
【Dify知识库中的普通分段与父子分段】
本文介绍了知识库构建中的分段策略,重点分析了父子分段的优势与应用。文章首先阐述了分段的必要性,包括提高检索效率、增强语义理解和优化存储结构,并列举了五种常见分段方法及其适用场景。随后详细解析了父子分段的层级结构设计,通过父分段保持主题完整性,子分段实现精准检索,解决了通用分段存在的上下文割裂问题。实验对比显示,父子分段在召回率和准确率上显著优于通用分段,尤其适用于技术文档、客服知识库等结构化内容场
一、知识库构建的分段方式
!!本文基于Dify中的知识库进行操作分析与讲解,需要对Dify有一定的基础,如果有需要,可以在评论区或者私信我,我会另写一篇有关Dify的内容,当然,相关内容在网上也有很多。!!
1.1 为什么要分段
在构建知识库的过程中,分段(Chunking)是指将大块的文本、数据或信息拆分成更小、更易管理的分段(Chunk)(即“段落”或“片段”),以便于存储、检索和分析。分段是知识库构建的核心步骤之一,直接影响后续的搜索、问答和AI理解的效果。
知识库分段的主要目的有如下几点:
- 提高检索效率:短文本比长文本更容易被搜索引擎或AI模型处理。
- 增强语义理解:合理分段能让AI更精准地理解上下文,避免信息混杂。
- 优化存储结构:结构化数据更易于管理和更新。
常见的分段方法:
1、按固定长度分割(Fixed-size Chunking)
例如:每200字或500字切分一次。
适用场景:标准化文档(如法律条文、技术手册)。
2、按自然段落分割(Paragraph-based Chunking)
根据换行符或段落标记(如`\n\n`)拆分。
适用场景:文章、报告、网页内容等。
3、按语义分割(Semantic Chunking)
使用NLP模型识别语义边界,确保每个片段表达完整意思。
适用场景:复杂文本(如研究论文、用户咨询记录)。
4、按标题/章节分割(Hierarchical Chunking)
依据文档结构(如H1/H2标题)划分。
适用场景:书籍、技术文档、带目录的长文。
5、滑动窗口分割(Sliding Window)
允许部分内容重叠,避免关键信息被切断。
适用场景:对话记录、连续日志。
分段时的注意事项:
- 避免信息碎片化:确保每个片段有独立意义,而非零散句子。
- 结合业务需求:问答系统需要更细的分段,而摘要生成可能适合大段落。
- 测试与优化:不同分段方式影响AI回答质量,需通过实验选择最佳策略。
示例对比
原始文本:“深度学习是机器学习的分支,依赖神经网络。训练时需要大量数据和GPU支持。应用场景包括图像识别、自然语言处理等。”
不好的分段(过于零碎):
C1、“深度学习是机器学习的分支。”
C2、“依赖神经网络。”
C3、“训练时需要大量数据。”
好的分段(语义完整):
C1、“深度学习是机器学习的分支,依赖神经网络。”
C2、“训练时需要大量数据和GPU支持,应用场景包括图像识别、自然语言处理等。”
1.2 什么是父子分段
在Dify的知识库中,将文本分段方法划分为通用分段和父子分段两种。父子分段(Hierarchical Chunking)是一种结构化的文本分段策略,通过建立“父分段-子分段”的层级关系,将内容按逻辑关联性组织。类似“按固定长度分割“和”按语义分割“的混合体。
- 父分段(Parent Chunk):代表一个完整主题或章节(如“数据库备份报错处理方案”)。
- 子分段(Child Chunk):父分段下的具体内容块(如“步骤一:XXX”、“步骤二:XXX”、……)。
父子分段的核心目的是 平衡检索精度与上下文完整性 ,解决通用分段的三大痛点:
1、上下文割裂问题:
-
- 通用分段可能将一个完整主题拆散(如将“操作指南”的步骤1和步骤2分到不同分段),导致大模型回答时缺失关键信息。
- 父子分段通过层级关联,确保子分段始终能回溯到父分段的上下文(如“步骤1”属于“操作指南”大主题)。
2、长尾检索优化:
-
- 当用户提问涉及细分内容(如“如何配置功能A的参数?”),父子分段能精准匹配子分段,同时通过父分段补充全局信息(如功能A的适用版本)。
- 而通用分段是针对真个分段快内容进行匹配,很可能由于召回率太低而无法找到精确的内容。
3、多粒度检索支持:
-
- 支持灵活查询:
- 粗粒度:检索父分段(如“系统登录失败”)。
- 细粒度:直接命中子分段(如“错误代码404的解决方法”)。
- 支持灵活查询:
1.3 父子分段 vs 通用分段的区别
| 对比维度 | 父子分段 | 通用分段 |
|---|---|---|
| 结构 | 层级化(父-子关系) | 扁平化(独立段落) |
| 检索逻辑 | 支持跨层级关联检索 | 仅单段匹配 |
| 适用场景 | 结构化文档(手册、API文档) | 短文、非结构化内容(新闻、评论) |
| 上下文保留 | 子分段继承父分段的语义 | 依赖滑动窗口或重叠分段 |
1.3.1 父子分段与通用分段在相同问题下的召回率对比
以动环监控系统使用手册知识库为例,划分为父子分段和通用分段两种类型,在召回率测试中,检索设置使用向量检索,使用beg Rerank模型,Top K设置为2,Score阈值关闭。分别对两个知识库询问相同的问题,进行召回率对比测试。结果如下:
问题1:用户如何登录系统?
父子分段召回测试结果:成功召回,并且以高分召回,表示改内容与问题极其相符。没有其他内容的干扰。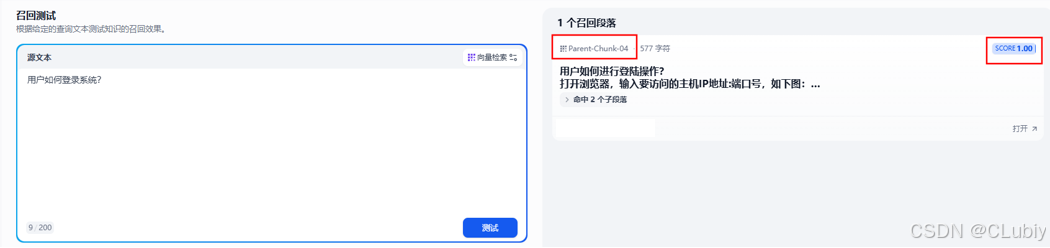
通用分段召回测试结果:成功召回,但还额外召回了不相关的内容,这种结果可能在之后对大模型的回复造成困扰。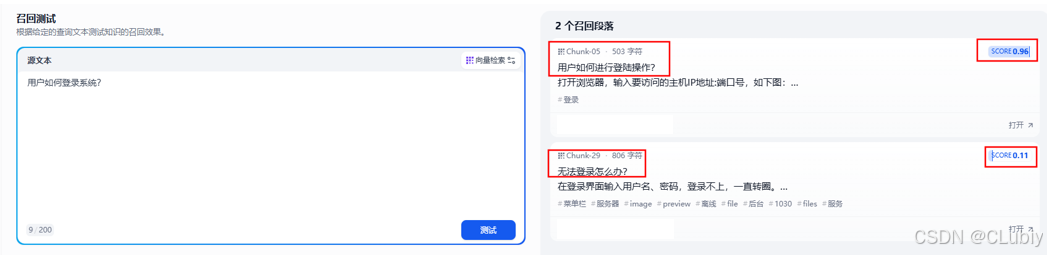
问题2:如何停用一个告警事件?
父子分段召回测试结果:召回成功,并且以高分召回,表示改内容与问题极其相符。没有其他内容的干扰。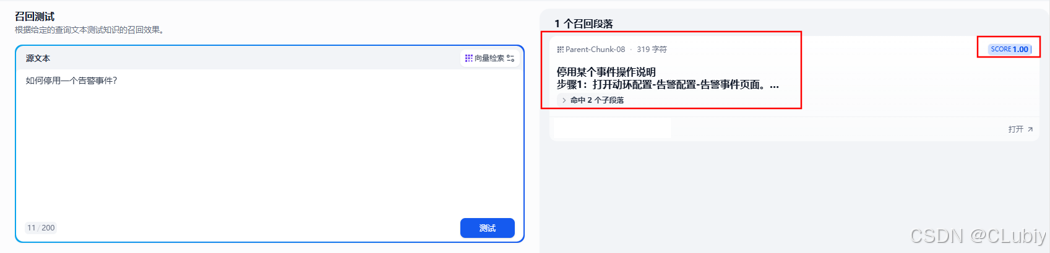
通用分段召回测试结果:召回成功,但是也召回了不太相关的内容,这种结果可能在之后对大模型的回复造成困扰。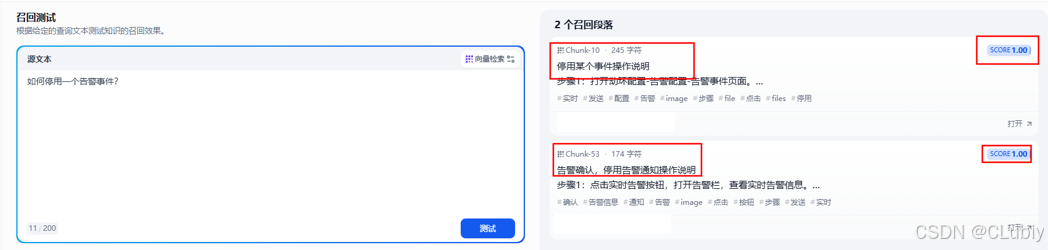
问题3:系统提示UPS输入电压低报警,怎么办?
父子分段召回测试结果:召回成功,并且以高分召回,表示改内容与问题极其相符。没有其他内容的干扰。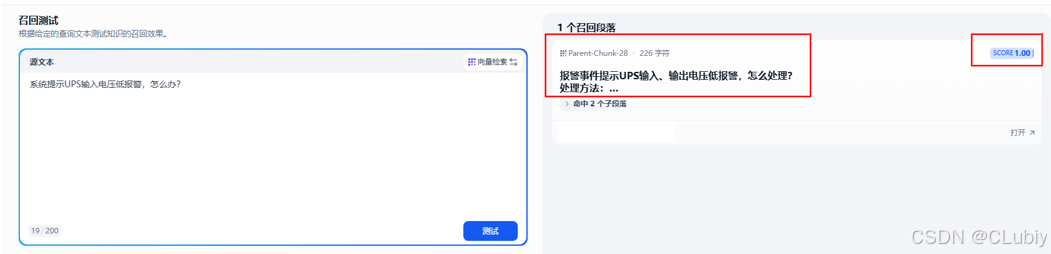
通用分段召回测试结果:召回成功,但是也召回了不太相关的内容,,这种结果可能在之后对大模型的回复造成困扰。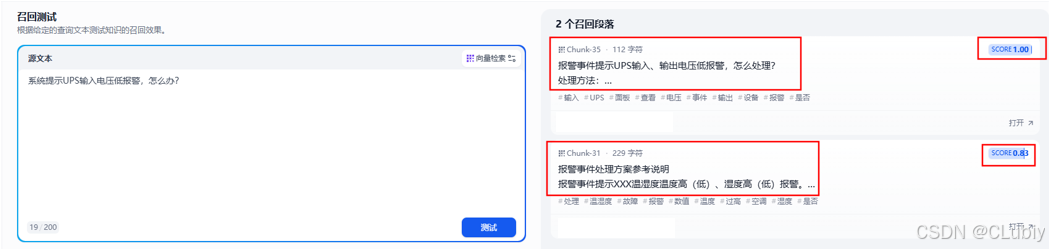
通过如上三个召回测试实验,可以直观地发现,使用父子分段后,知识库的召回率大幅提升,并且精度提高很多,同一问题只召回一个匹配的内容,然而通用分段的知识库虽然召回分数也不低,但是却同时召回了不太相关甚至完全不相关的内容,在后续对大模型生成内容的影响非常大。
1.4 父子分段的内容检索过程
父子分段将大段的父分段继续划分为更细粒度的子分段。在进行内容检索时,检索引擎将用户问题向量化之后,与众多子分段进行语义相似度计算(对于向量计算,显卡通过使用TensorCore,配合Tensor库方法,以及向量数据库的读取速度,可以计算得飞快,所以不用担心检索速度)。当获取到召回率最高的子分段后,会将完整的父分段返回给大模型,大模型根据父分段中的内容,生成回答返回给用户。
1.5总结
父子分段是Dify知识库针对 复杂结构化内容 的高级优化策略,尤其适合:
- 需要保留上下文的 技术文档、产品手册。
- 长尾查询频繁的 客服知识库。
- 多层级检索需求的 企业级知识管理。
建议:若内容高度结构化且检索精度要求高,优先采用父子分段;若内容简单或需快速部署,通用分段更高效。

一站式 AI 云服务平台
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)