
AnythingLLM本地知识库避坑指南+配置攻略(引用好文)
在AnythingLLM中调用DeepSeek R1 API 加持本地知识库 基于AnythingLLM构建的知识库下,离开DeepSeek R1 API 加持的本地知识库都是个渣渣,在深度踩坑后,发现了2个“残酷的”RAG真相。问错问题=如入天坑,原以为是Bug,还得到了来着AnythingLLM官方社群的“贴心答复”,以正三观。在部署AnythingLLM+DeepSeek R1的本地知识库方
一、前言
在AnythingLLM中调用DeepSeek R1 API 加持本地知识库 基于AnythingLLM构建的知识库下,离开DeepSeek R1 API 加持的本地知识库都是个渣渣,在深度踩坑后,发现了2个“残酷的”RAG真相。 问错问题=如入天坑,原以为是Bug,还得到了来着AnythingLLM官方社群的“贴心答复”,以正三观。 在部署AnythingLLM+DeepSeek R1的本地知识库方案后,凭借其简单、快速、小白友好、无代码压力等优势,精益新生小A快速利用春节假期进行更多的尝试和探索。 特别是,在尝试过用AnythingLLM+DeepSeek R1的本地知识库 进行:
行业报告解读:极简的个人AI知识库搭建——一个真实案例了解用AnythingLLM+DeepSeek构建本地知识库的用法及能力 - 知乎 数据分析和洞察: 再不学Python都来不了, AnythingLLM+DeepSeek R1 本地知识库也能做数据分析和洞察了 本地知识问答: 大模型本地知识问答大战深圳航空官方客服?AnythingLLM + DeepSeekR1 本地知识库做客服问答应用 精益实战-产能分析: 努力写了两周的报告竟然没打过DeepSeekR1推理模型3分钟,AnythingLLM+推理模型在设备产能利用评估及管理上的启发 等几个卓有成效的落地场景后,惊讶于DeepSeek 卓越的能力。顿时感觉——“AI上天,什么都能起来了”。 但随着更深和更多场景的探索,才发现“入坑不浅”。特别是阅遍各大平台各大牛博主的文章后,几乎全部都是聚焦在“如何部署AnythingLLM本地知识库并快速上手”或专业开发人员领域的“RAG实战”,鲜有对普通纯应用user的“深度探索并分享应用技巧”。 下面就分享精益新生小A探索AnythingLLM本地知识库中的部分坑及相关“RAG真相(2025年2月时刻)”。
二、初始认知(误区)
如前所述,在解锁4大经典成功应用本地知识库场景后,顿时感觉:如获至宝,LLM在手,RAG无所不能。 于是探索:
- 【电子书解读】 可否丢一本电子书进AnythingLLM, 让DeepSeek直接帮我详细解读电子书的任意章节及关键概念?
- 【全文搜索问答】 可否像“全文搜索”一样,对着加载进知识库的文章/书籍/笔记,深度检索并基于问题重构生成?
- 【复杂数据分析】 除上文验证过的“简单数据分析及洞察”外,做量更大、更复杂的数据分析?
- 【成体系的知识问答】 短的政策文章可以实现经典问答,那长的完整应用主题的知识问答,可否胜任?
在通过【场景重现】-【参数调整】-【结果对比分析】-【查找关联原理及流程】-【得出初步结论】的若干折腾后,发现了两个“残酷的真相”。
残酷真相1:哪怕是已成功验证的4个应用场景, 在离开“DeepSeek R1 API"(因被攻击后API功能未得到恢复)的加持后, 那些本地部署的模型在AnythingLLM里的表现,就是个“渣渣”。——部署并打通流程很简单,取得卓有成效的实战效果强依赖于LLM的理解-检索-推理-生成等底座能力。 残酷真相2:RAG世界里目前(2025年2月)暂时 没有“一招鲜、吃遍天”的神奇魔法,在单应用的某些场景下具有稳定输出能力的RAG核心技术仍掌握在少数“专业大厂”手里,无一不是经过了复杂的“策略优化-管道设计-训练-调优-发布”等专业开发流程。开源应用框架提供了发现或探索真理的机会,但目前:臣 - 妾 -做-不-到。
2.1、怎么就“离开DeepSeek R1 API”的加持,本地知识库就是渣渣了?
在【场景重现】时,重点对“SmartPet产量数据分析洞察”的案例进行重现探索。由于DeepSeek爆火后,持续被海外攻击,直至今日(大年初七)开工前夕,仍未恢复API申请和使用功能。 在部署了若干本地模型后,进行对比尝试。
- 调用“DeepSeek R1 API”(俗称:在线满血版R1),可以精准的解析上传的excel文件及数据,并回答问题,详见[ 再不学Python都来不及了,AnythingLLM+DeepSeek R1 本地知识库也能做数据分析和洞察了 ];
- 调用“ DeepSeek-R1-Distill-Qwen-14B ”在数据解析上的很难做到精准。
再用本地模型重现其他几个场景时,得到的结果基本一致:难以匹敌“DeepSeek R1 API(俗称:在线满血版R1)”的“接近完美的表现”。 因此,再次致敬:期待DeepSeek API的恢复,解锁更多可靠场景!
2.2、为什么“AnythingLLM”打造的是“本地知识库”,本地体现在哪里?
整体上,“本地” 的体现:知识在本地,大模型部署在本地,运算在本地,结果在本地。
- 数据存储位置在本地 :AnythingLLM中的各类文档、资料等知识数据上传后,都是在本地进行存储-分切-向量嵌入的,保存在我们自己可控制的本地环境中。
- 模型运行环境在本地 :如【】文所述的,通过 Ollama 等工具部署在本地设备并依赖本地算力的模型,在本地。但严格意义上“调用了API”的不算在本地,属于 “云计算” 。
- 应用程序部署 :AnythingLLM 本身是可以安装在本地电脑上的全栈应用程序,有本地的用户界面和交互环境,用户在本地即可进行知识库的创建、管理、查询等操作,无需通过网络访问远程的应用程序界面。 但AnythingLLM支持cloud部署 ,暂未探索。
2.3、那怎样查看和查找本地结果呢?
1. 本地对话记录 可以通过“小扳手标志的“配置”——“管理员”——“对话历史记录”,导出“工作区聊天历史记录”,支持csv和json格式,小A君通常导出用json格式,用sublime text 打开查看(或在Python中)。

2. 本地存储文件夹 所有AnythingLLM存储文件的地址是:C:\Users\user\AppData\Roaming\anythingllm-desktop\storage
2. 本地存储文件夹 所有AnythingLLM存储文件的地址是:C:\Users\user\AppData\Roaming\anythingllm-desktop\storage
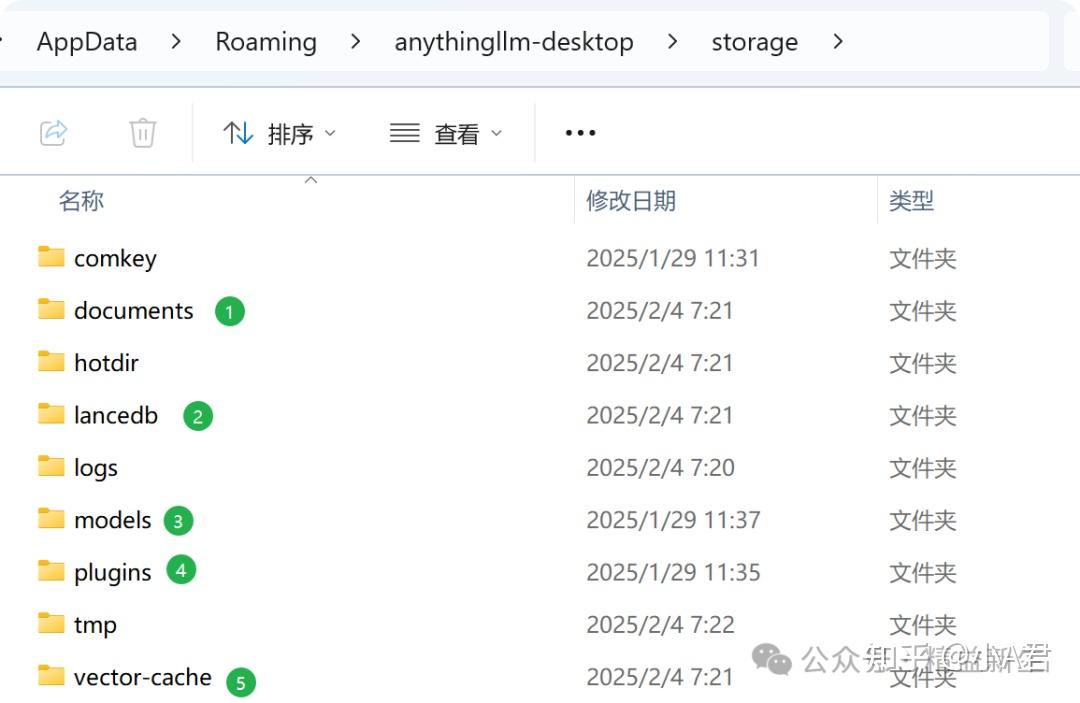
AnythingLLM (1.7.x 版本) Storage各文件夹存储内容整理如下: 以下是 AnythingLLM 本地存储文件夹 Storage 中子文件夹的整理表格,包含各文件夹的作用和存储内容:
其中,在探索RAG中,最具参考(学习)价值的是documents下的chunking分切后的文件,例如,打开一个可以获得以下信息:
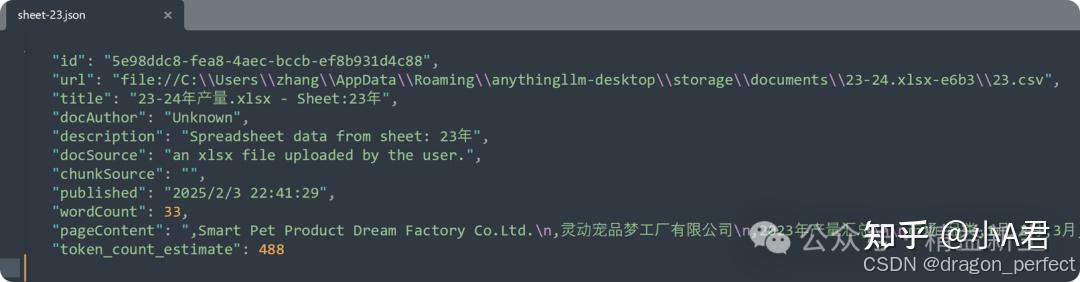
比如,
-
word count:文档的字符数;
-
token_count_estimate: 文档经分切后的token数量。
-
pagecontext:文档分切的上下文。
这个文档,非常有助于小白、初学者,理解本地知识库RAG增强检索生成的流程和逻辑。
问错问题=入天坑,有你中招的情况没?
下面的情况我全部碰到了:
-
"为什么总搜不到答案?" -想把知识库当全文搜索用。
-
"结果驴唇不对马嘴" ……出现大V嘴里常说的“幻觉”了。
-
“睁眼瞎” ……明明资料里有,而且上下文片段里也有,可就说“在上下文中找不到”。
-
“数字数” ……想让RAG来数一数文档字数,这绝对是来“捣乱的”。
-
“从头查到尾,跨整篇文章找“次数”或“列出所有人名”一类 ……这种问题,一旦容易出现“文本截断”就挂了。
期初根本不理解本地知识库的原理,以为是出Bug了…… 在频繁遇到“文本截断”问题后,以为是AnythingLLM出Bug了,小A后者脸皮竟然将这个问题发在了官方的github的社区里: **[Mintplex-Labs/anything-llm] [BUG]: " --prompt truncated for brevity--".When Uploading Long Files, (Issue #3035)** 我提交的问题(大佬就略过吧,简直太初级, 哈哈):
Q: When I uploading a txt file or pdf file (a report or a chapter of book), use the default setting (Text Chunk Size=512, Text Chunk Overlap=38), the default AnythingLLM Embedder, with LanceDB Vector Database.I see the Vector Count is around 100 -300.it can successfully embedded, When I ask the following questions, it always answers wrong.what is the key context about, how many words in the context? How many truncate labels in the context? where are they? Can you find "XXX" in the context?
来着官方社区的回答:
LLMs are not calculators and also you are asking for full context comprehension in a RAG system. RAG, by its very nature is pieces of relevant content. Not the entire text How many truncate labels in the context? where are they? Again, would require the full text to know Can you find "XXX" in the context? This also would require the full text, but could work in RAG, but unlikely. You should read this doc about how all RAG systems work: https://docs.anythingllm.com/llm-not-using-my-docs#llms-do-not-introspect Additionally, the --prompt truncated for brevity--is not a problem, it's actually helping you from having a problem. Your LLM does not have a large enough context window to fit all of your documents into it. If we just let that happen your computer would either lock up totally from RAM and CPU going to 100% or the LLM would just fail. You cannot fit an infinite amount of text into an LLM, not even the largest models can accomplish this - there is always a limit. RAG (which is what we use) enables us to chunk the document and then ask retrieve only the bits and pieces the make sense for your question and use that in the context window. This makes larger documents easier to use, but it is at the expense of these types of "whole document" understandings. Instead you should ask questions about the content not the document itself. The LLM has no idea what a document is, what it looks like, how many pages, and not the entire text. The only way to even accomplish this is using those very large context models like Gemini (2M) or Anthropic - again they still have limits and ingest that many tokens at once is expensive. Thus why RAG exists.
这段内容,可能值得部署了本地知识库的新手们——仔细研读,校正认知。
三、收货及思考
大模型时代,好问题胜过好答案; 同样,本地知识库:问错问题=入天坑,找错对象了。 心得:本地知识库好像是"超级资料员",但不是“全文检索器”,更非"全能决策者"。 用好它的核心在于:明确边界,扬长避短,人机协同。
3.1、PartII-配置攻略!AnythingLLM本地知识库你用的还好吗?部署后必看(二)极简RAG流程原理及配置参数入门(附:极简流程图)
本地知识库的潜力与挑战:部署容易,用好^有点难。 常见问题:“睁眼瞎”、“幻觉”、“回答不准确”背后的原因。 本文目标:有必要了解一点点点的 RAG检索增强生成的基本流程和原理,帮助解决实际应用中的困惑。
友好的AnythingLLM 1.7.x 默认配置并采用调用API的方式时,几乎不需要改任何参数。 但当遇到“睁眼瞎”或“幻觉”或“回答的不好”的时候,我们需要了解一点点RAG检索增强生成的基本流程和原理,来解答我们初学者(应用者)的困惑。
在经历了AnythingLLM构建的本地知识库“一些场景处理的非常棒”和“一些问题根本做不好”的探索后,精益新生小A带着好奇和疑问,继续学习和探索,打开了RAG的一扇窗(不敢说推开了一扇门……太太太复杂了)
在上一篇【【避坑指南!AnythingLLM本地知识库用的还好吗?】部署后必看(一)问错问题=入天坑(附社区答复及本地存储文件夹解读)】的文章中,我总结了各种“对RAG不友好的问题(RAG不太可能回答好的问题)”,以及一个“误把文本截断当成软件Bug且得到AnythingLLM官方社区的细致解答”的情况,
3.2、目的:
了解为什么本地知识库问答会出现“睁眼瞎”和“一本正经的胡说八道”,使我们一般用户能够“问对问题”,不至于纠结一些“小”问题点,在当前的“RAG框架能力”下,更好的使用。
注:不排除也非常期待2025年可以有“更聪明的、兼顾长短大小的、一招鲜吃遍天的RAG技术突破”
3.3、极简原理(理解版)
当我们用大模型进行一般性提问时,大模型问答(LLM-AIGC)是这样的;
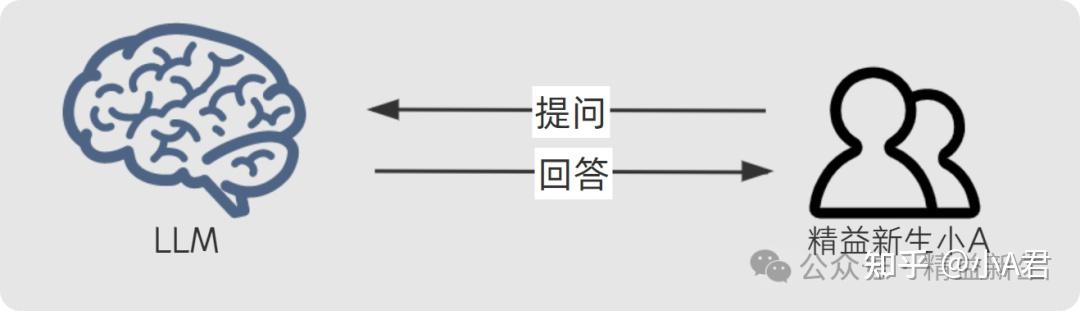
当我们要结合自己的知识材料,进行所谓“本地知识库检索增强生成RAG”是这样的:

RAG检索增强生成独特之处,就在与对本地知识的“学一下”和“找一找”。 那RAG检索增强的“学一下”和“找一找”和最直接的全文搜索查找有何不同呢? 据我的理解,全文搜索和增强检索“路径不同”,前者是通过直接的“找字词、对对碰”的方式查找并匹配,后者是通过 “算距离-找相近”的方式“学习并检索”。

更详细的说,是“访问对象不同”,一个是“字符”,一个是“数据”,更准确的说是“向量数据”。
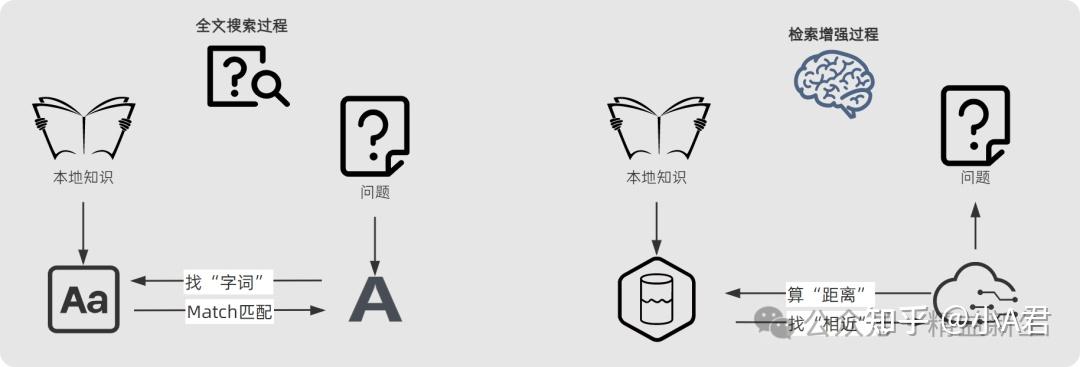
大预言模型的“学一下、理解一下”的神奇魔法之一可能就在这里了:人脑理解文字,电脑擅长计算“数据”,用向量化链接人脑的文字及语义及计算机理解的“数据最小、距离最近”…… 更进一步的问题:RAG是如何把本地知识的文字,向量化成大预言模型可以检索的“向量”呢?完整过程是这样的:
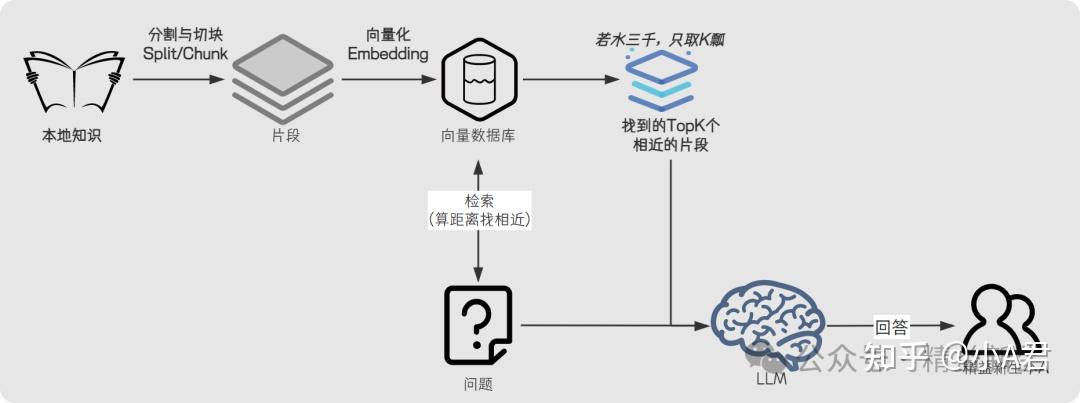
这就是进一步理解,AnythingLLM答疑回复的:
LLMs are not calculators and also you are asking for full context comprehension in a RAG system. RAG, by its very nature is pieces of relevant content. Not the entire text LLM是 不是计算器,而且您在RAG系统中要求 全文(完整的上下文)理解。RAG,就其本质而言,是相关内容的 片段, 不是整个文本.
那有没有一种,即可以全文搜索,又可以增强检索的 “改进型RAG”呢,好像有,我问过DeepSeek了,好像叫“混合增强检索”(尴尬的笑)……
3.4、AnythingLLM中的几个关键参数和配置
其实,带着“文本截断”一个问题,就把整个“RAG管道”理解了一遍。

LLM脑容量=上下文大小,单位Tokens. 结合这个流程,基本可以看到:
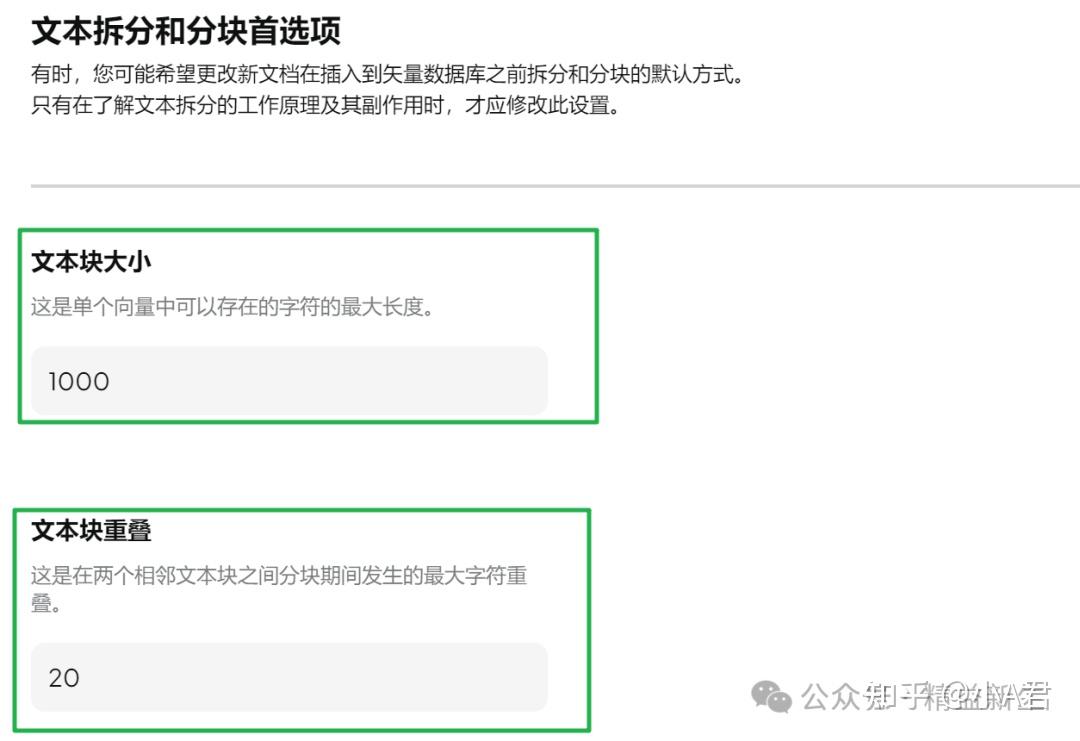
1 、分块处理
- 分块是为了向量化,在分块和向量编码的环节,要基本确保: 分块大小 ≤ embedding模型极限
- 在确保 分块大小 ≤ embedding模型极限 的前提下:
分块太大:细节抓不住; 分块太小:切的太碎,上下文连贯不好。
- 问了一众大佬,没有给具体设定参数的,但精益新生小A试过以下几个参数:
- 256
- 512
- 1000
- 2000
在AnythingLLM中,设置该参数在设置-文本分割-文本拆分和分块设置:
那下个问题:哪里可以查Embedding模型的能力大小?
2 、Embedding 嵌入向量模型
在Ollama Models中可以搜索到向量模型,

以nomic-embed-text 为例,点开这个“model”里面是模型参数:
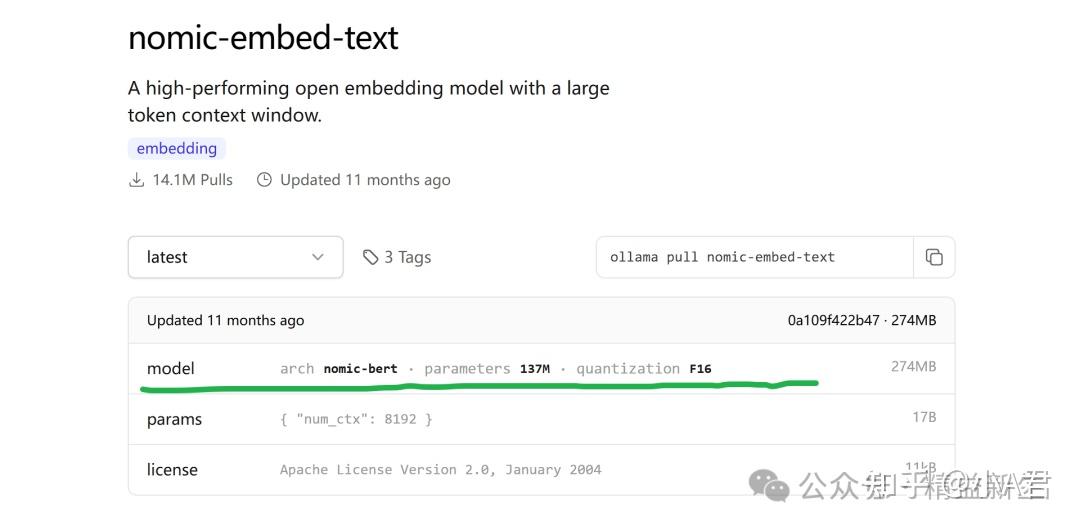
找到 context_length 就是了。
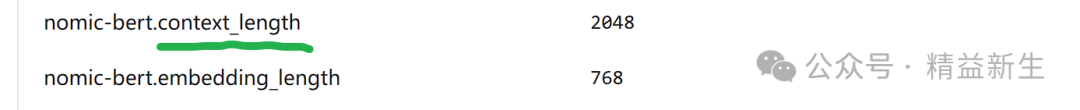
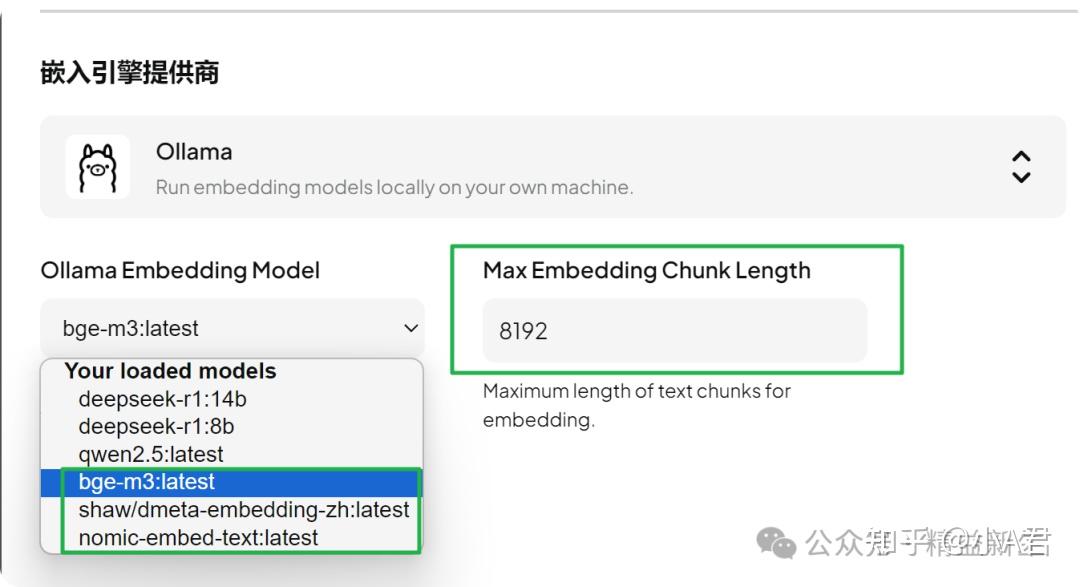
在AnythingLLM中,设置该参数在设置-Embedder嵌入首选项-选择模型-设置Max Embedding Chunk Length:
3、 TopK检索召回:
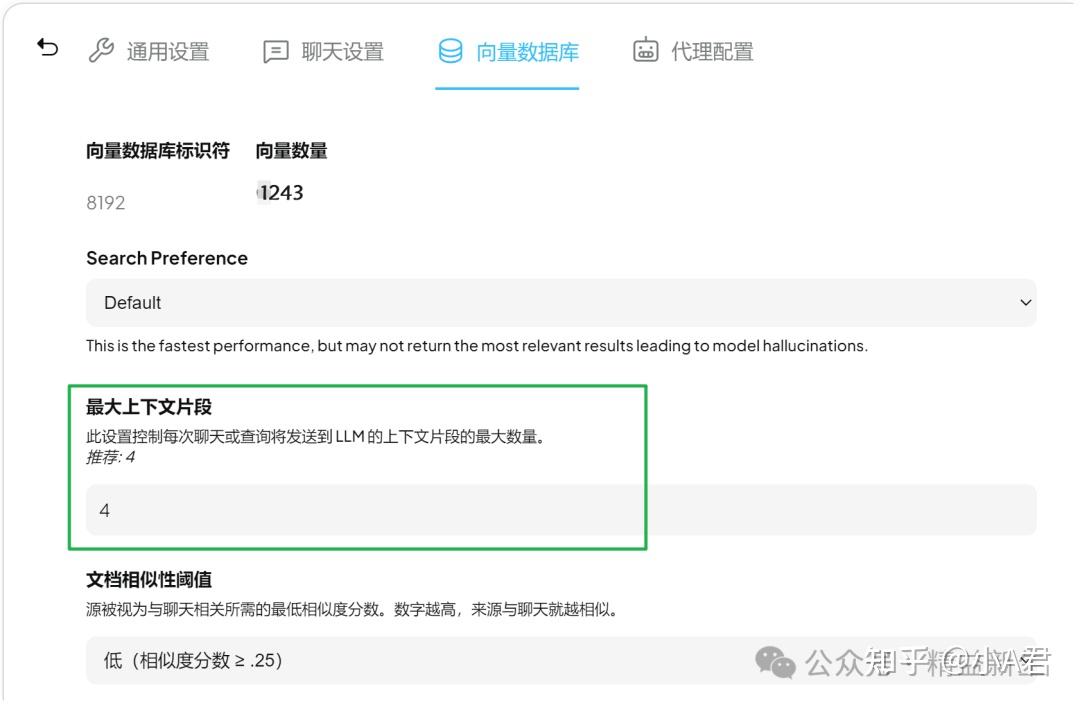
TopK,即每次检索从所有的向量片段中返回多少个与Query最相似的片段,在AnythingLLM中,该值是基于工作区设置的,在工作区-点齿轮-向量数据库-可以看到默认和推荐的值是4.
在一些其他平台的配置中,有一个推荐区间,比如3-20. 是不是找到的片段越多就越好呢?不是的:
TopK 值过大,会增加计算成本、引入噪声干扰、稀释关键信息 TopK过小,信息不完整,性能受限。
对于一些常见的问题,5-10 个片段可能就足以提供足够的信息来生成一个较为准确和完整的回答。 这里,就回应上一篇文章中提到的误区:
- RAG是“若水三千,只取K瓢”,尽量不要让RAG干依赖于完整知识文档才能做对的事儿,比如“数字数”。
4 、LLM 大模型首选项
LLM提供商,在AnythingLLM中可以任意设置,既可以调用API,也可以调用本地部署的。 在部署本地LLM后,Max Tokens依然要根据模型本身的能力上限来设置。例如:
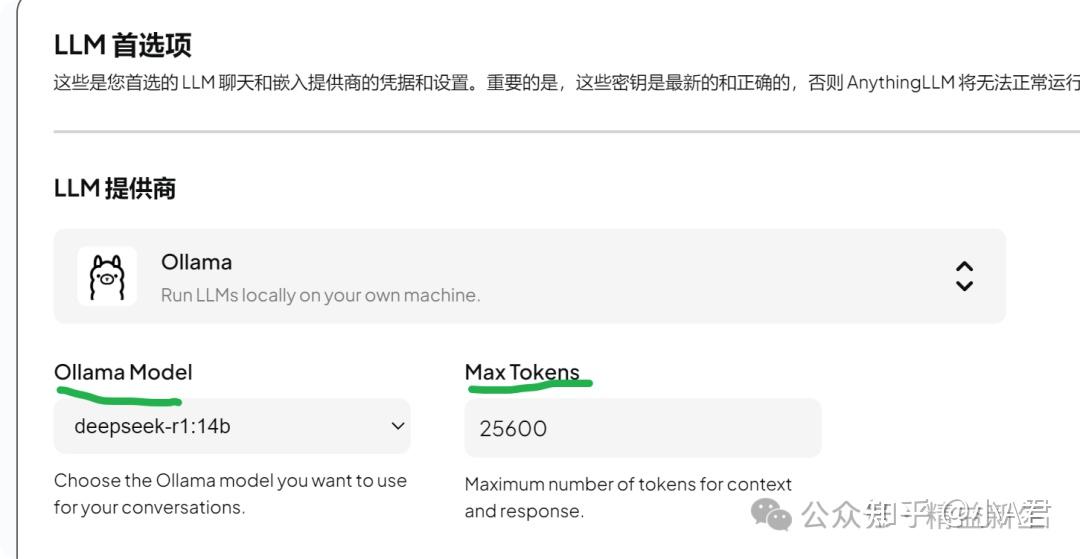
如何查看所部署模型的具体Max Context Tokens 呢? 依然是通过Ollama网站-模型搜索-查看models参数: 例如:DeepSeek-R1-Distill-Qwen-14B qwen2.context_length =131072, 即传说的128K。

四、减少“幻觉”的设定技巧
使用AnythingLLM后,技巧有3个:
- 文档Save& Embed后,点击“pin”。
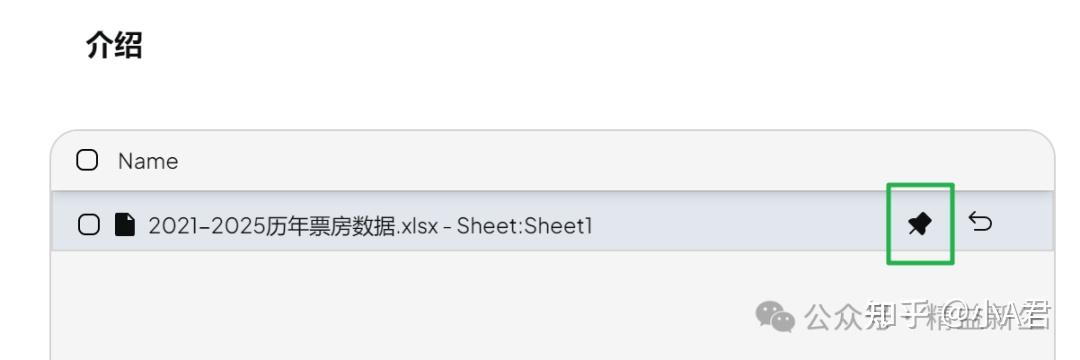
- 在工作区-小齿轮-聊天设置中,切换“聊天”为“查询”

- 在对话的问题中:仍然加上“请严格根据上下文回答……或, 请部分适当引用原文回答 ”。
五、总结
作为使用者,非RAG开发从业者,了解了基本的“本地知识库RAG检索增强生成”的流程和原理,可以更好的面对“能”与“不能”。

下面是一张经典的网络公开搜索获得的原理图,供大家参考学习。
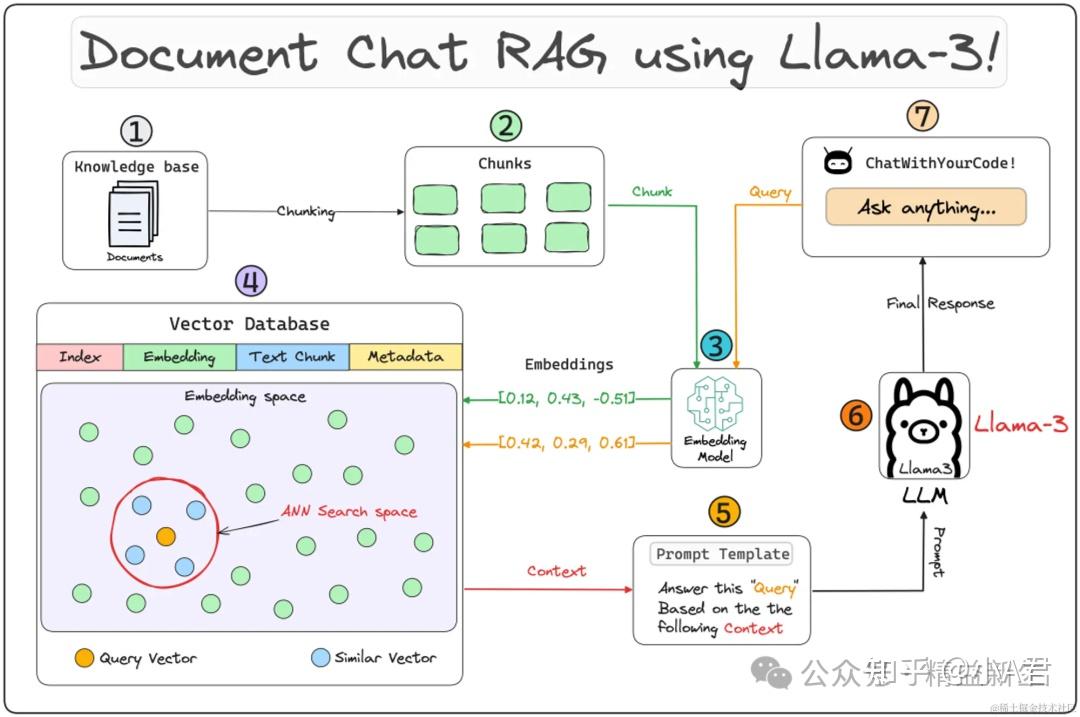
本图片来自于公开网络,归原作者。

一站式 AI 云服务平台
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)