
自己动手实现memcpy
自己动手实现memcpy(优化)
自己动手实现memcpy(优化)
1. 简单实现(未优化)
1.1 接口
按照memcpy的接口来设计,注意src用const void*。
void* my_memcpy(void *dst, const void *src, size_t n);
1.2 程序设计
代码如下⬇️
void* my_memcpy(void *dst, const void *src, size_t n) {
uint8_t *p = (uint8_t *)dst;
uint8_t *q = (uint8_t *)src;
size_t size = n;
while (n--) *p++ = *q++;
assert((uint64_t)p - (uint64_t)dst == size);
return dst;
}
过程很简单,即将指针转换成uint8_t类型的,一个字节一个字节的进行复制,并在最后进行判断,是否复制成功,然后ret。
2. 效率分析(速度太慢)
2.2 效率分析程序描述
写一个程序来测试,过程是,读取一个1GB文件,存放在from指向的内存空间,使用my_memcpy()来讲from指向的内容,拷贝到to指向的内存空间。
主要过程如下:
test_memcpy:
// 1.分配内存;
// 2.读文件到from,关闭文件;
// 3.执行memcpy(同时记录时间);
// 4.输出时间;
// 5.释放内存;
2.2 效率分析,实现代码⬇️
#include <bits/stdc++.h>
#include <sys/time.h>
using namespace std;
#define BUF_SIZE_ONE_GB 1024*1024*1024
uint8_t *from = NULL, *to = NULL;
timeval start_t, end_t;
void* my_memcpy(void *dst, const void *src, size_t n) {
uint8_t *p = (uint8_t *)dst;
uint8_t *q = (uint8_t *)src;
size_t size = n;
while (n--) *p++ = *q++;
assert((uint64_t)p - (uint64_t)dst == size);
return dst;
}
// 1.分配内存;2.读文件到from,关闭文件;3.执行memcpy(同时记录时间);4.输出时间;5.释放内存;
void test_memcpy() {
// 1. 分配内存
from = (uint8_t*)malloc(sizeof(uint8_t) * BUF_SIZE_ONE_GB);
to = (uint8_t*)malloc(sizeof(uint8_t) * BUF_SIZE_ONE_GB);
assert(from && to);
// 2. 读文件到from,并关闭文件
FILE *fp = NULL;
assert((fp = fopen("./1GB_random_file.txt", "r")));
fread (from, sizeof(uint8_t), BUF_SIZE_ONE_GB, fp);
fclose(fp);
fp = NULL;
// 3. 执行memcpy(同时记录时间)
gettimeofday(&start_t, NULL);
// memcpy(to, from, BUF_SIZE_ONE_GB);
// my_memcpy(to, from, BUF_SIZE_ONE_GB);
gettimeofday(&end_t, NULL);
// 4. 输出时间
cout << "memcpy time = " << (end_t.tv_sec - start_t.tv_sec) * 1000 +
(double)(end_t.tv_usec - start_t.tv_usec) / 1000<< "ms" <<endl;
// 5. 释放内存
free(from);
free(to);
from = NULL;
to = NULL;
}
int main() {
test_memcpy();
return 0;
}
2.3 效率分析,结果
测试结果:
-
memcpy time = 92.992ms -
my_memcpy time = 794.197ms
可以看到,拷贝1GB的内存,自己实现的速度要慢很多,但是我们可以对程序进行一些优化,加速我们自己实现的my_memcpy⬇️
3. 优化(性能 + 逻辑)
3.1 性能优化1——空间局部性
3.1.1 空间局部性优化 思路 + 代码
思路:之前的程序是一次复制一个字节,但是我们的内存空间是连续的,因此如果我们每次复制更多,或许速度会更快——直接改成uint64_t即可。
上述思路代码实现如下⬇️
void* my_memcpy_8B(void *dst, const void *src, size_t n) {
uint64_t *p = (uint64_t *)dst;
uint64_t *q = (uint64_t *)src;
n /= 8;
while (n--) *p++ = *q++;
assert((uint64_t)p - (uint64_t)dst == n * 8);
return dst;
}
这里的程序实现其实是错误的(如果n不是8的整数倍,需要对最后几个位置进行特殊处理,但是我这里懒,就不写了)。
3.1.2 空间局部性优化 结果
同样是复制1GB内存,上述程序测试结果如下⬇️
my_memcpy_8B time = 167.096ms
可以,看到速度提升了很多,但是还是系统库的2倍时间。
3.2 性能优化2——流水线优化,循环展开
3.2.1 循环展开优化 思路(原理)
思路:我们还可以进行流水线的优化,即通过循环展开,减少循环之间的数据依赖问题,提升cpu复制的并行性(这个是代码优化的常见思路,具体可以看CSAPP的第四、五、六章有关内容)。
循环展开的核心思想其实就是尽量减少多次循环之间的数据依赖问题。
试想:如果我们不进行展开,那么两次循环之间是
*p++ = *q++; // 语句0
*p++ = *q++; // 语句1
语句1中p的值,是由语句0计算得出的,而语句0的执行过程,在流水线执行中要分很多个阶段,只有当语句0更新了p的值之后,语句1才能进行流水的执行。
但是如果我们进行了循环展开,两次循环之间是:
*p = *q; // 语句0
*(p + 1) = *(q + 1); // 语句1
p += 2; // 语句2
q += 2; // 语句3
显然,经过循环展开后,语句0和语句1之间不再存在数据依赖问题,可以在流水线中近乎同时执行,语句1不需要再等待语句0的结果。——当然,也有坏处,也就是多执行了语句2和语句3的计算。
3.2.2 循环展开优化 代码
上述思路实现代码如下⬇️(我这里使用的是8路循环展开)
void* my_memcpy_unfold(void *dst, const void *src, size_t n) {
uint64_t *p = (uint64_t *)dst;
uint64_t *q = (uint64_t *)src;
n /= 64;
while (n--) {
*p = *q;
*(p + 1) = *(q + 1);
*(p + 2) = *(q + 2);
*(p + 3) = *(q + 3);
*(p + 4) = *(q + 4);
*(p + 5) = *(q + 5);
*(p + 6) = *(q + 6);
*(p + 7) = *(q + 7);
p += 8;
q += 8;
}
return dst;
}
3.2.3 循环展开优化 结果
循环展开 + 空间局部性的优化,运行时间如下。
my_memcpy_unfold time = 148.275ms
可以看到,还是提升了一些速度的,但是不多,哈哈。
性能优化到此结束,或许有更好的优化策略,但我相信库函数已经做的很好了。。。。
3.3 逻辑优化——解决内存空间重叠问题——倒着copy
3.3.1 内存空间重叠——问题描述
其实这里还有一个问题我们没有考虑到:如果dst和src对应的空间有重叠怎么办?
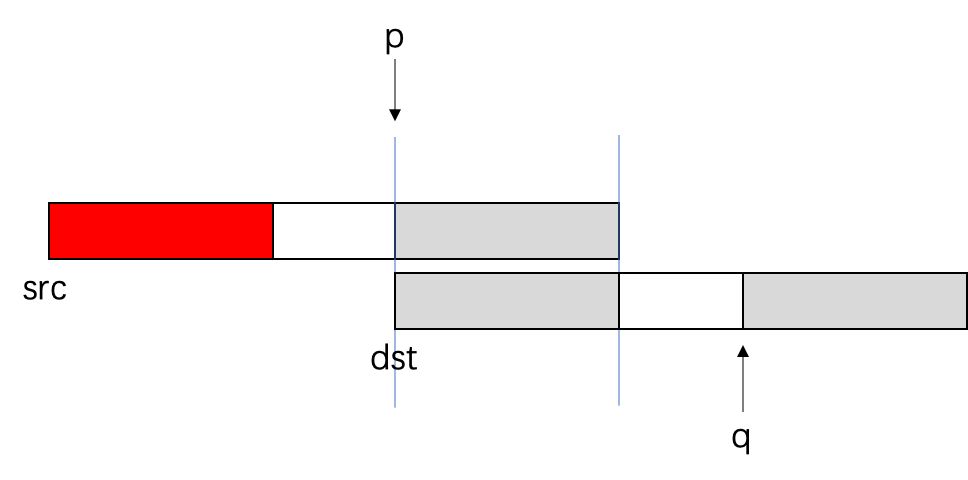
是不是云里雾里,重叠是个什么问题?看下图就明白了⬇️
- 假设src和dst的地址空间部分重叠,如下入所示,p是指向src的指针,q是指向dst的指针,红色,灰色和白色代表不同的数据(红灰数据量相同);
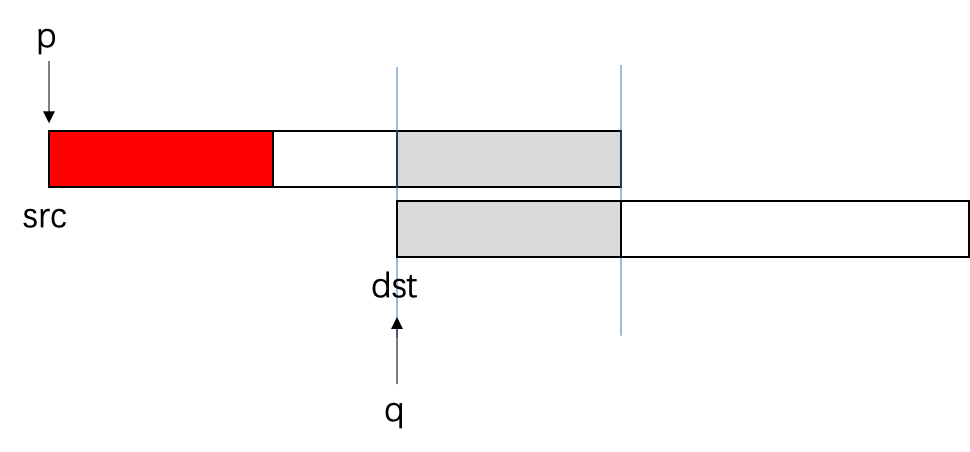
- 当p向后移动一段距离时,将会变成如下所示的内容⬇️,由于地址重叠,导致src复制前面的内容时,会覆盖src后面的内容⬇️
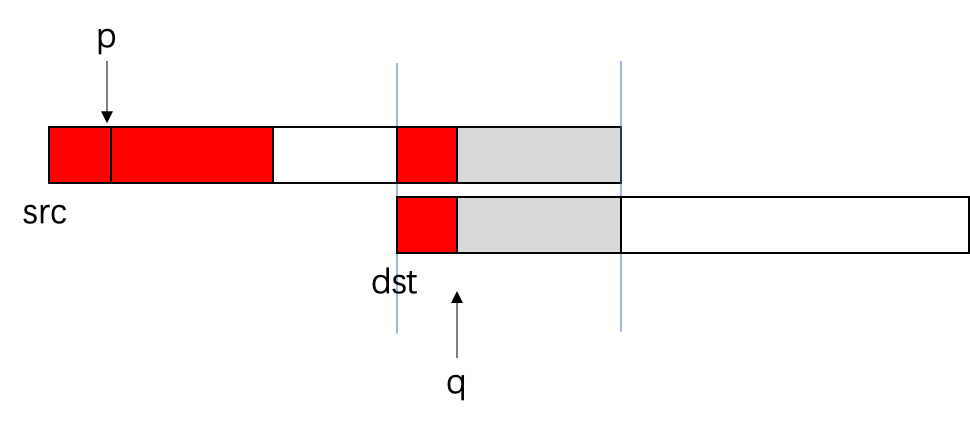
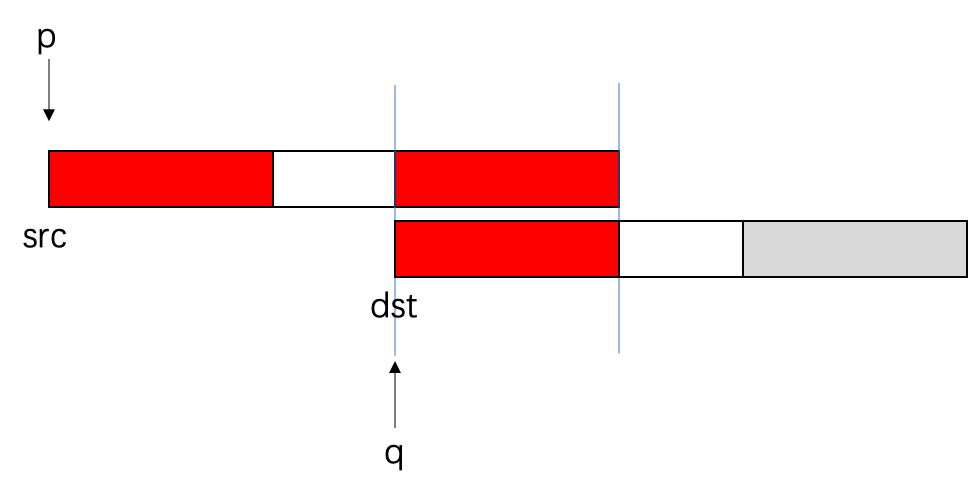
- 最终复制的结果是⬇️——发生了2点很严重的数据错误:1. src的内容被改变了;2.dst复制的内容也不是我们原来想要复制的内容。
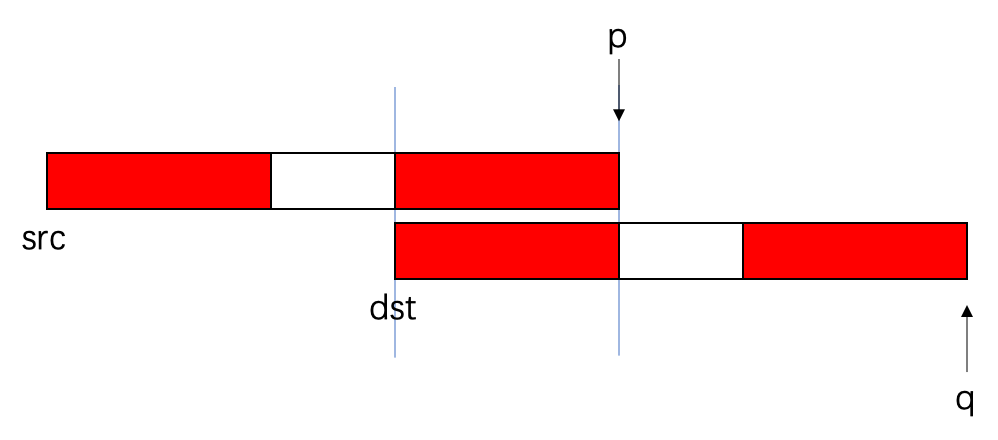
3.3.2 内存空间重叠——代码解决
内存空间重叠的解决方案很简单:从后往前倒着复制。
- 一开始我们就讲指针移动到末尾;
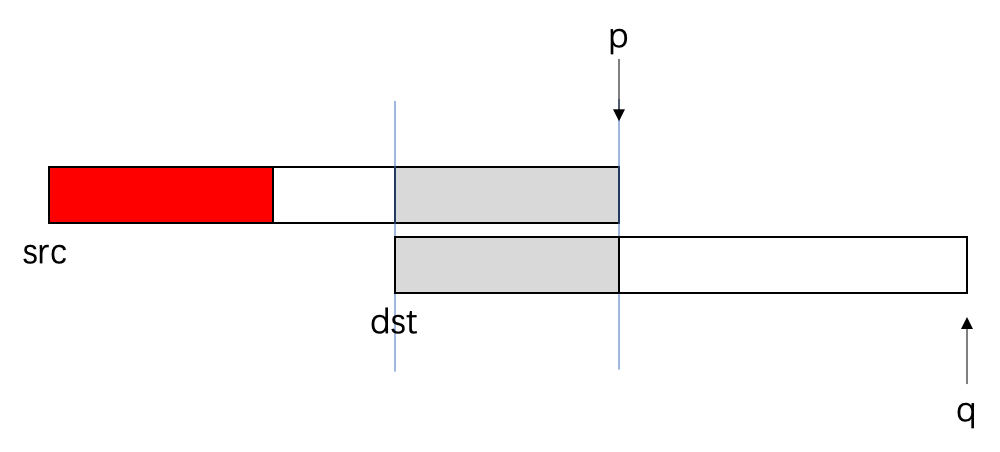
- 从后往前复制,就可以解决覆盖的问题;复制完灰色部分⬇️
- 流程结束⬇️——可以看到,dst没有出现错误,但是src仍然是被覆盖了。
上述思想的代码如下⬇️(为了和之前的内容区分开,这里用memmove作为函数名称——因为这里考虑了重叠问题,不再是cpy了,之前的内容可能被覆盖)。
void*
memmove(void *dst, const void *src, size_t n)
{
const char *s;
char *d;
s = (const char *)src;
d = (char *)dst;
if(s < d && s + n > d){
s += n;
d += n;
while(n-- > 0)
*--d = *--s;
} else
while(n-- > 0)
*d++ = *s++;
return dst;
}
PS:其实按理说,如果有重叠,就应该ret false的,保证src不被覆盖。
4. 完整例程
4.1 上述代码完整实例
代码流程:
test_memcpy:
// 1.分配内存;
// 2.读文件到from,关闭文件;
// 3.执行memcpy(同时记录时间);
// 4.输出时间;
// 5.释放内存;
代码⬇️(随机数生成文件见4.2)
#include <bits/stdc++.h>
#include <sys/time.h>
using namespace std;
// time_str
#define BUF_SIZE_ONE_GB 1024*1024*1024
uint8_t *from = NULL, *to = NULL;
timeval start_t, end_t;
void* my_memcpy_8B(void *dst, const void *src, size_t n) {
uint64_t *p = (uint64_t *)dst;
uint64_t *q = (uint64_t *)src;
n /= 8;
while (n--) *p++ = *q++;
// cout << "(uint64_t)p - (uint64_t)dst = " << (uint64_t)p - (uint64_t)dst << endl;
// assert((uint64_t)p - (uint64_t)dst == n * 8);
return dst;
}
void* my_memcpy_unfold(void *dst, const void *src, size_t n) {
uint64_t *p = (uint64_t *)dst;
uint64_t *q = (uint64_t *)src;
n /= 64;
while (n--) {
*p = *q;
*(p + 1) = *(q + 1);
*(p + 2) = *(q + 2);
*(p + 3) = *(q + 3);
*(p + 4) = *(q + 4);
*(p + 5) = *(q + 5);
*(p + 6) = *(q + 6);
*(p + 7) = *(q + 7);
p += 8;
q += 8;
}
// cout << "(uint64_t)p - (uint64_t)dst = " << (uint64_t)p - (uint64_t)dst << endl;
// assert((uint64_t)p - (uint64_t)dst == n * 8);
return dst;
}
void*
memmove(void *dst, const void *src, size_t n)
{
const char *s;
char *d;
s = (const char *)src;
d = (char *)dst;
if(s < d && s + n > d){
s += n;
d += n;
while(n-- > 0)
*--d = *--s;
} else
while(n-- > 0)
*d++ = *s++;
return dst;
}
void* my_memcpy(void *dst, const void *src, size_t n) {
uint8_t *p = (uint8_t *)dst;
uint8_t *q = (uint8_t *)src;
size_t size = n;
while (n--) *p++ = *q++;
// cout << "(uint64_t)p - (uint64_t)dst = " << (uint64_t)p - (uint64_t)dst << endl;
assert((uint64_t)p - (uint64_t)dst == size);
return dst;
}
// 1.分配内存;2.读文件到from,关闭文件;3.执行memcpy(同时记录时间);4.输出时间;5.释放内存;
void test_memcpy() {
// 1. 分配内存
from = (uint8_t*)malloc(sizeof(uint8_t) * BUF_SIZE_ONE_GB);
to = (uint8_t*)malloc(sizeof(uint8_t) * BUF_SIZE_ONE_GB);
assert(from && to);
// 2. 读文件到from,并关闭文件
FILE *fp = NULL;
assert((fp = fopen("./1GB_random_file.txt", "r")));
fread (from, sizeof(uint8_t), BUF_SIZE_ONE_GB, fp);
fclose(fp);
fp = NULL;
// 3. 执行memcpy(同时记录时间)
gettimeofday(&start_t, NULL);
// memcpy(to, from, BUF_SIZE_ONE_GB);
// my_memcpy(to, from, BUF_SIZE_ONE_GB);
// my_memcpy_8B(to, from, BUF_SIZE_ONE_GB);
// my_memcpy_unfold(to, from, BUF_SIZE_ONE_GB);
// memmove(to, from, BUF_SIZE_ONE_GB);
gettimeofday(&end_t, NULL);
// 4. 输出时间
cout << "memcpy time = " << (end_t.tv_sec - start_t.tv_sec) * 1000 +
(double)(end_t.tv_usec - start_t.tv_usec) / 1000<< "ms" <<endl;
// 5. 释放内存
free(from);
free(to);
from = NULL;
to = NULL;
}
int main() {
test_memcpy();
return 0;
}
4.2 生成随机数文件——1GB
#include <bits/stdc++.h>
using namespace std;
// 1GB
#define RANDOM_FILE_SIZE 1024*1024*1024
// 最简单的实现思路,每次随机生成一个0~255的数字,然后写入到文件中;
// 其实可以做很多优化,比如写uint64_t,再比如给一个buffer,再写入到文件;
void generator() {
FILE *fp;
fp = fopen("./1GB_random_file.txt", "w+");
assert (fp);
srand(time(NULL));
uint8_t _ran = 0;
for (int i = 0; i < RANDOM_FILE_SIZE; ++i) {
_ran = random() % 256;
fputc(_ran, fp);
}
fclose(fp);
return ;
}
int main() {
generator();
return 0;
}
4.3 说明
上述程序需要占用2GB内存空间 + 1GB磁盘空间,如果内存 / 磁盘不够用,请修改宏定义中的随机数文件大小。

一站式 AI 云服务平台
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)