
知识库——第三方框架
1. Spring1.1. Spring 模块组成Spring Core 框架核心,提供 IOC 容器,管理 bean 对象Spring Context 提供上下文信息Spring Dao 提供 JDBC 抽象层Spring ORM 提供“对象/关系”映射 APIs 的集成层Spring AOP 切面编程功能Spring Web 提供 web 开发的上下文信息Spring Web MVC 提供了
1. Spring
1.1. Spring 模块组成
- Spring Core 框架核心,提供 IOC 容器,管理 bean 对象
- Spring Context 提供上下文信息
- Spring Dao 提供 JDBC 抽象层
- Spring ORM 提供“对象/关系”映射 APIs 的集成层
- Spring AOP 切面编程功能
- Spring Web 提供 web 开发的上下文信息
- Spring Web MVC 提供了 web 应用的 model-view-controller 实现
1.2. AOP面向切面编程
- 不改变原逻辑增加额外功能,将多个类公共行为封装为可重用模块,降低系统耦合度
- Spring 注解 @Aspect,应用于拦截器,认证、日志、同一异常处理(@ControllerAdvice)等等
- 实现方式
- 动态代理技术 (JDK 动态代理、CGLib 动态代理)
- 静态织入方式
1.3. IoC控制反转
- 把创建和查找依赖对象的控制权交给 IoC 容器
- DI 依赖注入是IOC容器装配和注入对象的一种方式
- 作用
- 松耦合
- 资源集中管理
- 功能可复用
1.4. 三种依赖注入的方式
1.4.1. 构造方法注入
将被依赖对象通过构造函数的参数注入给依赖对象,并且在初始化对象的时候注入。
优点: 对象初始化完成后便可获得可使用的对象。
缺点: 当需要注入的对象很多时,构造器参数列表将会很长;不够灵活。若有多种注入方式,每种方式只需注入指定几个依赖,那么就需要提供多个重载的构造函数。
1.4.2. setter 方法注入
IoC Service Provider 通过调用成员变量提供的setter函数将被依赖对象注入给依赖类。
优点: 灵活,可以选择性地注入需要的对象。
缺点: 依赖对象初始化完成后由于尚未注入被依赖对象,因此还不能使用。
1.4.3. 接口注入
依赖类必须要实现指定的接口,然后实现该接口中的一个函数,该函数就是用于依赖注入,该函数的参数就是要注入的对象。
优点: 接口注入中,接口的名字、函数的名字都不重要,只要保证函数的参数是要注入的对象类型即可。
缺点: 侵入行太强,很少使用。
1.5. Spring 使用的注入方式
Spring 的注入方式只有两种,分别是 setter 注入和构造方法注入。
通常使用的 @Autowried 注解实际是 setter 注入的一种变体。
Spring 的注入模式有四种:
- no
- byType
- byName
- constructor
1.6. 用到哪些设计模式
- 工厂模式:Spring 使用工厂模式可以通过
BeanFactory或ApplicationContext创建 bean 对象; - 单例模式:Spring 中 bean 的默认作用域就是 singleton(单例)的;
- 代理模式:Spring AOP 就是基于动态代理的;
- 观察者模式:Spring 事件驱动模型就是观察者模式很经典的一个应用。
ApplicationListener监听器; - 适配器模式:Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配 Controller;
- 模版方法模式:Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式;
- 装饰者模式
1.7. @Transactional 注解哪些情况下会失效?
- 作用在非 public 方法上
- 方法异常被捕获
- 数据库不支持事务(例如 MySQL 的 MyISAM)
- 没开启事务注解
- 同一类中加 @Transactional 方法被无 @Transactional 的方法调用,事务失效
1.8. 常用注解
- bean定义注解
- @component 描述Spring框架中的bean
- @Repository 用于对DAO实现类进行标注
- @Service 用于对业务类进行标注
- @Controller 用于对控制类进行标注
- Spring属性注入
- @Autowired() 自动注入
- @Autowired(required=true) 找到匹配的Bean
- @Qualifier() 可指定Bean的名称。一个接口有多个实现类可指定使用哪种实现
- @Resource() 和 Autowired() 功能相似,@Resource() 是 JDk 自带注解
- 其他输入
- @PostConStruct() 初始化
- @PreDestory() 销毁
- @Scope() 指定作用域
- @Profile() 指定环境bean生效
1.9. bean循环引用如何解决
Spring Bean 的循环依赖问题,是指类A通过构造函数注入类B的实例(或者B中声明的Bean),而类B通过构造函数注入类A的实例(或者A中声明的 Bean),即将类A和类B的bean配置为相互注入,则 Spring IoC 容器会在运行时检测到此循环引用,并引发一个 BeanCurrentlyInCreationException。
- 延迟加载 @Lazy,例如
@Component public class CircularDependencyA { private CircularDependencyB circB; @Autowired public CircularDependencyA(@Lazy CircularDependencyB circB) { this.circB = circB; } } - 在实例变量上使用 @Autowired 注解,让 Spring 决定在合适的时机注入,而非在初始化类的时候就注入。
- 用基于 setter 方法的依赖注入取代基于构造函数的依赖注入来解决循环依赖。
1.10. 动态代理是什么?应用场景?如何实现
动态代理:在运行时,创建目标类,可以调用和扩展目标类的方法。
应用场景:
- 统计每个 api 的请求耗时
- 统一的日志输出
- 校验被调用的 api 是否已经登录和权限鉴定
- Spring的 AOP 功能模块就是采用动态代理的机制来实现切面编程
实现方法:
-
JDK 动态代理
JDK 动态代理只提供接口的代理,不支持类的代理。核心 InvocationHandler 接口和 Proxy 类,InvocationHandler 通过 invoke() 方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy 利用 InvocationHandler 动态创建一个符合某一接口的的实例, 生成目标类的代理对象。 -
CGLib 动态代理
如果代理类没有实现 InvocationHandler 接口,那么 Spring AOP 会选择使用 CGLIB 来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现 AOP。CGLIB 是通过继承的方式做的动态代理,因此如果某个类被标记为 final,那么它是无法使用CGLIB做动态代理的。
1.11. Spring MVC
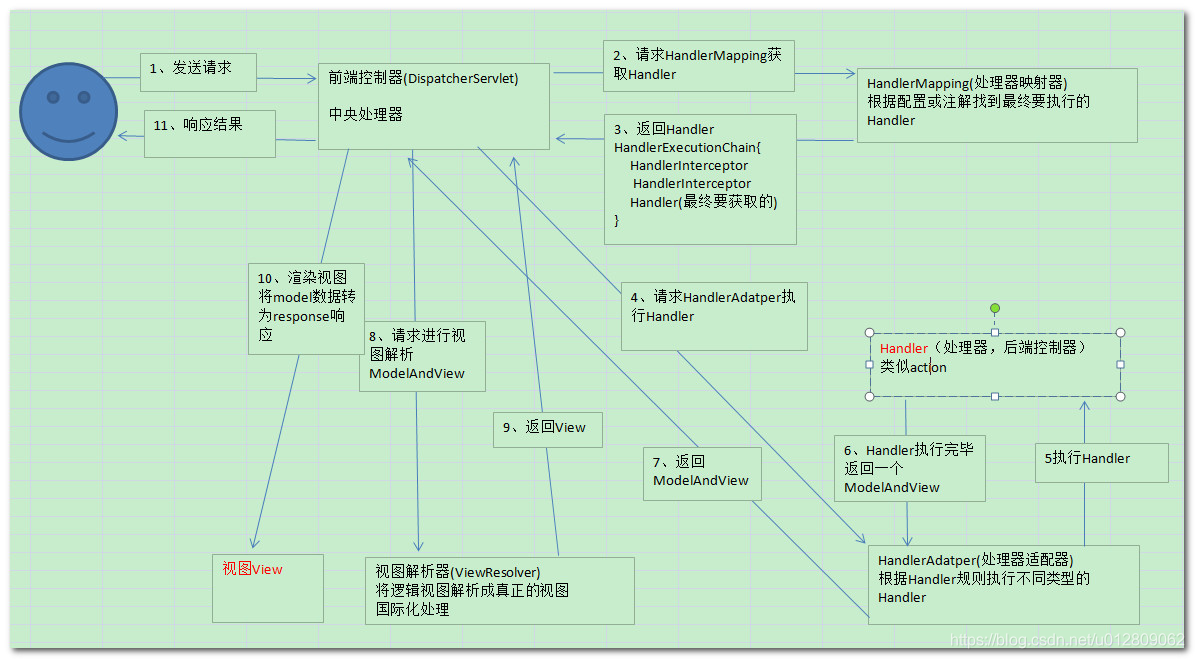
1.11.1. 工作原理
1、 用户发送请求至前端控制器 DispatcherServlet。
2、 DispatcherServlet 收到请求调用 HandlerMapping 处理器映射器。
3、 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给 DispatcherServlet。
4、 DispatcherServlet 调用 HandlerAdapter 处理器适配器。
5、 HandlerAdapter 经过适配调用具体的处理器(Controller,也叫后端控制器)。
6、 Controller 执行完成返回 ModelAndView。
7、 HandlerAdapter 将 Controller 执行结果 ModelAndView 返回给 DispatcherServlet。
8、 DispatcherServlet 将 ModelAndView 传给 ViewReslover 视图解析器。
9、 ViewReslover 解析后返回具体视图 View。
10、DispatcherServlet 根据 View 进行渲染视图(即将模型数据填充至视图中)。
11、 DispatcherServlet 响应用户。
1.11.2. 组件说明
DispatcherServlet:作为前端控制器,整个流程控制的中心,控制其它组件执行,统一调度,降低组件之间的耦合性,提高每个组件的扩展性。
HandlerMapping:通过扩展处理器映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
HandlAdapter:通过扩展处理器适配器,支持更多类型的处理器。
ViewResolver:通过扩展视图解析器,支持更多类型的视图解析,例如:jsp、freemarker、pdf、excel等。
2. Redis
2.1. 支持五种数据类型
- string 字符串 (value最大存储512M)
- hash 哈希(元素最多2^32-1)
- list 列表(元素最多2^32-1)
- set 集合(元素最多2^32-1)
- sorted set 有序集合(同set)
2.2. 单线程但性能依然好原因
- 单线程避免线程切换的消耗(redis6已支持多线程)
- 基于内存,内存读写都很快的
- 使用高性能数据结构,比如hash和跳表
- 使用非阻塞的IO多路复用机制
2.3. 持久化
- RDB:单文件灾难恢复操作简单,性能较高;每隔一段时间持久化,故障可能导致数据丢失
- AOF:日志追加,记录每个命令操作到 aof 文件中一次,宕机保证数据不会丢失,redis-check-aof 工具解决数据一致性问题;持久化文件较大,恢复速度慢
2.4. 过期键删除策略
- 定时删除(创建定时器达到过期时间删除)
- 惰性删除(当获取键时才检查是否删除)
- 定期删除(定期统一检查删除)
redis采用惰性删除和定期删除结合的策略
2.5. 常用客户端
Redisson、Jedis、Lettuce
2.6. 处理过大量的key同一时间过期吗?需要注意什么?
可能导致Redis短时间卡顿现象,量大时还可能出现缓存雪崩。过期时间不要求很精确的话,在时间上加一个随机值,使过期时间分散一些
2.7. Redis 适用场景
- 数据缓存
- 计数器、排行榜
- 集合队列,发布和订阅
2.8. key搜索禁止使用keys命令(key很多时搜索会导致线程堵塞),应该使用scan命令
2.9. 分布式锁
- 定义一个key,value为请求唯一id,设置超时时间,setnx成功即获得锁,删除key要校验value(可用lua脚本把读和删除原子化)
- 使用框架 Redisson
2.10. pipeline
建立管道长链路,一次性处理多个命令,提高吞吐量,但不能保证原子操作
2.11. 缓存穿透、击穿和雪崩
- 缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力;或者查询返回的数据为空仍然进行缓存,过期时间设置较短。
- 缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
- 使用互斥锁(mutex key)SETNX。缓存失效的时候,不立即去load db,而是去set一个mutex key,成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
- 缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
- 在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件
2.12. 主从、哨兵和 cluster 集群
- 主从:分摊读写压力
- 哨兵:高可用
- cluster 集群:兼顾两者
2.13. Redis集群不可用(集群三主三从,至少需要三台机器,互为主从,一台服务器宕机还能用)
- 半数宕机(fail一个主节点需要一半主以上投票通过)
- 某一结点主从全都宕机
2.14. 消息队列实现方式
- 基于异步消息队列 List lpush-brpop(rpush-blpop)
- 使用rpush和lpush操作入队列,lpop和rpop操作出队列
- 当队列为空时,lpop和rpop会一直空轮训,消耗资源;所以引入阻塞读blpop和brpop(b代表blocking),阻塞读在队列没有数据的时候进入休眠状态
- PUB/SUB 订阅/发布模式
- SUBSCRIBE,用于订阅信道
- PUBLISH,向信道发送消息
- UNSUBSCRIBE,取消订阅
- 基于 sorted set 的实现
- zadd 添加带分数元素
- zrange或zrevrange返回有序集合,指定区间的成员。使用0,0区间来获取处于顶部的元素
- zrem 移除元素,消费后移除
- 基于 stream 类型的实现。stream 是redis 5.0后新增的数据结构
2.15. 延迟消息实现
利用 zadd 和 zrangebyscore 来实现存入和读取消息
2.16. Sortes Set(有序列表)实现,压缩列表和跳表
2.16.1. 压缩列表 ziplist
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
2.16.2. 跳表 skiplist
- 一种基于有序链表的扩展,跳表会维护多个索引链表和原链表
- 查找次数近似于层数,时间复杂度为O(logn),插入、删除也为 O(logn)
- 跳表是一种随机化的数据结构(通过抛硬币来决定插入层数)
- 空间复杂度为 O(n)
2.17. 一致性哈希和哈希槽
2.17.1. 一致性哈希(一致性hash是一个0-2^32的闭合圆)
- 用于解决分布式缓存系统中的数据选择节点存储问题
和数据选择节点读取问题
以及在增删节点后减少数据缓存的消失范畴,防止雪崩的发生。 - 顺时针找到归属的节点
2.17.2. 哈希槽(redis cluster一共有2^14=16384个槽)
- redis cluster集群没有采用一致性哈希方案,而是采用数据分片中的哈希槽来进行数据存储与读取的。
- 根据CRC-16(key)384的值来判断属于哪个槽区,从而判断该key属于哪个节点
2.18. 使用场景
- 会话缓存(Session Cache),是 Redis 最常使用的一种情景
- 全页缓存(FPC)
- 用作网络版集合和队
- 排行榜和计数器,Redis 在内存中对数字递增、递减的操作实现的非常好。Set 和 Sorted Set 使得我们在执行这些操作的时候非常简单
- 发布和订阅
3. MQ
3.1. MQ 作用
- 应用解耦:生产和消费分离,甚至可以多个消费者
- 异步处理:比回调请求获取数据更快,性能更高
- 流量削峰:限制最大入库数据量,不超过系统所能承受的最大请求量,避免数据库压力过大
3.2. 缺陷
- 系统可用性降低,因为MQ可能宕机:以前只要担心系统的问题,现在还要考虑 MQ 挂掉的问题,MQ 挂掉,所关联的系统都会无法提供服务;
- 复杂度变高:要考虑消息丢失、消息重复消费等问题;
- 一致性问题:多个 MQ 消费系统,部分成功,部分失败,要考虑事务问题。
3.3. 常用MQ
- ActiveMQ:支持万级的吞吐量,较成熟完善;官方更新迭代较少,社区的活跃度不是很高,有消息丢失的情况。
- RabbitMQ:延时低,微妙级延时,社区活跃度高,bug 修复及时,而且提供了很友善的后台界面;用 Erlang 语言开发,只熟悉 Java 的无法阅读源码和自行修复 bug。
- RocketMQ:阿里维护的消息中间件,可以达到十万级的吞吐量,支持分布式事务。
- Kafka:分布式的中间件,最大优点是其吞吐量高,一般运用于大数据系统的实时运算和日志采集的场景,功能简单,可靠性高,扩展性高;缺点是可能导致重复消费。
3.4. 使用场景
- 秒杀抢购场景流量削峰,入队列,超过最大长度丢弃
- 异步处理和解耦。如注册用户发邮件验证,提交MQ由业务模块消费,同时将两个模块解耦
- 日志采集,常用 kafka
- 消息通讯。点对点或发布/订阅模式
3.5. 高可用方法
- RabbitMQ 镜像集群,多节点复制 queue 节点信息
- ActiveMQ 部署主从热备
- RocketMQ 有多 master 多 slave 异步复制模式和多 master 多 slave 同步双写模式支持集群部署模式
3.6. 如何保证消息不被重复消费
- 消息带上全局唯一id,缓存redis校验或入库校验
- 消息入库可用数据库唯一键约束
3.7. 如何保证消息不丢失?
- 生产者丢失:主流的 MQ 都有确认机制或事务机制,可以保证生产者将消息送达到 MQ。如 RabbitMQ 就有事务模式和 confirm 模式。
- MQ丢失:MQ 成功接收消息内部处理出错、宕机等情况。解决办法:开启 MQ 的持久化配置。
- 消费者丢失:采用消息自动确认模式,消费者取到消息未处理挂掉了。 解决办法:改为手动确认模式,消费者成功消费消息再确认。
3.8. 如何保证消息的顺序性
- 生产者保证消息入队的顺序;
- MQ 本身是一种先进先出的数据接口,将同一类消息,发到同一个 queue 中,保证出队是有序的;
- 避免多消费者并发消费同一个 queue 中的消息。
3.9. 消息大量堆积如何处理
消息的积压来自于两方面:要么发送快了,要么消费变慢了。
- 扩容消费端的实例数提高消费能力。或者启用多个消费者,并发接收消息消费;
- 另起一套MQ环境给当前业务使用,堆积消息的MQ环境自己消费,不要影响当前业务;
- 如果短时间内没有服务器资源扩容,没办法的办法是将系统降级,通过关闭某些不重要的业务,减少发送的数据量,最低限度让系统还能正常运转,服务重要业务;
- 监控发现,产生和消费消息的速度没什么变化,出现消息积压的情况,检查是有消费失败反复消费的情况;
- 监控发现,消费消息的速度变慢,检查消费实例,日志中是否有大量消费错误、消费线程是否死锁、是否卡在某些资源上。

一站式 AI 云服务平台
更多推荐


 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)