
oracle 强制走索引_数据库索引:成也索引,败也索引(萧何:喵喵喵)下
通过前面的介绍,我们知道了,查询数据的时候,即可以直接在主键索引上进行全表扫描,也可以走非主键索引,扫描后再到主键索引上回表查出最终数据。那么数据库是怎么确定要走哪种方案呢,在日常使用中,是不是也经常被MySQL误走索引而坑过呢。首先我们先准备一个测试数据吧。我们先建一张简单的表,表里有id, x, y三个字段,并给x和y添加索引create table t (id bigint...

通过前面的介绍,我们知道了,查询数据的时候,即可以直接在主键索引上进行全表扫描,也可以走非主键索引,扫描后再到主键索引上回表查出最终数据。那么数据库是怎么确定要走哪种方案呢,在日常使用中,是不是也经常被MySQL误走索引而坑过呢。
首先我们先准备一个测试数据吧。
我们先建一张简单的表,表里有id, x, y三个字段,并给x和y添加索引
create table t ( id bigint(20) not null PRIMARY key, x int, y INT, key x (x), key y (y));接着我们创建一个简单的过程,进行数据插入,我们这里插入10w条测试数据,为了防止优化器作祟,我们对值做随机数处理。
delimiter ;;create procedure mock_data()begin declare i int; set i=1; while(i<=100000)do insert into t(id, x, y) values(i, FLOOR(1 + (RAND() * 100000)), FLOOR(1 + (RAND() * 100000))); set i=i+1; end while;end;;delimiter ;最后,执行这个过程,去喝杯咖啡。
call mock_data()模拟数据插入完成后,我们简单执行个sql看一下x列的选择性如何:
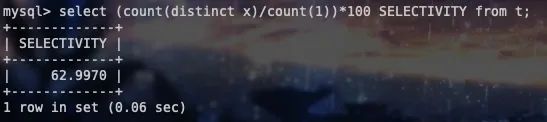
可以看到选择性达到了63%,大于20%,按经验值是可以,也应该建索引的。
然后,我们来分析一条非常简单的sql语句:
select id, x, y from t where x between 20000 and 30000;直觉告诉你:这还用分析么,铁定走索引啊!然而...

对,你没看错,MySQL选择了全表扫描。
于是我们再稍微地改一下sql条件:
select id, x, y from t where x between 20000 and 29000;
这一次,奇迹般地走了索引!

这也太随意了吧,难道MySQL是“猜拳”决定要不要走索引的么。
数据库的执行代价
那么数据库是如何评估是否要走索引呢?其实,数据库处理这件事情也很简单,数据库在查询数据之前,会先评估可能的方案的执行成本(cost),最后,哪种成本低就用哪种。就好比你上街买菜,张阿姨的菜摊5毛/斤,王婶的6毛/斤,那就选张阿姨的。不过这里可不是正儿八经地把每种方案都执行一遍来进行比较,而是一种估算。
既然要进行估计,那就得有估计的量化指标,也就是上面说的成本,这里的成本,主要包括IO成本和CPU成本:
-
IO成本:将数据从磁盘上加载到内存的成本。在MySQL里,一般读取一个页的成本定义为1
-
CPU成本:对数据进行筛选、过滤、排序等操作的CPU成本,一般检测记录成本定义为0.2
基于此,假如是全表扫描:
-
主键索引占用的页面数,用来计算IO成本,其中一个页面是16k
-
表中的记录数,用来计算搜索的成本
我们知道,MySQL InnoDB引擎的记录数是没有实时统计的。那么每次估计成本都要去跑一次sql查询总记录数么?这个代价就太大了,所以MySQL维护了一个表的粗略统计信息。
show table status like 't'\G;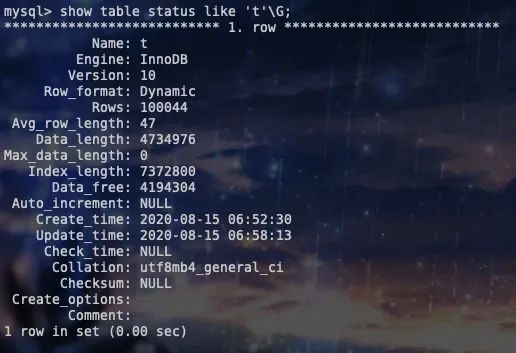
通过这个查询我们可以看到,表的行数(Rows),大小(Data_length),等信息,可是我们发现,这个总行数跟我们实际行数是有出入的,我们实际行数其实只有10w, 而这个rows多了44行,这也就是我们所谓的粗略的信息,这里并不是做实时的精确统计。BTW,这也是解决分页时count(*)非常慢的其中一种解决方案。
虽然不是精确的统计信息,但是用来做成本估计,其实是够用的了。我们套用上面的成本系数来计算:
-
IO: 4734976 ÷ (16 x 1024) = 289
-
CPU: 100044 x 0.2 ≈ 20009
-
总计:20009 + 289 = 20298
所以全表扫描成本大约在20298左右。
所以,MySQL选择执行计划其实是根据这样的一个个量化后的标准来选择走什么样的执行计划,还是相对比较客观的。但是,这个估算是强依赖于统计信息的,有时候因为大量的增删,会导致统计信息不准确,这个时候就会导致MySQL走错索引。这时可以有两种解决方式:
第一种:既然是统计信息不对,那就修正。analyze table [table_name] 命令,可以用来重新统计索引信息。
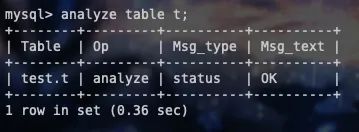
所以在实践中,如果你发现 explain 的结果预估的 rows 值跟实际情况差距比较大,可以采用这个方法来处理。
第二种:简单粗暴地给sql语句加强制索引FORCE INDEX(index_name)

加上force index后,我们看到执行计划就走了索引了。对于ORACLE可以用/*+index(t idx_name)*/这个HINT来进行强制索引如:
select /*+index(t x) */ * from t where x between 20000 and 30000;optimizer trace
最后,我们来介绍一下MySQL5.6之后新增的optimizer trace功能,可以用来查看执行计划的整个过程。有了这个功能,我们不仅可以了解优化器的选择过程,更可以了解每一个执行环节的成本。具体的文档可以参看官方文档。
如下语句打开 optimizer_trace 后,再执行 SQL 就可以查询 information_schema.OPTIMIZER_TRACE 表查看执行计划了,最后可以关闭 optimizer_trace。用完记得关闭,特别在线上环境使用,这玩意会损耗部分性能。
SET optimizer_trace="enabled=on";select x, y from t where x BETWEEN 20000 and 30000;SELECT * FROM information_schema.OPTIMIZER_TRACE;SET optimizer_trace="enabled=off";我们在trace字段里,可以拿到一串很长的JSON描述,我们截取部分来看一下:
"range_analysis": { "table_scan": { "rows": 100044, "cost": 20300 }, ....这里全表扫描成本提示是20300,跟我们上文计算出来的20298是非常相近的。
我们再来看索引的情况:
{ "index": "x", "ranges": [ "20000 <= x <= 30000" ], "index_dives_for_eq_ranges": true, "rowid_ordered": false, "using_mrr": false, "index_only": false, "rows": 17562, "cost": 21075, "chosen": false, "cause": "cost"}可以发现,走索引的成本是21075,要比全表扫描的成本来得更高,所以最终结论,是走全表扫描。
"best_access_path": { "considered_access_paths": [ { "rows_to_scan": 100044, "access_type": "scan", "resulting_rows": 100044, "cost": 20298, "chosen": true } ]}通过这个小工具,我们就能对数据库怎么决策执行计划的过程了如指掌了。

一站式 AI 云服务平台
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)