
mysql筛选两个表有相同项的数据库_用SQL查询两个表中相同的数据
展开全部1、创建测试表;create table test_col_1(id number, var varchar2(200));create table test_col_2(id number, var varchar2(200));2、插入测试数据,insert into test_col_1select level*8, 'var'||32313133353236313431303231
展开全部
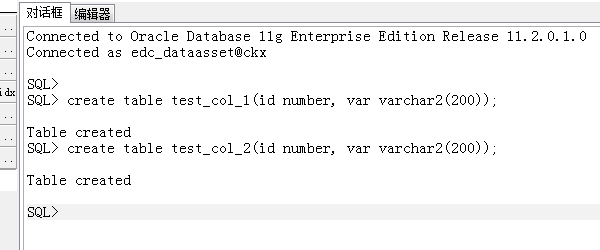
1、创建测试表;
create table test_col_1(id number, var varchar2(200));
create table test_col_2(id number, var varchar2(200));
2、插入测试数据,
insert into test_col_1
select level*8, 'var'||32313133353236313431303231363533e59b9ee7ad9431333431373839level*8 from dual connect by level <= 20;
insert into test_col_2
select level, 'var'||level from dual connect by level <= 100;

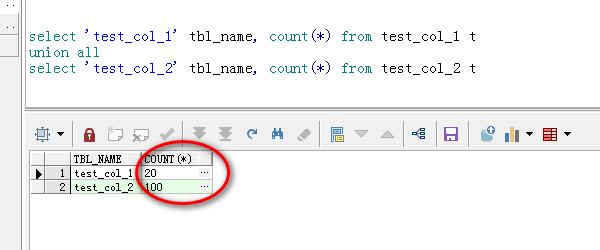
3、比较两表的数据,可以发现表2的数据多于表1;
select 'test_col_1' tbl_name, count(*) from test_col_1 t
union all
select 'test_col_2' tbl_name, count(*) from test_col_2 t
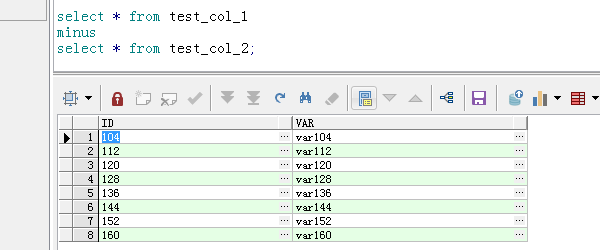
4、表1有部分比表2多的数据,
select * from test_col_1
minus
select * from test_col_2;
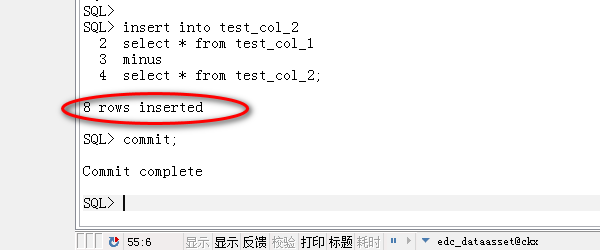
5、插入表1多的数据,如表2,执行sql,可以发现有多条记录插入。
insert into test_col_2
select * from test_col_1
minus
select * from test_col_2;

一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)