
java 线程池 数据库连接池_线程池配置与数据库连接池最大连接数配置
线程池 相关配置,不仅平时经常用到,而且面试也会经常问到。如何设置线程池大小?CPU 密集型任务:这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。I/O 密
线程池 相关配置,不仅平时经常用到,而且面试也会经常问到。
如何设置线程池大小?
CPU 密集型任务:这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
I/O 密集型任务:这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
综上可知:当线程数量太小,同一时间大量请求将被阻塞在线程队列中排队等待执行线程,此时 CPU 没有得到充分利用;当线程数量太大,被创建的执行线程同时在争取 CPU 资源,又会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。通过测试可知,4~6 个线程数是最合适的。
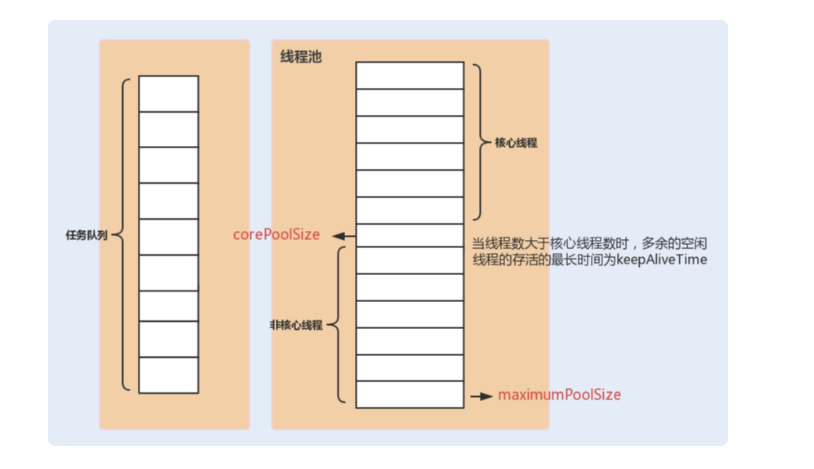
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
int maximumPoolSize,//线程池的最大线程数
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,//时间单位
BlockingQueue workQueue,//任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler) //拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
但是某些号称XXX架构师配置线程池参数(或者jdbc连接池数量)还是会拍脑袋,随便定个 核心线程数或者最大线程数100
这就是没有性能意思的码农(估计都了解过怎么配置,就是没有在意)了。 虽然说配置比如 最大线程数100 , 其实对于并发量不大的项目来说,其实运行起来也不会出什么问题。但是 能改则改。
// CPU 核心数:
// 核数 。CPU密集计算:N+1// IO类型的就是:2Nintcores = Runtime.getRuntime().availableProcessors();
线程池 spring boot 异步执行任务配置实例, 一般都是CPU类型的异步任务
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
import java.util.concurrent.ThreadPoolExecutor;
/**
* 自定义异步线程的执行器
* 使用 ThreadPoolTaskExecutor 线程池方式,避免开启过多的线程
*
* @author James
* @date 2018/7/16 上午11:40
*/
@Configuration
@EnableAsync
public class ExecutorConfig
{
/**
* Set the ThreadPoolExecutor's core pool size.
*/
private int corePoolSize = 4;
/**
* Set the ThreadPoolExecutor's maximum pool size.
*/
private int maxPoolSize = Runtime.getRuntime().availableProcessors() + 3;
/**
* Set the capacity for the ThreadPoolExecutor's BlockingQueue.
* 队列数不能太大,否则就会任务堆积,处理就太慢了。
*/
private int queueCapacity = 300;
@Bean
public Executor myAsync()
{
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setThreadNamePrefix("MyExecutor-");
// rejection-policy:当pool已经达到max size的时候,如何处理新任务
// CALLER_RUNS:不在新线程中执行任务,而是有调用者所在的线程来执行 。 一般这种任务不能丢弃
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}
以上代码就是 当spring boot 中 执行 异步 代码的时候所用到的线程池配置了: 即加了 @Async 的方法
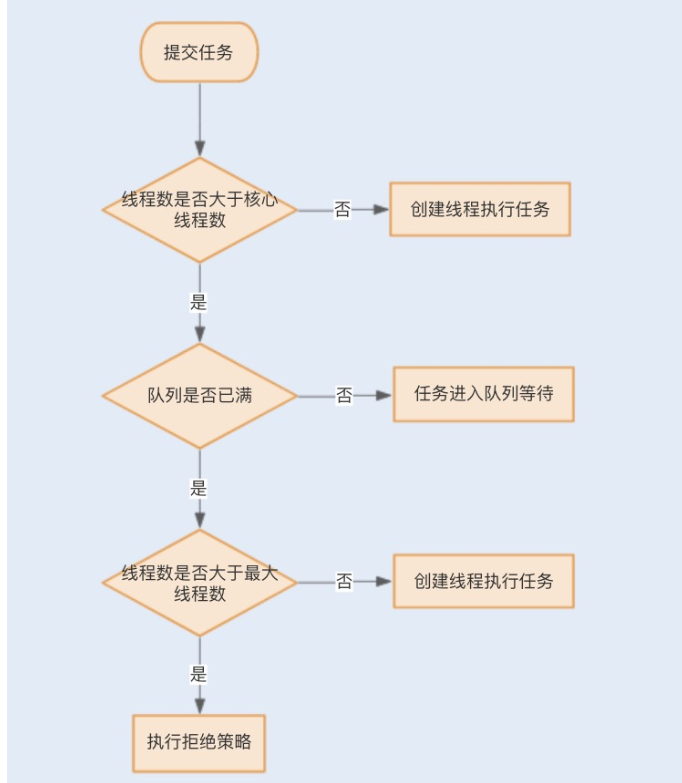
线程池任务拒绝策略
LinkedBlockingQueue和ArrayBlockingQueue迥异
自定义CPU密集型线程池例子
使用 LinkedBlockingQueue 是因为其可以有更高的吞吐量
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.util.concurrent.*;
@Component
public class ExecutionResultPool {
private static final Logger logger = LoggerFactory.getLogger(ExecutionResultPool.class);
private ExecutorService threadPool;
public void init() {
// 核数 。 CPU 密集计算: N+1
// IO 类型的就是: 2N
int cores = Runtime.getRuntime().availableProcessors();
ThreadFactory threadFactory = new ThreadFactoryBuilder()
.setNameFormat("timing-executor-pool-%d").build();
threadPool = new ThreadPoolExecutor(4,
cores+3, 30, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
threadFactory,
(r, executor) -> {
try {
// // 尝试再次加入队列。如果队列已满,那么等待,直到队列空了就放进去
executor.getQueue().put(r);
} catch (InterruptedException e) {
logger.error("任务加入队列失败", e);
Thread.currentThread().interrupt();
}
});
logger.info("初始化任务执行线程池 {}", threadFactory);
}
public void execute(Runnable runnable) {
threadPool.execute(runnable);
}
}
数据库连接池配置
发现一些同时将最大连接数配置到了100左右,其实也是随便拍脑袋的结果。

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)