
TimescaleDB【理论篇】01:什么是TimescaleDB【时序数据库】
什么是TimescaleDB【时序数据库】
一、时序数据库
时序数据库(Time Series Database, TSDB)是专门为时序数据(按时间顺序记录的数据点)设计的高效存储与查询数据库。
它针对时序数据的高写入频率、时间相关性、时间范围查询频繁等特点进行了优化,广泛应用于物联网(IoT)、工业监控、DevOps监控、金融行情、气象数据等领域。
1、时序数据的特点
时序数据是按时间戳顺序生成的结构化数据,典型特征包括:
(1)时间戳是核心属性
每条数据都包含精确的时间戳(如2024-03-10 12:00:00),时间维度是分析和查询的关键。
(2)流式写入
数据通常以高频、连续的方式写入(如传感器每秒产生一条数据),写入压力大。
(3)时间相关性
数据价值随时间衰减(如仅保留最近30天的监控数据),旧数据很少被访问。
(4)高冗余性
相邻时间点的数据可能高度相似(如温度传感器连续几分钟数值稳定),存在压缩空间。
(5)查询模式固定
主要查询基于时间范围(如“最近1小时的CPU使用率”)或时间聚合(如“今日平均温度”)。
2、时序数据库的核心优势
与传统关系型数据库(如MySQL)或通用NoSQL数据库相比,时序数据库针对时序数据特性做了深度优化:
(1)高写入性能
支持批量写入、内存缓冲、异步刷盘等机制,轻松应对每秒数十万甚至百万级的数据写入(如物联网设备的海量数据)。
(2)高效时间范围查询
通过时间分区(如按天/小时划分数据块)、时间索引(B树或跳表)等设计,快速定位时间范围内的数据,避免全表扫描。
(3)空间压缩优化
利用时序数据的冗余性(如连续相同值、缓慢变化趋势),采用列式存储+压缩算法(如LZ4、Snappy),大幅降低存储成本(通常比行式数据库节省50%-90%空间)。
(4)自动过期与清理
支持TTL(Time To Live)策略,自动删除过期数据(如保留最近30天数据),避免存储资源浪费。
(5)内置聚合计算
预计算并存储聚合结果(如每小时平均值、最大值),加速长时间范围的统计查询(无需实时计算原始数据)。
3、典型应用场景
时序数据库适用于所有需要按时间维度处理高频数据的场景:
(1)物联网(IoT)
传感器数据(温度、湿度、压力等)的实时采集与分析。
(2)工业监控
设备运行状态(转速、能耗、振动)的实时监测与故障预警。
(3)DevOps与APM
服务器/应用的性能指标(CPU、内存、请求延迟)监控,结合Grafana可视化。
(4)金融与交易
股票/期货的实时行情数据、交易流水的时间序列分析。
(5)气象与环境
气象站的温度、降水、风速等数据的长期存储与趋势预测。
4、主流时序数据库产品
目前市场上有开源、商业、云服务等多种类型的时序数据库,选择时需结合数据量、查询复杂度、部署环境等因素:
(1)开源时序数据库
(a)InfluxDB
最流行的开源时序数据库之一,支持高并发写入、时间分区、连续查询(预聚合),社区版(免费)和企业版(支持分布式、高级安全)。缺点是不支持SQL(需使用类SQL语法),分布式版本需付费。
(b)TimescaleDB
基于PostgreSQL扩展的时序数据库,兼容SQL语法,支持事务和复杂查询(如JOIN),适合需要关系型数据库特性的场景(如业务系统与监控数据关联)。通过“超表”(Hypertable)自动管理时间分区,扩展性强。
(c)Prometheus
专为云原生设计的监控数据库,与Grafana深度集成,支持时间序列数据的采集、存储与告警。采用拉模式(Pull)获取数据,适合容器化环境(如Kubernetes),但持久化存储依赖外部系统(如Thanos、Cortex)。
(d)OpenTSDB
基于HBase的分布式时序数据库,适合大规模数据场景(百亿级数据点),支持高可用和水平扩展,但对HBase依赖较强,部署复杂度较高。
(2)商业/云服务
(a)AWS Timestream
AWS托管的时序数据库,支持PB级数据存储,自动扩展,兼容SQL查询,适合AWS生态用户(如EC2、Lambda)。
(b)阿里云TSDB
阿里云提供的时序数据库服务,支持高并发写入、秒级查询,集成MaxCompute(离线分析)和Grafana可视化,适合国内企业。
(d)InfluxCloud
InfluxDB的托管服务,提供自动备份、多区域部署等企业级功能。
5、使用时序数据库的设计要点
为了充分发挥时序数据库的性能,需在设计阶段注意以下几点:
(1)合理规划标签(Tags)与字段(Fields)
- 标签(如device_id=server01、region=cn-north)用于分组和过滤,需设置为索引(但标签过多会增加写入开销)。
- 字段(如temperature=25.5、cpu_usage=80)是实际存储的数值,无需索引。
(2)选择合适的时间精度
根据业务需求决定时间戳精度(如秒级、毫秒级),避免存储冗余的高精度数据(如仅需分钟级统计时,无需存储毫秒级原始数据)。
(3)利用预聚合(Downsampling)
对长时间范围的查询(如“过去一年的每日最高温度”),预先计算并存储聚合结果(如每小时的最大值),减少实时计算压力。
(4)利用预聚合设置合理的TTL
根据业务需求设置数据保留周期(如30天、1年),避免存储成本过高。部分数据库支持分级TTL(如最近7天保留原始数据,更早数据保留聚合结果)。
(5)批量写入而非逐条写入
时序数据库通常优化了批量写入性能(如InfluxDB的batch_size参数),建议将多条数据打包后一次性写入。
6、总结
时序数据库是处理高频时间序列数据的专用工具,通过时间分区、列式存储、压缩优化等技术,在写入性能、查询效率、存储成本上显著优于传统数据库。
选择时需结合业务场景(如数据量、查询复杂度、部署环境),优先考虑主流产品(如InfluxDB、TimescaleDB、Prometheus),并合理设计数据模型以最大化性能。
二、TimescaleDB介绍
1、简介
TimescaleDB 是一款基于 PostgreSQL 扩展的开源时序数据库,通过将时序数据的高效存储与 PostgreSQL 的关系型特性(如 SQL 支持、事务、复杂查询)相结合,填补了传统时序数据库(如 InfluxDB)与通用关系型数据库之间的空白。
它既保留了时序数据库对高频写入、时间范围查询的优化,又继承了 PostgreSQL 的生态优势(如扩展插件、GIS 支持、JSONB 存储等),适用于需要时序数据处理+复杂业务逻辑关联的场景。
2、核心架构:超表(Hypertable)
TimescaleDB 的核心创新是 Hypertable(超表),它是一种逻辑上的时间分区表,通过自动将数据按时间分割成多个块(Chunk),实现对时序数据的高效管理。具体机制如下:
(1)时间分区(Time Partitioning)
Hypertable 会将数据按时间戳自动划分为多个块(Chunk),每个块对应一个时间区间(如按天、小时分区)。
例如,一个按天分区的 Hypertable,每天会生成一个新的 Chunk 存储当天的数据。
优势:块是物理存储的最小单元,查询时可快速定位到目标时间范围内的块,避免全表扫描;同时,旧块可自动归档或删除(通过 TTL),降低存储成本。
(2)空间分区(Space Partitioning,可选)
对于超大规模数据(如亿级数据点),可结合空间分区(如按设备 ID、区域等标签分区),将数据在时间和空间两个维度分割,进一步提升查询性能。
例如,按 device_id 和时间双重分区,查询某设备最近 1 小时的数据时,可直接定位到对应空间和时间块。
(3)自动管理
Hypertable 的分区策略(如时间间隔、块大小)可通过参数自动调整,无需手动干预。
当新数据写入时,系统会自动创建新块;
旧块超出保留周期后,可自动删除或迁移至低成本存储(如对象存储)。
3、核心特性
(1)完全兼容 SQL
TimescaleDB 基于 PostgreSQL 内核扩展,支持标准 SQL(包括 JOIN、子查询、窗口函数、事务等),可直接操作时序数据,无需学习类 SQL 语法(如 InfluxQL)。例如:
-- 查询某设备最近1小时的平均温度,并关联设备元数据
SELECT
time_bucket('5 minutes', time) AS bucket,
device_id,
AVG(temperature) AS avg_temp
FROM
metrics
JOIN
devices ON metrics.device_id = devices.id
WHERE
device_id = 'sensor-001'
AND time > NOW() - INTERVAL '1 hour'
GROUP BY
bucket, device_id;
(2)高性能写入与查询
写入优化:支持批量写入(如 INSERT INTO … VALUES (…), (…)),通过内存缓冲、异步刷盘、块级索引(仅对时间戳和标签索引)降低写入延迟,单节点可支持数十万点/秒的写入。
时间范围查询:通过分区裁剪(仅扫描目标时间块的 Chunk),结合块内索引(如时间戳、标签的 B-tree 索引),快速定位数据,避免全表扫描。
(3)自动数据生命周期管理(TTL)
支持基于时间的自动数据过期策略(ALTER TABLE … SET (timescaledb.retention_period = ‘7 days’)),旧数据可自动删除或归档至冷存储(如 S3),降低存储成本。
(4)连续聚合(Continuous Aggregates)
针对长时间范围的统计查询(如“过去 30 天的每小时平均 CPU 使用率”),TimescaleDB 支持预计算并存储聚合结果,避免实时计算原始数据。聚合结果会随新数据写入自动更新,查询时直接读取预聚合数据,大幅提升性能。
(5)与 PostgreSQL 生态深度融合
支持 PostgreSQL 所有扩展(如 PostGIS、Citus 分布式扩展、pg_partman 分区插件)。
兼容 PostgreSQL 客户端(如 psql、JDBC、ODBC),可无缝集成到现有系统中。
支持 JSONB、数组等数据类型,适合存储时序数据的附加信息(如设备元数据)。
(6)分布式支持(通过 Citus)
TimescaleDB 可与 Citus(PostgreSQL 的分布式扩展)结合,实现水平扩展,支持 PB 级数据存储和高并发查询。
分布式场景下,数据可按时间或空间分片,提升集群吞吐量。
4、典型应用场景
TimescaleDB 适合需要时序数据处理+复杂业务逻辑的场景,尤其当业务需与关系型数据(如用户信息、设备元数据)关联时:
(1)工业物联网(IIoT)与设备监控
存储设备传感器数据(温度、振动、能耗),同时关联设备元数据(型号、厂商)。
支持实时查询(如“某设备最近 10 分钟的振动值”)和复杂分析(如“近 1 周振动值的异常波动趋势”)。
(2)DevOps 与 APM 监控
存储服务器/应用的性能指标(CPU、内存、请求延迟),结合日志数据(存储于 PostgreSQL)进行关联分析。
支持通过 SQL 编写自定义告警规则(如“当 QPS 连续 5 分钟超过阈值时触发通知”)。
(3) 能源管理与智能电网
存储电表、光伏设备的实时能耗数据,按时间分区存储,支持“按小时/天统计用电量”或“跨区域能耗对比”等查询。
(4)金融与交易监控
存储股票/期货的实时行情数据(价格、成交量),结合交易记录(存储于 PostgreSQL)分析交易行为与市场波动的关系。
5、与其他时序数据库的对比
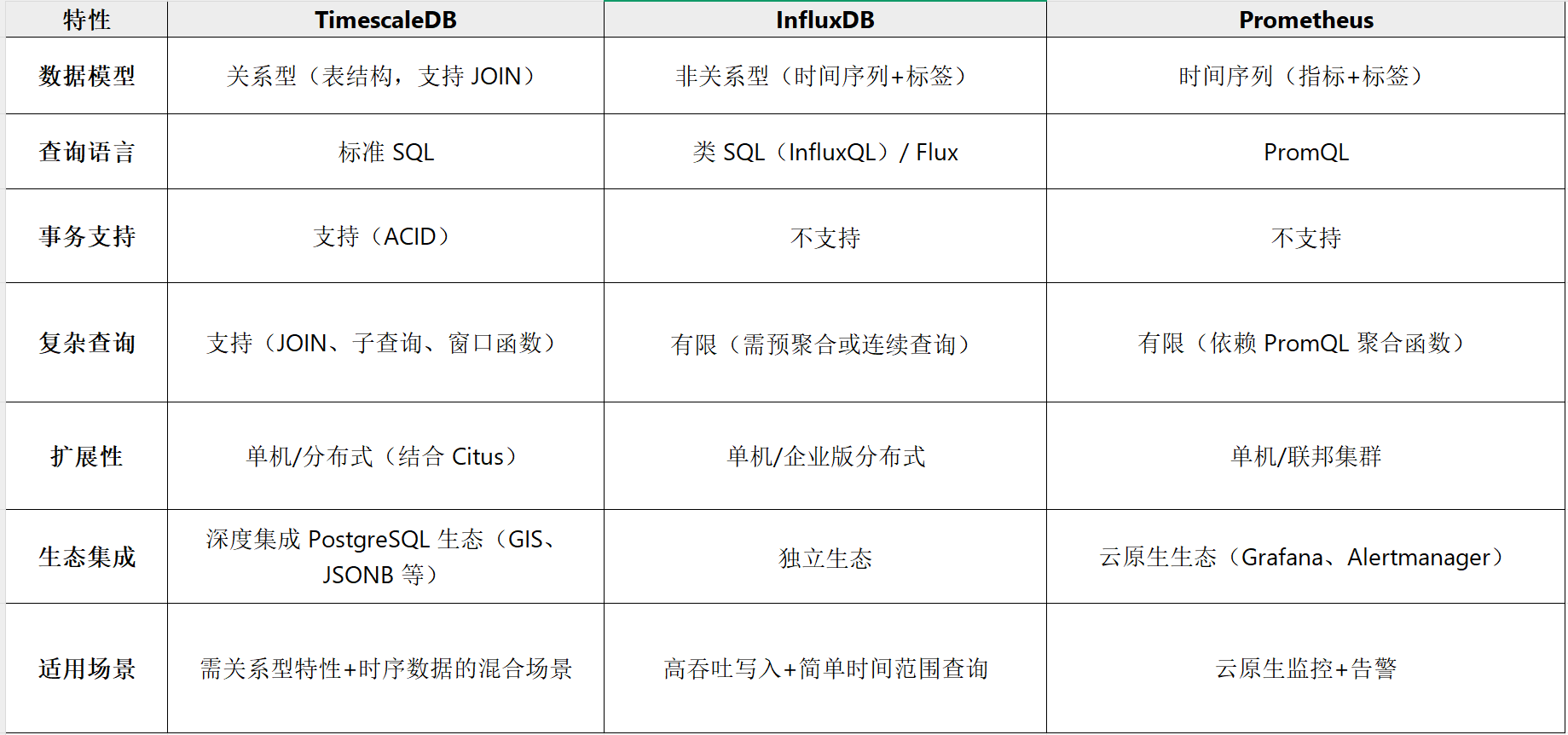
6、部署与使用建议
(1)部署方式
(a)单机版
直接通过 PostgreSQL 扩展安装(CREATE EXTENSION timescaledb;),适合小规模数据(亿级以下)或开发测试环境。
(b)分布式版
结合 Citus 扩展,将数据按时间或空间分片,支持 PB 级数据和水平扩展,适合生产环境大规模场景。
(c)云托管
AWS RDS、Azure Database、Google Cloud 等均提供 TimescaleDB 托管服务,简化运维(自动备份、扩缩容)。
(2)设计建议
(a)合理选择分区策略
根据数据量选择时间分区间隔(如秒级数据按小时分区,分钟级数据按天分区);超大规模数据可结合空间分区(如 device_id)。
(b)优化索引
仅在标签(如 device_id)和时间戳上创建索引,避免过多索引影响写入性能。
(c)利用连续聚合
对高频查询的统计指标(如小时均值、日最大值)创建连续聚合表,减少实时计算压力。
(d)设置 TTL
根据业务需求设置数据保留周期(如原始数据保留 30 天,聚合数据保留 2 年),降低存储成本。
(3)迁移注意事项
(a)从 InfluxDB 迁移时
可通过工具(如 influx2timescaledb)将数据导入 TimescaleDB,需注意标签(Tags)与字段(Fields)的映射(TimescaleDB 中标签通常作为列存储)。
(b)从 Prometheus 迁移时
可使用 promscale(TimescaleDB 官方工具)同步数据,支持实时写入和历史数据迁移。
7、总结
TimescaleDB 凭借“时序优化+关系型特性”的双重优势,成为需要复杂查询、事务支持或多数据类型关联场景的首选。
它既适合工业监控、DevOps 等传统时序场景,也能无缝集成到 PostgreSQL 生态中,满足企业级应用的多样化需求。
对于熟悉 SQL、需要与现有业务系统深度集成的团队,TimescaleDB 是替代专用时序数据库的高性价比选择。

一站式 AI 云服务平台
更多推荐



 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)