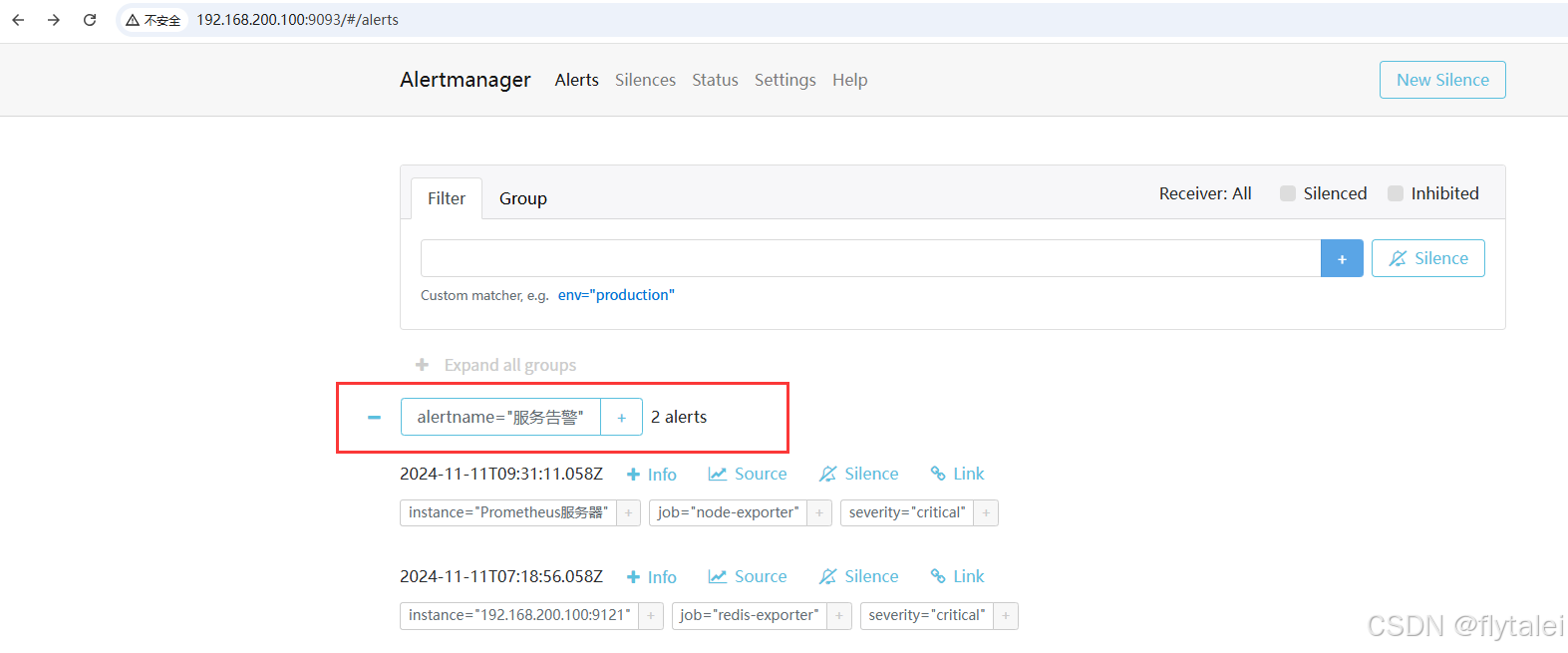
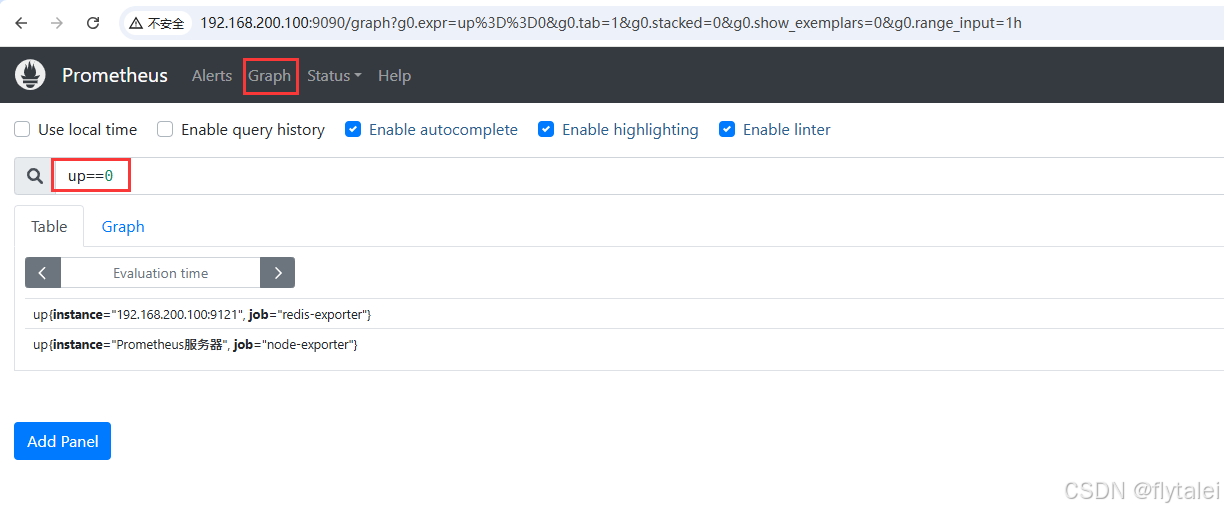
配置邮件报警
开启POP3/SMTP服务

复制授权码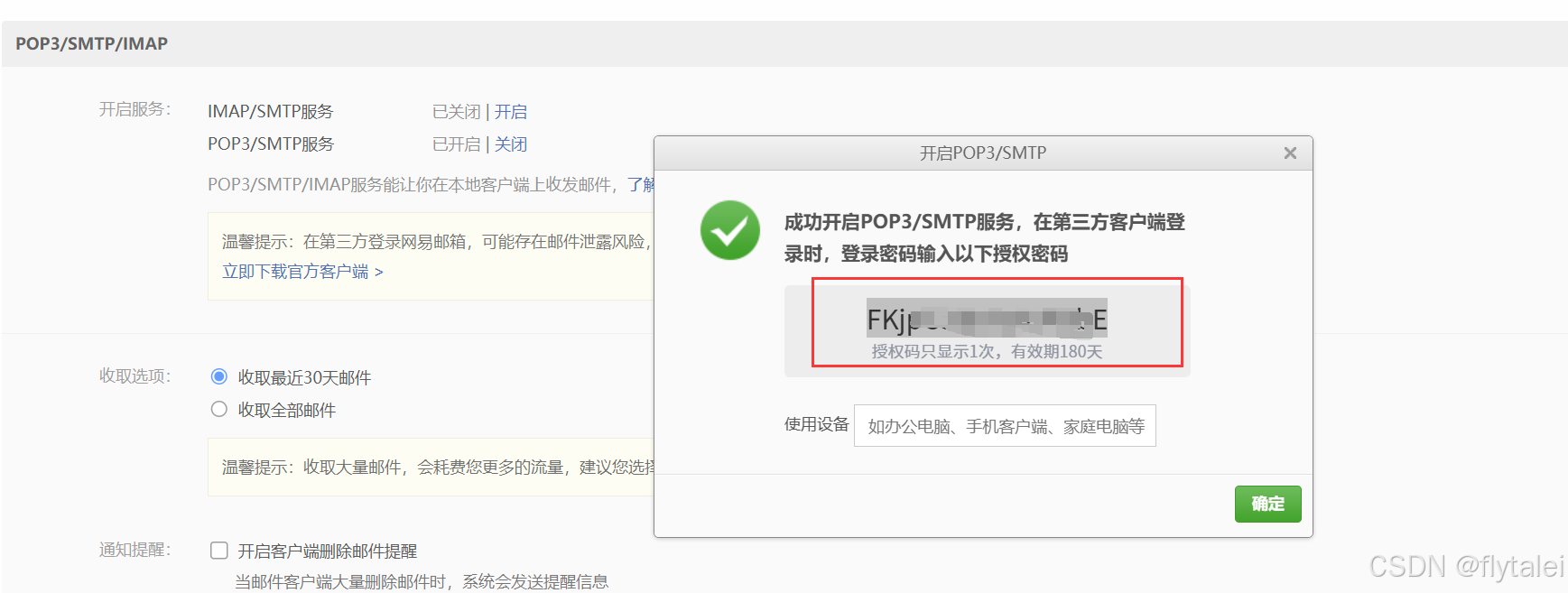
配置alertmanager的config.yml
global:
#163服务器
smtp_smarthost: 'smtp.163.com:465'
#发邮件的邮箱
smtp_from: '158@163.com'
#发邮件的邮箱用户名,也就是你的邮箱
smtp_auth_username: '158@163.com'
#发邮件的邮箱密码
smtp_auth_password: 'Fikljgljidjlo'
#进行tls验证
smtp_require_tls: false
route:
group_by: ['alertname']
# 当收到告警的时候,等待group_wait配置的时间,看是否还有告警,如果有就一起发出去
group_wait: 10s
# 如果上次告警信息发送成功,此时又来了一个新的告警数据,则需要等待group_interval配置的时间才可以发送出去
group_interval: 10s
# 如果上次告警信息发送成功,且问题没有解决,则等待 repeat_interval配置的时间再次发送告警数据
repeat_interval: 10m
# 全局报警组,这个参数是必选的
receiver: email
receivers:
- name: 'email'
#收邮件的邮箱
email_configs:
- to: 'fly@gmail.com'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
重启alertmanager或者重新加载配置
curl -X POST http://localhost:9093/-/reload
查看Alertmanager的status信息
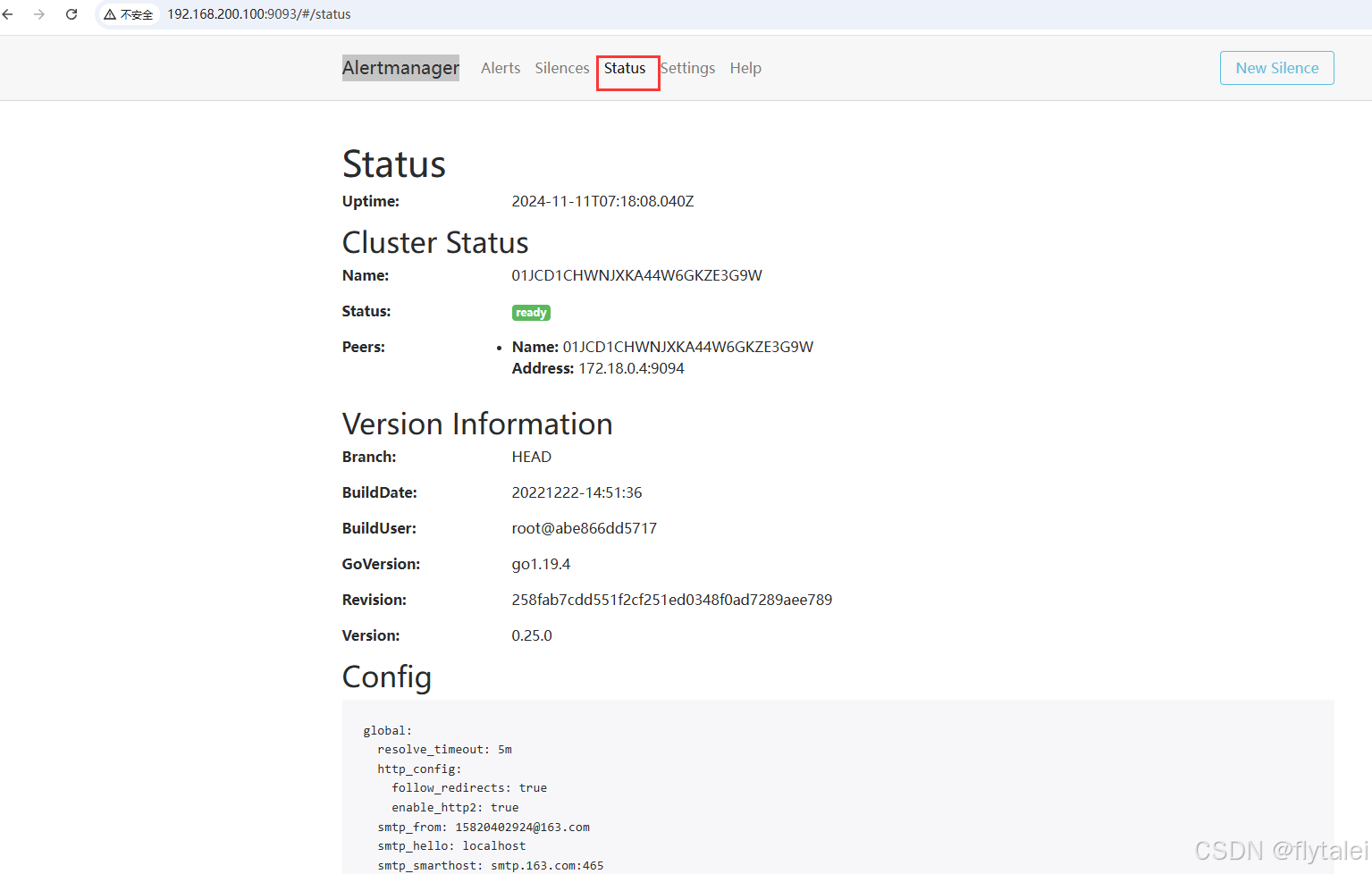
停掉node-exporter容器

停掉node-exporter之后,alertmanager已经接收到prometheus发送过来的告警信息了。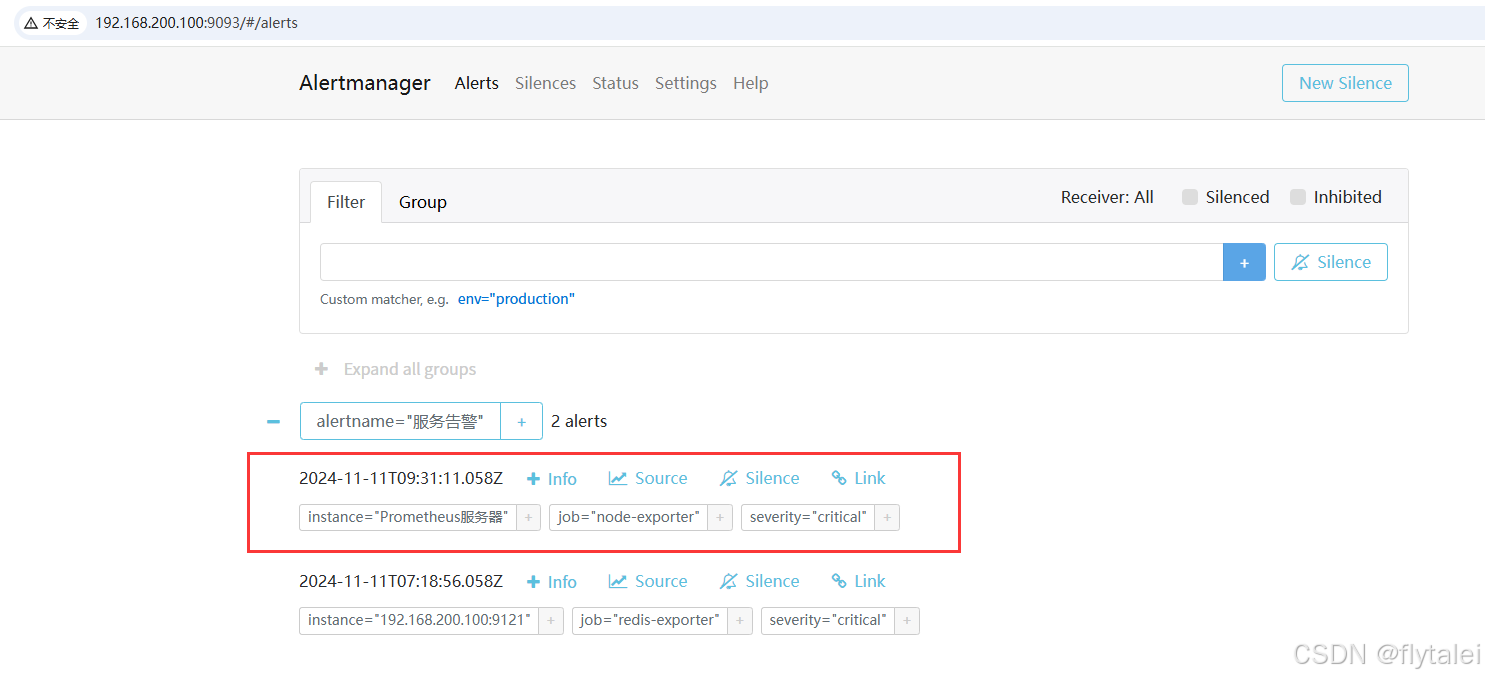
查看接收邮件
已经接收成功了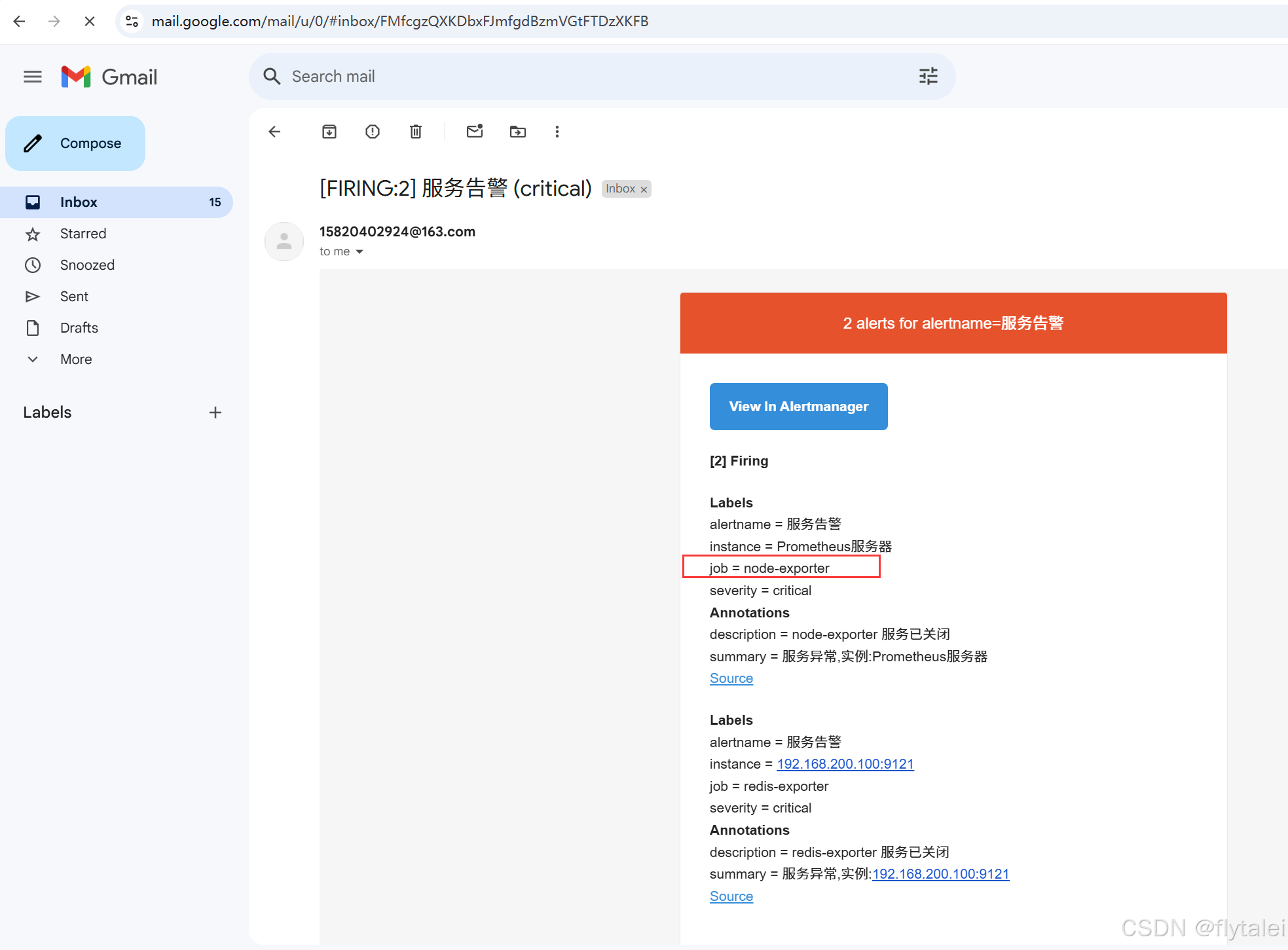
邮件信息模板
如果不想使用默认的邮件模板,可以创建一个新的模板
在alertmanager下创建一个template目录模板信息
vim email-template.tmpl
{{ define "email.alert" }}
<html>
<body>
<h2>⚠️ 监控告警通知 ⚠️</h2>
<p>您好,以下是新的告警信息:</p>
<h3>告警详情</h3>
<ul>
<li><strong>告警名称:</strong> {{ .CommonLabels.alertname }}</li>
<li><strong>告警级别:</strong> {{ .CommonLabels.severity }}</li>
<li><strong>告警状态:</strong> {{ .Status | toUpper }}</li>
<li><strong>发生时间:</strong> {{ .StartsAt }}</li>
<li><strong>恢复时间:</strong> {{ .EndsAt }}</li>
</ul>
<h3>告警标签</h3>
<ul>
{{ range $key, $value := .CommonLabels }}
<li><strong>{{ $key }}:</strong> {{ $value }}</li>
{{ end }}
</ul>
<h3>告警信息</h3>
<ul>
{{ range .Alerts }}
<li><strong>实例:</strong> {{ .Labels.instance }}</li>
<li><strong>摘要:</strong> {{ .Annotations.summary }}</li>
<li><strong>描述:</strong> {{ .Annotations.description }}</li>
<li><strong>告警时间:</strong> {{ .StartsAt }}</li>
<li><strong>恢复时间:</strong> {{ .EndsAt }}</li>
<br />
{{ end }}
</ul>
<p>请及时处理该告警,确保系统正常运行。</p>
<hr>
<p>此邮件为自动生成,请勿回复。</p>
</body>
</html>
{{ end }}
引用模板文件
在 alertmanager.yml 配置文件中引用此模板文件,并指定使用的模板名称。
需要配置templates和html
global:
smtp_smarthost: 'smtp.example.com:587'
smtp_from: 'alertmanager@example.com'
templates:
- 'email-template.tmpl'
receivers:
- name: 'email-receiver'
email_configs:
- to: 'user@example.com'
html: '{{ template "email.alert" . }}'

一站式 AI 云服务平台
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)