
[Classifier-Guided-Expand] More Control for Free! Image Synthesis with Semantic Diffusion Guidance
过去的text-to-image生成方法需要image-caption对进行训练,无法用在没有text annotation的数据集上本文用一个统一的框架,可以选择用reference image / language / language + image指导图像生成模型。
1、目的
过去的text-to-image生成方法需要image-caption对进行训练,无法用在没有text annotation的数据集上
本文用一个统一的框架,可以选择用reference image / language / language + image指导图像生成模型
2、方法
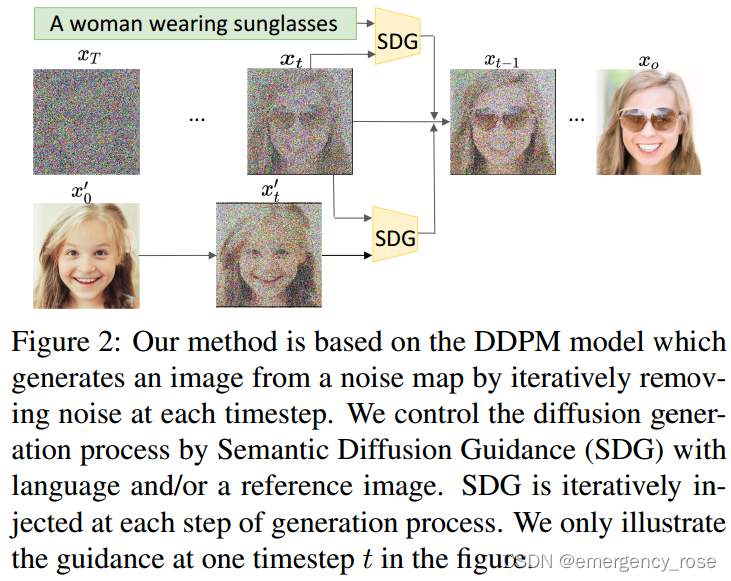
Semantic Diffusion Guidance (SDG)
1) 无需重新训练无条件DDPM,只需要训练CLIP finetune
-> 将BN层替换为adaptive BN层,以时间t作为condition
-> 自监督(contrastive objective,和
,其中
参数固定,
在噪声图像上finetune),无须text annotations
2) guidance
![]()

是用额外的timestep input上的噪声图像训练的image encoder
-> language guidance
是text encoder
![]()
用finetune过的CLIP预测image-text matching score
-> image guidance
content:
![]()
如果需要生成的图片和参考图片有相似的结构,可以用
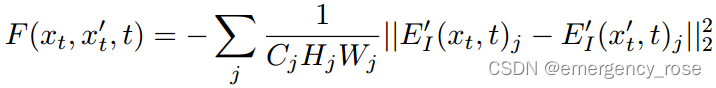
style
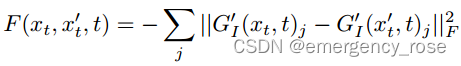
-> multimodal guidance
![]()

一站式 AI 云服务平台
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)