
嵌入模型:企业知识库的AI引擎 (小白总结篇 1)
以非技术人员角度,介绍了嵌入模型的基本概念,旨在学习记录并促进交流。作者解释了为何讨论嵌入模型——为使企业RAG知识库更智能,找到最佳向量化工具。采用通俗易懂的语言解释了什么是嵌入模型,以及它的工作原理,比如将非结构化数据转换为数值向量,并强调了相似文本在向量空间中会更接近的特点。此外,文章还详细列举了嵌入模型的应用场景,包括语义搜索、推荐系统、文本分类等,并介绍了Hugging Face MTE
摘要
以非技术人员角度,介绍了嵌入模型的基本概念,旨在学习记录并促进交流。作者解释了为何讨论嵌入模型——为使企业RAG知识库更智能,找到最佳向量化工具。采用通俗易懂的语言解释了什么是嵌入模型,以及它的工作原理,比如将非结构化数据转换为数值向量,并强调了相似文本在向量空间中会更接近的特点。此外,文章还详细列举了嵌入模型的应用场景,包括语义搜索、推荐系统、文本分类等,并介绍了Hugging Face MTEB排行榜作为选择合适嵌入模型的参考工具。
嵌入模型:企业知识库的AI引擎 (小白总结篇 1)
一、 为什么我们要聊嵌入模型?
1.1 背景:RAG 知识库,让企业知识“活”起来
- 作为一个非技术和研发人员,最近因为工作原因,在研究如何搭建更智能的企业知识库,所以本着学习的目的,把调研和查询到的材料做一个总结。而要让 RAG 知识库真正“聪明”起来,一个关键的工具就是 嵌入模型 (Embedding Model)。 这就是我调研嵌入模型的初衷: 为我们的 RAG 知识库,选一个最给力的“向量化”工具!
文章可能会分为两篇来总结,如果发现了问题描述错误,请大家指正。
1.2 面向 “小白” 朋友们的科普
- 作为一个非技术人员,这篇文章更多的是自己材料的查询和总结,期望使用大白话,来更好的记录和理解“嵌入模型” 这个概念。
目标只有一个: 一起学习,共同进步!
二、 什么是 “嵌入” 模型? (像搭积木一样简单)
2.1 从 “小白” 的角度看 “嵌入”
2.1.1 “嵌入” (Embedding) 是啥? 生活中的例子告诉你
“嵌入” 听起来挺抽象,其实我们生活中早就用到了类似的概念。 我给你举几个例子,你就秒懂了:
- 坐标地图: 你在地图上看到每个地点都有坐标 (经度、纬度),这就是把地理位置 “嵌入” 到数字空间里。 相似的地点 (比如挨得很近的两个咖啡馆),在坐标上也会很接近。
- 颜色代码: 我们用 RGB 值 (比如 #FF0000 代表红色) 来表示颜色,这也是把颜色 “嵌入” 到数值空间。 相似的颜色 (比如浅红和深红),RGB 值也会比较接近。
- 电影评分: 豆瓣电影评分 (1星到5星),是把用户对电影的喜好程度 “嵌入” 到数字空间。 评分相近的电影,往往类型也比较相似。
为什么要 “嵌入”? 因为计算机 “听不懂” 我们人类的语言,看不懂图片,但是 计算机很擅长处理数字! “嵌入” 就是把那些 “看不懂” 的东西, 变成计算机能 “理解” 的数字, 方便它进行各种操作。
2.1.2 “嵌入模型” 又是啥? 一个神奇的 “编码器”
简单来说, 嵌入模型就是一个工具,它可以把文本、图像等等 “非结构化数据”, 变成一串串 “数值向量”。 你可以把它想象成一个 “编码器”, 把我们人类的 “语言”, “编码” 成计算机可以理解的 “语言”。
举个例子: 假设我们用一个嵌入模型来处理文本。 当我们输入 “猫” 这个词,模型可能会输出这样一个向量: [0.2, 0.5, -0.1, ..., 0.8] (实际的向量维度会更高,这里只是示意)。 这个向量就是 “猫” 这个词的 “嵌入表示”。
2.1.3 “嵌入向量” 里藏着什么秘密? 语义空间和维度
- 语义空间: 最神奇的地方在于, 相似的文本, 经过嵌入模型处理后, 它们对应的向量在空间中会 “靠得更近”! 比如 “猫” 和 “小猫” 的向量,会比 “猫” 和 “汽车” 的向量更接近。 这就是所谓的 “语义空间”, 向量之间的距离,反映了文本的语义相似度。
- 向量维度: 向量的维度就像坐标轴的数量。 维度越高,能表达的信息就越丰富,但计算也更复杂。 就像用二维坐标 (经度、纬度) 可以定位地球上的地点,用三维坐标 (经度、纬度、海拔) 可以更精确地定位。 维度越高,模型捕捉的语义信息可能更丰富,但也可能带来过拟合等问题。 选择合适的维度,需要根据实际应用场景来权衡。
2.2 嵌入模型能干啥? 应用场景大盘点
嵌入模型就像一把瑞士军刀,应用场景非常广泛,这里列举几个常见的:
2.2.1 语义搜索: 搜你所想,不再是 “关键词匹配”
传统的搜索,往往是基于关键词匹配, 比如你搜 “红色连衣裙”, 只有标题或内容里包含 “红色”、“连衣裙” 的商品才会被搜到。 语义搜索,则能理解你的 “意图”。 即使你搜 “亮眼的红色裙子”, 也能找到相关的商品,因为模型理解了 “亮眼” 和 “红色” 在这里是语义相关的。
示例: 在电商网站搜索 “红色连衣裙”, 嵌入模型会把你的搜索query 和商品信息都转换成向量, 然后找到向量距离最近的商品, 这些商品就是语义上最相关的,即使标题里不一定完全包含 “红色” 和 “连衣裙” 这两个词。
2.2.2 推荐系统: 猜你喜欢,比你更懂你
各种 App 里的 “猜你喜欢” 功能,背后也离不开嵌入模型。 模型会分析你的浏览历史、购买记录等等, 把这些行为 “嵌入” 到向量空间, 然后找到和你 “兴趣向量” 相似的商品或内容, 推荐给你。
示例: 你最近浏览了很多关于 “咖啡” 的商品, 推荐系统可能会给你推荐咖啡豆、咖啡机、咖啡杯等等, 因为它通过嵌入模型, 理解了你对 “咖啡” 这个主题的兴趣。
2.2.3 文本分类: 自动给文章 “贴标签”
嵌入模型可以帮助我们对文本进行自动分类,比如:
示例: 自动识别垃圾邮件。 模型会把邮件内容转换成向量, 然后判断这个向量属于 “垃圾邮件” 还是 “正常邮件” 这个类别。
2.2.4 知识图谱: 构建知识的 “关系网”
知识图谱是一种结构化的知识表示方式,它用 “实体” 和 “关系” 来描述世界。 嵌入模型可以帮助我们构建和完善知识图谱。
示例: 构建人物关系图谱。 模型可以分析文本, 识别出人物实体 (比如 “马云”、“蔡崇信”), 以及他们之间的关系 (比如 “创始人”、“合伙人”), 并将这些信息 “嵌入” 到向量空间, 从而构建人物关系网络。
2.2.5 问答系统: 智能客服,有问必答
RAG 知识库的核心应用之一就是问答系统。 嵌入模型可以将用户的问题和知识库里的文档都转换成向量, 然后找到最相关的文档, 并基于文档内容生成答案。
示例: 智能客服机器人。 用户提问 “退货流程是什么?”, 模型会把这个问题和知识库里的 “退货流程” 文档都转换成向量, 找到最匹配的文档, 然后提取文档中的关键信息, 生成简洁明了的答案。
2.2.6 智能标注: 批量处理,效率翻倍
在实际工作中,我们经常需要对大量的文本或图像数据进行标注,比如文本分类、实体识别等等。 嵌入模型可以帮助我们实现智能标注,大幅提升效率。
示例: 假设我们要对一批电商评论进行情感标注 (正面/负面)。 我们可以先人工标注少量评论, 然后用嵌入模型将这些已标注的评论向量化。 对于未标注的评论, 模型可以计算它们与已标注评论的向量相似度, 自动找到语义相似的评论, 并推荐相同的标签。 这样,我们只需要人工审核少量高置信度的推荐结果, 就能完成大部分标注工作, 大大节省时间和人力。 这个思路也可以应用于图像标注等其他场景。
另一个示例: 在之前供职过的公司,我也曾经在内部的NLP训练平台中的标注板块,引入了嵌入模型,来实现文本分类的智能标注,他可以把待标注的单条语料,从剩余未标注的语料中进行向量检索,把语意最相似的语料按照匹配程度顺次展示出来,用户批量勾选即可实现批量的分类标注。
三、 嵌入模型怎么选? Hugging Face MTEB 来帮忙
3.1 Hugging Face MTEB 排行榜: 嵌入模型的 “武林大会”
面对市面上琳琅满目的嵌入模型, 我们该如何选择呢? Hugging Face 的 MTEB (Massive Text Embedding Benchmark) 排行榜, 专门用来 评估文本嵌入模型的性能。 你可以把它理解为嵌入模型的 “武林大会”, 各种模型都在这里一较高下。
排行榜地址: https://huggingface.co/spaces/mteb/leaderboard**
MTEB 是一个 基准测试, 它包含了 多个不同的任务和数据集, 用统一的标准来衡量不同模型的 “实力”, 确保评估的 公平性和客观性。
3.2 榜单筛选功能: 找到你的 “最佳选手”
MTEB 排行榜提供了强大的筛选功能, 我们可以根据自己的需求, 快速找到最合适的模型。
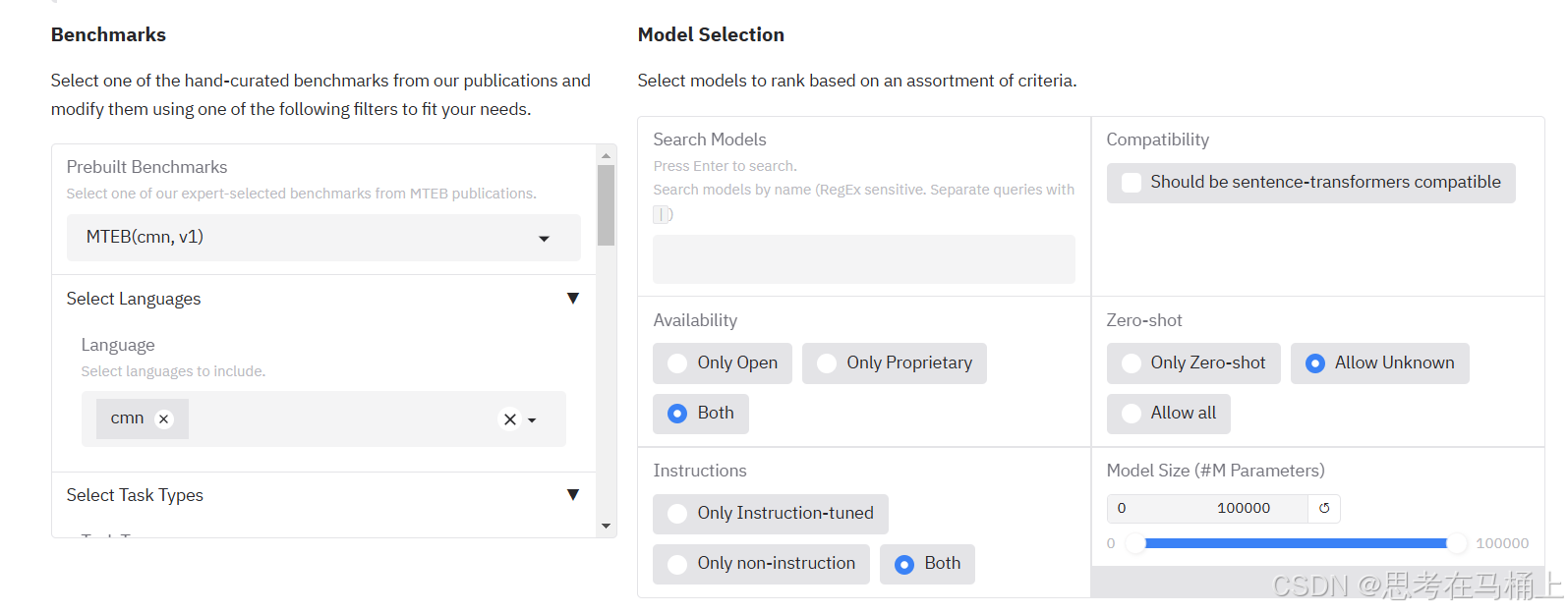
3.2.1 首先是预构建的基准(Prebuilt Benchmarks)
Prebuilt Benchmarks目标是了解每个基准数据集旨在测试模型的哪些方面,這举例说明:
- BEIR:Bi-Encoder Retrieval Dataset (双编码器检索数据集)
- 目的: 评估双编码器检索模型的数据集集合。
- 任务类型: 双编码器检索。 模型将查询和文档分别编码成向量,然后计算向量之间的相似度,检索出与查询最相关的文档。
- 应用场景: 企业内部知识库搜索。
- 示例:
- 场景: 员工需要查找公司关于“年度绩效考核流程”的文档。
- 双编码器检索: 模型将用户的查询(“年度绩效考核流程”)和知识库中的所有文档都编码成向量。然后计算查询向量和所有文档向量之间的相似度,找到最相似的文档并返回给用户。
- 重要性: 帮助员工快速准确地找到所需信息,提高工作效率。
-
BEIR-NL:BEIR 的荷兰语版本
-
BRIGHT:跨文档信息检索基准数据集
- 目的: 评估跨文档信息检索的性能。
- 任务类型: 跨文档信息检索。 需要模型能够从多个文档中提取信息并进行整合,才能回答用户的问题。
- 应用场景: 金融领域的风险评估。
- 示例:
- 场景: 分析师需要评估一家公司的信用风险,需要从该公司的新闻报道、财务报表、行业分析报告等多个文档中提取信息。
跨文档信息检索: 模型需要从多个文档中找到关于该公司的财务状况、经营状况、行业地位等信息,并进行整合分析,才能给出风险评估结果。 - 重要性: 提供更全面和准确的风险评估。
- 场景: 分析师需要评估一家公司的信用风险,需要从该公司的新闻报道、财务报表、行业分析报告等多个文档中提取信息。
- BuiltBench(eng):生成式模型评估基准 (英语)
- 目的: 评估生成式模型的性能。
- 任务类型: 生成式任务。 模型需要根据输入生成符合要求的文本。 常见的生成任务包括:文本摘要、机器翻译、代码生成等。
- 应用场景: 自动生成产品描述。
- 示例:
- 场景: 电商平台需要为新上架的商品自动生成描述文案。
- 生成式模型: 模型根据商品的属性(例如:品牌、型号、材质、功能等)生成一段描述文案,吸引用户购买。
- 重要性: 提高产品上架效率,降低人工成本。
- ChemTEB:化学领域文本嵌入基准
- 目的: 评估化学领域文本嵌入模型的性能。
- 任务类型: 化学领域的各种文本任务。 模型需要理解化学领域的专业术语和知识。
- 应用场景: 化学专利检索。
- 示例:
- 场景: 化学研究人员需要检索与某种特定化合物相关的专利。
- 化学领域文本嵌入: 模型将用户的查询(例如:化合物名称、分子式、CAS号等)和专利文档都编码成向量。 然后计算向量之间的相似度,找到最相关的专利。
- 重要性: 加速化学研究进程,避免重复研究。
- CoIR:跨语言信息检索基准
- 目的: 评估跨语言信息检索的性能。
- 任务类型: 跨语言信息检索。 用户用一种语言进行查询,模型需要检索出用另一种语言编写的文档。
- 应用场景: 国际贸易情报收集。
- 示例:
- 场景: 一家中国公司想了解德国市场上某种产品的竞争情况。
- 跨语言信息检索: 中国员工用中文进行查询,模型需要检索出用德语编写的市场分析报告。
- 重要性: 帮助企业更好地了解国际市场,做出更明智的决策。
- CodeRAG:代码检索和生成数据集
- 目的: 评估代码检索和代码生成模型的性能。
- 任务类型: 代码检索和代码生成。 代码检索是指根据自然语言查询检索出相关的代码片段;代码生成是指根据自然语言描述生成代码。
- 应用场景: AI 辅助编程。
- 示例:
- 场景: 程序员需要实现一个排序算法,但不记得具体的代码实现。
- 代码检索: 程序员用自然语言描述需求:“实现一个快速排序算法”。 模型检索出相关的代码片段。
- 代码生成: 程序员用自然语言描述需求:“实现一个计算两个日期之间天数的函数”。 模型自动生成相应的代码。
- 重要性: 提高开发效率,降低开发成本。
- FollowIR:跟随信息检索基准数据集
- 目的: 评估跟随信息检索的性能。
- 任务类型: 跟随信息检索。 模型需要根据用户的历史交互记录和当前的查询,更好地理解用户的意图,并检索出更相关的文档。 需要模型能够维护用户的上下文信息。
- 应用场景: 个性化新闻推荐。
- 示例:
- 场景: 用户之前浏览过很多关于“新能源汽车”的新闻,现在搜索“汽车”。
- 跟随信息检索: 模型会根据用户的历史浏览记录,判断用户更可能对“新能源汽车”感兴趣,因此优先推荐新能源汽车相关的新闻。
- 重要性: 提高用户满意度和粘性。
- LongEmbed:长文档嵌入基准数据集
- 目的: 评估长文档嵌入模型的性能。
- 任务类型: 长文档嵌入。 传统的嵌入模型可能难以处理长文档,因为长文档会超出模型的最大输入长度限制。 长文档嵌入模型需要能够有效地处理长文本并生成高质量的嵌入向量。
- 应用场景: 法律合同相似度比较。
- 示例:
- 场景: 律师需要比较两份法律合同的相似度,判断是否存在抄袭或侵权行为。
- 长文档嵌入: 模型将两份合同都编码成向量,然后计算向量之间的相似度。 相似度越高,说明两份合同越相似。
- 重要性: 提高法律服务的效率和质量。
- MINERSBitextMining:用于挖掘平行文本的数据集
- 目的: 评估挖掘平行文本的能力。 平行文本是指内容相同,但使用不同语言表达的文本对 (例如:同一篇文章的中文版和英文版)。
- 任务类型: 双语平行文本挖掘。 模型需要从大量的文本数据中自动识别出哪些文本是互为翻译的。
- 应用场景: 构建机器翻译训练数据集。
- 示例:
- 场景: 构建一个中文到英文的机器翻译模型,需要大量的中文-英文平行文本数据。
- 平行文本挖掘: 模型从互联网上抓取大量的中文和英文网页,自动识别出哪些网页是互为翻译的,并将这些网页作为机器翻译模型的训练数据。
- 重要性: 降低机器翻译模型的训练成本。
- MTEB (Multilingual Text Embedding Benchmark) 系列数据集
- 目的: 评估多语言文本嵌入模型在不同语言和领域的表现。
- 任务类型: 多语言文本嵌入。 模型需要能够处理多种语言的文本,并生成高质量的嵌入向量。 MTEB 包含多种不同的任务,例- - 如:语义相似度计算、文本分类、信息检索等。
- 应用场景: 多语言搜索引擎。
- 示例:
- 场景: 用户可以用任何语言进行搜索,搜索引擎需要能够检索出用任何语言编写的网页。
- 多语言文本嵌入: 模型将用户的查询和所有网页都编码成向量。然后计算向量之间的相似度,找到最相关的网页。
- 具体数据集举例:
MTEB(cmn, v1): 评估模型在中文文本上的表现。
MTEB(deu, v1): 评估模型在德语文本上的表现。
MTEB(Medical, v1): 评估模型在医学领域的文本上的表现。
MTEB(Law, v1): 评估模型在法律领域的文本上的表现。
重要性: 提高多语言信息检索的效率和准确性,促进跨文化交流。
** 3.2.3 然后是语言选择:**
MMTEB排行榜对1000多种语言的文本嵌入模型进行比较。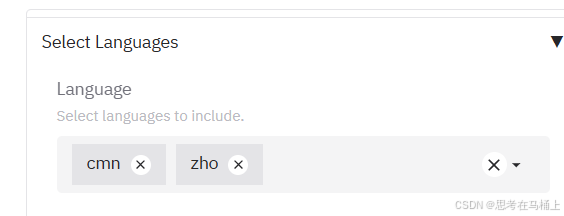
3.2.3 接下来是任务类型:
- BelebeleRetrieval:信息检索任务
- 任务类型: 信息检索 (Information Retrieval)。 涉及从大量文档中检索与给定查询相关的信息。
- 应用场景: 网络论坛中的高质量内容推荐
- 示例:
- 场景: 一个专注于罕见疾病的在线社区论坛,用户提问关于“线粒体脑肌病”的最新治疗进展。
- 任务执行: 系统需要从论坛历史帖子、医学论文库、新闻报道等来源中检索出最相关且可靠的信息,优先展示高质量的解答和权威来源的链接,帮助用户更好地了解这种疾病。
- 重要性: 在信息爆炸的时代,帮助用户从海量信息中快速找到所需的、高质量的内容,避免信息过载和误导。
- FloresBitextMining:平行文本挖掘任务
- 任务类型: 平行文本挖掘 (Bitext Mining)。 旨在从大量文本数据中识别和提取平行语料库,即内容相同但使用不同语言表达的文本对。
- 应用场景: 低资源语言的机器翻译模型构建
- 示例:
- 场景: 假设需要开发一种尼泊尔语到英语的机器翻译系统,但现有的尼泊尔语-英语平行语料非常有限。
- 任务执行: 通过平行文本挖掘技术,从互联网上抓取大量的尼泊尔语和英语网页,自动识别出哪些网页的内容互为翻译(例如:新闻报道、政府公告等),从而构建一个更大的尼泊尔语-英语平行语料库,用于训练机器翻译模型。
- 重要性: 解决低资源语言机器翻译模型训练数据不足的问题,提高翻译质量。
- MIRACLRetrievalHardNegatives:信息检索任务 (困难负样本)
- 任务类型: 信息检索 (Information Retrieval),特别关注于处理困难的负样本。 负样本是指与查询不相关的文档。 困难负样本是- 指那些在语义上与查询比较接近,容易被模型误判为相关的文档。
- 应用场景: 提升专业领域的搜索引擎的准确率
- 示例:
- 场景: 在法律领域的搜索引擎中,用户搜索 “专利侵权诉讼”。
- 任务执行: 模型需要区分哪些专利文件确实涉及侵权,而哪些只是在描述类似的技术概念,但并未构成侵权。模型需要学习区分细微的语义差别,避免将仅仅是 “相关” (但非侵权) 的文档错误地排在搜索结果的前面。
- 重要性: 确保专业领域用户能够获得高度精准的搜索结果,避免因误判而浪费时间和精力。
- MLQARetrieval:多语言问答检索任务
- 任务类型: 多语言问答检索 (Multilingual Question Answering Retrieval)。 涉及在多语言环境中检索答案,即用户可以用一种语言提问,模型需要在另一种或多种语言的文档中找到答案。
- 应用场景: 国际旅游咨询机器人
- 示例:
- 场景: 韩国游客用韩语提问 “도쿄에서 가장 인기 있는 관광지는 어디인가요?”(东京最受欢迎的旅游景点是哪里?)。
任务执行: 模型需要在包含日语、英语、中文等多种语言的旅游信息文档中找到答案,并将答案翻译成韩语返回给用户。 - 重要性: 为全球游客提供便捷的、无语言障碍的旅游信息服务。
- 场景: 韩国游客用韩语提问 “도쿄에서 가장 인기 있는 관광지는 어디인가요?”(东京最受欢迎的旅游景点是哪里?)。
- NTREXBitextMining:平行文本挖掘任务
- 任务类型: 平行文本挖掘 (Bitext Mining)。 与 FloresBitextMining 类似,旨在从大量文本数据中识别和提取平行语料库。 NTREX 可能使用了不同的数据集或针对了特定的领域。
- 应用场景: 提升多语言新闻聚合的准确性
- 示例:
- 场景: 一个多语言新闻聚合平台需要自动识别哪些新闻报道在不同语言版本中描述的是同一事件。
- 任务执行: 利用 NTREXBitextMining 技术,平台可以从抓取到的各种语言的新闻网站上,自动识别出描述同一事件的平行新闻报道,并将其聚合在一起,方便用户阅读不同语言的报道。
- 重要性: 确保多语言新闻聚合平台提供准确且一致的信息。
- SIB200ClusteringS2S:聚类任务
- 任务类型: 聚类 (Clustering),使用序列到序列 (Sequence-to-Sequence, S2S) 方法。 涉及将相似的文档或文本片段分组在一起。 S2S 方法通常用于处理文本序列,可以将一个文本序列转换为另一个文本序列。
应用场景: 客户服务工单的自动分类 - 示例:
- 场景: 客户服务部门每天收到大量的客户工单,需要将这些工单自动分类到不同的类别(例如:产品咨询、投诉建议、退货申请等),以便分配给相应的处理人员。
- 任务执行: 利用 SIB200ClusteringS2S 技术,模型可以学习将具有相似主题和内容的工单自动聚类在一起,从而实现工单的自动分类。
- 重要性: 提高客户服务效率,加快问题解决速度。
- XNLI:跨语言自然语言推理任务
- 任务类型: 跨语言自然语言推理 (Cross-lingual Natural Language Inference, XNLI)。 旨在评估模型在不同语言之间的推理能力,即判断一个给定的前提 (Premise) 和假设 (Hypothesis) 之间的关系 (例如:蕴含 entailment、矛盾 contradiction、中立 neutral)。
- 应用场景: 识别跨语言的虚假信息
- 示例:
- 场景: 为了打击虚假信息传播,需要判断一篇中文文章与其对应的英文翻译版本在内容上是否一致。
- 任务执行: 利用 XNLI 技术,模型需要理解中文文章和英文文章的语义,判断它们之间是否存在逻辑矛盾。 如果发现矛盾,则可能表明其中一篇是虚假信息。
- 重要性: 维护网络信息的真实性和可靠性。
未完待续

一站式 AI 云服务平台
更多推荐



 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)