
通过docxtpl 自动生成数据库设计文档
docxtpl这是一个比较冷门的 Python 库,而且库中的函数也不多,才几个,但功能却很专一。如果说 docx 库的强大在于生成我们想要的 Word 文档,那么 Docxtpl 库的存在就是将这些文档按固定格式输出。今天在编写数据库结构文档,想到如此重复的工作,自然有系统办法实现,就找到了这个库。docxtpl是基于python-docx和jinja2开发出来的库。他通过对docx文档模版加载
·
docxtpl这是一个比较冷门的 Python 库,而且库中的函数也不多,才几个,但功能却很专一。如果说 docx 库的强大在于生成我们想要的 Word 文档,那么 Docxtpl 库的存在就是将这些文档按固定格式输出。
今天在编写数据库结构文档,想到如此重复的工作,自然有系统办法实现,就找到了这个库。
docxtpl是基于python-docx和jinja2开发出来的库。他通过对docx文档模版加载,使用类似jinja2网页模版开发的语法对其进行修改。
第一步,设计文档模板,按照jinjia2的结构要求

第二步,编写获取元数据字典的脚本
import jinja2
from docxtpl import DocxTemplate
from docxtpl import InlineImage
from docx.shared import Mm
import psycopg2
import psycopg2.extras
tablesql = """
SELECT row_number() over(ORDER BY table_name) as table_no,
table_name as table_english_name,
obj_description (oid, 'pg_class') as table_chinese_name,
table_catalog as table_catalog,
table_schema as table_schema,
pg_size_pretty (pg_relation_size (table_name)) as pg_size_pretty
FROM information_schema.tables t1,
pg_class t2
WHERE table_schema = 'public'
AND t1.table_name = t2.relname
ORDER BY 2"""
tablecolumnsql = """
SELECT t1.relname as table_english_name,
base.column_name column_english_name,
col_description (t1.oid,t2.attnum) column_chinese_name,
base.udt_name column_data_type,
t2.attnum as column_no,
COALESCE(character_maximum_length, numeric_precision, datetime_precision) column_length,
(case when t2.attnotnull = true then 'Y' else 'N' end) as column_null_flag,
(case when (select count(pg_constraint.*)
from pg_constraint
inner join pg_class on pg_constraint.conrelid = pg_class.oid
inner join pg_attribute on pg_attribute.attrelid = pg_class.oid and pg_attribute.attnum = any(pg_constraint.conkey)
inner join pg_type on pg_type.oid = pg_attribute.atttypid
where pg_class.relname = t1.relname
and pg_constraint.contype = 'p'
and pg_attribute.attname =t2.attname) > 0 then 'Y'
else 'N' end) as column_primarykey_flag
FROM information_schema.COLUMNS base,
pg_class t1,
pg_attribute t2
WHERE t1.relname = base."table_name"
AND t2.attname = base."column_name"
AND base.table_schema='public'
AND t1.oid = t2.attrelid
AND t2.attnum > 0
order by 1,5
"""第三步,构造数据库链接,获取数据
def gettablecolumninfo():
tablelist = []
tablecolumnlist = []
hostname = '*.*.*.*'
port = '5432'
username = 'postgres'
password = '*******'
database = '*****db'
connection = psycopg2.connect(host=hostname, port=port, user=username, password=password, dbname=database)
cur = connection.cursor(cursor_factory=psycopg2.extras.DictCursor)
cur.execute(tablesql)
results = cur.fetchall()
for result in results:
tablelist.append(result)
cur.execute(tablecolumnsql)
results = cur.fetchall()
for result in results:
tablecolumnlist.append(result)
cur.close()
connection.close()
return tablelist, tablecolumnlist第四步,将数据结构转换为嵌套方式,以便前端容易实现
def trandataformat(tablelist, tablecolumnlist):
tablecolumnlist_out = []
for table in tablelist:
tabledict = {}
tabledict['table_no'] = table[0]
tabledict['table_english_name'] = table[1]
tabledict['table_chinese_name'] = table[2]
columnlist = []
for column in tablecolumnlist:
if tabledict['table_english_name'] == column[0]:
columndict = {}
columndict['table_english_name'] = column[0]
columndict['column_english_name'] = column[1]
columndict['column_chinese_name'] = column[2]
columndict['column_data_type'] = column[3]
columndict['column_no'] = column[4]
columndict['column_length'] = column[5]
columndict['column_pk_flag'] = column[7]
columnlist.append(columndict)
tabledict['columns'] = columnlist
tablecolumnlist_out.append(tabledict)
return tablecolumnlist_out第五步,进行转换,将模板和数据输出到文件中
tablelist, tablecolumnlist = gettablecolumninfo()
tablecolumnlist_out = trandataformat(tablelist, tablecolumnlist)
project_name = 'XXXX系统'
project_unit_name = 'XXXX中心'
project_description = 'XXXXXXXXXXXX'
db_type = 'PostgreSQL'
db_name = 'XXXdb'
templatefile = r'D:\JetBrains\PycharmProjects\solutionprj\表设计说明书模板.docx'
tpl = DocxTemplate(templatefile)
context = {"project_name": project_name,
"project_unit_name": project_unit_name,
"project_description": project_description,
"db_type": db_type,
"db_name": db_name,
"tablecolumnlist": tablecolumnlist_out
}
jinja_env = jinja2.Environment()
tpl.render(context, jinja_env)
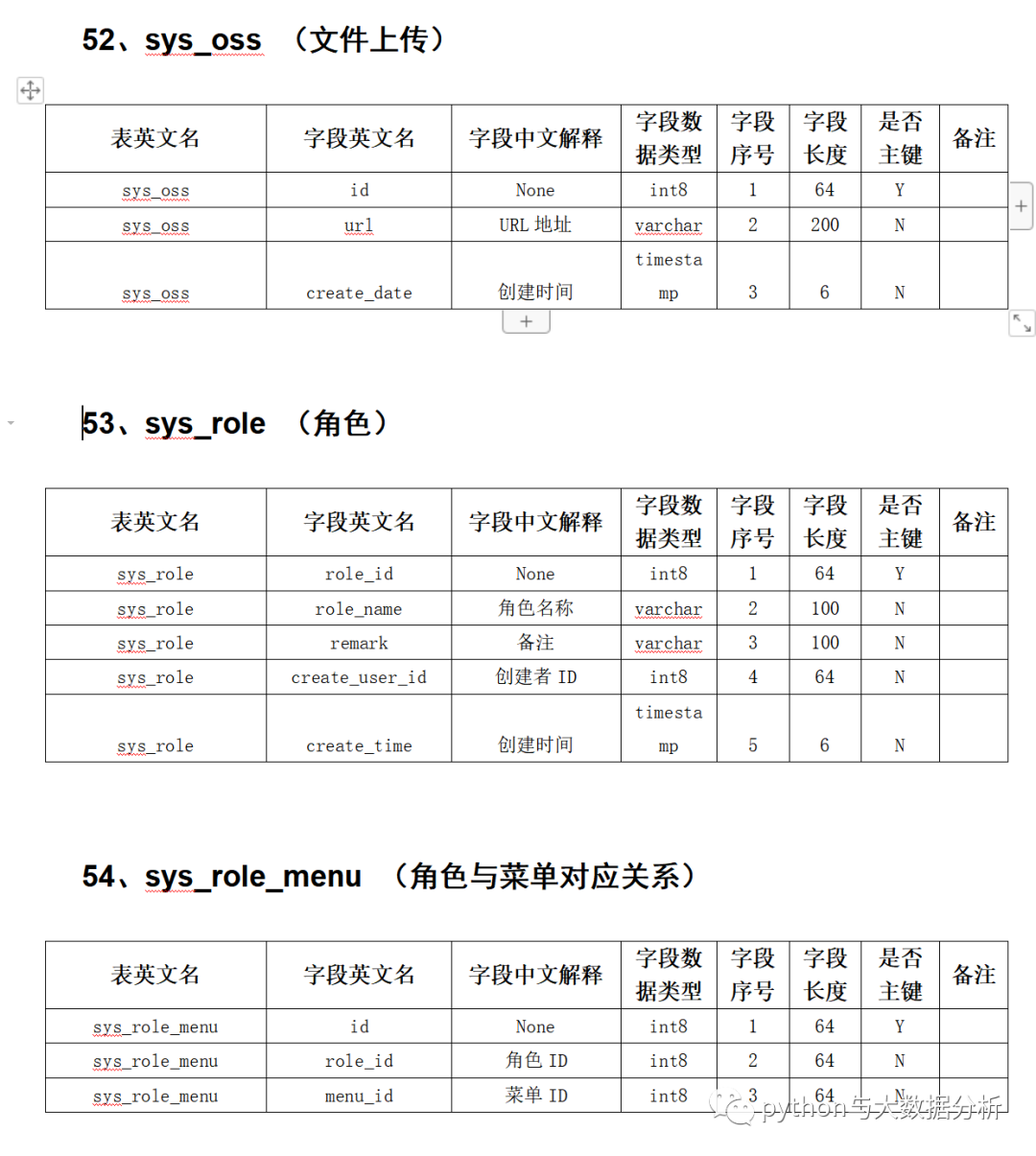
tpl.save("D:\JetBrains\PycharmProjects\solutionprj\XXXX系统表结构.docx")以下是最后生成的样例
欢迎关注公众号:python与大数据分析


一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)