
dbcc收缩数据库_使用DBCC SHRINKFILE收缩数据库
dbcc收缩数据库 介绍 (Introduction)SQL Server is pretty good at managing disk space.As long as we do our part to set up appropriate storage types and place files and filegroups properly and set reasona...
dbcc收缩数据库
介绍 (Introduction)
SQL Server is pretty good at managing disk space. As long as we do our part to set up appropriate storage types and place files and filegroups properly and set reasonable AUTOGROW settings, it’s almost a set-it-and-forget-it operation. Mind you, I said, “almost!” Sometimes, things do go BUMP! in the night and we need to act. Here’s what happened to me not too long ago:
SQL Server非常擅长管理磁盘空间。 只要我们尽力设置适当的存储类型并正确放置文件和文件组并设置合理的AUTOGROW设置,这几乎就是“设置后忘记”操作。 我说,“快点!” 有时候,事情确实会变得很糟糕! 在晚上,我们需要采取行动。 这是不久前发生在我身上的事情:
I look after a fairly large database (about 10TB at the moment, and growing). Using table partitioning and switching and archiving, we can manage in the space we have, assuming other things don’t change. One day though, I noticed our free space was reaching a critical level: just 5%. Upon investigation, I discovered that the Windows drive my database was on was shared with another database that didn’t really belong there and it was growing with no end in sight. That got my attention!
我照顾一个相当大的数据库(目前大约10TB,并且还在不断增长)。 假设其他情况不变,使用表分区以及切换和归档功能,我们可以在现有的空间中进行管理。 但是有一天,我注意到我们的可用空间达到了一个临界水平:只有5%。 经过调查,我发现数据库所在的Windows驱动器与另一个并不真正属于该数据库的数据库共享,并且该数据库在不断发展,而且没有尽头。 那引起了我的注意!
应用压缩 (Applying compression)
The first thing I did to this rogue database was compress it. I have another SQLShack article, How to use SQL Server Data Compression to Save Space, that discusses compression, if you haven’t used it before. Simply put, SQL Server can achieve 40%, 50%, 60% and sometimes even more compression, depending on the data. After compressing all the tables and indexes in this particular database, I had a 1 TB database with more than 60% free space. But in case you’re thinking, “Problem solved!” that is only half the story. You see, the database had stopped growing but was still occupying that 1 TB on the file system. It’s just that now that file had tons of free space in it. I really wanted to reclaim that free space to give my main database some more headroom.
我对这个恶意数据库所做的第一件事就是压缩它。 我还有另一篇SQLShack文章,《 如何使用SQL Server数据压缩来节省空间》 ,其中讨论了压缩(如果您以前没有使用过的话)。 简而言之,根据数据的不同,SQL Server可以实现40%,50%,60%的压缩,有时甚至更高。 压缩了该特定数据库中的所有表和索引之后,我有了一个1 TB数据库,其可用空间超过60%。 但是如果您在想,“问题解决了!” 那只是故事的一半。 您会看到,数据库已停止增长,但仍在文件系统上占用了1 TB。 只是现在文件中有大量可用空间。 我真的很想回收该可用空间,以便为我的主数据库留出更多空间。
看到缩小 (Seeing the shrink)
You might be aware that databases can be configured with an AUTOSHRINK setting. A little googling will turn up any number of articles on why this is usually not a good thing to enable. In a nutshell, shrinking is expensive. CPU, I/O, logging, blocking – all of these things increase during a shrink operation. If you need to shrink your database, you want to control it. I needed to shrink my rogue database but no way was I going to enable AUTOSHRINK! For reasons why not, see Auto-shrink – turn it OFF!
您可能知道,可以使用AUTOSHRINK设置来配置数据库。 进行一些谷歌搜索将发现许多文章,为什么通常这不是一件好事。 简而言之,收缩是昂贵的。 CPU,I / O,日志记录,阻止–所有这些事情在收缩操作期间都会增加。 如果需要收缩数据库,则需要对其进行控制。 我需要缩小流氓数据库,但无法启用AUTOSHRINK! 出于某些原因,请参阅自动收缩–将其关闭!
What’s the alternative, you might ask? DBCC! The Database Console Commands is a set of commands to perform various types of maintenance and metadata activities. You probably already know the command CHECKDB. I needed to use another command SHRINKFILE.
您可能会问,还有什么选择? DBCC ! 数据库控制台命令是一组用于执行各种类型的维护和元数据活动的命令。 您可能已经知道命令CHECKDB。 我需要使用另一个命令SHRINKFILE。
DBCC SHRINKFILE, as the name implies, shrinks files not databases. Of course, from a file system standpoint, a database is nothing more than a set of files, so that makes sense. Shrink all the files in a database and you’ve shrunk the database. Simple, except…
顾名思义,DBCC SHRINKFILE收缩文件而不是数据库。 当然,从文件系统的角度来看,数据库不过是一组文件而已,所以这很有意义。 缩小数据库中的所有文件,然后缩小数据库。 很简单,除了...
Those warnings about CPU, I/O, logging and blocking are real. For my first try, I just ran the command:
这些有关CPU,I / O,日志记录和阻塞的警告是真实的。 对于我的第一次尝试,我只运行了命令:
DBCC SHRINKFILE (N’MyDataFile’, 0);
DBCC SHRINKFILE(N'MyDataFile',0);
(Note: 0 is the target size of the file in megabytes, but the command always leaves enough space for the data in the file.)
(注意:0是文件的目标大小,以兆字节为单位,但是该命令始终为文件中的数据保留足够的空间。)
Which simply says, “Rearrange all the pages in the file until all the free space is at the end, then truncate the file at that point.” Sounds like just what I needed! However, on my 1TB database with 60% free space, this was still running after…drum roll…two days, and less than 30% done! I had to cancel it to let some production jobs run (remember the warning about blocking?) Now, perhaps you’re thinking, “But still, your file is 30% smaller now.” Sigh! The file size hadn’t changed at all! You see, SHRINKFILE doesn’t truncate the file until the desired size is reached or there is no more free space to squeeze out.
它只是说:“重新排列文件中的所有页面,直到所有可用空间都结束为止,然后在那一点上截断文件。” 听起来就像我所需要的! 但是,在我的具有60%可用空间的1TB数据库上,它在……鼓滚动……两天后仍在运行,完成了不到30%! 我必须取消它才能运行某些生产作业(还记得有关阻塞的警告吗?)现在,也许您在想:“但是,您的文件现在要小30%。” 叹! 文件大小完全没有改变! 您会看到,SHRINKFILE不会截断文件,直到达到所需的大小或没有更多的可用空间可供挤出为止。
检查站? (Checkpoints?)
Wouldn’t it be nice if SHRINKFILE would checkpoint itself every so often, truncate the file to commit the free space it had recovered, then continue? Well, it doesn’t work that way but we can get it to do that if we are clever. You see, there is no reason to try to shrink the file in one operation. You can do it in two operations, or four, or four hundred. Also, you can pause between each shrink step to let other processes work with the database. Doing it this way, you minimize blocking and logging, and the CPU and I/O can be hidden in the noise of other work.
如果SHRINKFILE会如此频繁地对自身进行检查,截断文件以提交已恢复的可用空间,然后继续执行,那不是很好吗? 好吧,这种方式行不通,但是如果我们很聪明,我们可以做到这一点。 您会发现,没有理由尝试通过一项操作来缩小文件。 您可以分两次或四次或四百次进行。 此外,您可以在每个收缩步骤之间暂停,以使其他进程与数据库一起工作。 这样,可以最大程度地减少阻塞和日志记录,并且CPU和I / O可能隐藏在其他工作中。
Here’s a simple script that can do this:
这是一个可以执行此操作的简单脚本:
USE SQLShack
GO
DECLARE @FileName sysname = N'SQLShack';
DECLARE @TargetSize INT = (SELECT 1 + size*8./1024 FROM sys.database_files WHERE name = @FileName);
DECLARE @Factor FLOAT = .999;
WHILE @TargetSize > 0
BEGIN
SET @TargetSize *= @Factor;
DBCC SHRINKFILE(@FileName, @TargetSize);
DECLARE @msg VARCHAR(200) = CONCAT('Shrink file completed. Target Size: ',
@TargetSize, ' MB. Timestamp: ', CURRENT_TIMESTAMP);
RAISERROR(@msg, 1, 1) WITH NOWAIT;
WAITFOR DELAY '00:00:01';
END;
Let me walk you through this script to see what’s going on. First, I declare three variables:
让我引导您完成此脚本,看看发生了什么。 首先,我声明三个变量:
- @FileName is the name of the file to be shrunk. I’ll show you where to find the name in a moment. @FileName是要缩小的文件的名称。 一会儿,我将告诉您在哪里可以找到名字。
- @TargetSize is the desired size of the file, after shrinking. The query returns the current size in megabytes, + 1 to account for rounding. @TargetSize是缩小后文件的所需大小。 该查询返回以兆字节为单位的当前大小(+1)以进行舍入。
- @Factor is a factor to be applied to the target size for every time DBCC SHRINKFILE is called. 每次调用DBCC SHRINKFILE时,@ Factor是一个应用于目标大小的因素。
The system view sys.database_files shows all the files for the database context you are currently in. In my case, this query:
系统视图sys.database_files显示您当前所在的数据库上下文的所有文件。在我的情况下,此查询:
SELECT TYPE_DESC, NAME, size, max_size, growth, is_percent_growth
FROM sys.database_files;
Returns:
返回值:
There are two files in this little database. The first one contains data rows – tables and indexes and other objects; the second one is for the log. The name column is what I need for the @FileName parameter, above. The size column is the size of the file in SQL Server pages. Recall that a page is 8K = 8192 bytes. The other columns show the max size (-1 means no limit) and growth factor, in pages, unless the column is_percent_growth = 1, in which case the growth is in percent.
这个小数据库中有两个文件。 第一个包含数据行–表和索引以及其他对象; 第二个用于日志。 名称列是我需要上述@FileName参数的地方。 大小列是SQL Server页面中文件的大小。 回想一下页面是8K = 8192字节。 其他列以页为单位显示最大大小(-1表示无限制)和增长因子,除非is_percent_growth = 1,在这种情况下增长以百分比表示。
I need to convert size in pages to megabytes. That is just:
我需要将页面大小转换为兆字节。 那只是:
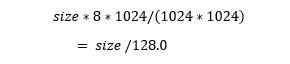
In the body of the loop, I first reduce the target size by the factor. In this case that is .999 or 1/1000th. That seems small but it makes sense for my 1 TB database. That is 1GB per shrink operation. Now, I execute the DBCC SHRINKFILE command then issue a message, reporting on my process. DBCC will also produce a result set for each call. It looks like this:
在循环的主体中,我首先将目标大小减小了一个因子。 在这种情况下是0.999或1/1000。 这似乎很小,但对我的1 TB数据库来说是有意义的。 即每个收缩操作1GB。 现在,我执行DBCC SHRINKFILE命令,然后发出一条消息,报告我的过程。 DBCC还将为每个调用生成一个结果集。 看起来像这样:
It shows the current size (after shrinking), the minimum size this database could be, the current number of used pages and the estimated minimum size after shrinking. Why are there 8 more pages in the current size than the actual used pages? That’s partially because SQL Server allocates space in extents which are 64KB in size, or 8, 8KB pages. SQL Server has also reserved one extent for housekeeping.
它显示了当前大小(缩小后),该数据库可能的最小大小,当前使用的页面数以及缩小后的估计最小大小。 为什么当前尺寸的页面比实际使用的页面多8个? 部分原因是因为SQL Server在大小为64KB或8、8KB页的扩展区中分配空间。 SQL Server还保留了一种范围的内务处理。
I added a WAITFOR statement to pause between each operation. In my case, that’s only one second, but I set it up to run after hours when the database was otherwise idle. A larger value (and perhaps a smaller factor) would allow this to be run along with other work, although running it in the wee hours is preferred.
我添加了一个WAITFOR语句以在每个操作之间暂停。 就我而言,这仅是一秒钟,但是我将其设置为在数据库空闲之前的几个小时后运行。 较大的值(可能较小的因数)可以使其与其他工作一起运行,尽管最好在凌晨运行。
摘要 (Summary)
Sometimes, shrinking a database is unavoidable. This happened to me after I applied table and index compression to a large database. However, shrinking a database is an expensive operation. I’ve shown how you can do that in small increments and keep the overhead to a minimum, even if it takes a little longer to reach the minimum size for a database.
有时,收缩数据库是不可避免的。 在将表和索引压缩应用于大型数据库之后,这发生在我身上。 但是,收缩数据库是一项昂贵的操作。 我已经展示了如何以较小的增量做到这一点,并将开销降至最低,即使达到数据库的最小大小需要花费更长的时间。
翻译自: https://www.sqlshack.com/shrinking-your-database-using-dbcc-shrinkfile/
dbcc收缩数据库

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)