
deepseek+dify部署本地知识库答疑篇
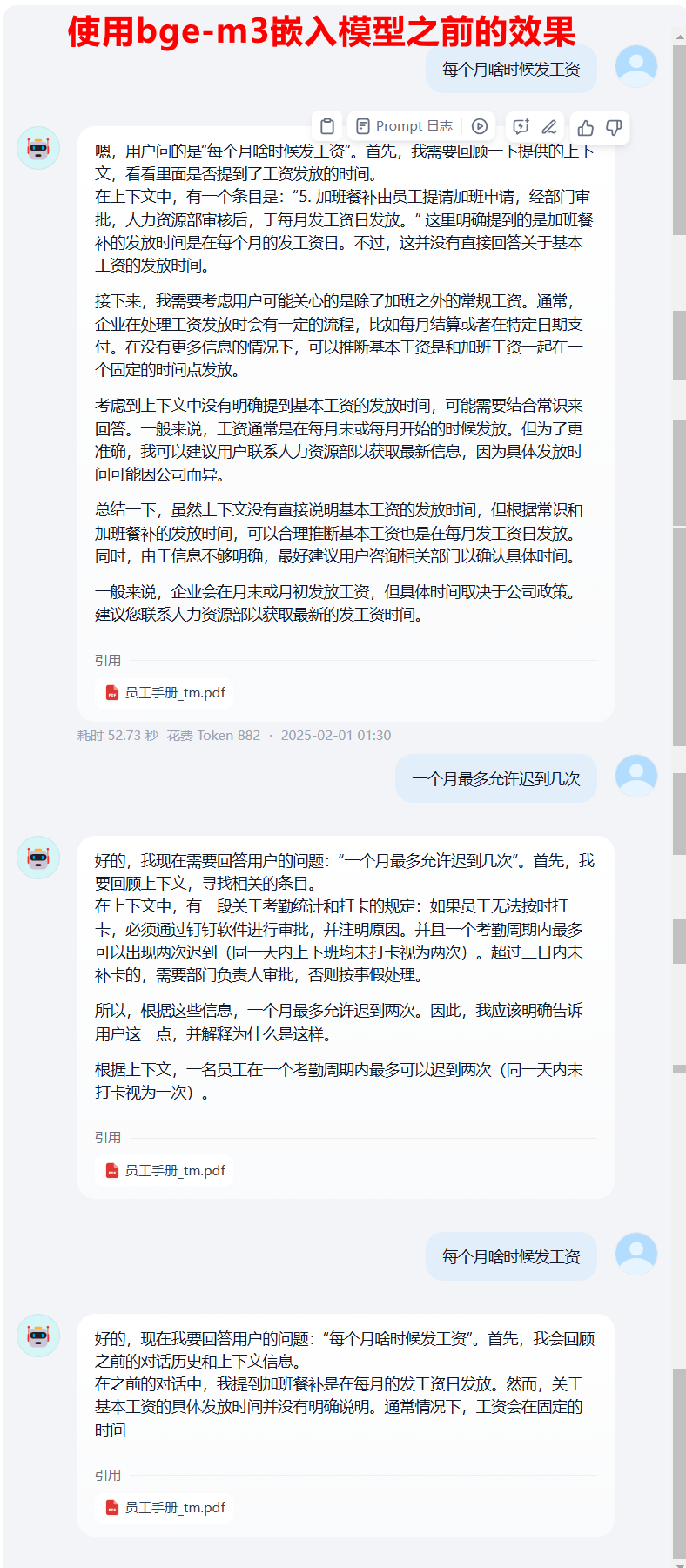
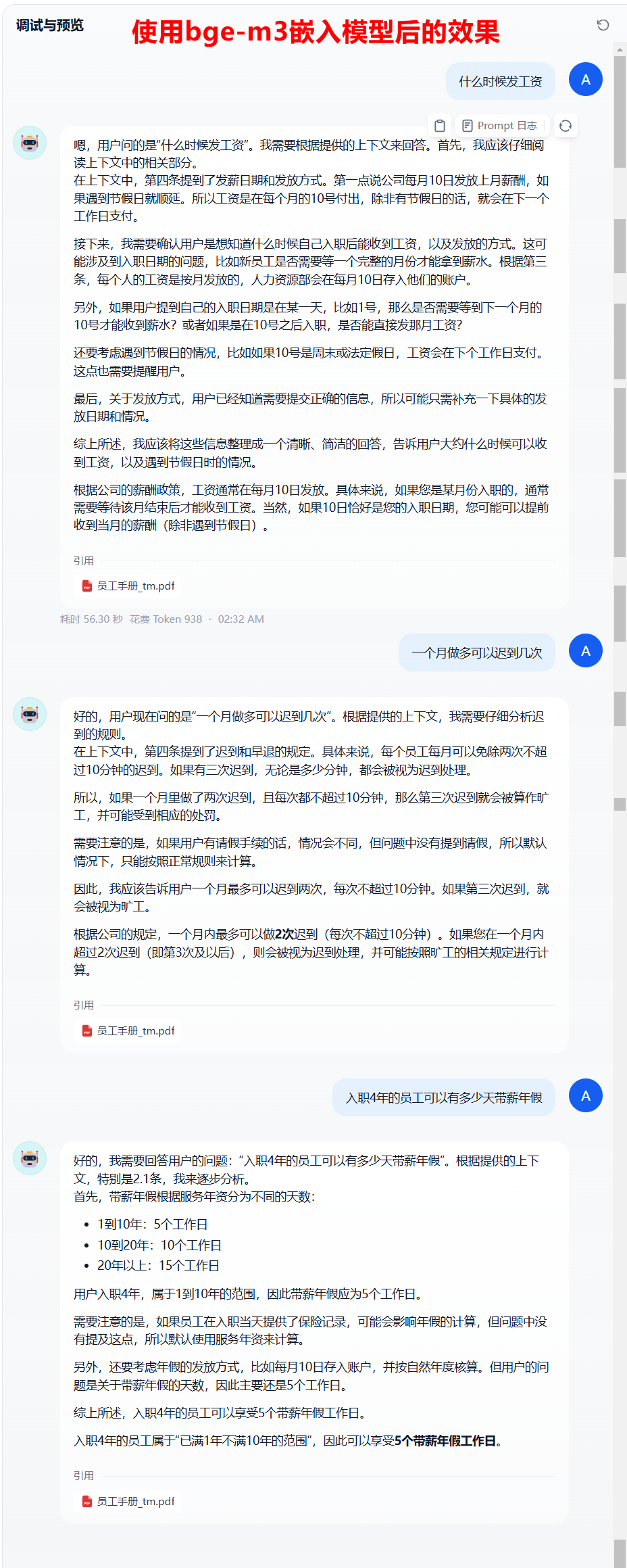
使用deepseek-r1作为嵌入模型时,有些问题回答的不是很尽如人意,因此,我又测试了其他几款专业embedding模型,综合结果显示:bge-m3 效果最好,这里推荐大家使用 bge-m3 作为嵌入模型。对比可以看到,使用bge-m3之前,对于有些问题的回答,答非所问,虽然有时候答案是对的,但是那是蒙的,并没有引用到正确的知识库对应的信息。使用了bge-m3之后,很明显答案有理有据,推理依据是
前几天,我发了一遍 DeepSeek+Dify 部署本地知识库的文章,在公众号,知乎,星球上,很多朋友都跟着进行了实操,也给了我很多的反馈,在此,我专门做一下集中答疑,希望朋友们少走弯路,主要有以下几点:
一、Dify 和 ollama 关联时,使用本机IP,还是跑不通怎么办?
如果使用本机内网IP联不通的话,可以尝试把指定 Ollama 的 API 地址改为host.docker.internal:11434 试试
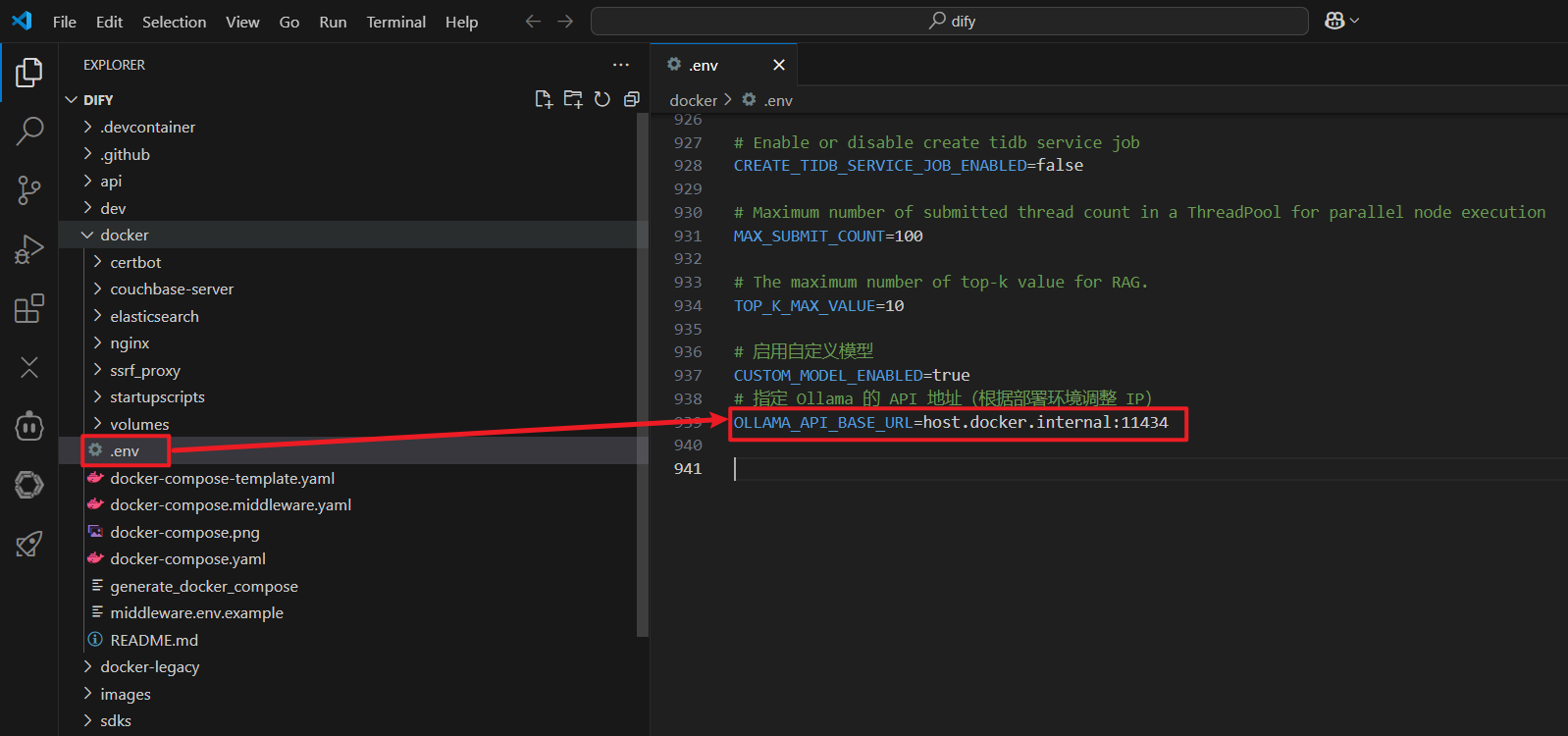
改完后,执行如下两个命令:
docker compose down
docker compose up -d
二、知识库 embedding 模型使用哪个比较好?
原本为了降低教程难度,我就使用了deepseek-r1模型作为embedding模型来使用了,使用效果也勉强过得去.
但是,deepseek-r1毕竟不是专门的embeddinig模型,他不是专门为了嵌入场景训练的。
所以,使用deepseek-r1作为嵌入模型时,有些问题回答的不是很尽如人意,因此,我又测试了其他几款专业embedding模型,综合结果显示:bge-m3 效果最好,这里推荐大家使用 bge-m3 作为嵌入模型。
一)安装 bge-m3 模型
bge-m3 模型安装和deepseek-r1完全一样,一个命令即可安装:
ollama pull bge-m3

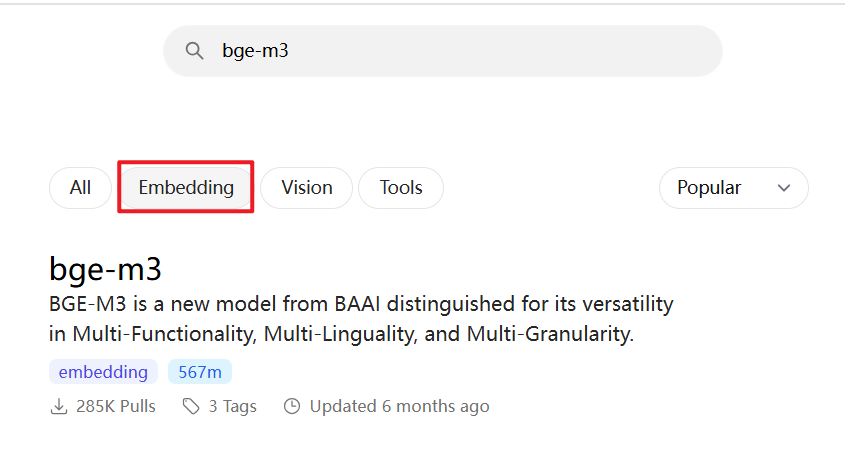
Embedding 模型那么多,为什么选择 bge-m3 ?
BGE (BAAI General Embedding) 专注于检索增强llm领域,经本人测试,对中文场景支持效果更好,当然也有很多其他embedding模型可供选择,可以根据自己的场景,在ollama上搜索“embedding”查询适合自己的嵌入模型。
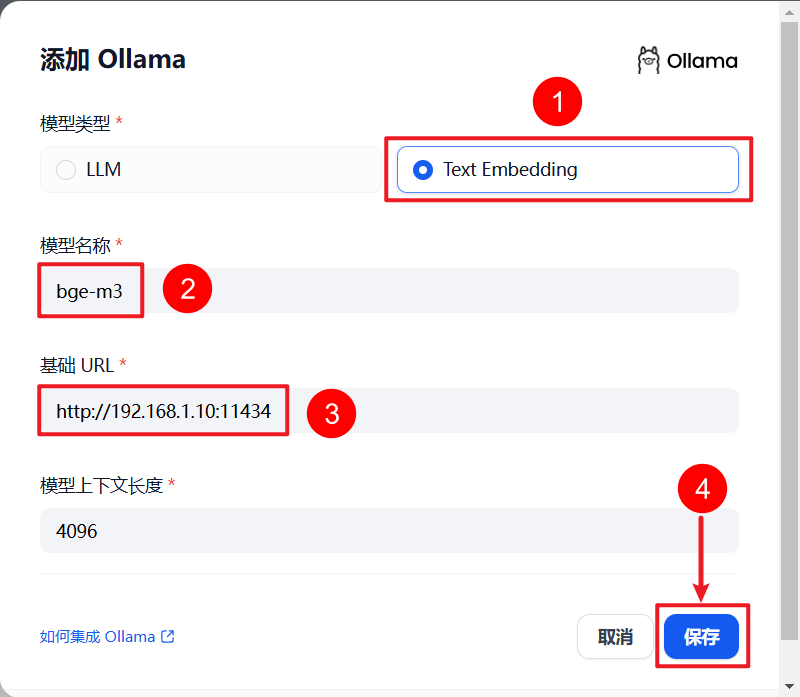
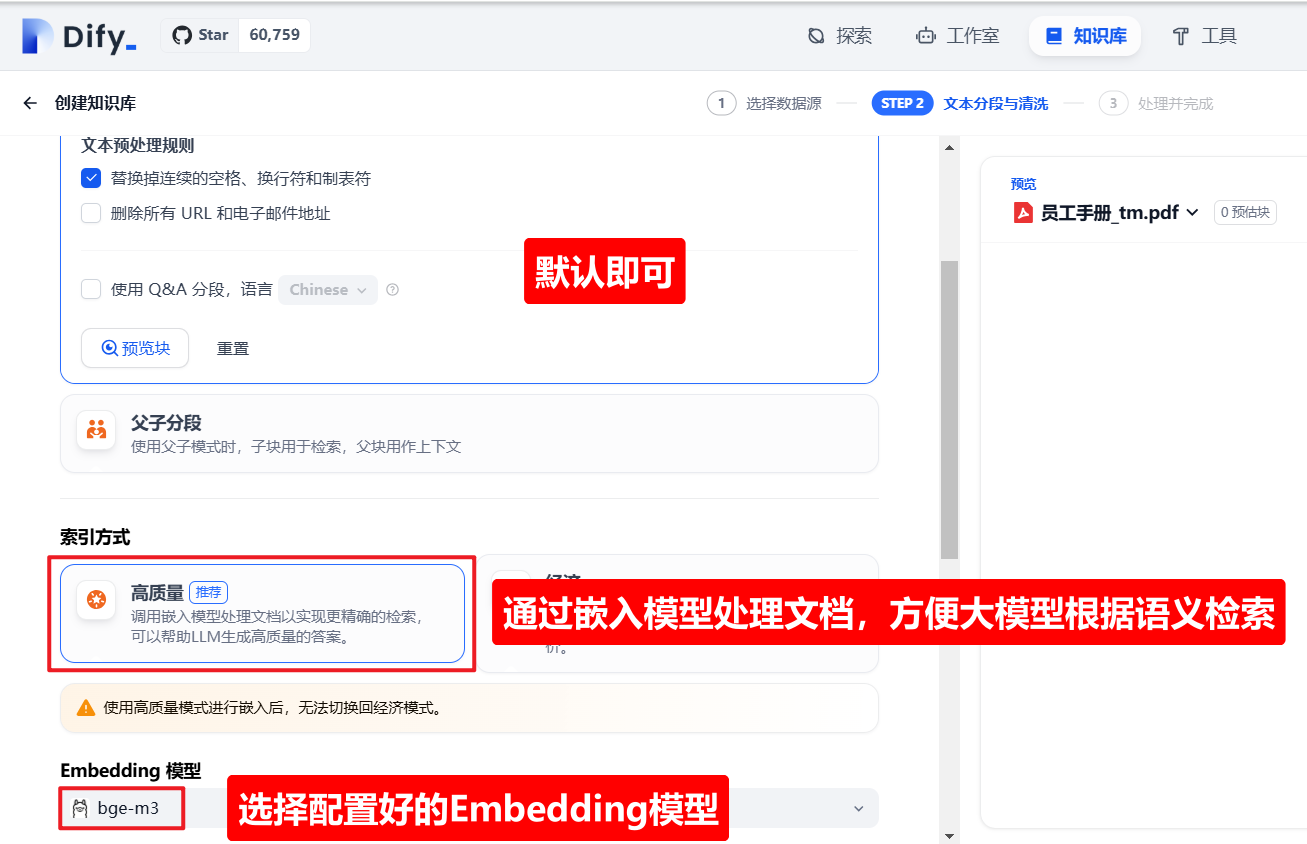
二)配置 Embedding 模型
三)创建知识库
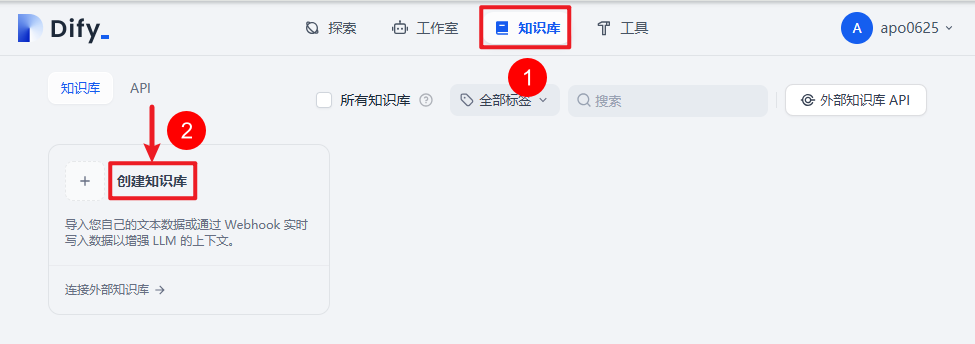
四)上传资料
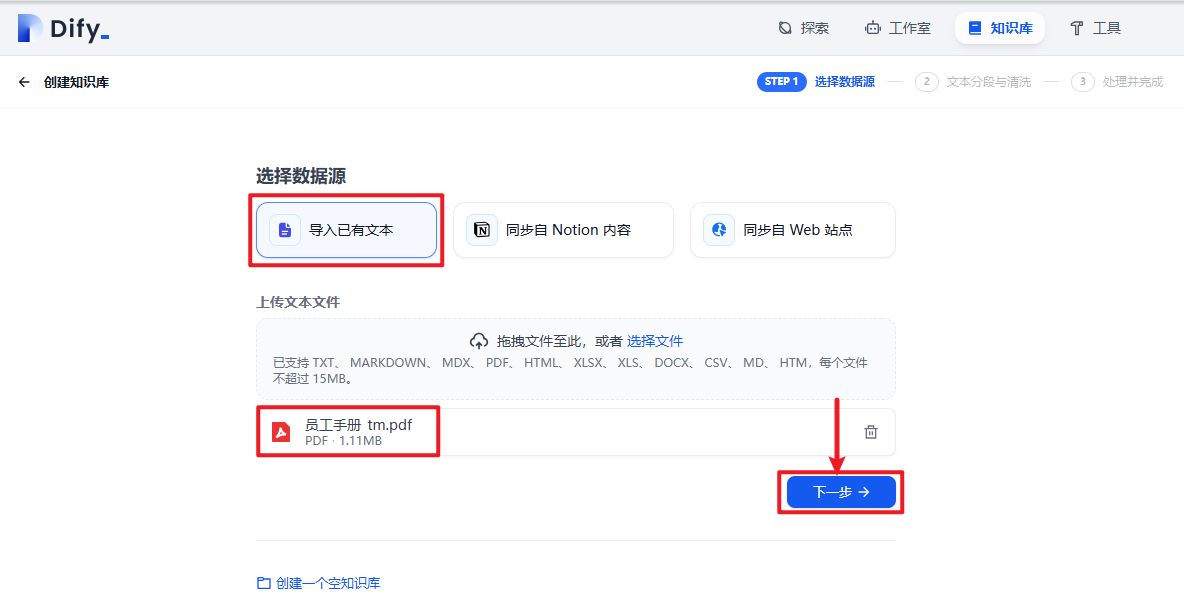
五)保存并处理
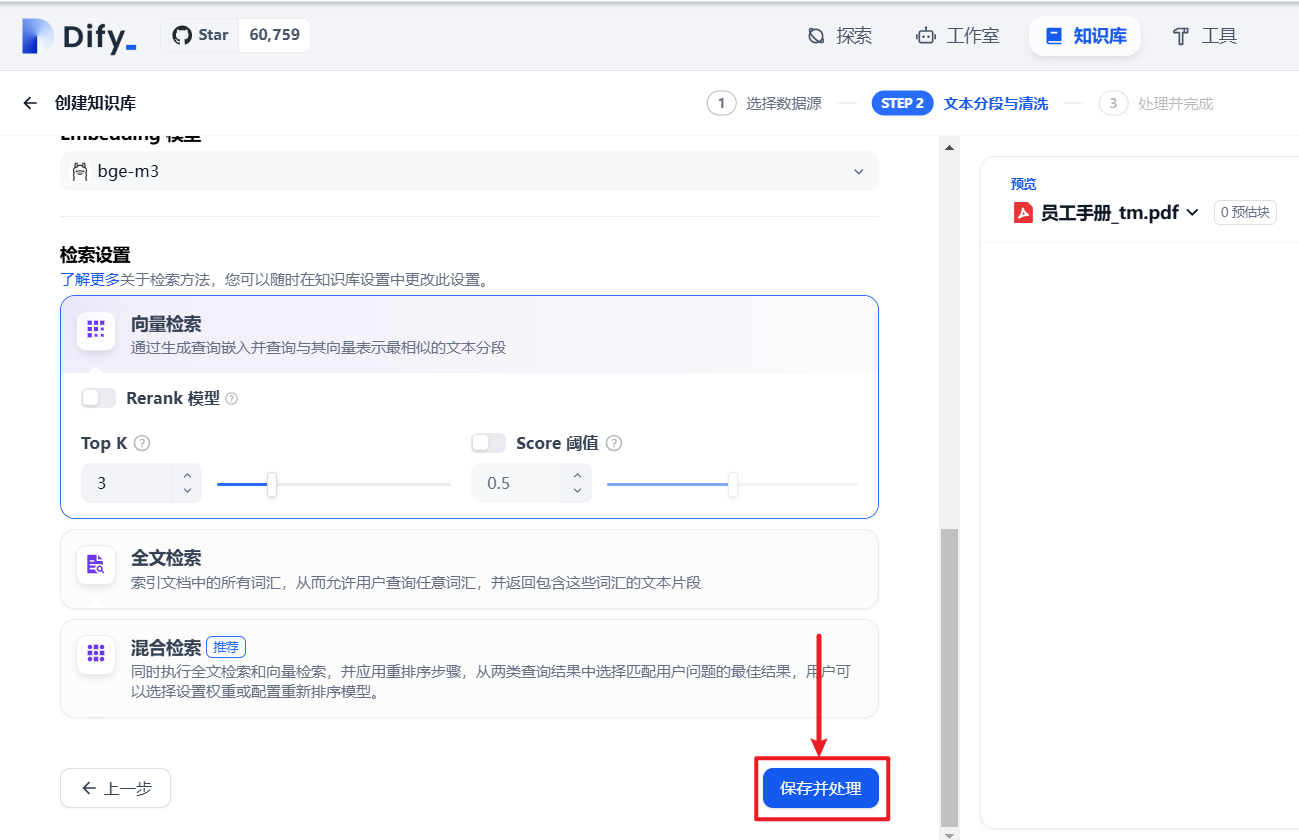
六)知识库创建完成
七)测试效果
对比可以看到,使用bge-m3之前,对于有些问题的回答,答非所问,虽然有时候答案是对的,但是那是蒙的,并没有引用到正确的知识库对应的信息。
使用了bge-m3之后,很明显答案有理有据,推理依据是正确的上下文,而非猜测。
所以,知识库回答效果跟Embedding模型有很大关系,需要根据实际场景进行选型。

一站式 AI 云服务平台
更多推荐

 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)