
数据库MYSQL及MYSQL ODBC
,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接;,查出满足条件的分组结果。它是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作。的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。- 再确定需要连接的表,使用INNER JOIN <表2>的语法。,获得一组组的集合,然后从每组
文章目录
- MYSQL下载安装
- 数据类型
- 主键
- 外键
- 索引
- 事务
- 临时表:只在当前连接可见
- 复制表
- 元数据
- Mysql基操
-
- 赋权
- 获取日期
- 连接
- 创建database:CREATE
- 删除database: DROP
- 选择database
- 创建table: CREATE
- 删除table: DROP
- 插入数据: INSERT
- 查询数据: SELECT
- WHERE子句
- GROUP BY子句: 根据一个或多个列对结果集进行分组
- HAVING
- 更新指定行数据: UPDATE
- 删除记录: DELETE
- LIKE子句
- UNION操作符:连接两个以上的 SELECT 语句的结果组合到一个结果集合中
- 排序: ORDER BY
- NULL处理
- ALTER命令
- 列出所有数据库 `SHOW DATABASES`
- 列出当前数据库的所有表 `SHOW TABLES`
- 查看一个表的结构 `DESC students`
- 查看创建表的SQL语句 `SHOW CREATE TABLE students`
- 退出 `EXIT`
- 添加ODBC数据源
- QT连接Mysql
MYSQL下载安装
-
安装:双击运行mysql-installer-web-community-8.0.31.0



设置安装路径:【Advanced Options】。
注:如果是32位程序要使用mysql,ODBC应该选择X86版本。
MySQL Connector/ODBC
MySQL的详细安装教程
problem:数据库初始化失败
数据类型
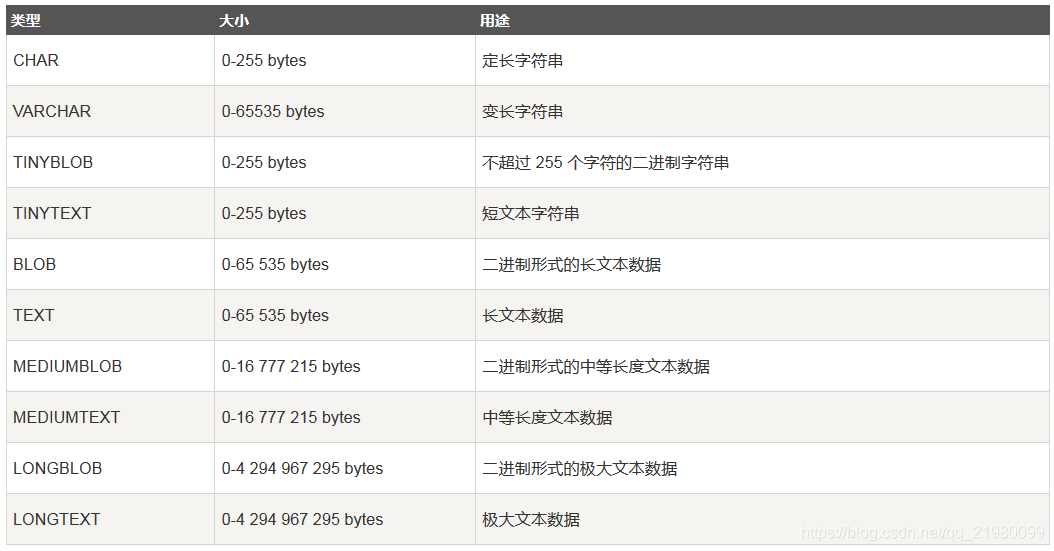
数值类型
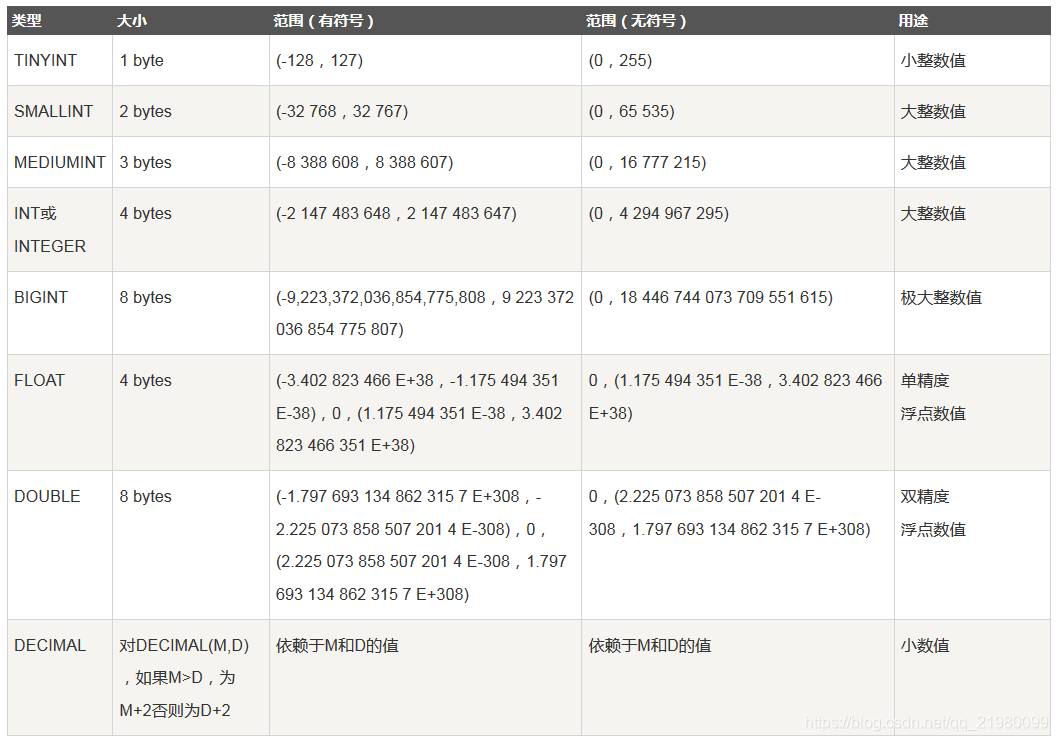
日期和时间类型
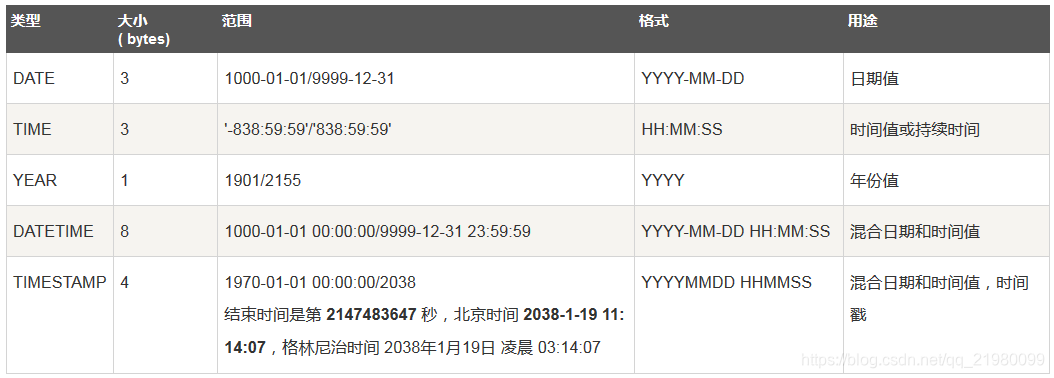
字符串类型
PS:
char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
- varchar不定长比定长char类型更节省空间。
- VARCHAR需要使用1或2个额外字节记录字符串的长度。
主键
主键是关系表中记录的唯一标识。主键的选取非常重要:主键不要带有业务含义,而应该使用BIGINT自增或者GUID类型。主键也不应该允许NULL。
外键
[CONSTRAINT symbol] FOREIGN KEY [id] (index_col_name, ...)
REFERENCES tbl_name (index_col_name, ...)
[ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
[ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
CONSTRAINT 'xiaodi_ibfk_1' FOREIGN KEY ('dage_id') REFERENCES 'dage' ('id'):dage中id为主键。
http://www.cppblog.com/wolf/articles/69089.html
级联: CASCADE
索引
- 索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。
- 分类
- 单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。
- 组合索引,即一个索引包含多个列。
- 实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
- 缺点:
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
- 建立索引会占用磁盘空间的索引文件。
基本操作
创建索引
CREATE INDEX indexName ON table_name (column_name)
修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(columnName)
创建表的时候直接指定
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
删除索引
DROP INDEX [indexName] ON mytable;
唯一索引(UNIQUE INDEX): 索引列的值必须唯一,但允许有空值
- 在设计关系数据表的时候,看上去唯一的列,例如身份证号、邮箱地址等,因为他们具有业务含义,因此不宜作为主键。但是,这些列根据业务要求,又具有唯一性约束:即不能出现两条记录存储了同一个身份证号。这个时候,就可以给该列添加一个唯一索引。
事务
主要用于处理操作量大,复杂度高的数据。
- 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert,update,delete 语句
- 一般来说,事务是必须满足4个条件(ACID)。
临时表:只在当前连接可见
复制表
元数据
Mysql基操
赋权
// mysql
create user root@'%' identified by '123456';
grant all privileges on *.* to root@'%' with grant option;
flush privileges;
获取日期
select now();
CString strSQL = "select now()"; // oracle: select systime from dual
CAdoRecord rs;
if(!rs.Open(m_pConn, strSQL))
return FALSE;
COleDateTime dt;
rs.GetFieldValue("now()", dt);
rs.Close();
连接
mysql -u root -p
创建database:CREATE
CREATE DATABASE 数据库名;
存在则不创建;设定编码集utf-8CREATE DATABASE IF NOT EXISTS 数据库名 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
删除database: DROP
drop database 数据名;
使用mysqladmin删除数据库:mysqladmin -u root -p drop 数据库名
选择database
在其他操作前。use 数据库名;
创建table: CREATE
CREATE TABLE table_name (column_name column_type)
CREATE TABLE IF NOT EXISTS `runoob_tbl`(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_title` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
- NOT NULL:在操作数据库时如果输入该字段的数据为NULL,就会报错。
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- 一般使用BIGINT类型。
- 如果使用INT自增类型,那么当一张表的记录数超过2147483647(约21亿)时,会达到上限而出错。使用BIGINT自增类型则可以最多约922亿亿条记录。
- 一般使用BIGINT类型。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
- ENGINE 设置存储引擎,CHARSET 设置编码。
删除table: DROP
DROP TABLE table_name
DROP TABLE IF EXISTS 'table_name'
插入数据: INSERT
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
INSERT INTO runoob_tbl
-> (runoob_title, runoob_author, submission_date)
-> VALUES
-> ("学习 PHP", "菜鸟教程", NOW());
重复数据处理
- PRIMARY KEY
- UNIQUE
- 如果我们设置了唯一索引,那么在插入重复数据时,SQL 语句将无法执行成功,并抛出错。
- INSERT IGNORE INTO 会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
- 如果我们设置了唯一索引,那么在插入重复数据时,SQL 语句将无法执行成功,并抛出错。
查询数据: SELECT
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[LIMIT N][ OFFSET M]
- 可以使用**星号(*)**来代替其他字段,SELECT语句会返回表的所有字段数据
- 使用
WHERE语句来包含任何条件。 - 使用
LIMIT属性来设定返回的记录数。 - 通过
OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
聚合查询
SELECT COUNT(*) num FROM students; 设置结果集的列名为num
多表查询
SELECT * FROM FROM <表名1> <别名1>, <表名2> <别名2>
- 同时从<表1>表和<表2>表的“乘积”,查询数据。
- 使用表名.列名这样的方式来引用列和设置别名,这样就避免了结果集的列名重复问题。
连接查询
内连接/等值连接INNER JOIN
获取两个表中字段匹配关系的记录。
- 先确定主表,仍然使用FROM <表1>的语法;
- 再确定需要连接的表,使用INNER JOIN <表2>的语法
- 然后确定连接条件,使用ON <条件…>,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接;
- 可选:加上WHERE子句、ORDER BY等子句。
SELECT ... FROM runoob_tbl a INNER JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
相当于: SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a, tcount_tbl b WHERE a.runoob_author = b.runoob_author;
左连接LEFT JOIN**
获取左表所有记录,即使右表没有对应匹配的记录。
右连接RIGHT JOIN
与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
FULL OUTER JOIN
WHERE子句
- 使用 AND 或者 OR 指定一个或多个条件
- WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
- 使用 BINARY 关键字来设定 WHERE 子句的字符串比较是区分大小写的。
SELECT * from runoob_tbl WHERE BINARY runoob_author='runoob.com';
GROUP BY子句: 根据一个或多个列对结果集进行分组
SELECT column_name, function(column_name) FROM table_name
WHERE column_name operator value
GROUP BY column_name;
- 统计每个人有多少条记录:
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
WITH ROLLUP: 在分组统计数据基础上再进行相同的统计
SELECT name, SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
HAVING
显示每个地区的总人口数和总面积,仅显示那些面积超过1000000的地区。
SELECT region, SUM(population), SUM(area)
FROM bbc
GROUP BY region
HAVING SUM(area)>1000000
WHERE vs GROUP BY vs HAVING
-
where:数据库中常用的是where关键字,用于在初始表中筛选查询。它是一个约束声明,用于约束数据,在返回结果集之前起作用。
-
group by:对select查询出来的结果集按照某个字段或者表达式进行分组,获得一组组的集合,然后从每组中取出一个指定字段或者表达式的值。
-
having:用于对where和group by查询出来的分组过滤,查出满足条件的分组结果。它是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作。
更新指定行数据: UPDATE
UPDATE table_name SET field1=new_value1, field2=new_value2 [WHERE Clause]
- 将字段中的特定字符串批量修改为其他字符串
UPDATE table_name SET field=REPLACE(field, 'old-string', 'new-string') [WHERE Clause]
删除记录: DELETE
DELETE FROM table_name [WHERE Clause]
DELETE vs DROP vs TRUNCATE
delete,drop,truncate 都有删除表的作用,区别在于:
- delete 和 truncate 仅仅删除表数据,drop 连表数据和表结构一起删除,打个比方,delete 是单杀,truncate 是团灭,drop 是把电脑摔了。
- delete 是 DML 语句,操作完以后如果没有不想提交事务还可以回滚,truncate 和 drop 是 DDL 语句,操作完马上生效,不能回滚。
- 执行的速度上,drop > truncate > delete。
LIKE子句
SELECT * FROM table_name WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'
- 使用百分号
%字符来表示任意字符 - 如果没有使用百分号 %等, LIKE 子句与等号 = 的效果是一样的。
- 模糊匹配
- %:表示任意 0 个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示。
- _:表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句。
- []:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
- [^] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
- 查询内容包含通配符时,由于通配符的缘故,导致我们查询特殊字符 “%”、“_”、“[” 的语句无法正常实现,而把特殊字符用 “[ ]” 括起便可正常查询。
UNION操作符:连接两个以上的 SELECT 语句的结果组合到一个结果集合中
SELECT expression1, expression2, ... expression_n
FROM tables [WHERE conditions]
UNION [ALL | DISTINCT]
SELECT expression1, expression2, ... expression_n
FROM tables [WHERE conditions];
- DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
- ALL: 可选,返回所有结果集,包含重复数据。
排序: ORDER BY
SELECT field1, field2,...fieldN FROM table_name1, table_name2... ORDER BY field1 [ASC [DESC][默认 ASC]], [field2...] [ASC [DESC][默认 ASC]]
- 如果字符集采用的是 utf8(万国码),需要先对字段进行转码然后排序
... ORDER BY CONVERT(runoob_title using gbk)
NULL处理
当提供的查询条件字段为 NULL 时,该命令可能就无法正常工作。
- IS NULL: 当列的值是 NULL,此运算符返回 true。
- IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。
- <=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
SELECT * FROM runoob_test_tbl WHERE runoob_count IS NULL;
ALTER命令
修改数据表名或者修改数据表字段(DROP\ADD\MODIFY)。
- 删除:
ALTER TABLE table_name DROP col_name; - 添加:
ALTER TABLE table_name ADD i INT;- 指定新增字段的位置,可以使用MySQL提供的关键字 FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)
- 修改字段类型及名称
ALTER TABLE testalter_tbl MODIFY c CHAR(10);ALTER TABLE testalter_tbl CHANGE old_name new_name BIGINT;
列出所有数据库 SHOW DATABASES
列出当前数据库的所有表 SHOW TABLES
查看一个表的结构 DESC students
查看创建表的SQL语句 SHOW CREATE TABLE students
退出 EXIT
添加ODBC数据源
手动配置
- 将Mysql数据库连接到window ODBC。打开windows ODBC数据源管理程序(注意32位DTCD,故ODBC也应使用32位)。

- 选择对应的数据源驱动程序。

- 添加Mysql数据库。填写ODBC连接名、MYSQL所在IP、MYSQL用户名、密码、数据库名。并点击【测试】,测试成功后,再点击【OK】。


【MySQL】ODBC数据源配置
命令行配置
Wdac: Add-OdbcDsn
Add-OdbcDsn -Name "MyPayroll" -DriverName "MySQL ODBC 5.3 Unicode Driver" -DsnType "User" -Platform "32-bit" -SetPropertyValue @("DSN=ODBCNAME", "Server=127.0.0.1", "Trusted_Connection=Yes", "Database=DBNAME", "PORT=3306")
Add-OdbcDsn
Add an ODBC SQL Server connection with a specific user with Powershell
Creating an ODBC Connection With PowerShell Using a Specific Account
odbcconf.exe
// 创建系统DSN
// 仅能使用windows直接登录
"C://Windows//SysWOW64//odbcconf.exe" /A {CONFIGSYSDSN "MySQL ODBC 5.3 Unicode Driver" "DSN=DTCDHL7|SERVER=127.0.0.1|Database=DTCDHL7|PORT=3306|Trusted_Connection=Yes"}
// 创建用户DSN
// 标准用户名、密码登录
"C://Windows//SysWOW64//odbcconf.exe" /A {CONFIGSYSDSN "MySQL ODBC 5.3 Unicode Driver" "DSN=DTCDHL7|SERVER=127.0.0.1|Database=DTCDHL7|PORT=3306|UID=root|PWD=password"}
Windows上命令行实现运行时添加ODBC数据源-odbcconf命令的使用
Error Creating DSN using odbcconf.exe for SQL Server
其它方案
How can I create an ODBC connection from .bat file in Windows?
Create 32-Bit system ODBC DSN with Powershell
64位机器上调用32位ODBC
cmd命令行中执行C:\Windows\SysWOW64\odbcad32.exe开启32位
64 位元 ODBC 位置:C:\Windows\System32\odbcad32.exe
Note for 32-bit programs running on 64-bit systems the path is HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\ODBC…
ODBC 管理员工具在 64 位版本的 Windows 中同时显示 32 位和 64 位用户 DSN
How can I create an ODBC connection from .bat file in Windows?
warning & problem
String data, right truncation
选择的ODBC数据库字符集 与 数据库字符集不统一。
QT连接Mysql
报错:
QSqlDatabase: QMYSQL driver not loaded
QSqlDatabase: available drivers: QSQLITE QODBC QODBC3 QPSQL QPSQL7
主要由于Qt没有找到用于连接MySQL数据库的QMYSQL驱动。
解决方案:
- 确保MySQL Server已经安装,且路径被添加到了系统环境变量。
- 如果您是使用MySQL的非安装版本(即ZIP归档版),需要手动将libmysql.dll文件(通常位于MySQL的lib文件夹)拷贝到你的应用程序的可执行文件所在的目录。
- 将Qt安装目录下的sqldrivers目录中的qsqlmysql.dll和qsqlmysqld.dll复制到你的应用程序目录(E:\Qt\Qt5.12.9\5.12.9\msvc2017\plugins\sqldrivers下)。部分版本Qt中需要手动编译生成。
编译生成QT mysql库
安装
Qt安装时勾选源码Sources
编译
- 在源码目录中找到mysql(E:\Qt\Qt5.12.9\5.12.9\Src\qtbase\src\plugins\sqldrivers)。
- 打开mysql文件,点击mysql.pro进行配置。
- 修改mysql.pro:
3.1 注释掉“QMAKE_USE += mysql”。
3.2 添加mysql路径。 - 使用QTcreator打开,并构建项目。
- 将其拷贝到E:\Qt\Qt5.12.9\5.12.9\msvc2017\plugins\sqldrivers下,就可以正确的在QT中使用Mysql了。或应用程序目录下?
导入
Qt的Mysql项目编译成功后会在Qt所在安装盘符的主目录生成一个 plugins 文件夹
然后将qsqlmysql.dll和qsqlmysqld.dll拷贝到Qt的安装目录下

一站式 AI 云服务平台
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)