
【分布式数据库】——rqlite
一、前言rqlite : 基于 SQLite 构建的轻量级、分布式关系数据库, 使用Go 编程实现,使用 Raft 算法来确保所有 SQLite 数据库实例的一致性。下载地址和方式:Download二、下载启动使用(伪分布式)1、主节点启动#下载curl -L https://github.com/rqlite/rqlite/releases/downloa...
一、前言
rqlite : 基于 SQLite 构建的轻量级、分布式关系数据库, 使用Go 编程实现,使用 Raft 算法来确保所有 SQLite 数据库实例的一致性。
- 下载地址和方式 :Download
二、下载启动使用(伪分布式)
1、主节点启动
#下载
curl -L https://github.com/rqlite/rqlite/releases/download/v4.5.0/rqlite-v4.5.0-linux-
amd64.tar.gz -o rqlite-v4.5.0-linux-amd64.tar.gz
#解压
tar xvfz rqlite-v4.5.0-linux-amd64.tar.gz
#启动,默认启用4001端口
cd rqlite-v4.5.0-linux-amd64
./rqlited ~/node.1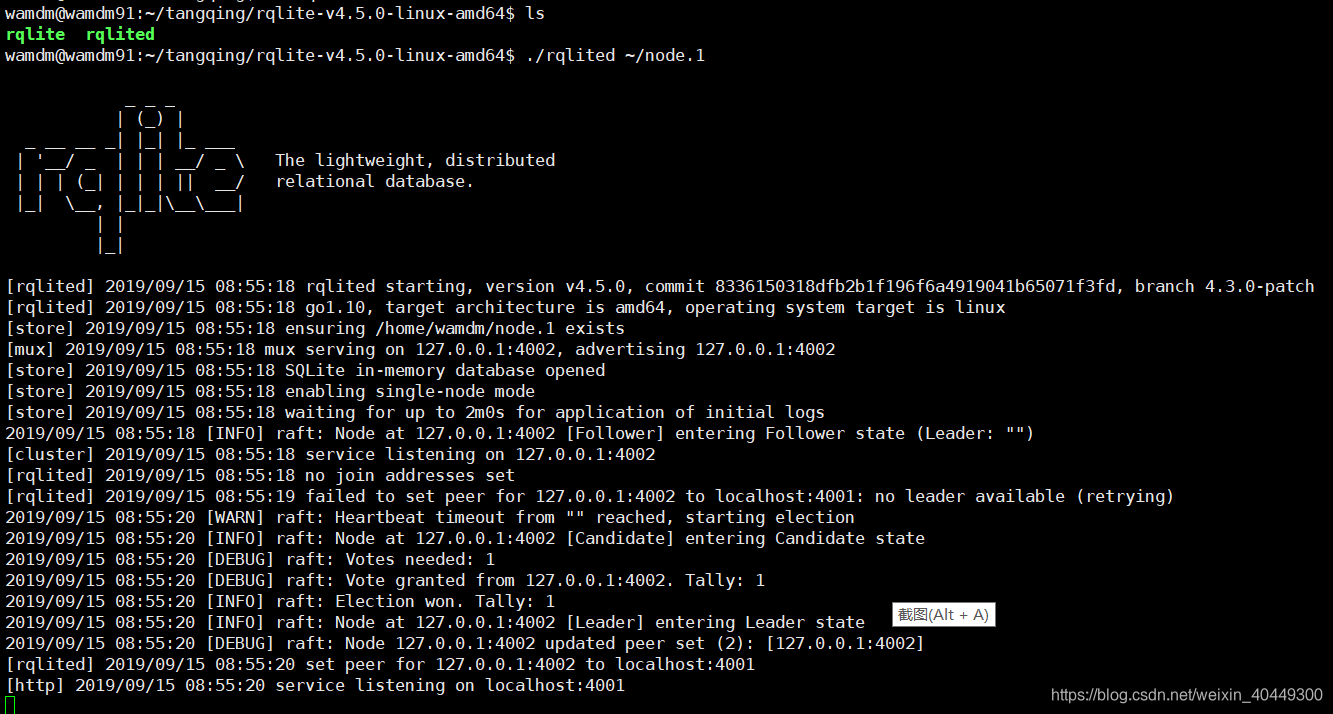
2、多节点加入
rqlited -http-addr localhost:4003 -raft-addr localhost:4004 -join http://localhost:4001 ~/node.2
rqlited -http-addr localhost:4005 -raft-addr localhost:4006 -join http://localhost:4001 ~/node.3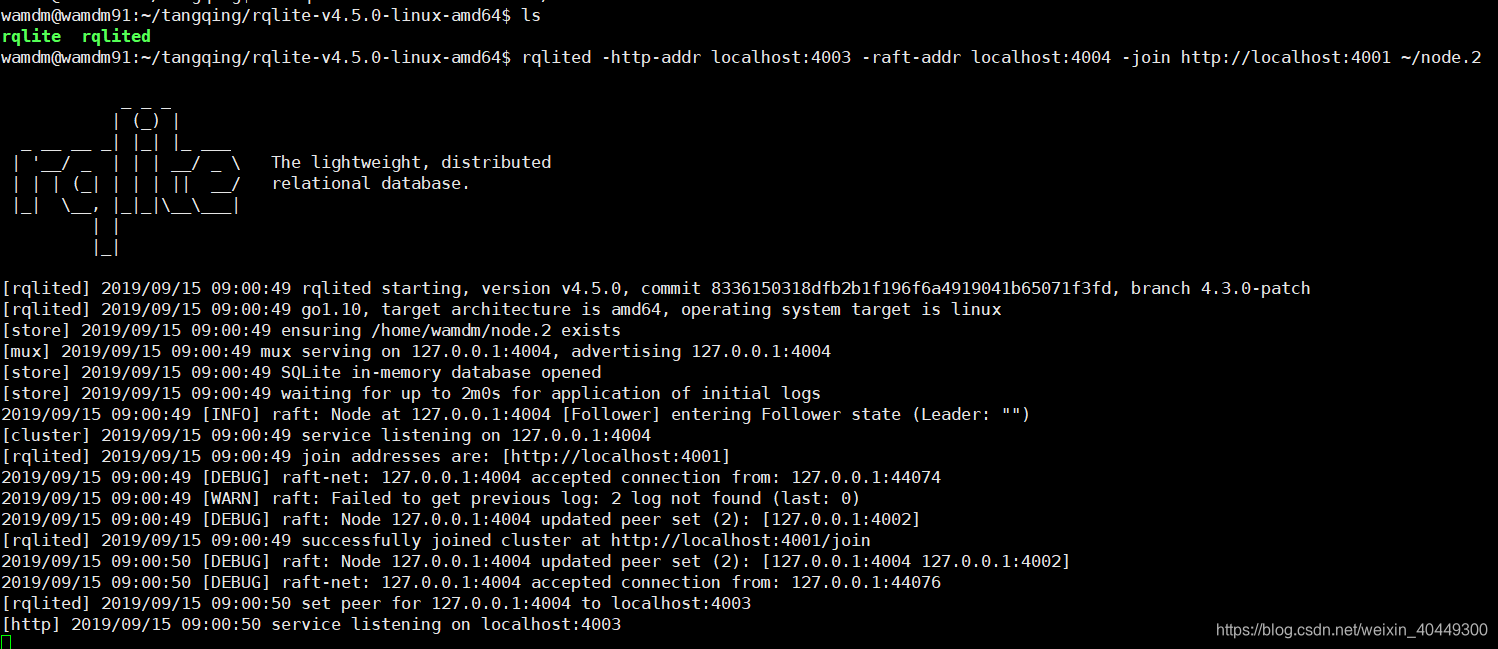
注:这个演示展示了在同一台主机上运行的所有3个节点。
3、测试
$ rqlite
127.0.0.1:4001> CREATE TABLE foo (id INTEGER NOT NULL PRIMARY KEY, name TEXT)
0 row affected (0.000668 sec)
127.0.0.1:4001> .schema
+-----------------------------------------------------------------------------+
| sql |
+-----------------------------------------------------------------------------+
| CREATE TABLE foo (id INTEGER NOT NULL PRIMARY KEY, name TEXT) |
+-----------------------------------------------------------------------------+
127.0.0.1:4001> INSERT INTO foo(name) VALUES("fiona")
1 row affected (0.000080 sec)
127.0.0.1:4001> SELECT * FROM foo
+----+-------+
| id | name |
+----+-------+
| 1 | fiona |
+----+-------+
三、测试(伪分布式)
本文采用pyrqlite提供的接口进行测试,github地址:https://github.com/rqlite/pyrqlite
1、下载安装
$ cd
$ git clone https://github.com/rqlite/pyrqlite.git
$ pip install ./pyrqlite2、安装pytest
pip install -U pytest3、测试样例
import pyrqlite.dbapi2 as dbapi2
# Connect to the database
connection = dbapi2.connect(
host='localhost',
port=4001,
)
try:
with connection.cursor() as cursor:
cursor.execute('CREATE TABLE foo (id integer not null primary key, name text)')
cursor.executemany('INSERT INTO foo(name) VALUES(?)', seq_of_parameters=(('a',), ('b',)))
with connection.cursor() as cursor:
# Read a single record with qmark parameter style
sql = "SELECT `id`, `name` FROM `foo` WHERE `name`=?"
cursor.execute(sql, ('a',))
result = cursor.fetchone()
print(result)
# Read a single record with named parameter style
sql = "SELECT `id`, `name` FROM `foo` WHERE `name`=:name"
cursor.execute(sql, {'name': 'b'})
result = cursor.fetchone()
print(result)
finally:
connection.close()
资源消耗情况:
Tasks: 273 total, 1 running, 272 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.1 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 13152356+total, 12714140+free, 772272 used, 3609888 buff/cache
KiB Swap: 999420 total, 999420 free, 0 used. 12996041+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2274 rabbitmq 20 0 4567292 58184 5112 S 3.3 0.0 764:12.83 beam.smp
314296 wamdm 20 0 1584840 15032 8776 S 2.0 0.0 0:45.72 rqlited
314437 wamdm 20 0 1148244 12156 8888 S 0.7 0.0 0:10.53 rqlited
314590 wamdm 20 0 1297020 12040 8612 S 0.7 0.0 0:09.50 rqlited
4、集体测试
$ python setup.py test四、分布式集群搭建
节点数量最好是单数,对于3节点,多数为2;对于4节点,多数为3。因此,3节点集群可以容忍单个节点的失败。然而,一个4节点的集群也只能容忍单个节点的失败。
假设你有3台主机,主机1, 主机2,和主机3,并将这些主机名解析为可从其他主机访问的IP地址
1、主机1:
host1:$ rqlited -node-id 1 -http-addr host1:4001 -raft-addr host1:4002 ~/node 此命令启动一个节点,侦听端口4001上的API请求,其他几点的请求通过端口4002。此节点将其状态存储在~/node.
2、主机2
host2:$ rqlited -node-id 2 -http-addr host2:4001 -raft-addr host2:4002 -join http://host1:4001 ~/node如果节点接收到连接请求,而该节点实际上不是集群的领导者,则接收节点将自动将请求节点重定向到领导节点。因此,节点实际上可以通过联系集群中的任何节点来加入集群。还可以指定多个连接地址,节点将尝试每个地址,直到连接成功为止。
3、节点3
host3:$ rqlited -node-id 3 -http-addr host3:4001 -raft-addr host3:4002 -join http://host1:4001 ~/node重新启动节点时,不再需要传递-join..如果节点已经是集群的成员,它将被忽略。现在你已经拥有了一个容错、分布式的关系数据库。它可以容忍任何节点的故障,甚至是领导者的失败,并保持运行状态。
4、删除节点
如果一个节点完全失败并且没有返回,或者如果您关闭一个节点是因为您希望解除它,那么它的记录也应该从集群中删除。要从集群中删除节点的记录,请执行以下命令:
curl -XDELETE http://localhost:4001/remove -d '{"id": "<node raft ID>"}'删除节点不会改变达到仲裁所需的节点数,因此必须添加一个新节点作为替代。
五、自发现服务(分布式集群)
若要形成RQLITE集群,必须向连接节点提供集群中其他节点的网络地址,必须知道其他节点的网络地址才能加入集群。例如,如果您不知道将提前分配哪些网络地址,则第一次创建群集需要执行以下步骤:
- 首先启动一个节点并指定其网络地址。
- 让它成为领导者。
- 启动下一个节点,将第一个节点的网络地址传递给第二个节点。
- 重复前面的步骤,直到拥有所需大小的群集为止。
为了使这一切变得更容易,rqlitt还支持发现模式。在这种模式下,每个节点向外部服务注册其网络地址,并学习加入来自同一服务的其他节点的地址。为方便起见,rqlitt的免费发现服务托管在discovery.rqlite.com..
1、创建自发现ID
要通过发现形成一个新的集群,必须首先为集群生成一个唯一的发现ID。然后,在启动时将此ID传递给每个节点,从而允许rqite节点之间自动连接。若要使用rqite发现服务生成ID,执行以下命令:
curl -XPOST -L -w "\n" 'http://discovery.rqlite.com'{
"created_at": "2019-09-15 01:25:45.589277",
"disco_id": "809d9ba6-f70b-11e6-9a5a-92819c00729a",
"nodes": []
}在上面的例子中809d9ba6-f70b-11e6-9a5a-92819c00729a就是注册生成的,然后,在启动时向每个节点提供此ID。
rqlited -disco-id 809d9ba6-f70b-11e6-9a5a-92819c00729a当任何节点使用ID注册时,都会返回使用该ID注册的当前节点列表。如果该节点是第一个使用该ID访问服务的节点,则它将收到一个仅包含自身的列表-随后将选出自己的领导。随后的节点将接收一个包含多个条目的列表。这些节点将使用列表中的一个连接地址来加入集群。

一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)