
解锁时序数据库选型密码,为何国产开源时序数据库IoTDB脱颖而出?
《时序数据库选型指南:从IoTDB看未来数据管理趋势》 本文全面剖析了时序数据库的核心特性与应用场景。随着物联网和大数据技术的普及,时序数据库凭借高效写入、压缩存储和快速查询能力,在工业监控、金融分析等领域展现出独特价值。文章重点介绍了国产开源时序数据库IoTDB的四大优势:树状数据模型与工业场景高度契合、自研TsFile格式实现超高压缩比、强大的乱序数据处理能力,以及轻量化的边云协同设计。通过上
摘要:本文系统梳理 IoTDB 的缘起、优势、核心功能与生态,指导如何根据业务需求(写入频率、存储规模、实时性等)做选型;并给出 Windows 单机安装、建库插数、查询三步走示例,附上海电气、蓝箭航天、德国铁路三大落地案例,助力快速落地时序数据平台。
目录
1.时序数据库引言
(一)IoTDB是什么
Apache IoTDB是一个开源物联网原生数据库,旨在满足大规模物联网和工业物联网(IoT和IIoT)应用对数据、存储和分析的严苛要求。该项目最早是由清华大学大数据系统软件团队研发,并于2018年11月进入捐赠给Apache,进行了为期1年10个月的孵化。孵化过程中,得到了4位项目导师的精心指导和来自全球78位贡献者、251名成员的5124封邮件,合并了1413个PR,发布了9个版本,以17票支持一次通过社区投票。2020年9月16日,经Apache董事会表决,Apache IoTDB正式晋升为顶级项目。
IoTDB 全称 Apache IoTDB,是一个分布式、高压缩、低延迟的时序数据库。它把“设备-测点-时间”抽象成树形路径(如 root.factory.line1.sensor1.temperature),底层用 TsFile 列式存储,支持 SQL、流计算、AI 推理节点,既能跑在树莓派,也能跑在千节点集群。
(二)为什么使用IoTDB
IoT 场景的典型痛点:
• 写入:百万设备、1 kHz 采样,峰值每秒数十亿点。
• 存储:原始数据 1 PB,存三年要 30 PB。
• 查询:既要秒级查看最新值,也要离线分析三年趋势。
传统关系库/通用 NoSQL 会写爆、查慢、成本高。IoTDB 通过“时间分区+列式编码+双层索引”把磁盘省 90%,通过“乱序数据合并+内存表+异步刷盘”把写入撑到千万点/秒,再用“时间索引+布隆过滤器”把点查降到毫秒级。

(三)IoTDB背景
在大数据时代的浪潮下,数据如汹涌的洪流般不断涌现,而时序数据库作为处理时间序列数据的关键利器,正逐渐崭露头角,成为众多领域不可或缺的重要工具。
时间序列数据,简单来说,就是按照时间顺序排列的数据点序列,每一个数据点都带有时间戳以及与之相关的数值或事件。这些数据广泛存在于我们生活的方方面面,如物联网设备产生的传感器数据、金融市场中的交易数据、系统监控的日志信息等 。随着物联网、人工智能、大数据分析等技术的飞速发展,时间序列数据的规模呈指数级增长,传统的数据库系统在处理这类数据时往往显得力不从心,时序数据库便应运而生。
时序数据库专为时间序列数据而生,具有一系列独特的特性,使其在处理这类数据时展现出卓越的性能和优势。它支持时间序列数据的高效写入,能够在短时间内处理大量数据写入操作。许多时序数据库采用批量写入、内存缓存和异步处理等技术,大大提高了数据写入效率,就像 Prometheus 使用内存缓存和分片技术,将数据写入效率最大化。其在存储方面,针对时间序列数据的高冗余性,采用专门的压缩算法和存储格式,大幅降低了存储空间需求。Gorilla 和 Facebook 的时序数据库采用的高效压缩算法,使得数据存储更加经济。同时,时序数据库支持复杂的时间范围查询和聚合操作,通过优化的索引机制和查询处理方法,能够在大规模数据集中快速检索所需信息,InfluxDB 使用特殊的索引结构,能够快速响应查询请求。
正是这些特性,让时序数据库在众多领域得到了广泛的应用。在物联网领域,大量的传感器设备持续不断地产生海量的时间序列数据,如温度、湿度、压力等环境参数,以及设备的运行状态信息。时序数据库能够高效地存储和处理这些数据,支持实时查询和分析,为实现远程监控、故障预警等功能提供了有力支持。比如,智能家居系统通过时序数据库来监控和管理家庭设备的状态和性能,让我们的生活更加便捷和舒适。在智能工厂中,通过对生产设备的各项参数进行实时监测和分析,可以及时发现设备故障隐患,提前进行维护,避免生产中断,提高生产效率和产品质量。
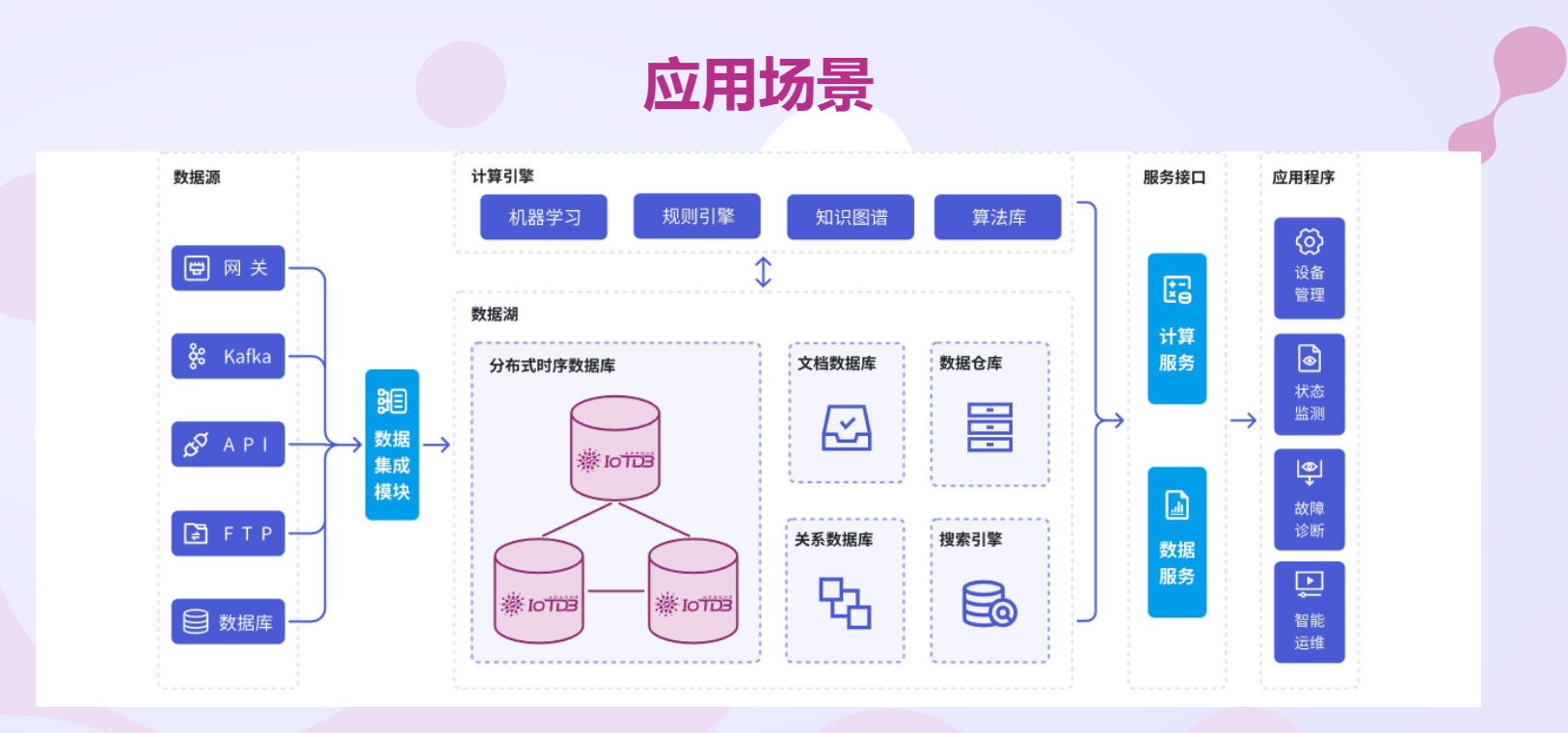
金融领域也是时序数据库的重要应用场景之一。股票价格、交易量、利率等金融数据都是典型的时间序列数据,对这些数据的分析和挖掘能够帮助投资者发现市场趋势,制定合理的投资策略,进行风险管理。金融机构利用时序数据库存储和分析实时交易数据,能够快速做出决策,抓住投资机会,降低风险。通过对历史股票价格数据的分析,可以预测股票价格的走势,为投资者提供参考依据;对交易数据的实时监控,可以及时发现异常交易行为,防范金融风险。
在系统监控和日志分析方面,时序数据库同样发挥着重要作用。它可以用于存储和查询系统性能数据、操作日志等时间序列数据,通过分析这些数据,能够及时发现系统问题,优化系统性能,提高系统的稳定性和可靠性。对于服务器的 CPU 使用率、内存占用率、网络流量等性能指标进行实时监测和分析,当发现某项指标异常时,及时发出警报,通知管理员进行处理,从而保障系统的正常运行。
2.选型前的自我审视:明确你的需求
(一)业务场景剖析
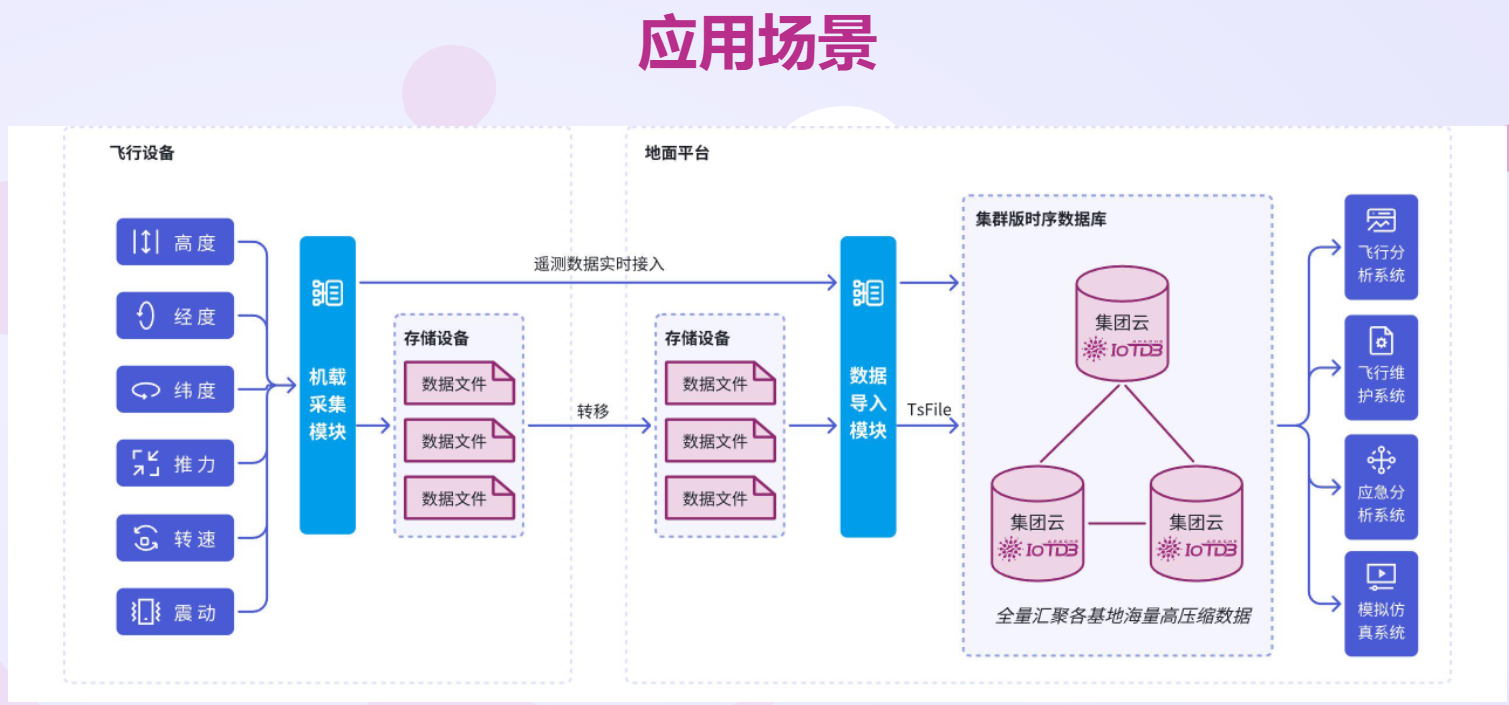
不同的业务场景对时序数据库有着截然不同的需求,这就好比不同的车型适用于不同的路况和驾驶需求。在物联网场景中,大量的传感器设备持续不断地产生海量数据,如智能工厂中的设备运行状态监测、智能家居中的环境参数采集等。这些场景对时序数据库的写入性能要求极高,需要能够支持高并发写入,确保数据不丢失,并且能够高效地管理和组织设备相关的数据。
以智能工厂为例,工厂内的各种生产设备,如机床、机器人等,会实时产生大量的运行数据,包括温度、压力、转速等。这些数据需要被及时、准确地写入到时序数据库中,以便进行实时监控和分析。一旦设备出现异常,系统能够迅速根据数据库中的数据发出警报,通知工作人员进行处理,从而避免生产事故的发生。因此,在物联网场景下,时序数据库需要具备高并发写入能力、高效的设备管理功能以及实时查询和分析能力。
在金融领域,股票交易数据、汇率数据等都是典型的时间序列数据。金融机构需要对这些数据进行实时监控和分析,以便及时做出投资决策。金融场景对数据的实时性和准确性要求极高,同时需要支持复杂的查询和分析功能,如计算移动平均线、分析市场趋势等。在股票交易中,投资者需要实时了解股票价格的变化情况,以及各种技术指标的计算结果,以便及时买入或卖出股票。因此,金融场景下的时序数据库需要具备高实时性、高精度的查询和分析能力,以及强大的数据处理和计算能力。
在系统监控场景中,服务器的性能指标、网络流量等数据需要被持续监测和记录。系统管理员需要通过对这些数据的分析,及时发现系统中的潜在问题,优化系统性能。系统监控场景对数据的存储和查询效率要求较高,同时需要支持数据的长期存储和历史数据分析。对于服务器的 CPU 使用率、内存占用率等性能指标,系统管理员需要能够随时查询历史数据,分析其变化趋势,以便及时调整系统配置,提高系统的稳定性和可靠性。
(二)关键指标考量
- 数据写入频率:数据写入频率是衡量时序数据库性能的重要指标之一。在一些物联网场景中,传感器可能每秒甚至每毫秒就会产生一次数据,这种高频次的数据写入对数据库的写入性能提出了极高的要求。如果数据库无法承受如此高的写入压力,就会导致数据丢失或写入延迟,影响系统的正常运行。因此,在选型时,需要确保所选的时序数据库能够支持业务场景所需的写入频率,具备高效的写入机制,如批量写入、异步写入等,以提高写入性能。
- 存储规模:随着时间的推移,时序数据的规模会不断增长。在工业物联网中,大量设备产生的数据可能在短时间内就会达到数 TB 甚至数 PB 的规模。因此,时序数据库需要具备良好的扩展性,能够支持大规模的数据存储。一些数据库采用分布式存储架构,通过增加节点来扩展存储容量,能够有效地应对数据规模的增长。同时,数据库还需要具备高效的压缩算法,以降低数据存储成本,提高存储效率。
- 查询复杂度:不同的业务场景对查询的复杂度要求也不同。简单的查询可能只需要获取某个时间范围内的数据,而复杂的查询可能涉及多个时间序列的关联分析、聚合计算等。在金融风险评估中,可能需要对多个金融指标进行复杂的计算和分析,以评估风险水平。因此,在选型时,需要根据业务需求选择能够支持相应查询复杂度的时序数据库,确保其具备强大的查询和分析能力,能够快速、准确地返回查询结果。
- 实时性要求:对于一些实时性要求较高的应用场景,如实时监控、交易系统等,数据的处理和查询需要在极短的时间内完成。在电力系统的实时监控中,一旦发现电网故障,需要立即根据采集到的数据进行分析和处理,以保障电力系统的安全稳定运行。因此,在这些场景下,需要选择能够提供低延迟查询和实时数据处理能力的时序数据库,确保系统能够及时响应业务需求。
3.核心功能大揭秘:衡量数据库的硬实力
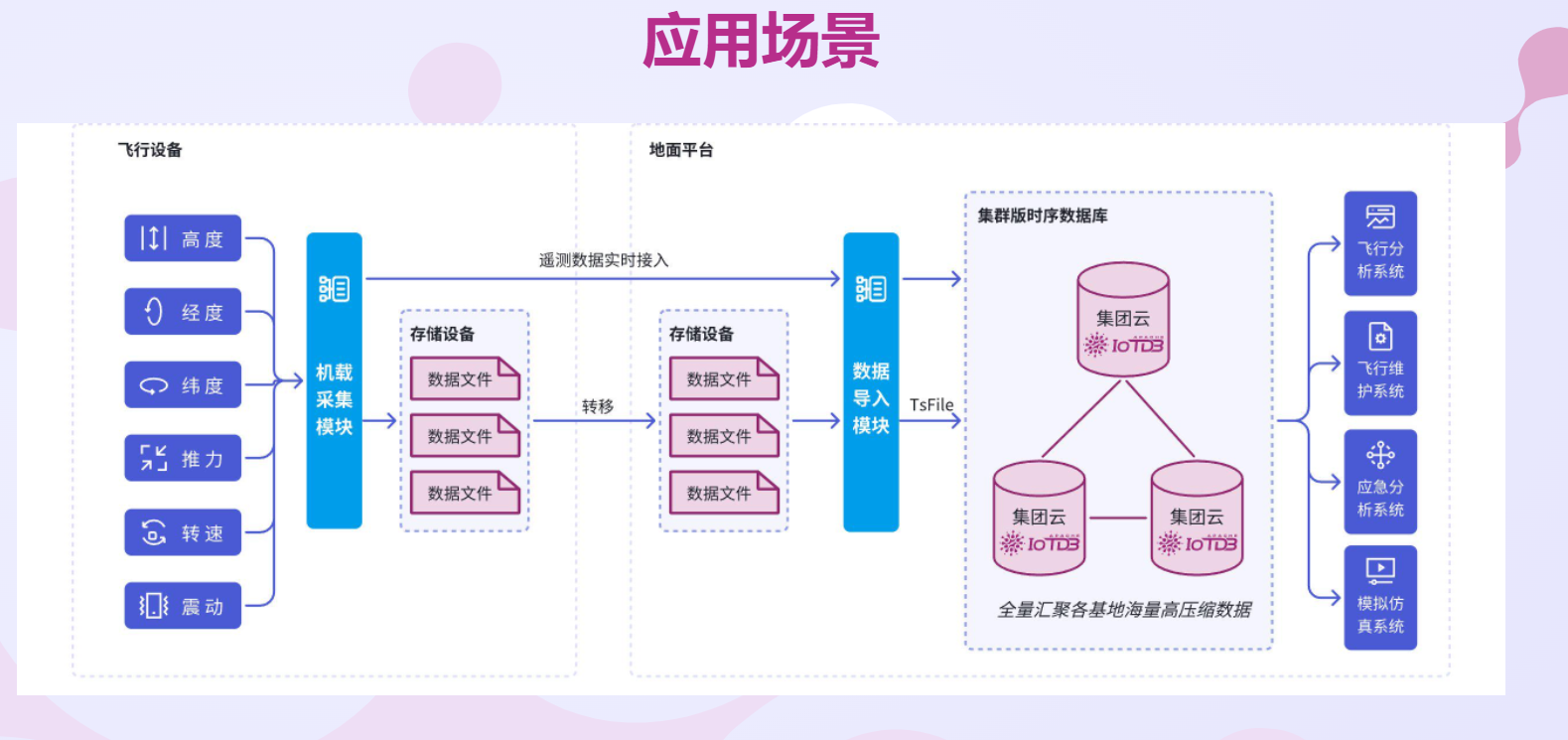
(一)写入性能
对于时序数据库而言,高吞吐量写入是其立足的根本。在物联网、工业监控等场景中,大量设备会持续不断地产生海量数据,这就要求时序数据库具备强大的写入能力,能够快速、稳定地将这些数据写入到数据库中,确保数据的完整性和及时性。如果写入性能不足,数据就会出现积压,导致实时性降低,甚至可能出现数据丢失的情况,严重影响业务的正常运行。
CREATE DATABASE power;
INSERT INTO root.power.Station001.Battery01(timestamp,voltage,current)
VALUES(now(), 3.67, 120.5);不同的时序数据库在写入性能上表现各异。一些数据库采用了优化的写入算法和存储结构,能够显著提高写入速度。例如,InfluxDB 通过使用基于时间序列的索引结构和批量写入机制,能够高效地处理大量的写入请求,大大提高了写入性能 。它将数据按时间序列进行分组存储,使得写入操作可以批量进行,减少了磁盘 I/O 的次数,从而提高了写入效率。而 Prometheus 则采用了内存缓存和分片技术,将数据先缓存在内存中,然后再异步写入磁盘,进一步提高了写入性能。在大规模监控场景中,Prometheus 能够轻松应对每秒数千个时间序列的写入请求,确保数据的实时采集和存储。
(二)数据压缩
随着时间序列数据量的不断增长,存储成本也成为了一个重要的问题。高效的压缩算法可以有效地降低存储成本,提高存储效率。数据压缩不仅可以节省硬件资源,还可以减少数据传输的带宽需求,提高系统的整体性能。
常见的压缩算法包括差分编码、霍夫曼编码、游程编码等。差分编码通过计算相邻数据点之间的差值来减少数据的冗余,从而实现数据压缩。霍夫曼编码则根据数据的出现频率为不同的数据分配不同长度的编码,出现频率高的数据使用较短的编码,出现频率低的数据使用较长的编码,以此来达到压缩的目的。游程编码则是对连续重复的数据进行编码,用一个计数值和一个数据值来表示连续重复的数据,从而减少数据的存储空间。
不同的压缩算法在压缩比和压缩速度上有所不同。例如,霍夫曼编码在压缩比上表现较好,但压缩速度相对较慢;而游程编码则在压缩速度上具有优势,但压缩比相对较低。在实际应用中,需要根据业务需求和数据特点选择合适的压缩算法,以达到最佳的压缩效果。
伪代码案例:
from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType
from iotdb.utils.Tablet import Tablet
ip = "127.0.0.1"
port = "6667"
username = "root"
password = "root"
session = Session(ip, port, username, password)
session.open(False)
measurements = ["s_01", "s_02", "s_03", "s_04", "s_05", "s_06"]
data_types = [
TSDataType.BOOLEAN,
TSDataType.INT32,
TSDataType.INT64,
TSDataType.FLOAT,
TSDataType.DOUBLE,
TSDataType.TEXT,
]
values = [
[False, 10, 11, 1.1, 10011.1, "test01"],
[True, 100, 11111, 1.25, 101.0, "test02"],
[False, 100, 1, 188.1, 688.25, "test03"],
[True, 0, 0, 0, 6.25, "test04"],
]
timestamps = [1, 2, 3, 4]
tablet = Tablet(
"root.db.d_03", measurements, data_types, values, timestamps
)
session.insert_tablet(tablet)
with session.execute_statement(
"select ** from root.db"
) as session_data_set:
while session_data_set.has_next():
print(session_data_set.next())
session.close()(三)查询性能
在时序数据库中,高效的查询性能是实现数据分析和决策支持的关键。时间范围查询、聚合操作和降采样是时序数据查询中常见的操作,它们能够帮助用户快速获取所需的数据,并对数据进行分析和处理。
SELECT last voltage FROM root.power.Station001.Battery01;时间范围查询允许用户根据时间戳来查询特定时间段内的数据,这对于分析数据的趋势和变化非常重要。聚合操作则可以对数据进行统计分析,如计算平均值、最大值、最小值等,帮助用户了解数据的整体特征。降采样则是将高频率的数据转换为低频率的数据,以减少数据量,提高查询效率,同时也可以用于分析数据的长期趋势。
为了实现高效的查询性能,时序数据库通常会采用索引优化和并行查询等技术。索引可以加快数据的查找速度,减少查询时间;并行查询则可以利用多核处理器的优势,同时处理多个查询任务,提高查询效率。一些时序数据库还支持分布式查询,能够在多个节点上并行执行查询操作,进一步提高查询性能。
(四)分布式支持
在大规模数据场景中,分布式架构是时序数据库的必然选择。分布式架构可以将数据分散存储在多个节点上,通过节点之间的协作来实现数据的存储和处理,从而提高系统的扩展性、容错性和性能。
分布式架构的优势主要体现在以下几个方面:一是可以通过增加节点来扩展系统的存储和处理能力,以应对不断增长的数据量和业务需求;二是具备高容错性,当某个节点出现故障时,系统可以自动将任务转移到其他节点上,确保业务的连续性;三是能够提高系统的性能,通过并行处理和负载均衡,将任务均匀分配到各个节点上,提高系统的处理效率。
SELECT AVG(voltage)
FROM root.power.Station001.Battery01
GROUP BY([2024-07-17 00:00:00, 2024-07-18 00:00:00), 1h);以 Apache IoTDB 为例,它采用了分布式架构,支持水平扩展和高可用性。通过将数据分片存储在多个节点上,并使用一致性哈希算法来实现数据的负载均衡,IoTDB 能够有效地处理大规模的时间序列数据。在物联网场景中,IoTDB 可以轻松应对数百万个设备的数据存储和查询需求,为物联网应用提供了强大的支持。
(五)数据生命周期管理
数据生命周期管理是时序数据库中一个重要的功能,它包括自动数据过期和冷热数据分层存储等。自动数据过期可以根据用户设定的规则,自动删除过期的数据,以释放存储空间,降低存储成本。冷热数据分层存储则是根据数据的访问频率和重要性,将数据分为热数据、温数据和冷数据,并分别存储在不同的存储介质上,以提高存储效率和查询性能。
热数据通常是最近产生的数据,访问频率较高,需要存储在高性能的存储介质上,如内存或固态硬盘,以确保快速的查询响应。温数据的访问频率较低,可以存储在性能适中的存储介质上,如普通硬盘。冷数据则是长时间未被访问的数据,访问频率极低,可以存储在低成本的存储介质上,如磁带库,以节省存储成本。
通过合理的数据生命周期管理,时序数据库可以有效地管理数据的存储和访问,提高系统的性能和效率,同时降低存储成本。
Apache IoTDB_国产开源时序数据库_时序数据管理服务商-天谋科技Timecho天谋科技Timecho提供行业领先的物联网时序数据库管理系统及服务,是专业的时序数据管理服务商,致力于围绕物联网原生的Apache IoTDB,以高吞吐,高压缩,高可用的开源时序数据库-国产数据库IoTDB,为工业用户解决数据"存,查,用"难题![]() https://timecho.com/发行版本 | IoTDB Website发行版本 历史版本下载:https://archive.apache.org/dist/iotdb/ 环境配置 推荐修改的操作系统参数 将 somaxconn 设置为 65535 以避免系统在高负载时出现
https://timecho.com/发行版本 | IoTDB Website发行版本 历史版本下载:https://archive.apache.org/dist/iotdb/ 环境配置 推荐修改的操作系统参数 将 somaxconn 设置为 65535 以避免系统在高负载时出现 ![]() https://iotdb.apache.org/zh/Download/
https://iotdb.apache.org/zh/Download/

一站式 AI 云服务平台
更多推荐



 95
95 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)