
PGVECTOR【理论篇】01:什么是PGVECTOR【向量数据库】
什么是PGVECTOR【向量数据库】
一、向量数据库
1、向量数据库介绍
向量数据库(Vector Database)是一种专门为高维向量数据设计的高效存储与查询系统,核心目标是解决大规模非结构化数据(如图像、文本、音频、视频等)的相似性搜索、聚类分析和模式挖掘问题。
它是人工智能(尤其是机器学习)与数据库技术结合的产物,广泛应用于推荐系统、计算机视觉、自然语言处理(NLP)、药物研发等领域。
2、为什么需要向量数据库?
传统的关系型数据库(如MySQL、PostgreSQL)或NoSQL数据库(如MongoDB)主要存储结构化或半结构化数据(如表格、文档),并通过精确匹配(如SQL的WHERE条件)或简单范围查询(如时间戳、数值区间)完成任务。
但对于非结构化数据(如一张图片、一段文本),需先通过AI模型(如CNN、Transformer)将其转换为高维向量(Embedding),才能被计算机理解和处理。
传统数据库在处理这类向量数据时存在明显缺陷:
- 查询效率低:高维向量(如1024维、2048维)的相似性搜索(如“找最相似的10个向量”)若用暴力枚举,时间复杂度为O(N)(N为向量总数),无法应对亿级数据规模。
- 缺乏针对性优化:传统数据库的索引(如B树、哈希索引)无法高效处理高维向量的“近似最近邻”(ANN,Approximate
Nearest Neighbor)搜索需求。
3、向量数据库的核心能力
向量数据库针对高维向量的特性,设计了专门的存储和查询技术,核心能力包括:
(1)高效的相似性搜索
通过近似最近邻算法(如HNSW、IVF、PQ等),在百万到百亿级向量中快速找到与目标向量最相似的Top-K结果(如“找和这张图片最像的10张图”),查询延迟可低至毫秒级。
(2)支持多种相似度度量
根据业务需求,支持余弦相似度(Cosine Similarity)、欧氏距离(Euclidean Distance)、内积(Inner Product)等常见相似度计算方式。
(3)动态扩展与高可用
支持水平扩展(增加节点提升容量和性能),部分产品提供分布式架构、副本机制和自动故障转移,满足企业级高可用需求。
(4)与AI流程深度集成
支持直接导入AI模型生成的向量(如通过TensorFlow、PyTorch训练的Embedding模型),并与机器学习平台(如MLflow)、数据湖(如HDFS、S3)无缝对接。
4、向量数据库的关键技术
(1)向量存储结构
向量数据库需高效存储高维向量,常见存储方式包括:
原始向量存储:
直接存储向量数值(如float32数组),简单但占用空间大(1024维float32向量约占4KB)。
量化压缩:
通过量化算法(如乘积量化PQ、LSH)将高维向量压缩为低维整数,减少存储占用(如1024维向量压缩后仅需几百字节),同时尽量保留相似性信息。
(2)索引技术
索引是向量数据库的核心,决定了查询效率。常见索引算法包括:
倒排索引(Inverted Index):
将高维空间划分为多个“桶”,向量根据特征落入对应桶中,查询时仅搜索相关桶内的向量(适用于低维向量)。
层次化可导航小世界图(HNSW,Hierarchical Navigable Small World):
构建向量间的图结构,通过“跳表”思想快速跳转搜索,适合高维向量(如1024维),精度与效率平衡优秀(Milvus、Weaviate常用)。
倒排文件索引(IVF,Inverted File Index):
将向量聚类为多个簇(Cluster),查询时仅搜索目标向量所在簇及邻近簇内的向量(如FAISS库的核心思想)。
局部敏感哈希(LSH,Locality-Sensitive Hashing):
通过哈希函数将相似向量映射到同一桶中,大幅减少搜索范围(适用于实时性要求极高的场景)。
(3)分布式架构
为应对海量数据(十亿级向量),向量数据库通常采用分布式架构,支持:
分片(Sharding):
将数据按哈希或范围划分到不同节点。
副本(Replication):
每个分片的多副本存储,保证数据可靠性。
负载均衡:
动态调整数据分布,避免热点问题
5、典型应用场景
向量数据库的核心价值在于解决“非结构化数据的相似性搜索”问题,典型场景包括:
(1)推荐系统
将用户行为(点击、购买)和物品(商品、视频)转换为向量,通过相似性搜索推荐“用户可能喜欢的物品”(如“看过此电影的用户还看了哪些?”)。
(2)图像/视频检索
提取图像的特征向量(如通过ResNet模型),支持“以图搜图”(如找相似风格的服装、找监控中的相似车辆)。
(3)自然语言处理(NLP)
文本向量化(如通过BERT、GPT生成Embedding),支持“语义搜索”(如搜索“苹果”时,同时返回水果和手机的相关内容)。
(4)药物研发
分子结构向量化(如通过Graph Neural Network生成分子指纹),搜索“与目标化合物相似的候选分子”,加速新药发现。
(5)金融风控
用户行为、交易记录向量化,识别“异常交易模式”(如与历史欺诈交易高度相似的当前交易)。
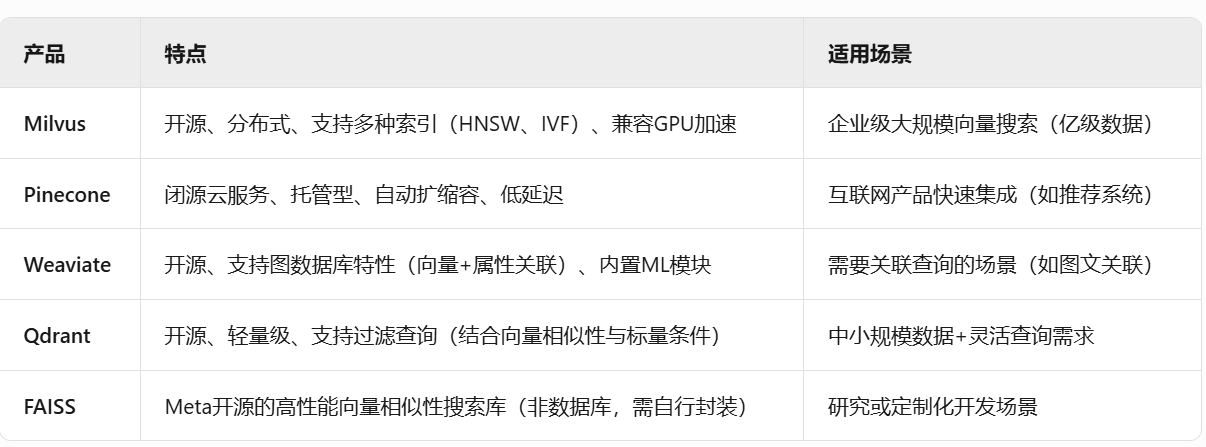
6、主流向量数据库产品
目前市场上有开源和商业两种类型的向量数据库,选择时需结合业务规模(数据量、QPS)、精度要求、部署复杂度等因素:
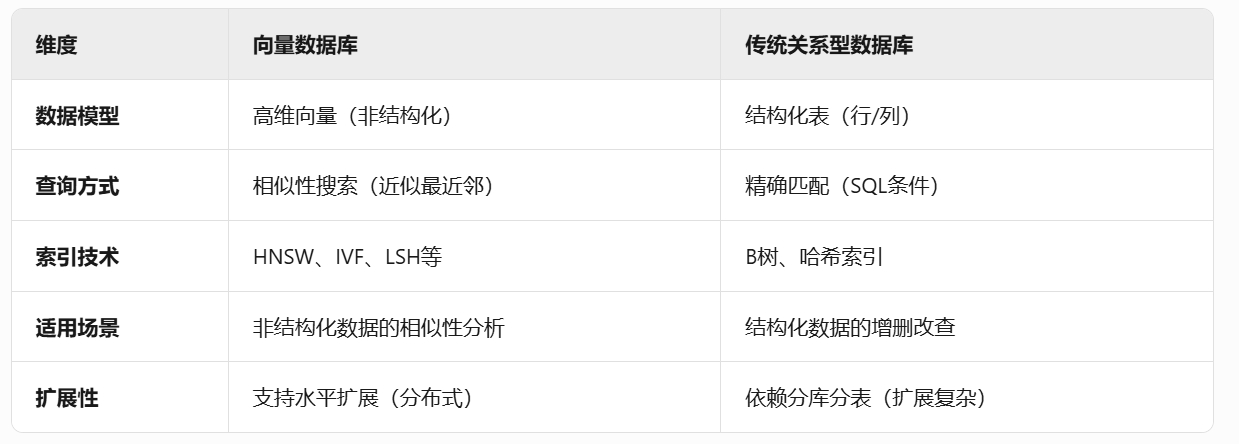
7、向量数据库 vs 传统数据库
8、总结
向量数据库是AI时代的关键基础设施,它通过优化高维向量的存储与查询效率,让机器学习模型能够更高效地处理非结构化数据。
随着AI应用的普及(如AIGC、多模态大模型),向量数据库的需求将持续增长,未来可能进一步融合事务支持、多模态数据(向量+文本/图像)等能力,成为企业数据架构的核心组件之一。
二、PGVECTOR介绍
1、PGBECTOR介绍
PGVECTOR 是 PostgreSQL 的一个官方扩展模块(2021年随 PostgreSQL 14 正式纳入 contrib 扩展库),专为高维向量数据的存储、索引和相似性搜索设计。
它将向量数据原生集成到 PostgreSQL 中,使用户无需脱离熟悉的 SQL 生态,即可高效处理非结构化数据(如图像、文本、音频的向量表示)。
2、PGVECTOR 的核心定位
PGVECTOR 的核心目标是将向量搜索能力与 PostgreSQL 的事务性、SQL 生态深度融合,解决以下问题:
- 传统关系型数据库(如 PostgreSQL)无法高效存储和查询高维向量。
- 专用向量数据库(如 Milvus、Pinecone)需要额外维护,且与现有 PostgreSQL 生态(如用户、权限、业务逻辑)割裂。
3、PGVECTOR 的核心功能
(1)向量数据类型支持
PGVECTOR 定义了一种新的数据类型 vector,用于存储固定维度的高维向量(如 128 维、768 维)。支持 float32(单精度浮点数)和 float64(双精度浮点数)两种数值类型。
-- 创建表时定义 vector 列(维度 768,常见于 BERT 等模型)
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(768) -- 存储 768 维的 float32 向量
);
(2)相似性搜索
PGVECTOR 支持基于余弦相似度(默认)或欧氏距离的相似性查询,通过 <= 操作符或 SIMILARITY 函数实现。
-- 查询与目标向量最相似的前 10 条记录(余弦相似度)
SELECT id, content, embedding
FROM documents
ORDER BY embedding <-> '0.1,0.2,...,0.768'::vector -- <-> 是相似性排序操作符
LIMIT 10;
-- 计算两条向量的余弦相似度(范围 [-1, 1],越接近 1 越相似)
SELECT SIMILARITY(embedding1, embedding2);
-- 计算欧氏距离(需显式指定)
SELECT ||embedding1 - embedding2||; -- 欧氏距离(L2 范数)
(3)高效索引支持
PGVECTOR 提供多种索引类型,优化不同场景下的查询性能:
索引创建示例:
-- 为 embedding 列创建 IVFFlat 索引(nlist=100 表示聚类为 100 个桶)
CREATE INDEX idx_documents_embedding_ivfflat
ON documents USING ivfflat (embedding vector_l2_ops) -- vector_l2_ops 表示使用 L2 距离
WITH (lists = 100); -- 聚类桶数量
-- 为 embedding 列创建 HNSW 索引(m=16 表示每个节点连接 16 个邻居)
CREATE INDEX idx_documents_embedding_hnsw
ON documents USING hnsw (embedding vector_cosine_ops) -- vector_cosine_ops 表示使用余弦相似度
WITH (m = 16, ef_construction = 200); -- 构建时的扩展因子
(4)与机器学习集成
PGVECTOR 天然支持与 PostgreSQL 的机器学习扩展(如 pg_trgm、tsearch2)或其他工具链(如 Python 的 psycopg2、sqlalchemy)结合,方便将 AI 模型生成的向量直接写入数据库。
典型流程:
- 用 Python(如 PyTorch、TensorFlow)将文本/图像转换为向量。
- 通过 psycopg2 将向量插入 PostgreSQL 表的 vector 列。
- 直接在 SQL 中执行相似性查询,结果返回给业务系统。
4、PGVECTOR 的核心优势
(1)与 PostgreSQL 生态深度整合
(a)事务支持
向量数据与普通关系型数据共享同一事务,支持 ACID 特性(如插入向量时同时更新元数据)。
(b)SQL 生态
可直接使用 PostgreSQL 的 SQL 功能(如 JOIN、WHERE、聚合函数)结合向量查询。
(c)权限管理
复用 PostgreSQL 的用户权限体系(如通过 GRANT 控制向量表的读写权限)。
(2)降低技术栈复杂度
企业无需维护额外的向量数据库服务(如 Milvus 集群),只需基于现有的 PostgreSQL 基础设施(备份、监控、高可用)即可支持向量搜索,大幅降低运维成本。
(3)适合混合负载场景
PGVECTOR 支持“事务性操作 + 向量搜索”的混合负载(如用户下单时同时查询相似商品),而专用向量数据库通常仅支持查询,需额外对接关系型数据库处理事务。
5、PGVECTOR 的局限性
(1)性能上限
在高并发(万 QPS 以上)或超大规模数据(百亿级向量)场景下,性能可能弱于专用向量数据库(如 Milvus 的分布式架构)。
(2)索引类型有限
目前支持的索引类型(IVFFlat、HNSW 等)虽覆盖主流需求,但定制化能力不如专用数据库。
(3)存储效率
向量数据以原始浮点数存储(未压缩),存储占用较高(1024 维 float32 向量约 4KB/条),需结合分区、归档优化。
6、五、典型应用场景
PGVECTOR 适合需要事务支持、且向量数据规模适中(百万到亿级)的场景:
(1)推荐系统:
用户画像向量与商品向量关联查询(如“根据用户历史行为推荐相似商品”)。
(2)文档检索:
将 PDF/文章转换为向量,支持“语义搜索”(如搜索“机器学习”时返回相关文档)。
(3)图像/视频管理:
提取图像特征向量,实现“以图搜图”(如找相似风格的服装图片)。
(4)知识图谱:
实体嵌入向量与图结构关联,支持“相似实体推荐”(如“与‘爱因斯坦’相关的科学家”)。
7、总结
PGVECTOR 是 PostgreSQL 生态中原生支持向量搜索的扩展,适合需要事务性、SQL 集成和轻量级部署的场景。
对于已有 PostgreSQL 基础设施的企业,PGVECTOR 能快速扩展非结构化数据处理能力,避免引入额外技术栈的复杂度。
对于超大规模数据或高并发场景,可结合专用向量数据库(如 Milvus)作为补充,通过 ETL 同步数据。

一站式 AI 云服务平台
更多推荐



 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)