
多模态视觉任务Video Grounding介绍
Video Grounding不太好找到较好的中文翻译,grounding有“接地、基础”等意思。对于video grounding:输入:一个query(文本),以及一段视频。返回:文本所描述的活动的开始时间和结束时间
·
Video Grounding不太好找到较好的中文翻译,grounding有“接地、基础”等意思。
对于video grounding:
输入:一个query(文本),以及一段视频。
返回:文本所描述的活动的开始时间和结束时间
乍一看这不就是TAL(temporal activity localization)么?!实际上不是的,VG是需要理解文本的,相当于CLIP与TAL的结合。
我们看一下英文描述: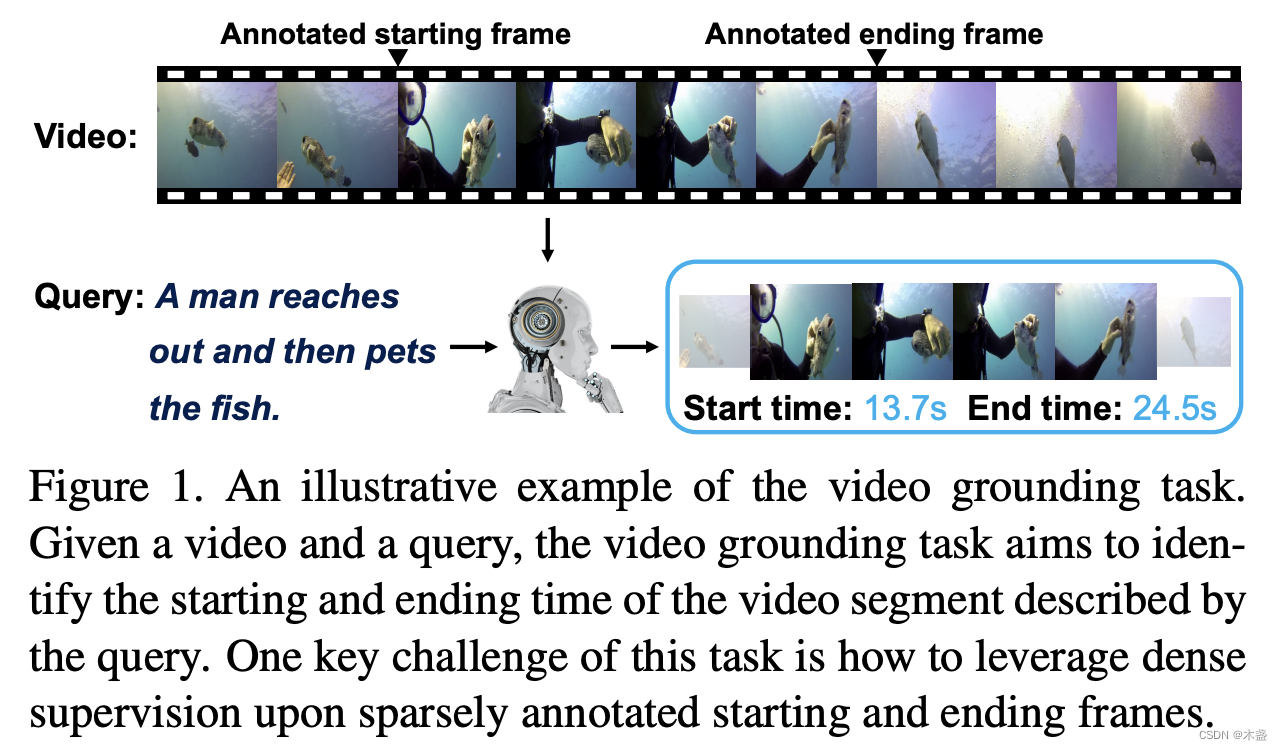
Figure 1. An illustrative example of the video grounding task.Given a video and a query, the video grounding task aims to identify the starting and ending time of the video segment described by the query. One key challenge of this task is how to leverage dense supervision upon sparsely annotated starting and ending frames.

一站式 AI 云服务平台
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)