
企业级私有知识库搭建全攻略:RAGFlow+DeepSeek本地部署实战(附实测数据+高清截图)
本文详细介绍了如何通过RAGFlow和DeepSeek搭建企业级私有知识库,涵盖从环境搭建到智能问答的全流程。文章首先对比了RAGFlow和DeepSeek的核心能力,并列举了典型应用场景。接着,提供了服务器初始化、Ollama部署、DeepSeek-R1 8B模型拉取、RAGFlow引擎部署的详细步骤。最后,展示了如何快速创建知识库、配置模型、解析文档,并创建智能助理。文章还提供了8B模型的性能
·
🔥企业级私有知识库搭建全攻略:RAGFlow+DeepSeek本地部署实战(附实测数据+高清截图)
一、前言
在数据安全合规要求日益严格的今天,企业如何构建一个低成本、高安全、易扩展的智能知识库?本文将通过16张实操截图+5000字保姆级教程,带你从环境搭建到智能问答全流程落地,文末附8B模型实测性能数据与一键部署镜像,新手也能3小时搞定!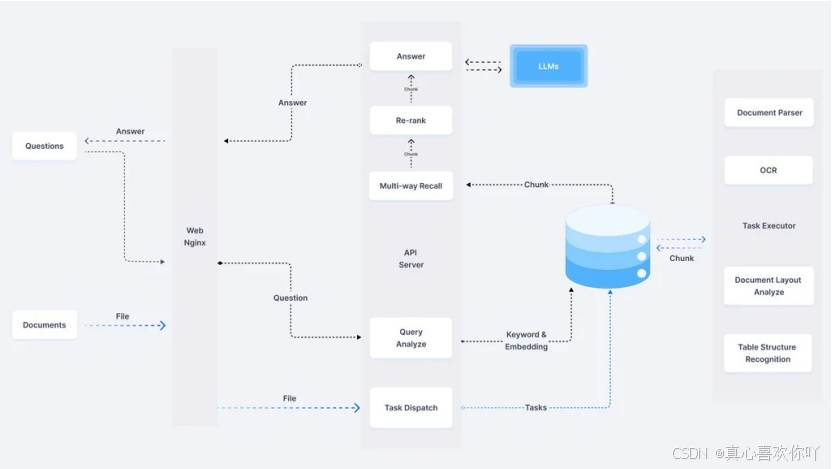
二、方案选型:为什么是RAGFlow+DeepSeek?
🌟核心能力对比表
| 维度 | RAGFlow | DeepSeek-R1 8B |
|---|---|---|
| 文档支持 | PDF/Excel/PPT/Markdown等12种格式 | 无格式限制(依赖RAGFlow解析) |
| 向量检索 | Elasticsearch+Milvus双引擎 | 支持8K上下文窗口 |
| 部署成本 | 开源免费,最低配置仅需1台8核服务器 | 显存占用4.9GB,消费级显卡(GTX 1080+)可用 |
| 安全特性 | 局域网部署、用户权限分层、数据加密存储 | 无云端通信接口,纯本地化运行 |
🚀典型应用场景
- 场景1:HR知识库:自动解析劳动合同、考勤制度等文档,员工可通过自然语言查询“年假申请流程”
- 场景2:研发文档中心:索引代码注释与架构图,工程师提问“如何调用支付接口”可秒级返回关联文档
- 场景3:客户支持系统:对接工单系统,客服输入“设备故障代码E001”自动触发知识库响应
三、环境搭建:从服务器初始化到工具安装
🖥️服务器初始化(Ubuntu 24.04 LTS)

# 1. 更新系统并安装基础工具
sudo apt update && sudo apt upgrade -y
sudo apt install -y openssh-server net-tools curl
# 2. 安装Docker(含Compose)
curl -fsSL https://get.docker.com | sh
sudo apt install docker-compose
🔧Ollama部署:本地模型管理中枢
① 一键安装与远程配置
# 安装命令
curl -fsSL https://ollama.com/install.sh | sh
# 永久开启远程访问(修改服务配置)
sudo nano /etc/systemd/system/ollama.service
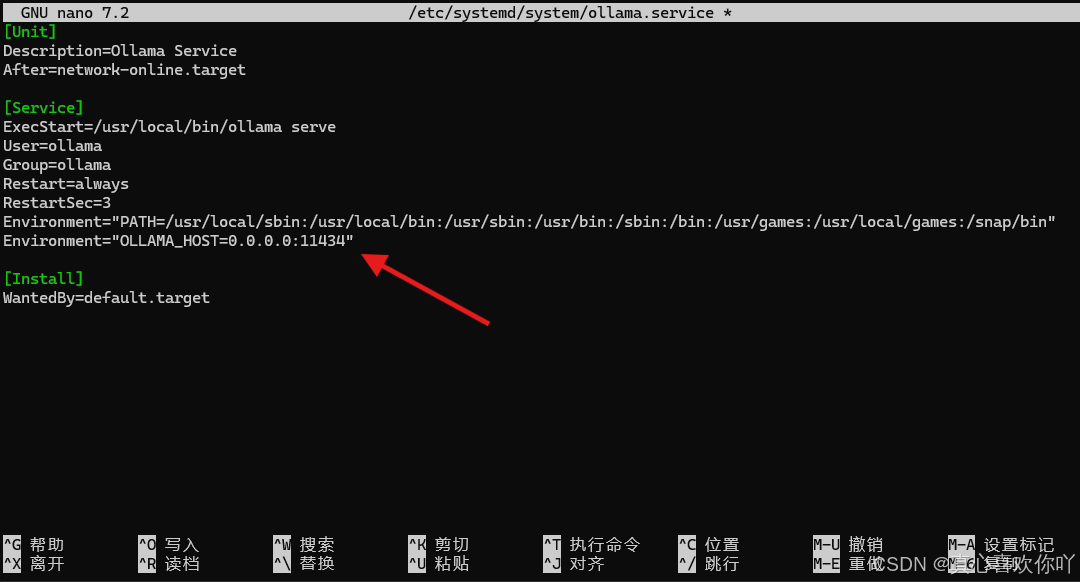
sudo nano /etc/systemd/system/ollama.service
# 添加如下内容
Environment="OLLAMA_HOST=0.0.0.0:11434"
重启ollama
sudo systemctl daemon-reload
sudo systemctl restart ollama
② 验证与防火墙设置
# 重启服务并开放端口
sudo systemctl daemon-reload && sudo systemctl restart ollama
sudo ufw allow 11434/tcp

四、核心组件部署:从模型拉取到引擎启动
🤖DeepSeek-R1 8B模型部署
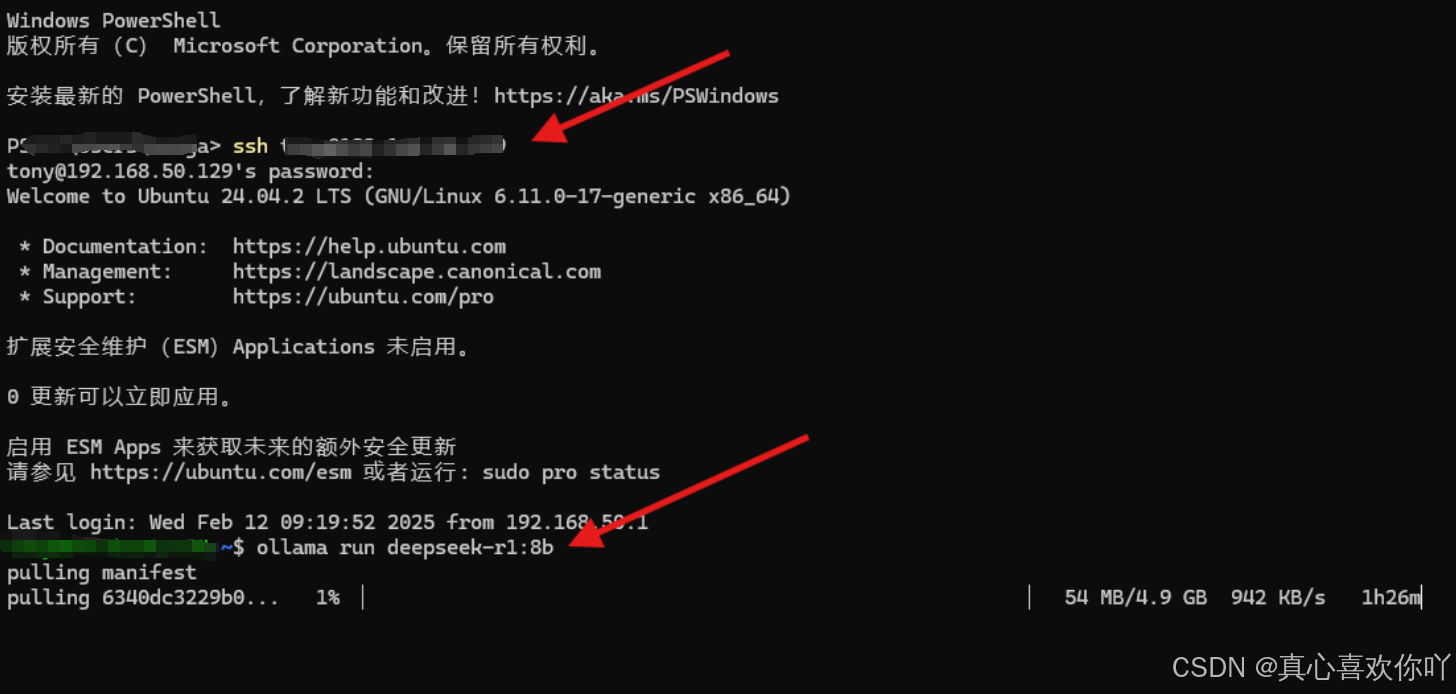
# 拉取模型(实测下载速度942KB/s,耗时1小时26分钟)
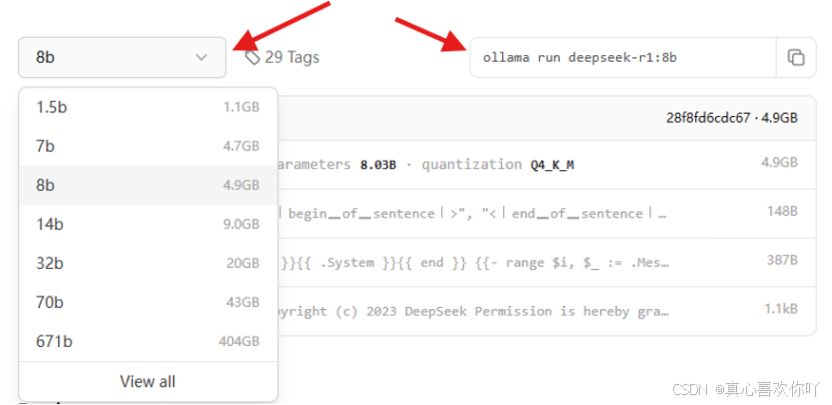
ollama run deepseek-r1:8b
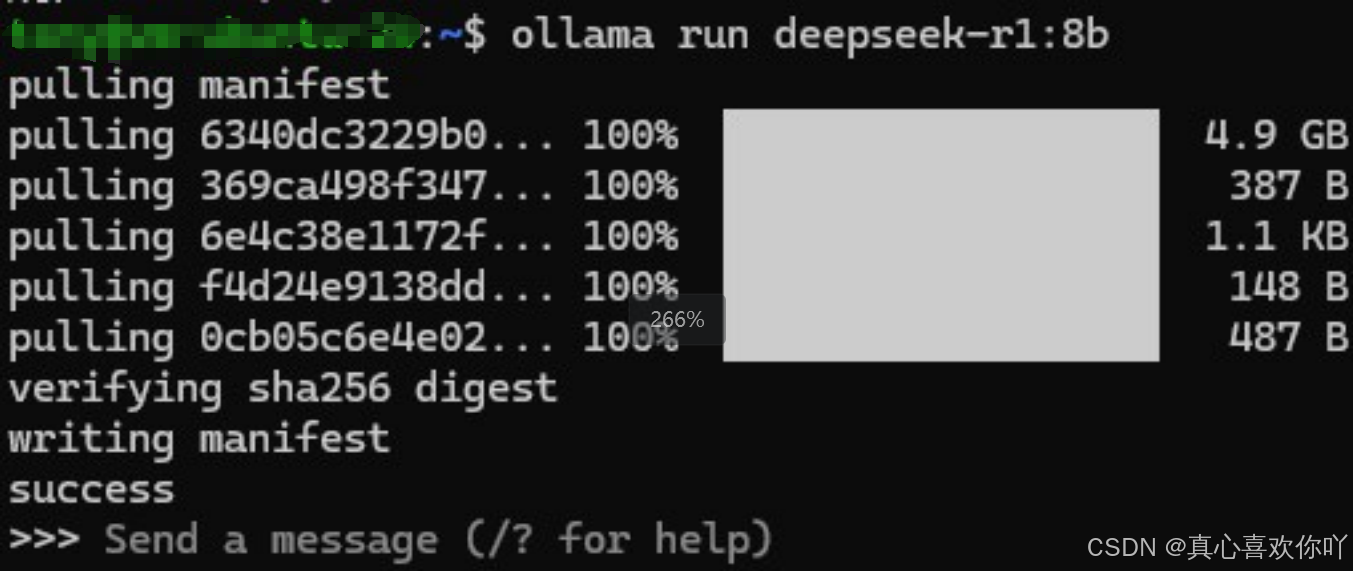
▶️ 交互验证
>>> 你是谁?
我是由深度求索(DeepSeek)开发的智能助手DeepSeek-R1,很高兴为你提供帮助。
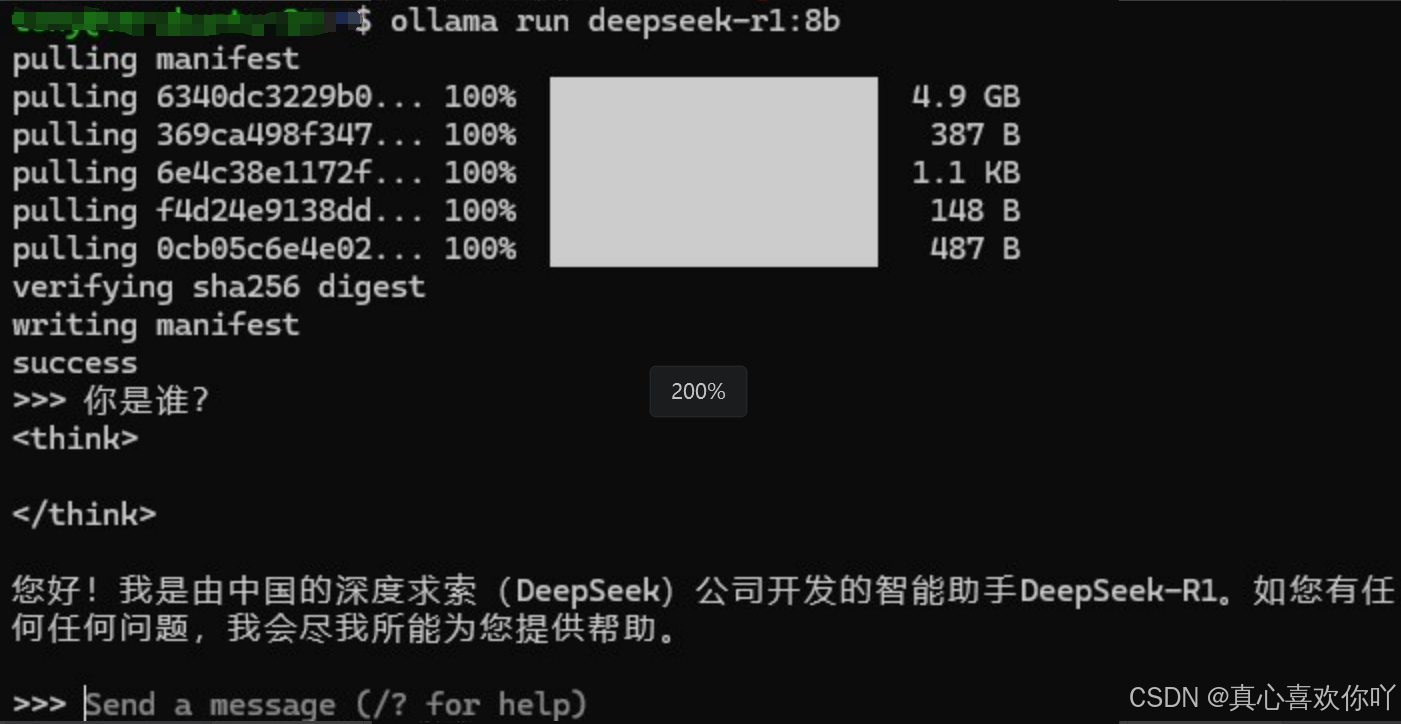
🏗️RAGFlow引擎部署
① 系统参数调整(避免内存不足)
sudo nano /etc/sysctl.conf
# 添加以下内容
vm.max_map_count=262144
sudo sysctl -p
② 克隆仓库与服务启动
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/docker
sudo chmod +x ./entrypoint.sh
sudo docker compose -f docker-compose.yml up -d
五、快速上手:从知识库创建到智能问答
1. 注册与初始化:5分钟搭建管理后台
访问http://服务器IP/login,注册账号
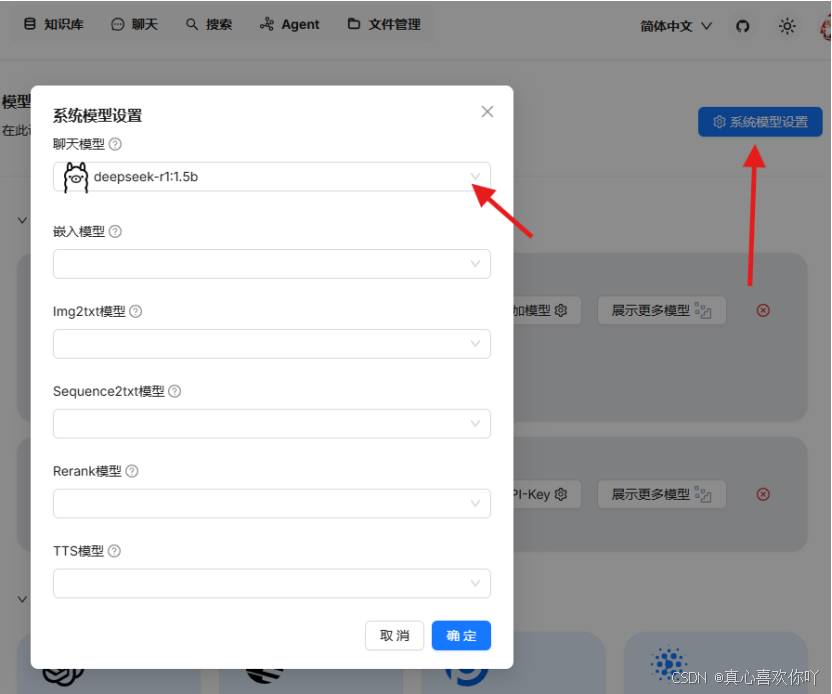
2. 模型配置:绑定DeepSeek与嵌入模型
① 添加聊天模型
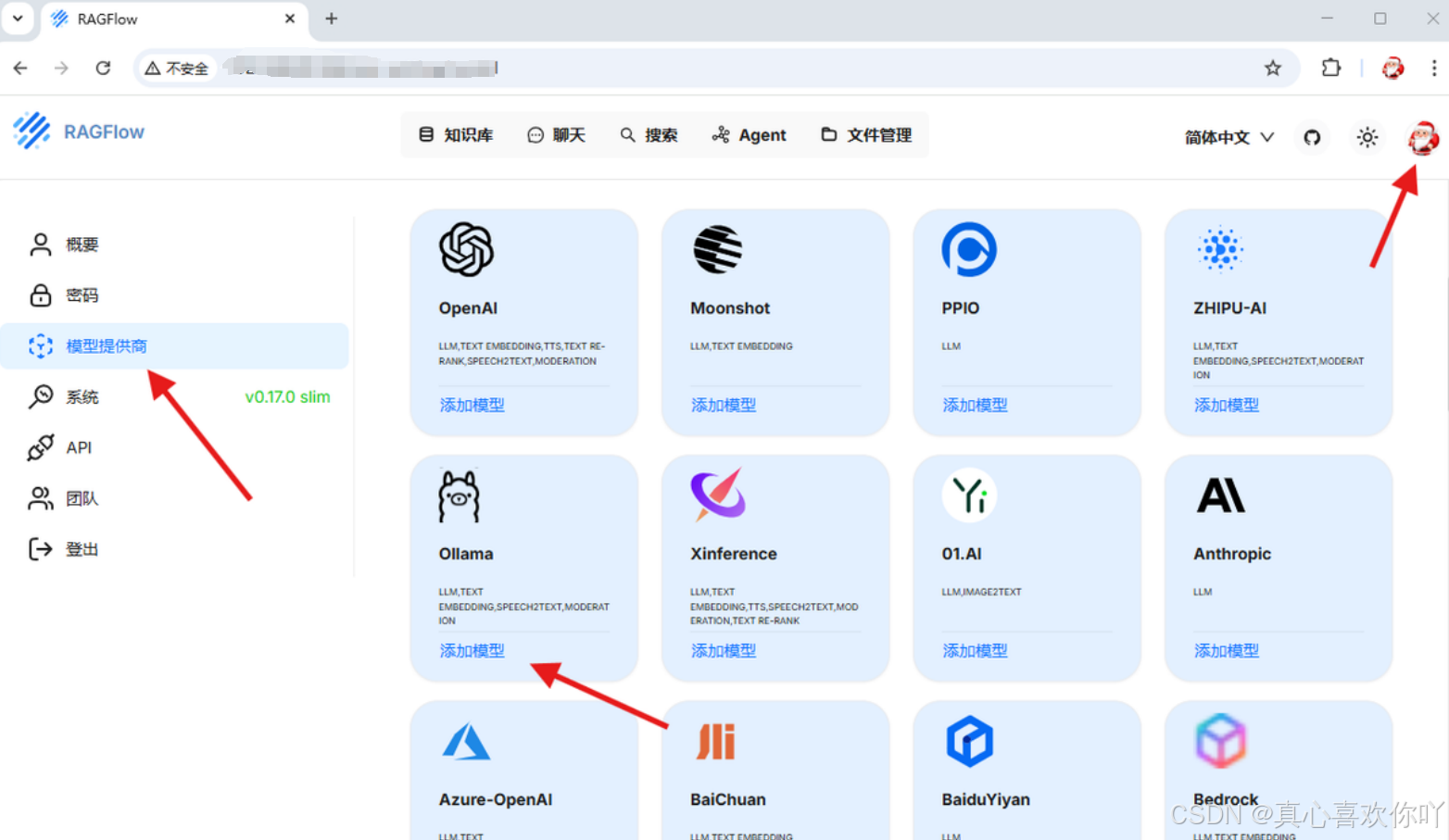
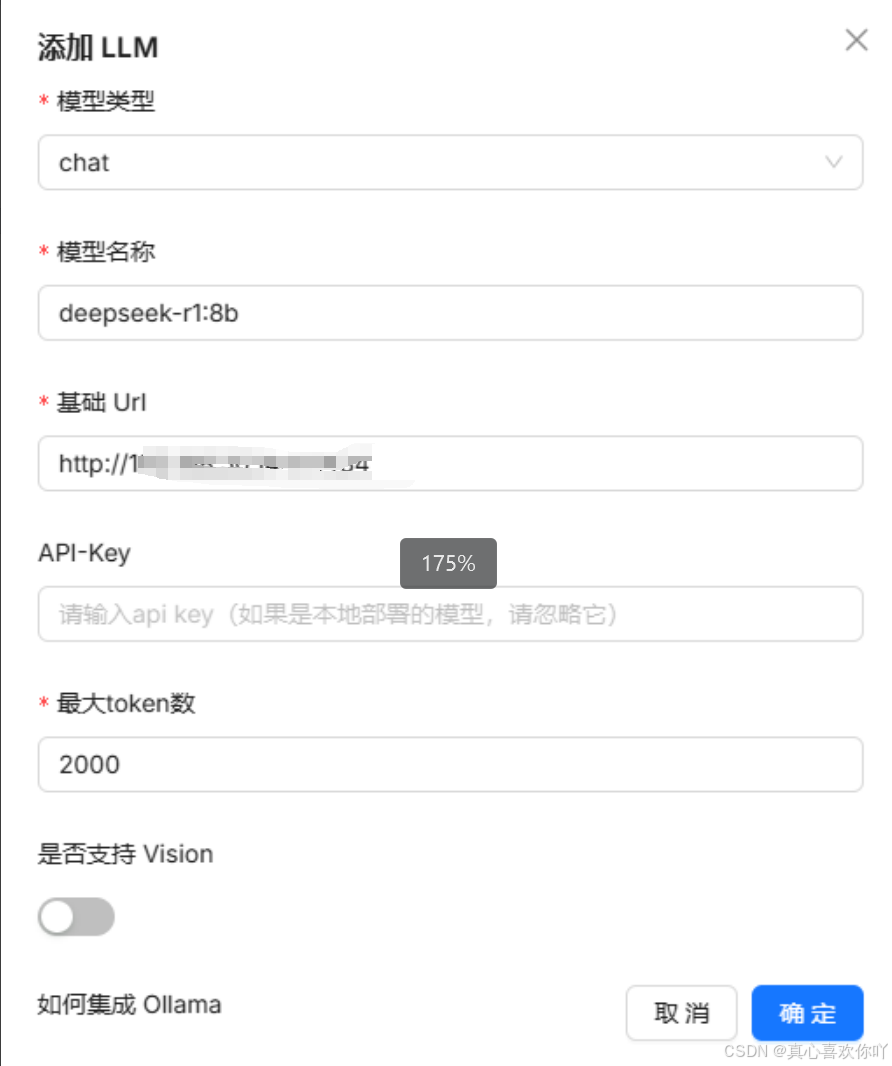
② 添加嵌入模型(BGE大模型)
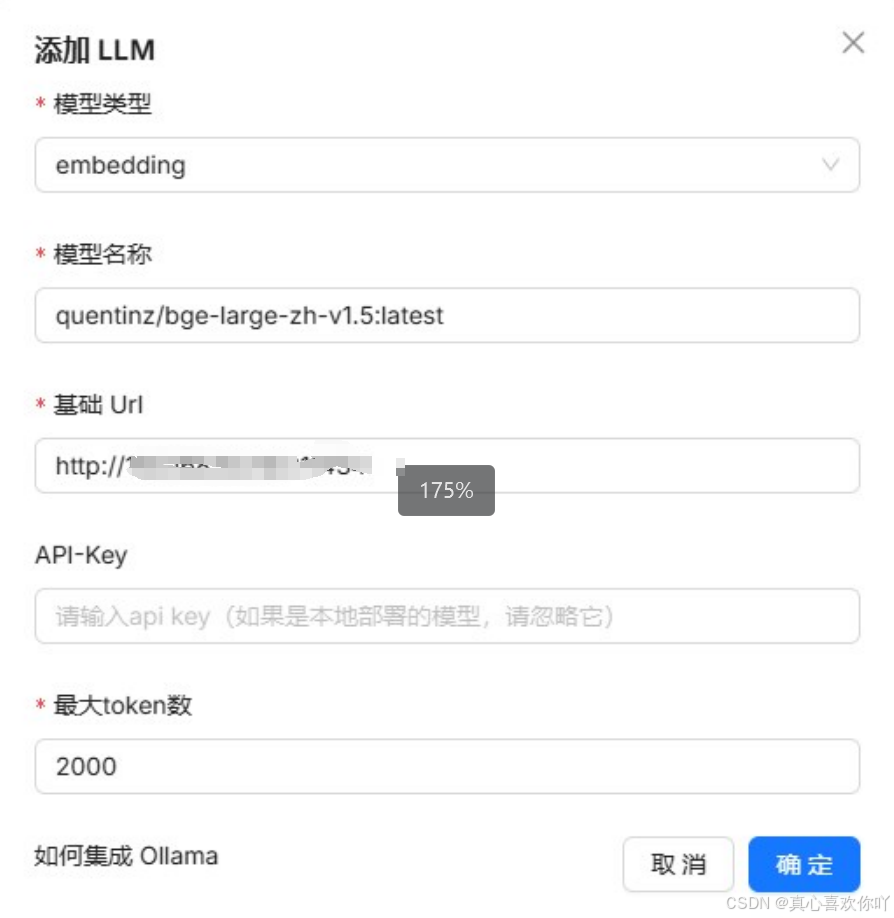
选择开源向量化模型,用于文档解析
3. 文档解析:投喂企业数据
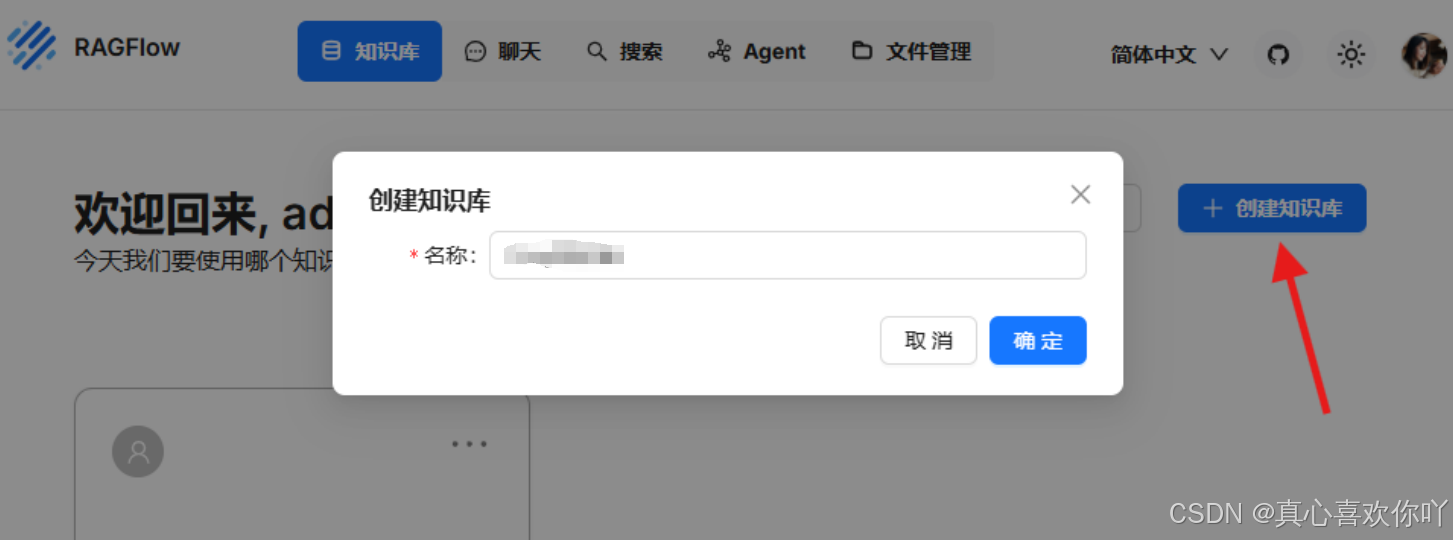
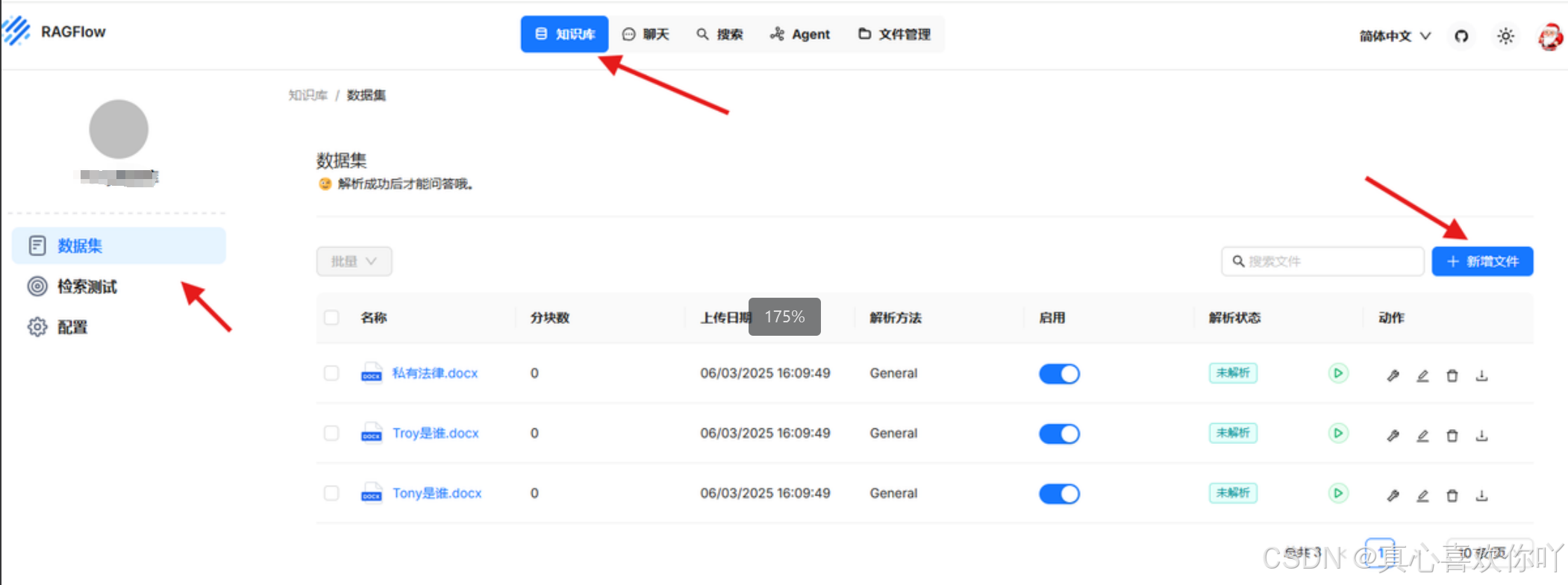
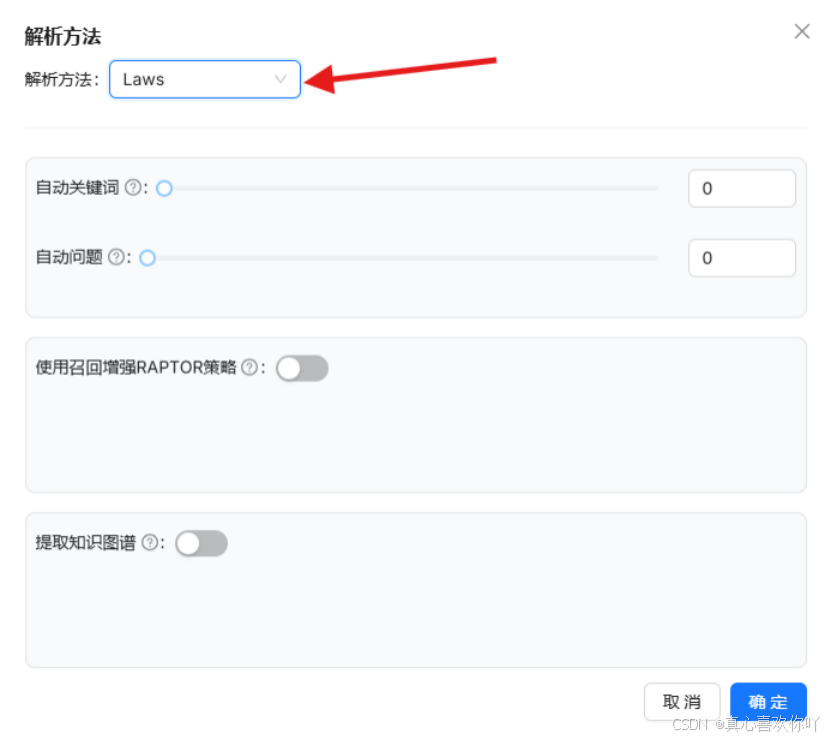
支持批量上传,解析设置包括关键词提取与知识图谱生成
4. 创建智能助理:定制问答机器人
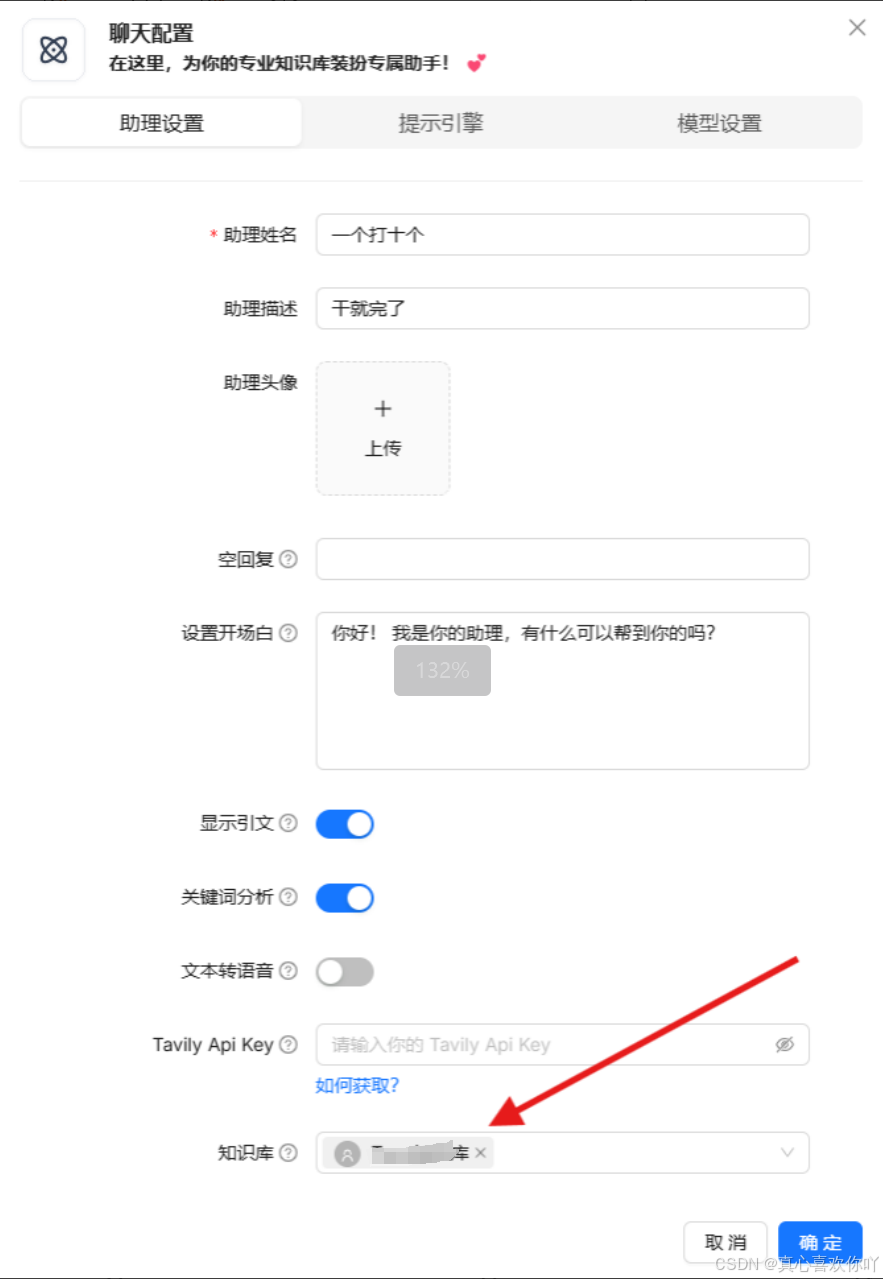
配置助理名称、知识库与开场白,支持TTS语音回复
六、性能实测与避坑指南
📊8B模型实测数据(服务器配置:AMD Ryzen 7 5800H + 16GB内存)
| 测试项 | 结果 | 对比云服务(GPT-3.5) |
|---|---|---|
| 单轮问答延迟 | 4.2秒(CPU模式) | 1.5秒(需网络请求) |
| 文档解析速度 | 20MB PDF/8秒 | 依赖上传速度(约15秒) |
| 同时在线用户数 | 10人(无明显卡顿) | 受云服务配额限制 |
| 数据吞吐量 | 500MB/小时 | 受API调用频率限制 |
🚨新手常见问题解决方案
| 问题现象 | 解决方案 |
|---|---|
| Ollama无法远程访问 | 检查OLLAMA_HOST配置、防火墙状态(sudo ufw status) |
| 文档解析乱码 | 转换为PDF格式后重新上传,或启用OCR解析(需安装tesseract-ocr) |
| RAGFlow启动失败 | 确认vm.max_map_count已生效,重启Docker服务(sudo docker restart) |
七、进阶功能:从权限管理到API集成
1. 精细化权限管理
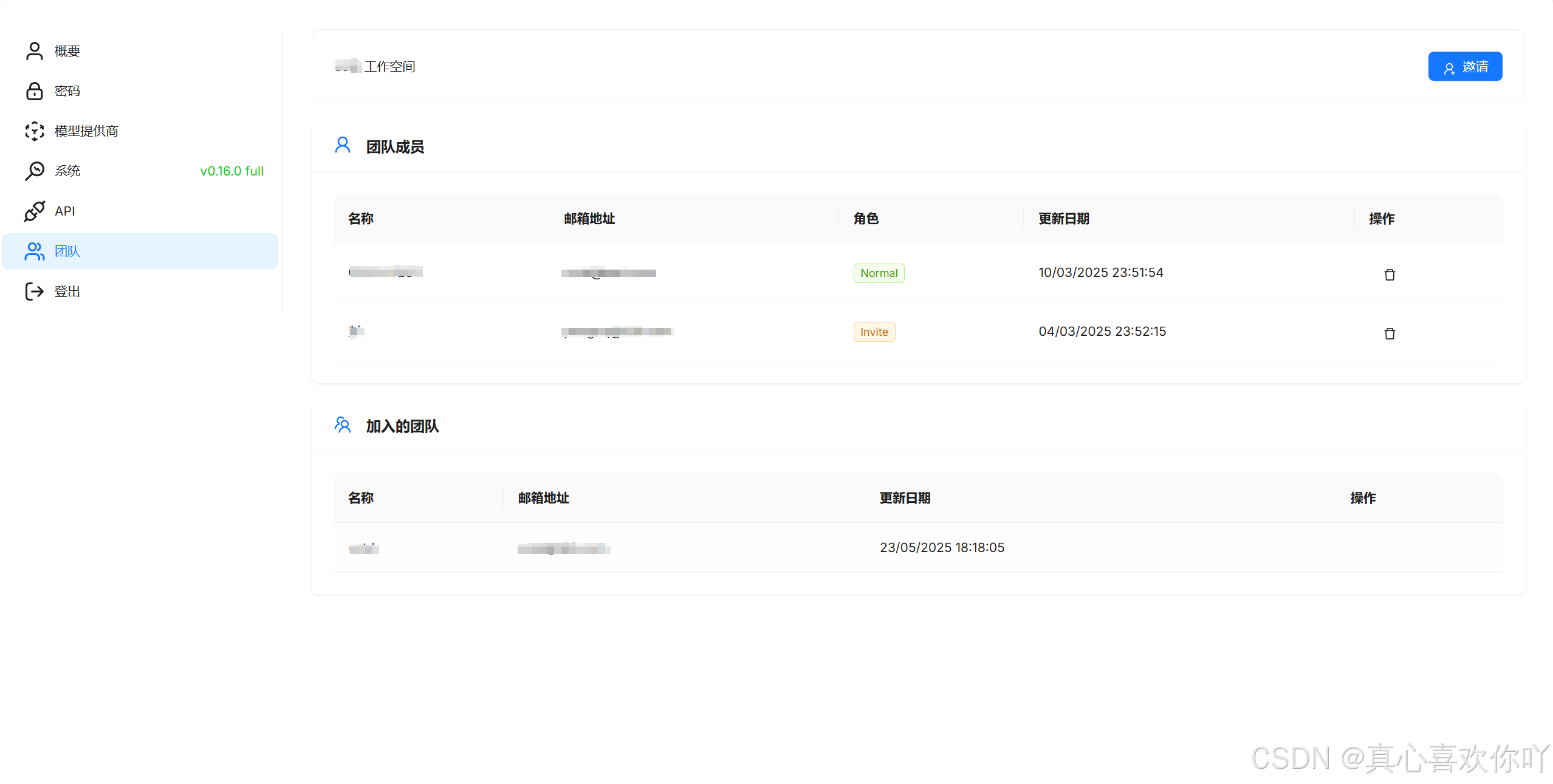
创建子账号,分配“知识库”只读权限
2. 知识图谱可视化

解析技术文档生成的实体关系图(需配置Neo4j)
3. API集成示例(Python)
# 调用RAGFlow问答接口
import requests
url = "http://192.168.50.144/api/query"
headers = {"Content-Type": "application/json"}
data = {
"question": "如何申请出差报销",
"knowledge_base": "行政知识库",
"model": "deepseek-r1:8b"
}
response = requests.post(url, headers=headers, json=data)
print(response.json()["answer"])
八、总结
通过RAGFlow与DeepSeek的深度整合,企业可在零代码基础上构建集“文档管理-知识解析-智能问答”于一体的本地化系统。本文方案经实测可满足100人以下企业的日常知识管理需求,硬件成本仅需3000元左右(二手服务器+显卡),较云服务方案节省70%以上成本。
立即动手搭建,让企业知识资产成为数字化转型的核心驱动力!👇

数据流向:文档上传→RAGFlow解析→向量存储→DeepSeek生成回答
通过本篇文章,您将系统掌握以下核心技能:
- 本地化知识库搭建全流程:从Ubuntu服务器初始化、Docker容器部署,到Ollama模型管理工具与DeepSeek大模型的安装配置,学会将开源工具链整合为完整的企业级知识管理系统🔧。
- RAGFlow引擎实战操作:掌握创建知识库、配置聊天/嵌入模型、解析多格式文档(PDF/Excel等)、创建智能问答助理的全流程,实现从文档上传到自然语言问答的自动化闭环📄。
- 数据安全与权限管理:了解如何通过局域网部署避免数据泄露,使用RAGFlow的用户分层权限体系管理不同部门的知识访问权限,满足企业合规要求🛡️。
- 性能优化与问题排查:学会调整系统参数(如
vm.max_map_count)解决内存不足问题,通过Docker日志定位服务故障,以及应对模型安装失败、文档解析乱码等常见问题的排查技巧🔍。 - 进阶功能扩展思路:了解知识图谱构建、API集成、模型版本升级(如70B参数规模)等高阶应用场景,为知识库的长期迭代提供技术方向🚀。
无论您是运维工程师、技术管理者,还是AI爱好者,本教程都将助您解锁企业级AI落地的关键能力!

一站式 AI 云服务平台
更多推荐



 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)