
ECCV2024论文解读|VideoMamba: State Space Model for Efficient Video Understanding 用于高效视频理解的状态空间模型
本文提出了VideoMamba,一种基于状态空间模型(SSM)的视频理解模型,旨在解决视频理解中的局部冗余和全局依赖问题。VideoMamba通过其线性复杂度算子,实现了高效的长期建模,这对于高分辨率长视频的理解至关重要。该模型在无需大量数据集预训练的情况下,展现了在视觉领域的可扩展性、对短期动作的敏感性、在长期视频理解中的优越性以及与其他模态的兼容性。广泛的评估表明,VideoMamba在处理短
论文标题
VideoMamba: State Space Model for Efficient Video Understanding
VideoMamba:用于高效视频理解的状态空间模型
论文链接
论文作者
Kunchang Li,Xinhao Li,Yi Wang,Yinan He,Yali Wang,Limin Wang,Yu Qiao
内容简介
本文提出了VideoMamba,一种基于状态空间模型(SSM)的视频理解模型,旨在解决视频理解中的局部冗余和全局依赖问题。VideoMamba通过其线性复杂度算子,实现了高效的长期建模,这对于高分辨率长视频的理解至关重要。该模型在无需大量数据集预训练的情况下,展现了在视觉领域的可扩展性、对短期动作的敏感性、在长期视频理解中的优越性以及与其他模态的兼容性。广泛的评估表明,VideoMamba在处理短期和长期视频内容方面均表现出色,且所有代码和模型均已开源。
分点关键点
1.创新的模型架构
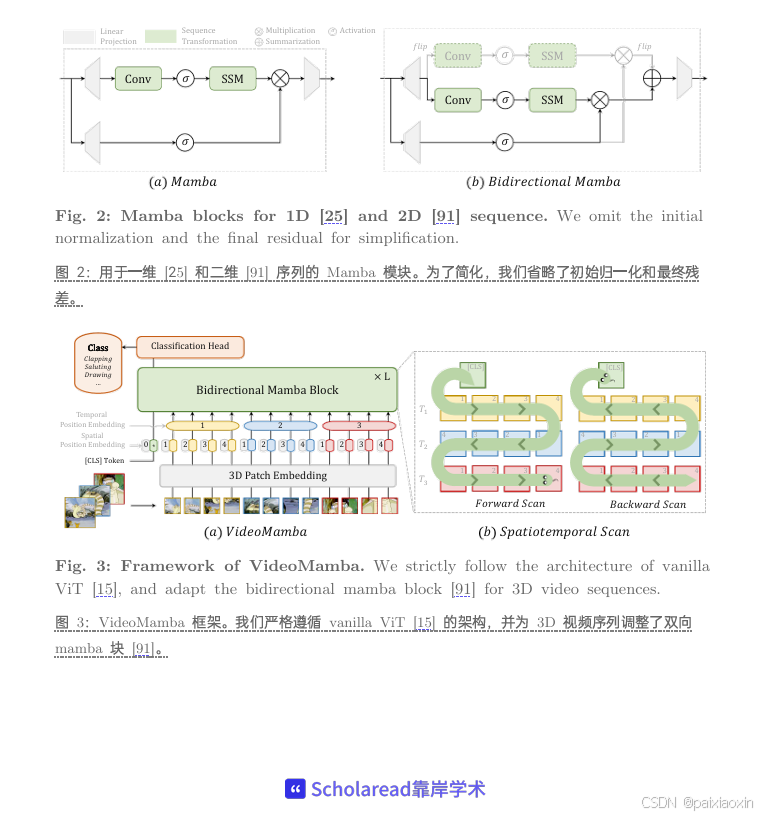
VideoMamba采用纯SSM基础架构,巧妙融合了卷积和注意力机制,提供了一种线性复杂度的动态时空上下文建模方法,特别适合高分辨率长视频。
2.无需预训练的可扩展性
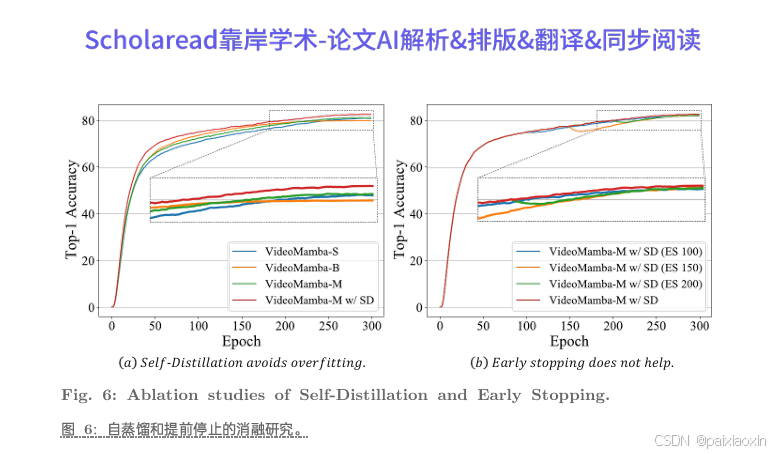
通过新颖的自蒸馏技术,VideoMamba在模型和输入尺寸增加时能够实现显著的性能提升,无需进行大规模数据集预训练,有效解决了纯Mamba模型容易过拟合的问题。

3.短期动作识别的敏感性
VideoMamba能够准确区分短期动作,即使动作差异细微,如“打开”和“关闭”。其性能优于现有的基于注意力的模型,并且适用于掩码建模,进一步增强了时间敏感性。
4.长期视频理解的优越性
在长期视频理解方面,VideoMamba通过端到端训练,显著优于传统基于特征的方法。与TimeSformer相比,VideoMamba的运行速度快6倍,GPU内存需求仅为1/40。
5.多模态兼容性
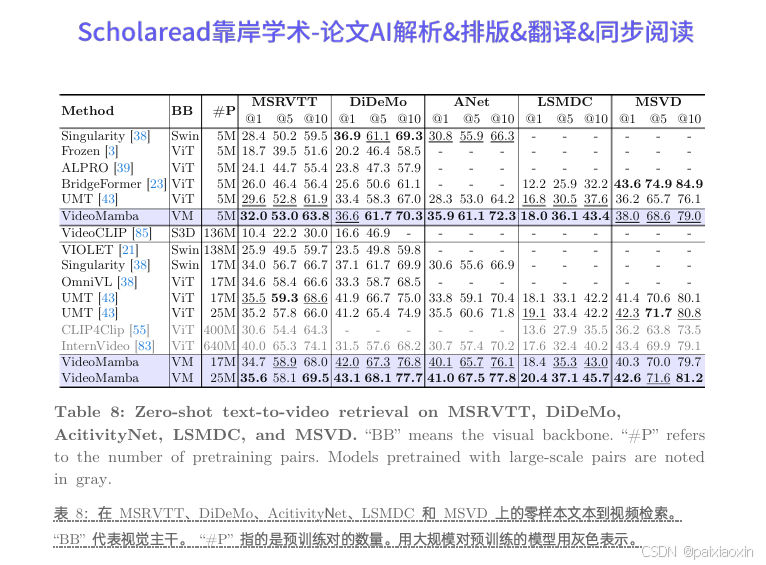
VideoMamba在视频-文本检索等多模态任务中表现出色,特别是在长视频和复杂场景中,展现了强大的鲁棒性和多模态集成能力。
论文代码
https://github.com/OpenGVLab/VideoMamba
ECCV-3DGS论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!

一站式 AI 云服务平台
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)