
Doris数据库建表语法以及分区分桶简介
doris数据库数据库的基本操作,以及分区和分桶的基本概念,以及使用场景
3.数据表的创建
3.1 创建用户和数据库
(1)创建test用户
#进入mysql
mysql -h hadoop1 -P 9030 -uroot -p
#创建test用户,密码为test
create user 'test' identified by 'test';(2)创建数据库
create database test_db;(3)用户授权
grant all on test_db to test;(4)验证
#退出MySQL-client
quit;
#使用进入mysql-client
mysql -h hadoop102 -P 9030 -utest -p;
#使用test_db数据库
use databases;
show tables;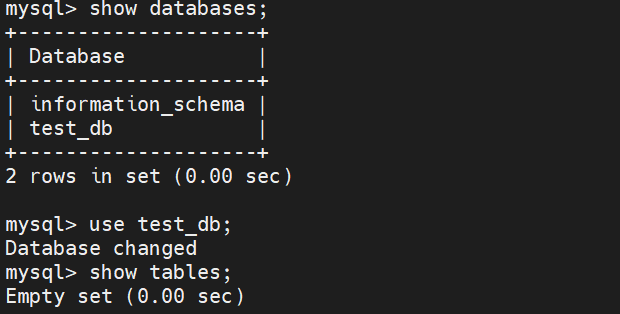
3.2 数据基本概念
3.2.1 Row&Column
这个行(Row)和列(Column)与我们在mysql数据表中的行和列是一样的,Row就是用户的一行数据,Column就是一行数据中的各个字段。
*默认模型,Column只分为排序列和非排序列。存储引擎会按照排序对数据进行排序存储,并建立稀疏索引,以便在排序数据上进行快速查找。
*聚合模型,Column可以分为两大类:Key和Value。从业务角度,key和value可以看作就是维度列和指标列。从聚合模型的角度来说,key列相同的行,会聚合成一行。其中Value列聚合方式由用户在建表时指定。
举例说明一下维度列和指标列,计算某一学科的平均分,学科就是维度列,平均分就是指标列。
3.2.2 分区和分桶
在 Doris 的存储引擎中,用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一步的按照 Hash 的方式分桶,分桶的规则是要找用户指定的分桶列的值进行 Hash 后分桶。
每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
*Tablet 之间的数据是没有交集的,独立存储的。Tablet 也是数据移动、复制等操作的最小物理存储单元。
* Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
3.3 建表示例
3.3.1 建表语法
使用的命令:CREATE TABLE
CREATE TABLE 表名CREATE TABLE 表名
HELP CREATE TABLE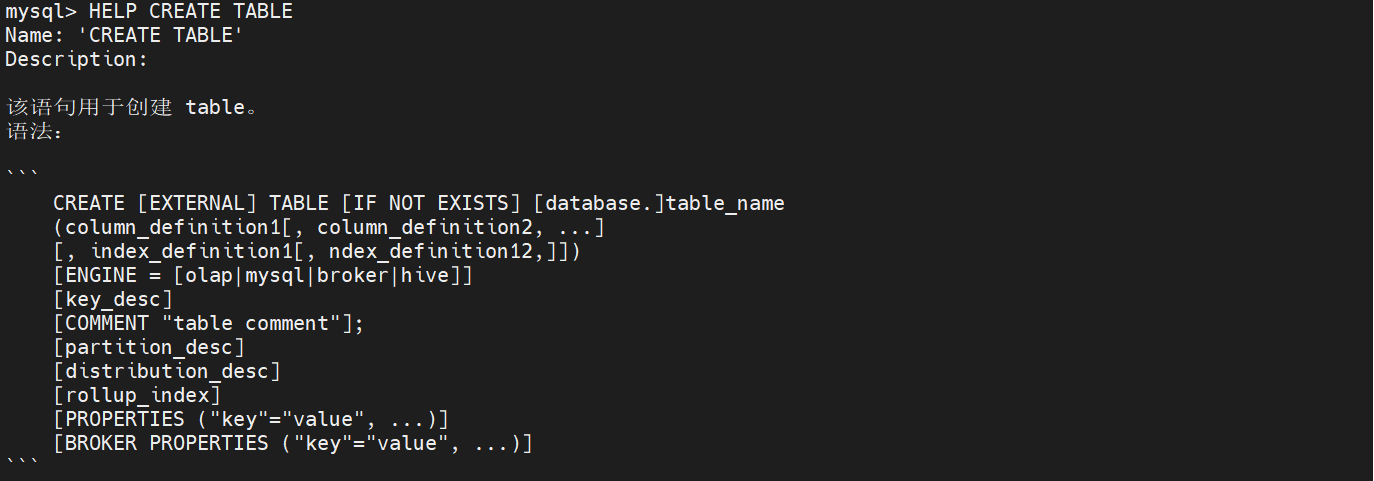
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name 建表的表名
(column_definition1[, column_definition2, ...] 对于列的定义 id int 之类的
[, index_definition1[, index_definition12,]]) 定义索引
[ENGINE = [olap|mysql|broker|hive]] 引擎 可选四种
[key_desc] 指定key列
[COMMENT "table comment"]; 表的注释
[partition_desc] 分区
[distribution_desc] 分桶
[rollup_index] 上卷
[PROPERTIES ("key"="value", ...)] 表的属性
[BROKER PROPERTIES ("key"="value", ...)]; broker属性
Doris的建表是一个同步命令,命令返回成功,就代表建表成功
Doris支持单分区和复合分区两种建表方式
1)复合分区:既有分区也有分桶
第一级称之为Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型类型和时间类型的列),并指定每个分区的取值范围。
第二级称之为Distribution,即分桶。用户可以指定一个或者多个维度以及桶数对数据进行HASH分布。
2)单分区:只做HASH分布,即只做分桶
3.3.2 字段类型
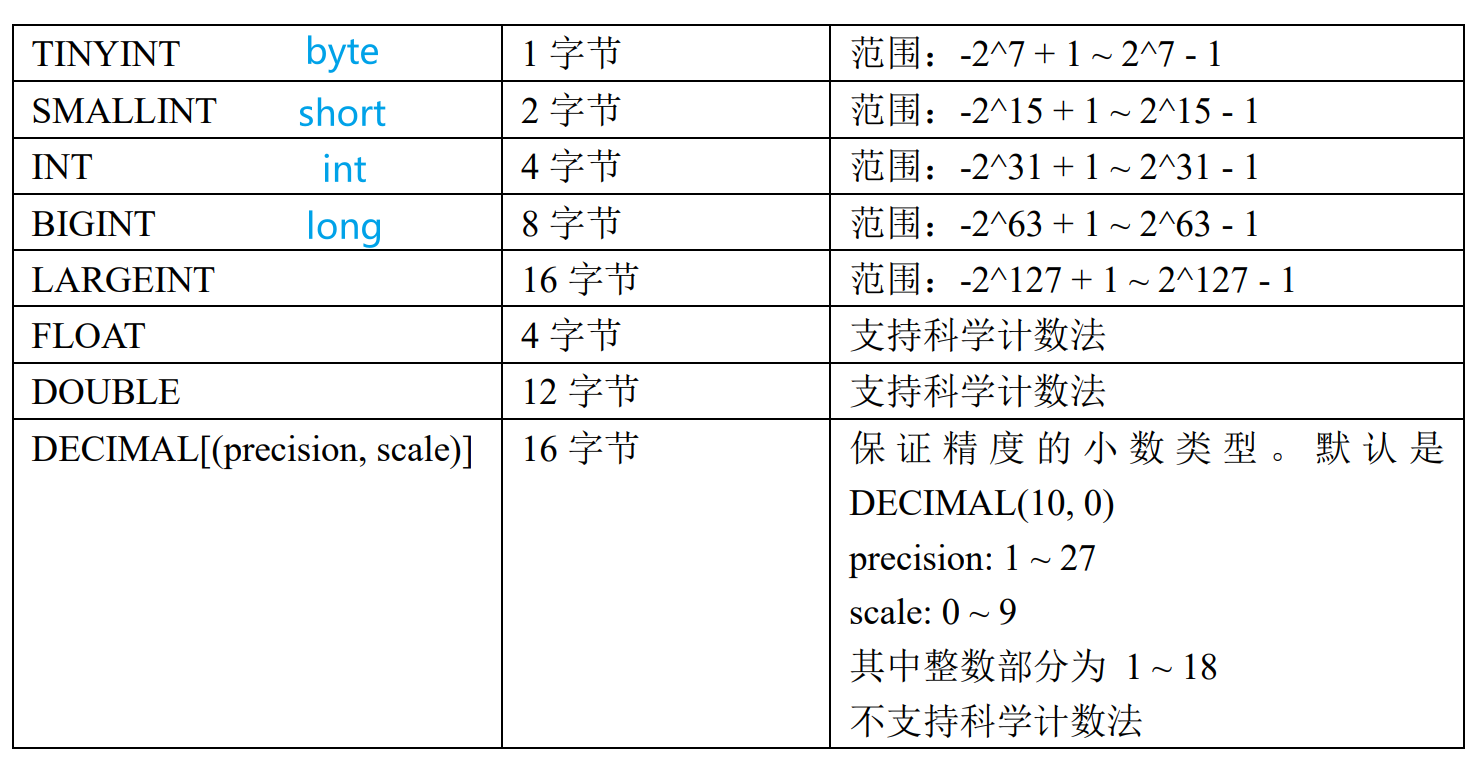
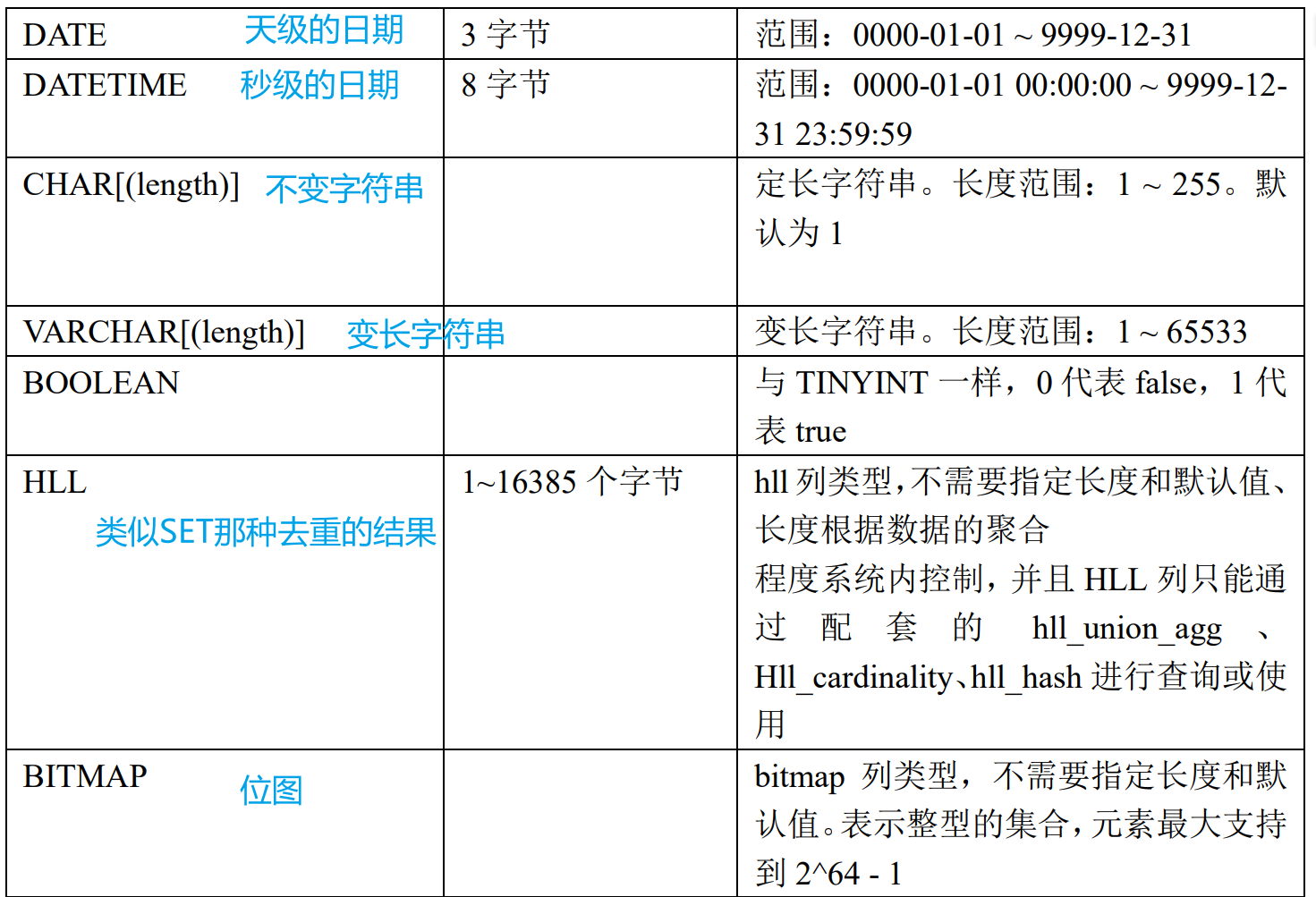
注:聚合模型在定义字段类型后,可以指定字段的 agg_type 聚合类型,如果不指定,则该列为 key 列。否则,该列为 value 列, 类型包括:SUM、MAX、MIN、REPLACE。
个人理解:
针对聚合模型的字段,我们可以理解为这个字段是会变化的,就是如果我们指定了一个字段是聚合类型是sum的类型,就是可以说明这个字段是算的一个累计的值,就比如说有这么一个字段是累计消费,然后我们把这个字段的聚合类型设置成sum字段,然后对这个字段就是会计算累计的消费,max是计算该字段某一维度的最大值,min就是计算该字段的某一维度的最小值,replace就是计算该字段的最新的值进行替换。
3.3.3 建表示例
我们以一个建表操作来说明 Doris 的数据划分。
示例一:按照时间分区,按照user_id做分桶
CREATE TABLE IF NOT EXISTS example_db.expamle_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01
00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
); 
示例二:
按照城市做分区
CREATE TABLE IF NOT EXISTS example_db.expamle_list_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01
00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时
间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
); 
3.3.4 数据的划分
以 AGGREGATE KEY 数据模型为例进行说明。更多数据模型参阅 Doris 数据模型。
列的基本类型,可以通过在 mysql-client 中执行 HELP CREATETABLE; 查看。
AGGREGATE KEY 数据模型中,所有没有指定聚合方式(SUM、REPLACE、MAX、MIN)的列视为 Key 列。而其余则为 Value 列。
定义列时,可参照如下建议:
➢ Key 列必须在所有 Value 列之前。
➢ 尽量选择整型类型。因为整型类型的计算和查找比较效率远高于字符串。
➢ 对于不同长度的整型类型的选择原则,遵循够用即可。
➢ 对于 VARCHAR 和 STRING 类型的长度,遵循 够用即可。
➢ 所有列的总字节长度(包括 Key 和 Value)不能超过 100KB。
3.3.5 分区与分桶
分区
Doris 支持两层的数据划分。第一层是 Partition,支持 Range 和 List 的划分方式。第二层是 Bucket(Tablet),仅支持 Hash 的划分方式。
也可以仅使用一层分区。使用一层分区时,只支持 Bucket 划分。
1) Range 分区
分区列通常为时间列,以方便的管理新旧数据。不可添加范围重叠的分区。
Partition 指定范围的方式
* VALUES LESS THAN (...) 仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。分区的删除不会改变已存在分区的范围。删除分区可能出现空洞。
* VALUES [...) 指定同时指定上下界,生成一个左闭右开的区间。
通过 VALUES [...) 同时指定上下界比较容易理解。这里举例说明,当使用 VALUES LESS THAN (...) 语句进行分区的增删操作时,分区范围的变化情况:
(1)如上 expamle_range_tbl 示例,当建表完成后,会自动生成如下 3 个分区:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
(2)增加一个分区 p201705 VALUES LESS THAN ("2017-06-01"),分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
p201705: [2017-04-01, 2017-06-01)
(3)此时删除分区 p201703,则分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)
注意到 p201702 和 p201705 的分区范围并没有发生变化,而这两个分区之间,出现了
一个空洞:[2017-03-01, 2017-04-01)。即如果导入的数据范围在这个空洞范围内,是无法导
入的。
(4)继续删除分区 p201702,分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201705: [2017-04-01, 2017-06-01)
(5)现在增加一个分区 p201702new VALUES LESS THAN ("2017-03-01"),分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)
(6)现在删除分区 p201701,并添加分区 p201612 VALUES LESS THAN ("2017-01-01"),
分区结果如下:
p201612: [MIN_VALUE, 2017-01-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)
即出现了一个新的空洞:[2017-01-01, 2017-02-01)
2)List 分区
分区 列支 持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE,DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。不可添加范围重叠的分区。
Partition 支持通过 VALUES IN (...) 来指定每个分区包含的枚举值。下面通过示例说明,进行分区的增删操作时,分区的变化。
(1)如上 example_list_tbl 示例,当建表完成后,会自动生成如下 3 个分区:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
(2)增加一个分区 p_uk VALUES IN ("London"),分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
p_uk: ("London")
(3)删除分区 p_jp,分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_uk: ("London")
分桶
(1)如果使用了 Partition,则 DISTRIBUTED ... 语句描述的是数据在各个分区内的划分规则。如果不使用 Partition,则描述的是对整个表的数据的划分规则。
(2)分桶列可以是多列,但必须为 Key 列。分桶列可以和 Partition 列相同或不同。
(3)分桶列的选择,是在 查询吞吐 和 查询并发 之间的一种权衡:
① 如果选择多个分桶列,则数据分布更均匀。
如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景。
② 如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。
此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的 IO 影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
(4)分桶的数量理论上没有上限。
3.3.6 使用复合分区的场景
以下场景推荐使用复合分区
(1)有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
(2)历史数据删除需求:如有删除历史数据的需求(比如仅保留最近 N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE语句进行数据删除。
(3)解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
3.3.7 多列分区
Doris支持指定多列作为分区列,示例如下:
1)Range 分区
PARTITION BY RANGE(date, id)
(
PARTITION p201701_1000 VALUES LESS THAN ("2017-02-01", "1000"),
PARTITION p201702_2000 VALUES LESS THAN ("2017-03-01", "2000"),
PARTITION p201703_all VALUES LESS THAN ("2017-04-01")
)指定 `date`(DATE 类型) 和 `id`(INT 类型) 作为分区列。以上示例最终得到的分区如下:
p201701_1000: [(MIN_VALUE, MIN_VALUE), ("2017-02-01", "1000") )
p201702_2000: [("2017-02-01", "1000"), ("2017-03-01", "2000") )
p201703_all: [("2017-03-01", "2000"), ("2017-04-01", MIN_VALUE))
注意,最后一个分区用户缺省只指定了 `date` 列的分区值,所以 `id` 列的分区值会默认填充`MIN_VALUE`。当用户插入数据时,分区列值会按照顺序依次比较,最终得到对应的分区。举例如下:
数据 --> 分区
2017-01-01, 200 --> p201701_1000
2017-01-01, 2000 --> p201701_1000
2017-02-01, 100 --> p201701_1000
2017-02-01, 2000 --> p201702_2000
2017-02-15, 5000 --> p201702_2000
2017-03-01, 2000 --> p201703_all
2017-03-10, 1 --> p201703_all
2017-04-01, 1000 --> 无法导入
2017-05-01, 1000 --> 无法导入
判断分区逻辑如下:
首先我们对该逻辑进行一个总结,就是首先我们对我们的第一个分区的条件的第一个条件进行判断,如果符合就本划分到第一个分区,如果不符合就会和第二个条件进行对比,符合就还是会在第一个分区
就类似与这个
if(第一个分区第一个条件||第二个分区第二个条件……){
}else if(第二个分区第一个条件||第二个分区第一个条件……){
}……2)List 分区
PARTITION BY LIST(`id`, `city`)
(
PARTITION `p1_city` VALUES IN (("1", "Beijing"), ("1", "Shanghai")),
PARTITION `p2_city` VALUES IN (("2", "Beijing"), ("2", "Shanghai")),
PARTITION `p3_city` VALUES IN (("3", "Beijing"), ("3", "Shanghai"))
) 指定 `id`(INT 类型) 和 `city`(VARCHAR 类型) 作为分区列。最终得到的分区如下:
p1_city: [("1", "Beijing"), ("1", "Shanghai")]
p2_city: [("2", "Beijing"), ("2", "Shanghai")]
p3_city: [("3", "Beijing"), ("3", "Shanghai")]
当用户插入数据时,分区列值会按照顺序依次比较,最终得到对应的分区。举例如下:
数据 ---> 分区
1, Beijing ---> p1_city
1, Shanghai ---> p1_city
2, Shanghai ---> p2_city
3, Beijing ---> p3_city
1, Tianjin ---> 无法导入
4, Beijing ---> 无法导入
3.3.8 表属性(PROPERTIES)

每个tablet的副本数量,默认就是3,在建表语句中,所有的Partition中的Tablet副本数量统一指定的,在增加新的分区的时候,可以单独指定新分区中Tablet的副本数量。
副本数量可以运行时修改,官方建议保持奇数。
最大副本数却决于集群独立IP数量(不是BE的数量)Doris 中副本分布的原则是,不允许同一个 Tablet 的副本分布在同一台物理机上,而识别物理机即通过 IP。
ENGINE
本示例中,ENGINE 的类型是 olap,即默认的 ENGINE 类型。在 Doris 中,只有这个ENGINE 类型是由 Doris 负责数据管理和存储的。其他 ENGINE 类型,如 mysql、broker、es 等等,本质上只是对外部其他数据库或系统中的表的映射,以保证 Doris 可以读取这些数据。而 Doris 本身并不创建、管理和存储任何非 olap ENGINE 类型的表和数据。

一站式 AI 云服务平台
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)