
DrissionPage 在ubuntu运行报错raise BrowserConnectError(f‘\n{ip}:{port}浏览器无法链接。\n请确认:\n1、该端口为浏览器\n
2、已添加’–remote-debugging-port=9222’启动项。5、如果是Linux系统,可能还要添加’–no-sandbox’启动参数。可使用ChromiumOptions设置端口和用户文件夹路径。4、如为无界面系统,请添加’–headless=new’参数。127.0.0.1:9222浏览器无法链接。3、用户文件夹没有和已打开的浏览器冲突。
·
报错如下:
DrissionPage.errors.BrowserConnectError:
127.0.0.1:9222浏览器无法链接。
请确认:
1、该端口为浏览器
2、已添加’–remote-debugging-port=9222’启动项
3、用户文件夹没有和已打开的浏览器冲突
4、如为无界面系统,请添加’–headless=new’参数
5、如果是Linux系统,可能还要添加’–no-sandbox’启动参数
可使用ChromiumOptions设置端口和用户文件夹路径。
解决
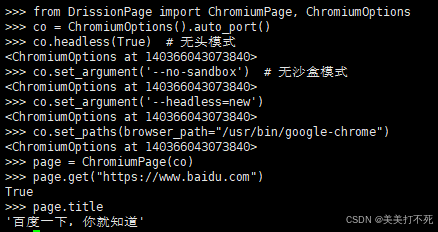
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions().auto_port() # 指定程序每次使用空闲的端口和临时用户文件夹创建浏览器
co.headless(True) # 无头模式
co.set_argument('--no-sandbox') # 无沙盒模式
co.set_argument('--headless=new') # 无界面系统添加
co.set_paths(browser_path="/usr/bin/google-chrome") # 设置浏览器路径
page = ChromiumPage(co)
page.get("https://www.baidu.com")
print(page.title)
多线程案例
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions().auto_port() # 指定程序每次使用空闲的端口和临时用户文件夹创建浏览器
co.headless(True) # 无头模式
co.set_argument('--no-sandbox') # 无沙盒模式
co.set_argument('--headless=new') # 无界面系统添加
co.set_paths(browser_path="/usr/bin/google-chrome") # 设置浏览器路径
page = ChromiumPage(co)
# page.get("https://www.baidu.com")
# print(page.title)
from threading import Thread
from DrissionPage import ChromiumPage
from DataRecorder import Recorder
def collect(tab, recorder, title):
"""用于采集的方法
:param tab: ChromiumTab 对象
:param recorder: Recorder 记录器对象
:param title: 类别标题
:return: None
"""
num = 1 # 当前采集页数
while True:
# 遍历所有标题元素
for i in tab.eles('.title project-namespace-path'):
# 获取某页所有库名称,记录到记录器
recorder.add_data((title, i.text, num))
# 如果有下一页,点击翻页
btn = tab('@rel=next', timeout=2)
if btn:
btn.click(by_js=True)
tab.wait.load_start()
num += 1
# 否则,采集完毕
else:
break
def main():
# 新建页面对象
# page = ChromiumPage()
# 第一个标签页访问网址
page.get('https://gitee.com/explore/ai')
# 获取第一个标签页对象
tab1 = page.get_tab()
# 新建一个标签页并访问另一个网址
tab2 = page.new_tab('https://gitee.com/explore/machine-learning')
# 获取第二个标签页对象
tab2 = page.get_tab(tab2)
# 新建记录器对象
recorder = Recorder('data.csv')
# 多线程同时处理多个页面
Thread(target=collect, args=(tab1, recorder, 'ai')).start()
Thread(target=collect, args=(tab2, recorder, '机器学习')).start()
if __name__ == '__main__':
main()

一站式 AI 云服务平台
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)