
mysql查询每个用户第一条数据_MySQL数据库订单表按用户邮箱字段分组查询每个用户的第一条记录...
程序开发或者一些数据统计时,在MySQL中使用GROUP BY分组是很常用的SQL语句。那么,如果如下的简单示例订单数据表,我们现需要使用GROUP BY分组后查询每个用户的第一个订单记录,应该如何实现呢?首先,我们创建示例数据表:orders,SQL语句如下:CREATE TABLE `orders` (`id` int(6) NOT NULL AUTO_INCREMENT,`email_add
程序开发或者一些数据统计时,在MySQL中使用GROUP BY分组是很常用的SQL语句。那么,如果如下的简单示例订单数据表,我们现需要使用GROUP BY分组后查询每个用户的第一个订单记录,应该如何实现呢?
首先,我们创建示例数据表:orders,SQL语句如下:
CREATE TABLE `orders` (
`id` int(6) NOT NULL AUTO_INCREMENT,
`email_address` varchar(45) NOT NULL DEFAULT '',
`created_on` datetime DEFAULT CURRENT_TIMESTAMP,
`price` decimal(8,2) DEFAULT '0.00',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='订单表';
数据库成功创建后,我们插入一些示例数据:
INSERT INTO orders (email_address,price)VALUES('a@a.com',25.55);
INSERT INTO orders (email_address,price)VALUES('b@a.com',20.75);
INSERT INTO orders (email_address,price)VALUES('c@a.com',52.35);
INSERT INTO orders (email_address,price)VALUES('c@a.com',20.00);
INSERT INTO orders (email_address,price)VALUES('e@a.com',80.85);
INSERT INTO orders (email_address,price)VALUES('a@a.com',95.15);
INSERT INTO orders (email_address,price)VALUES('c@a.com',210.55);
INSERT INTO orders (email_address,price)VALUES('f@a.com',57.00);
以上orders表和数据都准备好之后,最后一步则需要使用GROUP BY的SQL语句来查询按用户分组的每个用户订单价格最高的第一条记录了,如下:
SELECT MIN(O.id) AS min_id
,O.email_address
,O.price
FROM orders AS O
JOIN (SELECT A.email_address,MAX(price) AS max_price
FROM orders AS A
GROUP BY A.email_address) AS T
ON T.email_address=O.email_address AND T.max_price=O.price
GROUP BY O.email_address,O.price
执行以上GROUP BY的分组查询,结果如下截图:
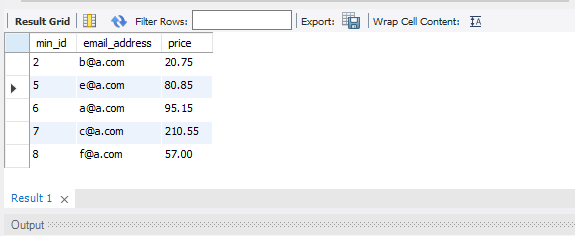
关于MySQL的查询有很多方式,本文旨在提供一种可行的实现方式,如果你有其他的实现SQL语句,欢迎留言反馈,交流。

一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)