
MySQL数据库
建库、建表、数据类型、修改表、常用函数、约束、索引、事务、视图、管理。
目录
1)创建数据库
在MySQL里进入“新建查询”,输入
//数据库名称
CREATE DATABASE my_new_database
//字符集
CHARACTER SET utf8mb4
//排序规则
COLLATE utf8mb4_unicode_ci;2)查看、删除数据库
- 显示数据库:
SHOW DATABASES - 显示创建数据库语句:
//在创建数据库的时候,为了规避关键字,可以使用反引号`` SHOW CREATE DATABASE (`name`) - 删除数据库:
DROP DATABASE [IF EXISTS] (name)
3)备份恢复数据库
备份命令要在命令行下进行:
- 备份特定表:
mysqldump -u 用户名 -p 数据库名 表名1 表名2 > 表备份.sql - 备份单个数据库:
mysqldump -u 用户名 -p 数据库名 > 备份文件.sql - 备份所有数据库
mysqldump -u 用户名 -p --all-databases > 完整备份.sql
恢复命令要在MySQL命令行中进行:
- 恢复完整备份:
mysql -u 用户名 -p 数据库名 < 备份文件.sql - 从完整备份中恢复单个数据库:
mysql -u 用户名 -p --one-database 数据库名 < 完整备份.sql
4)创建表
语法:
CREATE TABLE _name(
field1 datatype,
field2 datatype,
field3 datatype
)character set collate engine
//field:制定列名
//datatype:指定列类型(字段类型)
//character set 字符集
//collate 校对规则
//engine 引擎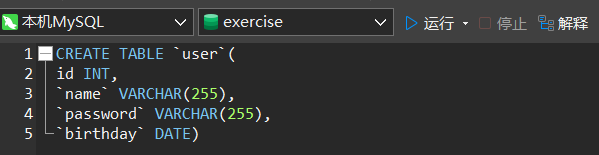
5)MySQL数据类型
MySQL数据类型
├── 数值类型
│ ├── 整数类型
│ │ ├── TINYINT (1字节)
│ │ ├── SMALLINT (2字节)
│ │ ├── MEDIUMINT (3字节)
│ │ ├── INT/INTEGER (4字节)
│ │ └── BIGINT (8字节)
│ │
│ └── 小数类型
│ ├── 精确小数
│ │ └── DECIMAL[M,D]
│ │
│ └── 近似小数
│ ├── FLOAT (单精度 4字节)
│ └── DOUBLE (双精度 8字节)
│
├── 字符串类型
│ ├── 文本字符串
│ │ ├── CHAR (定长 0-255)
│ │ ├── VARCHAR (变长 0-65535(2^16-1))
│ │ ├── TINYTEXT
│ │ ├── TEXT(0-65535(2^16-1))
│ │ ├── MEDIUMTEXT
│ │ └── LONGTEXT(0-2^32-1)
│ │
│ └── 二进制字符串
│ ├── BINARY (定长)
│ ├── VARBINARY (变长)
│ ├── TINYBLOB
│ ├── BLOB(0-2^16-1)
│ ├── MEDIUMBLOB
│ └── LONGBLOB(0-2^32-1)
│
├── 日期时间类型
│ ├── DATE (年月日 YYYY-MM-DD)
│ ├── TIME (时分秒 HH:MM:SS)
│ ├── DATETIME (年月日时分秒 YYYY-MM-DD HH:MM:SS)
│ ├── TIMESTAMP (时间戳)
│ └── YEAR (年份)
│
├── 位类型
│ └── BIT (位字段)
│
└── 特殊类型
├── ENUM (枚举)
├── SET (集合)
├── JSON (JSON数据)
└── GEOMETRY (空间数据)
├── POINT
├── LINESTRING
├── POLYGON
├── MULTIPOINT
├── MULTILINESTRING
├── MULTIPOLYGON
└── GEOMETRYCOLLECTION6)数据类型之整型
无符号的最大值是有符号最大值的*2 - 1。
-
TINYINT
-
存储空间:1字节
-
有符号范围:-128 到 127
-
无符号范围:0 到 255
-
常用于小范围数值或布尔值表示
-
-
SMALLINT
-
存储空间:2字节
-
有符号范围:-32,768 到 32,767
-
无符号范围:0 到 65,535
-
-
MEDIUMINT
-
存储空间:3字节
-
有符号范围:-8,388,608 到 8,388,607
-
无符号范围:0 到 16,777,215
-
-
INT (INTEGER)
-
存储空间:4字节
-
有符号范围:-2,147,483,648 到 2,147,483,647
-
无符号范围:0 到 4,294,967,295
-
最常用的整型类型
-
-
BIGINT
-
存储空间:8字节
-
有符号范围:-9,223,372,036,854,775,808 到 9,223,372,036,854,775,807
-
无符号范围:0 到 18,446,744,073,709,551,615
-
用于极大整数
-
CREATE TABLE zheng_xing(
#使用unsigned修饰则为无符号
id01 INT UNSIGNED,
#不修饰的话默认为有符号(包含负数)
id02 INT)7)数据类型之bit
BIT 是 MySQL 中用于存储位值的数据类型,适合存储二进制标志位或位掩码。
基本语法:
BIT[(M)]- M表示位数(1-64),默认为1。例如BIT,BIT(8),BIT(64)。
存储空间: 1byte = 8bit
-
1-8位:占用1字节
-
9-16位:占用2字节
-
17-24位:占用3字节
-
以此类推,最多8字节(64位)
取值范围:
-
BIT(1):0或1
-
BIT(8):0到255 (2^8-1)
-
BIT(64):0到2^64-1
与TINYINT比较:
| 特性 | BIT(8) | TINYINT UNSIGNED |
|---|---|---|
| 存储空间 | 1字节 | 1字节 |
| 取值范围 | 0-255 | 0-255 |
| 语义 | 位集合 | 数值 |
| 位操作效率 | 更高 | 较低 |
| 数值运算 | 需要转换 | 直接支持 |
BIT类型在需要位级操作时更高效,而TINYINT在需要数值运算时更方便。
8)数据类型之小数
MySQL 提供了多种存储小数的数据类型,主要分为近似小数类型和精确小数类型两大类。
1)近似小数类型(浮点数)
FLOAT:
FLOAT(M,D) -- 单精度浮点数特点:
-
4字节存储
-
约7位有效数字
-
有精度损失,计算速度快
DOUBLE:
DOUBLE(M, D) -- 双精度浮点数特点:
-
8字节存储
-
约15位有效数字
-
比FLOAT精度高,仍有精度损失
2)精确小数类型(固定精度)
DECIMAL:
DECIMAL(M, D) -
M:总位数(精度),范围 1-65 -
D:小数点后的位数(标度),范围 0-30 且 D ≤ M
特点:
-
精确存储,无精度损失
-
适合财务数据等需要精确计算的场景
-
存储空间可变:每9位数字占用4字节,剩余位数需要额外空间
| 类型 | 存储空间 | 精确性 | 适用场景 |
|---|---|---|---|
| DECIMAL | 可变 | 精确 | 财务计算、货币值 |
| FLOAT | 4字节 | 近似 | 科学数据、不需要精确的值 |
| DOUBLE | 8字节 | 近似 | 需要更大范围的科学计算 |
9)数据类型之字符串
1. 定长字符串类型
CHAR:
-
语法:
CHAR(M) -
特点:
-
固定长度,M 范围为 0-255 个字符
-
存储时总是占用 M 个字符的空间(不足用空格填充)
-
检索时会自动删除尾部空格
-
-
适用场景: 存储长度固定的数据(如国家代码、性别、MD5哈希值等)
CREATE TABLE users (
gender CHAR(1) -- 存储 'M' 或 'F'
);2. 变长字符串类型
VARCHAR:
-
语法:
VARCHAR(M) -
特点:
-
可变长度,M 范围为 0-65,535 个字符(实际限制受行大小限制)
-
只占用实际数据长度+1或+2字节的长度前缀
-
不会自动删除尾部空格
-
-
适用场景: 存储长度变化较大的数据(如用户名、地址等)
utf8编码最大21844(65535-3)/3字符,有1-3个字符用于记录大小。
CREATE TABLE products (
name VARCHAR(100) -- 存储产品名称
);字符串使用细节:
1)
char(4)、varchar(4):这个4都表示字符数,不是字节数,不管是中文还是字母都是放4个,按字符计算。
2)
char(4)是定长,即时插入'aa',也会占用分配的4个字符的空间
varchar(4)是变长,,如果插入了'aa',实际占用空间大小并不是4个字符,而是按照实际占用空间来分配(varchar本身还需要占用1-3个字节来记录存放内容长度)
3)
如何选择char、varchar?
如果定长选char,比如身份证、手机号。
不定长选varchar,文章等。
查询速度:char>varchar
4)
在存放文本时,也可以使用Text数据类型,Text没有默认值,大小为0-2^16字节。MEDIUMTEXT为2^24,LONGTEXT为2^32。
10)数据类型之日期
DATE:
-
格式:
YYYY-MM-DD -
范围: '1000-01-01' 到 '9999-12-31'
-
存储空间: 3字节
-
用途: 仅存储日期,不包含时间部分
CREATE TABLE events (
event_date DATE -- 存储如 '2023-05-15'
);TIME:
-
格式:
HH:MM:SS或HHH:MM:SS -
范围: '-838:59:59' 到 '838:59:59'
-
存储空间: 3字节
-
用途: 存储时间或时间间隔
CREATE TABLE schedules (
start_time TIME -- 存储如 '14:30:00' 或 '120:00:00'(120小时)
);DATETIME:
-
格式:
YYYY-MM-DD HH:MM:SS -
范围: '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59'
-
存储空间: 8字节
-
用途: 存储日期和时间组合
CREATE TABLE orders (
order_time DATETIME -- 存储如 '2023-05-15 14:30:45'
);TIMESTAMP:
-
格式:
YYYY-MM-DD HH:MM:SS -
范围: '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' UTC
-
存储空间: 4字节
-
特点:
-
自动转换为UTC存储,检索时转换回当前时区
-
可自动初始化和更新(见下文)
-
受2038年问题限制
-
CREATE TABLE logs (
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);11)修改表
1.添加列
ALTER TABLE 表名 ADD COLUMN 列名 数据类型 [约束条件] [FIRST|AFTER 现有列名];-- 在users表末尾添加age列
ALTER TABLE users ADD COLUMN age INT;
-- 在users表的username列后添加email列
ALTER TABLE users ADD COLUMN email VARCHAR(100) AFTER username;
-- 在users表开头添加id列
ALTER TABLE users ADD COLUMN id INT FIRST;2.删除列
ALTER TABLE 表名 DROP COLUMN 列名;-- 删除users表中的age列
ALTER TABLE users DROP COLUMN age;3.修改列定义
ALTER TABLE 表名 MODIFY COLUMN 列名 新数据类型 [约束条件];-- 修改users表的email列长度为150
ALTER TABLE users MODIFY COLUMN email VARCHAR(150);重命名列并修改定义:
ALTER TABLE 表名 CHANGE COLUMN 旧列名 新列名 数据类型 [约束条件];-- 将users表的phone列改名为mobile并修改数据类型
ALTER TABLE users CHANGE COLUMN phone mobile VARCHAR(20);4.修改表选项
ALTER TABLE 表名 表选项;5.重命名表
ALTER TABLE 旧表名 RENAME TO 新表名;
-- 或
RENAME TABLE 旧表名 TO 新表名;-- 将users表重命名为customers
ALTER TABLE users RENAME TO customers;
-- 或
RENAME TABLE users TO customers;6.多组合操作
ALTER TABLE users
ADD COLUMN age INT AFTER email,
MODIFY COLUMN username VARCHAR(50) NOT NULL,
DROP COLUMN old_column;7.查看表结构
DESCRIBE 表名;
-- 或
SHOW CREATE TABLE 表名;12)insert语句
INSERT语句用于向表中插入新行。
INSERT INTO 表名 (列1, 列2, 列3, ...)
VALUES (值1, 值2, 值3, ...);-- 向users表插入一行数据
INSERT INTO users (username, email, created_at)
VALUES ('john_doe', 'john@example.com', NOW());
-- 插入多行数据
INSERT INTO products (name, price, stock)
VALUES
('Laptop', 999.99, 50),
('Phone', 699.99, 100),
('Tablet', 399.99, 75);注意事项:
- 插入的数据应与字段的数据类型相同
- 数据的长度应在列的的规定范围内
- 在values中列出的数据位置必须与被加入的列的排列位置相对应
- 字符和日期类数据应包含在单引号中
- 列可以插入空值,前提是该字段允许为空 insert into table value(null)
- insert into () values ()()()形式添加多条记录
- 如果是给表中所有字段添加数据,可以前面不写字段名称
- 字段值不赋值时会使用默认值,如果不存在默认值就会报错
13)update语句
UPDATE 语句用于修改 MySQL 数据库表中的现有记录。
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
//table_name:表名
//set:指定要更新的列及其新值
//where:指定记录哪些需要更新(可选,但通常很重要)
//condition:确定哪些行将被更新的条件WHERE 子句非常重要:如果不加 WHERE 条件,将更新表中的所有行
更新单列:
UPDATE customers SET email = 'new.email@example.com' WHERE customer_id = 1;更新多列:
UPDATE employees SET salary = 50000, department = 'Marketing' WHERE employee_id = 101;使用表达式更新:
UPDATE employees SET salary = 50000, department = 'Marketing' WHERE employee_id = 101;更新所有行(慎用):
UPDATE settings SET last_updated = NOW();
14)delete语句
DELETE 语句用于从 MySQL 数据库表中删除记录。
DELETE FROM table_name
WHERE condition;delete语句不能删除某一列的值(可使用update设为 null 或 '')
使用delete语句仅删除记录,不删除表本身。若要删除表,要用drop table 语句。
15)select语句
SELECT 是 MySQL 中最重要、最常用的语句,用于从数据库中查询数据。
SELECT
[DISTINCT] (column1, column2, ...)/(*)
FROM
table_name
[WHERE condition]
[GROUP BY column_name(s)]
[HAVING condition]
[ORDER BY column_name(s) [ASC|DESC]]
[LIMIT offset, row_count];
- distinct表示是否删除重复数据,要每列字段都相同才去重
- *表示查询所有列
- column指定列名
- from指查询哪张表
order by子句:
-- 查询最贵的 10 个商品(降序)
SELECT * FROM products
ORDER BY price DESC
LIMIT 10;
-- 按部门升序,同部门按入职时间降序
SELECT name, department, hire_date
FROM employees
ORDER BY department ASC, hire_date DESC;
-- 按名字长度排序,相同长度再按字母顺序
SELECT * FROM customers
ORDER BY LENGTH(name), name;| 功能 | 写法 |
|---|---|
| 升序(默认) | ORDER BY column 或 ORDER BY column ASC |
| 降序 | ORDER BY column DESC |
| 多列排序 | ORDER BY col1, col2 DESC |
| 按函数排序 | ORDER BY LENGTH(name) |
| 控制 NULL 顺序 | ORDER BY IF(column IS NULL, 0, 1), column |
| 自定义排序 | ORDER BY FIELD(status, 'active', 'pending') |
| 随机排序 | ORDER BY RAND() |
16)where子句中的运算符
1.比较运算符
| 运算符 | 说明 | 示例 |
|---|---|---|
= |
等于 | WHERE age = 25 |
<> 或 != |
不等于 | WHERE status <> 'inactive' |
< |
小于 | WHERE price < 100 |
> |
大于 | WHERE score > 80 |
<= |
小于等于 | WHERE quantity <= 10 |
>= |
大于等于 | WHERE salary >= 5000 |
<=> |
NULL 安全的等于(可比较 NULL) | WHERE name <=> NULL |
IS NULL |
判断是否为 NULL | WHERE email IS NULL |
IS NOT NULL |
判断是否不为 NULL | WHERE phone IS NOT NULL |
BETWEEN ... AND ... |
在某个范围内(包含边界) | WHERE age BETWEEN 18 AND 30 |
NOT BETWEEN ... AND ... |
不在某个范围内 | WHERE price NOT BETWEEN 50 AND 100 |
IN (...) |
在指定列表中 | WHERE id IN (1, 3, 5) |
NOT IN (...) |
不在指定列表中 | WHERE status NOT IN ('pending', 'cancelled') |
2.逻辑运算符
| 运算符 | 说明 | 示例 |
|---|---|---|
AND 或 && |
逻辑与(同时满足) | WHERE age > 18 AND status = 'active' |
OR |
逻辑或(满足其一) | WHERE role = 'admin' OR role = 'manager' |
NOT 或 ! |
逻辑非(取反) | WHERE NOT (age < 18) |
XOR |
逻辑异或(仅一个条件为真) | WHERE is_student XOR is_employed |
3.模糊匹配运算符
| 运算符 | 说明 | 示例 |
|---|---|---|
LIKE |
模糊匹配(% 任意字符,_ 单个字符) |
WHERE name LIKE 'J%'(以 J 开头) |
NOT LIKE |
不匹配模式 | WHERE email NOT LIKE '%@gmail.com' |
REGEXP 或 RLIKE |
正则表达式匹配 | WHERE name REGEXP '^A.*n$'(以 A 开头,n 结尾) |
NOT REGEXP |
正则表达式不匹配 | WHERE phone NOT REGEXP '^[0-9]{10}$' |
4.其他
| 运算符 | 说明 | 示例 |
|---|---|---|
DIV |
整数除法 | WHERE value DIV 2 = 5 |
& |
位与 | WHERE flags & 1 = 1 |
<< |
左移位 | WHERE num << 1 = 8 |
>> |
右移位 | WHERE num >> 1 = 4 |
+ |
加法 | WHERE age + 5 > 25 |
- |
减法 | WHERE price - discount < 50 |
* |
乘法 | WHERE salary * 12 > 60000 |
/ |
除法 | WHERE total / quantity > 10 |
% 或 MOD |
取模(求余数) | WHERE id % 2 = 0(偶数) |
17)聚合函数
1.count() 计数
计算行数或非 NULL 值的数量。
COUNT(*) -- 计算所有行(包括NULL)
COUNT(column) -- 计算某列非NULL的行数
COUNT(DISTINCT column) -- 计算某列去重后的数量-- 计算 users 表的总行数
SELECT COUNT(*) FROM users;
-- 计算 email 列非 NULL 的数量
SELECT COUNT(email) FROM users;
-- 计算不同城市的数量(去重)
SELECT COUNT(DISTINCT city) FROM customers;2.sum() 求和
计算某列数值的总和(忽略 NULL)。
SUM(column)
SUM(DISTINCT column) -- 去重后求和-- 计算订单总金额
SELECT SUM(amount) FROM orders;
-- 计算不同产品的销售总额(去重)
SELECT SUM(DISTINCT price) FROM products;3.avg() 平均值
计算某列的平均值(忽略 NULL)。
AVG(column)
AVG(DISTINCT column) -- 去重后计算平均值-- 计算员工的平均工资
SELECT AVG(salary) FROM employees;
-- 计算不同产品的平均价格(去重)
SELECT AVG(DISTINCT price) FROM products;4.max() 最大值
返回某列的最大值(适用于数字、日期、字符串)。
MAX(column)-- 查找最高工资
SELECT MAX(salary) FROM employees;
-- 查找最近注册的用户
SELECT MAX(register_date) FROM users;
-- 查找字母排序最大的名字
SELECT MAX(name) FROM customers; -- 'Z' 会排在 'A' 前面5.min() 最小值
返回某列的最小值(适用于数字、日期、字符串)。
MIN(column)-- 查找最低价格
SELECT MIN(price) FROM products;
-- 查找最早的订单日期
SELECT MIN(order_date) FROM orders;
-- 查找字母排序最小的名字
SELECT MIN(name) FROM customers; -- 'A' 会排在 'Z' 前面18)分组统计
按指定列分组,并对每组数据进行聚合计算(如 COUNT, SUM, AVG 等)。
SELECT 列1, 列2, 聚合函数(列3)
FROM 表名
WHERE 条件
GROUP BY 列1, 列2;-- 按部门统计员工数量
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department;
-- 按城市和性别统计用户数量
SELECT city, gender, COUNT(*) AS user_count
FROM users
GROUP BY city, gender;
-- 计算每个产品的销售总额
SELECT product_id, SUM(amount) AS total_sales
FROM orders
GROUP BY product_id;having------分组过滤结果
对
GROUP BY分组后的数据进行筛选(类似于WHERE,但用于聚合值)。SELECT 列1, 聚合函数(列2) FROM 表名 GROUP BY 列1 HAVING 聚合函数(列2) 条件;-- 筛选员工数超过 5 人的部门 SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department HAVING COUNT(*) > 5; -- 筛选平均工资超过 8000 的部门 SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department HAVING AVG(salary) > 8000; -- 筛选总销售额超过 10000 的产品 SELECT product_id, SUM(amount) AS total_sales FROM orders GROUP BY product_id HAVING SUM(amount) > 10000;
having与where对比:
| 特性 | WHERE | HAVING |
|---|---|---|
| 执行时机 | 在分组前过滤数据(原始数据) | 在分组后过滤数据 |
| 能否使用聚合函数 | ❌ 不能 | ✅ 可以 |
| 能否使用普通列 | ✅ 可以 | ✅ 可以(但通常用于聚合列) |
| 是否依赖 GROUP BY | ❌ 不依赖 | ✅ 依赖(除非聚合未分组) |
19)字符串函数
字符串长度与比较函数:
LENGTH(str):返回字符串的字节长度
SELECT LENGTH('MySQL'); → 5CHAR_LENGTH(str) / CHARACTER_LENGTH(str):返回字符串的字符数
SELECT CHAR_LENGTH('数据库'); → 3STRCMP(expr1, expr2):比较两个字符串,返回0(相等)、1(expr1>expr2)或-1(expr1<expr2)
SELECT STRCMP('text', 'text2'); → -1字符串连接函数:
CONCAT(str1, str2, ...):连接多个字符串
SELECT CONCAT('My', 'SQL'); → 'MySQL'CONCAT_WS(separator, str1, str2, ...):用指定分隔符连接字符串
SELECT CONCAT_WS(',', 'John', 'Doe'); → 'John,Doe'大小写转换函数:
LOWER(str) / LCASE(str):转换为小写
SELECT LOWER('MySQL'); → 'mysql'UPPER(str) / UCASE(str):转换为大写
SELECT UPPER('mysql'); → 'MYSQL'字符串截取与提取函数:
SUBSTRING(str, pos, len) / SUBSTR(str, pos, len) / MID(str, pos, len):从位置pos开始截取len个字符
SELECT SUBSTRING('MySQL', 3, 2); → 'SQ'LEFT(str, len):从左开始截取指定长度
SELECT LEFT('MySQL', 2); → 'My'RIGHT(str, len):从右开始截取指定长度
SELECT RIGHT('MySQL', 3); → 'SQL'字符串查找函数:
LOCATE(substr, str, pos) / POSITION(substr IN str):返回子串位置(从1开始),找不到返回0
SELECT LOCATE('SQL', 'MySQL'); → 3INSTR(str, substr):类似LOCATE但参数顺序相反
SELECT INSTR('MySQL', 'SQL'); → 3FIND_IN_SET(str, strlist):在逗号分隔的列表中查找字符串
SELECT FIND_IN_SET('b', 'a,b,c,d'); → 2字符串替换与修改函数:
REPLACE(str, from_str, to_str):替换字符串中的子串
SELECT REPLACE('www.mysql.com', 'w', 'W'); → 'WWW.mysql.com'INSERT(str, pos, len, newstr):在指定位置插入/替换字符串
SELECT INSERT('Quadratic', 3, 4, 'What'); → 'QuWhattic'TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str):去除两端空格或指定字符
SELECT TRIM(' MySQL '); → 'MySQL'
SELECT TRIM(LEADING 'x' FROM 'xxxMySQLxxx'); → 'MySQLxxx'LTRIM(str) / RTRIM(str):去除左/右空格
SELECT LTRIM(' MySQL'); → 'MySQL'字符串填充函数:
LPAD(str, len, padstr):左侧填充到指定长度
SELECT LPAD('MySQL', 10, '*'); → '*MySQL'RPAD(str, len, padstr):右侧填充到指定长度
SELECT RPAD('MySQL', 10, '*'); → 'MySQL*'格式化与转换函数:
FORMAT(X, D):数字格式化
SELECT FORMAT(12345.6789, 2); → '12,345.68'HEX(str) / UNHEX(str):字符串与十六进制转换
SELECT HEX('MySQL'); → '4D7953514C'BIN(n) / OCT(n) / HEX(n):数字转换为二进制/八进制/十六进制字符串
SELECT BIN(12); → '1100'20)数学函数
基本数学运算函数:
ABS(X):返回X的绝对值
SELECT ABS(-32); → 32SIGN(X):返回X的符号:-1(负数)、0(零)或1(正数)
SELECT SIGN(-5); → -1MOD(N,M) 或 %:返回N除以M的余数
SELECT MOD(15,4); → 3
SELECT 15 % 4; → 3CEIL(X) / CEILING(X):向上取整
SELECT CEIL(3.2); → 4FLOOR(X):向下取整
SELECT FLOOR(3.7); → 3ROUND(X, D):四舍五入,D指定小数位数
SELECT ROUND(3.14159, 2); → 3.14TRUNCATE(X, D):截断数字,保留D位小数
SELECT TRUNCATE(3.14159, 2); → 3.14指数与对数函数:
POW(X,Y) / POWER(X,Y):返回X的Y次方
SELECT POW(2,3); → 8SQRT(X):返回X的平方根
SELECT SQRT(25); → 5EXP(X):返回e的X次方
SELECT EXP(1); → 2.718281828459045LN(X) / LOG(X):返回X的自然对数(以e为底)
SELECT LN(2.718281828459045); → 1.0LOG10(X):返回X的常用对数(以10为底)
SELECT LOG10(100); → 2LOG2(X):返回X的以2为底的对数
SELECT LOG2(8); → 3随机数函数:
RAND() / RAND(N):返回0到1之间的随机浮点数,N为种子值
SELECT RAND(); → 0.8407172561533891
SELECT RAND(5); → 0.406135472887009 (固定种子产生固定随机数)21)日期函数
获取当前日期和时间:
NOW() / SYSDATE() / CURRENT_TIMESTAMP():返回当前日期和时间
SELECT NOW(); → '2023-11-15 14:30:45'CURDATE() / CURRENT_DATE():返回当前日期
SELECT CURDATE(); → '2023-11-15'CURTIME() / CURRENT_TIME():返回当前时间
SELECT CURTIME(); → '14:30:45'UTC_DATE() / UTC_TIME() / UTC_TIMESTAMP():返回UTC日期/时间/时间戳
SELECT UTC_TIMESTAMP(); → '2023-11-15 06:30:45' (UTC时间)日期时间计算函数:
DATE_ADD(date, INTERVAL expr unit) / ADDDATE(date, INTERVAL expr unit):日期加法
SELECT DATE_ADD('2023-11-15', INTERVAL 1 MONTH); → '2023-12-15'DATE_SUB(date, INTERVAL expr unit) / SUBDATE(date, INTERVAL expr unit):日期减法
SELECT DATE_SUB('2023-11-15', INTERVAL 1 WEEK); → '2023-11-08'ADDTIME(expr1, expr2):时间加法
SELECT ADDTIME('14:30:45', '02:15:30'); → '16:46:15'SUBTIME(expr1, expr2):时间减法
SELECT SUBTIME('14:30:45', '02:15:30'); → '12:15:15'DATEDIFF(expr1, expr2):计算两个日期之间的天数差(expr1 - expr2)
SELECT DATEDIFF('2023-11-20', '2023-11-15'); → 5TIMEDIFF(expr1, expr2):计算两个时间之间的差值
SELECT TIMEDIFF('14:30:45', '10:15:30'); → '04:15:15'TIMESTAMPDIFF(unit, datetime1, datetime2):计算两个日期时间的差值,返回指定单位的结果
SELECT TIMESTAMPDIFF(MONTH, '2023-01-01', '2023-11-15'); → 1022)加密函数
MySQL提供了一系列加密和哈希函数,用于数据安全、密码存储和数据保护。以下是MySQL中常用的加密函数分类详解:
哈希函数:
MD5(str):计算字符串的MD5 128位哈希值(32位十六进制字符串)
安全性较低,不建议用于密码存储
SELECT MD5('password'); → '5f4dcc3b5aa765d61d8327deb882cf99'SHA1(str) / SHA(str):计算字符串的SHA1 160位哈希值(40位十六进制字符串)
比MD5更安全但仍不够强
SELECT SHA1('password'); → '5baa61e4c9b93f3f0682250b6cf8331b7ee68fd8'SHA2(str, hash_length):计算SHA2哈希系列(SHA-224, SHA-256, SHA-384, SHA-512)
参数hash_length可以是224、256、384或512
推荐用于安全应用
SELECT SHA2('password', 256); → '5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8'PASSWORD(str):MySQL特有的密码哈希函数(用于mysql.user表)
不同MySQL版本算法不同
不建议在应用中使用
SELECT PASSWORD('password'); → '*2470C0C06DEE42FD1618BB99005ADCA2EC9D1E19'加密/解密函数:
AES_ENCRYPT(str, key_str):使用AES算法加密字符串(高级加密标准)
返回二进制数据
SELECT AES_ENCRYPT('secret', 'encryption_key'); → [二进制数据]AES_DECRYPT(crypt_str, key_str):解密AES_ENCRYPT加密的数据
SELECT AES_DECRYPT(AES_ENCRYPT('secret', 'encryption_key'), 'encryption_key'); → 'secret'ENCODE(str, pass_str):使用pass_str作为密码加密str
安全性较低,已弃用
SELECT ENCODE('secret', 'password'); → [二进制数据]DECODE(crypt_str, pass_str):解密ENCODE加密的数据
SELECT DECODE(ENCODE('secret', 'password'), 'password'); → 'secret'DES_ENCRYPT(str[, {key_num | key_str}]):使用DES算法加密(需要SSL支持)
SELECT DES_ENCRYPT('secret', 'password'); → [二进制数据]DES_DECRYPT(crypt_str[, key_str]):解密DES_ENCRYPT加密的数据
SELECT DES_DECRYPT(DES_ENCRYPT('secret', 'password'), 'password'); → 'secret'随机值生成:
RAND():生成0到1之间的随机浮点数
SELECT RAND(); → 0.8407172561533891RAND(N):使用种子N生成可重复的随机数序列
SELECT RAND(5); → 0.406135472887009UUID():生成通用唯一标识符(UUID)
格式:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
SELECT UUID(); → 'a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11'SELECT UUID(); → 'a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11'UUID_SHORT():生成64位无符号整数的UUID
SELECT UUID_SHORT(); → 9239578384825876523)流程控制函数
MySQL提供了一系列流程控制函数,用于在SQL查询中实现条件逻辑和流程控制。这些函数可以极大地增强SQL的表达能力,使查询更加灵活和强大。
条件判断函数:
1. IF函数
语法:IF(expr1, expr2, expr3)
- 如果expr1为TRUE(expr1 ≠ 0且expr1 ≠ NULL),返回expr2,否则返回expr3
- 类似于其他编程语言中的三元运算符
SELECT IF(1 > 2, 'true', 'false'); -- 返回 'false' SELECT IF(2 > 1, 'true', 'false'); -- 返回 'true' SELECT IF(NULL, 'not null', 'null'); -- 返回 'null'2. IFNULL函数
语法:IFNULL(expr1, expr2)
如果expr1不为NULL,返回expr1,否则返回expr2
SELECT IFNULL(NULL, 'default value'); -- 返回 'default value' SELECT IFNULL('not null', 'default'); -- 返回 'not null'3. NULLIF函数
语法:NULLIF(expr1, expr2)
- 如果expr1 = expr2,返回NULL,否则返回expr1
- 用于避免除零错误等场景
SELECT NULLIF(1, 1); -- 返回 NULL SELECT NULLIF(1, 2); -- 返回 124)分页查询
MySQL 分页查询是数据库操作中非常常见的需求,主要用于处理大量数据时的分批显示。
SELECT * FROM table_name LIMIT offset, row_count;
-- 或者
SELECT * FROM table_name LIMIT row_count OFFSET offset;-- 获取前10条记录
SELECT * FROM users LIMIT 10;
-- 获取第11-20条记录(第二页,每页10条)
SELECT * FROM users LIMIT 10, 10;
-- 或者
SELECT * FROM users LIMIT 10 OFFSET 10;25)all、any的使用
ALL 操作符表示"所有"或"每一个",只有当比较操作对所有子查询返回的值都为真时,整个表达式才为真。
查找比所有部门平均工资都高的员工:
SELECT name, salary
FROM employees
WHERE salary > ALL (
SELECT AVG(salary)
FROM employees
GROUP BY department_id
);ANY 操作符表示"任意一个"或"至少一个",只要比较操作对子查询返回的任何一个值为真,整个表达式就为真。
查找工资高于任何部门平均工资的员工:
SELECT name, salary
FROM employees
WHERE salary > ANY (
SELECT AVG(salary)
FROM employees
GROUP BY department_id
);26)表复制操作
只复制表结构:
CREATE TABLE employees_copy LIKE employees;复制表结构及数据:
CREATE TABLE employees_copy AS SELECT * FROM employees;27)左外连、右外连
-- 查询所有员工及其部门信息(包括没有部门的员工)
SELECT e.employee_id, e.name, d.department_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id;
-- 使用WHERE子句筛选右表为NULL的记录(查找没有部门的员工)
SELECT e.employee_id, e.name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id
WHERE d.dept_id IS NULL;28)primary key
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50) NOT NULL
);特点:
- 数据不能重复且不能为NULL
- 一张表只能有一个主键,但可以是复合主键,例如:
primary key(id,`name`) - 两种定义方式:
1.字段名 primary key
2.primary key 列名 - 通过desc表名可以看到主键情况
29)unique
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
email VARCHAR(100) UNIQUE,
phone VARCHAR(20)
);特点:
- 数据不可重复但可为NULL
- 可以定义多个unique
30)foreign key
-- 创建表时定义
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
-- 添加外键到已有表
ALTER TABLE order_items
ADD FOREIGN KEY (order_id) REFERENCES orders(order_id);
-- 指定操作行为
CREATE TABLE order_items (
item_id INT PRIMARY KEY,
order_id INT,
product_id INT,
FOREIGN KEY (order_id) REFERENCES orders(order_id)
ON DELETE CASCADE
ON UPDATE CASCADE
);特点:
- 外键指向的表的字段,要求是primary key或者是unique
- 表的类型是innodb才支持外键
- 外键字段的类型要和主键字段的类型一致
- 外键字段的值必须在主键字段中出现过或者为NULL,前提是主键允许为NULL
- 不能随意删除主外键
31)check
用于限制字段,不符合则会报错
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
salary DECIMAL(10,2) CHECK (salary > 0),
age INT CHECK (age >= 18 AND age <= 65)
);32)default
CREATE TABLE orders (
order_id INT PRIMARY KEY,
order_date DATE DEFAULT CURRENT_DATE(),
status VARCHAR(20) DEFAULT 'Pending'
);特点:
-
为列提供默认值
-
当插入数据未指定值时使用
33)auto_increment
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
salary DECIMAL(10,2) CHECK (salary > 0),
age INT CHECK (age >= 18 AND age <= 65)
);特点:
-
唯一性:保证每行有唯一标识为主键或unique
-
自动递增:每次插入新行时自动增加
-
可配置性:可以设置起始值和增量
-
可重置:可以重新设置当前值
34)索引
索引是数据库中一种特殊的数据结构,它类似于书籍的目录,能够帮助数据库引擎快速定位数据。
索引底层为B+。
索引的优点:
-
大大加快数据检索速度
-
加速表连接操作
-
优化排序和分组操作
-
实现唯一性约束
索引的缺点:
-
占用额外的存储空间
-
降低数据写入速度(增删改操作需要维护索引)
-
增加数据库维护开销
1.普通索引:
-- 创建表时添加
CREATE TABLE users (
id INT,
username VARCHAR(50),
INDEX idx_username (username)
);
-- 后期添加
CREATE INDEX idx_username ON users(username);2.唯一索引:
CREATE TABLE users (
email VARCHAR(100),
UNIQUE INDEX idx_email (email)
);
-- 后期添加
CREATE UNIQUE INDEX idx_email ON users(email);3.主键索引
CREATE TABLE users (
id INT PRIMARY KEY,
username VARCHAR(50)
);35)删除索引
1.使用drop index
DROP INDEX idx_username ON users;2.使用alter table
ALTER TABLE customers DROP INDEX idx_email;删除主键索引:
ALTER TABLE orders DROP PRIMARY KEY;
36)事务
事务是数据库管理系统中的一个重要概念,它保证了数据库操作的完整性和一致性。下面详细介绍MySQL中的事务机制。
事务(Transaction)是数据库操作的最小工作单位,是一组不可再分割的操作集合。事务具有以下特性(ACID):
-
原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成
-
一致性(Consistency):事务执行前后,数据库从一个一致状态变为另一个一致状态
-
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务
-
持久性(Durability):事务一旦提交,其结果就是永久性的
开启事务:
START TRANSACTION; -- 或者 BEGIN;提交事务:
COMMIT;回滚事务:
ROLLBACK;设置保存点:
SAVEPOINT savepoint_name; ROLLBACK TO savepoint_name; RELEASE SAVEPOINT savepoint_name;
37)事务隔离级别
MySQL支持四种事务隔离级别:
-
READ UNCOMMITTED (读未提交):最低隔离级别,允许读取未提交的数据变更
-
READ COMMITTED (读已提交):只能读取已提交的数据
-
REPEATABLE READ (可重复读):MySQL默认级别,确保同一事务中多次读取同样数据结果一致
-
SERIALIZABLE (串行化):最高隔离级别,完全串行执行事务
设置隔离级别:
SET TRANSACTION ISOLATION LEVEL level;
-- 例如
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;查看当前会话隔离级别:
SELECT @@transaction_isolation;
-- 或者
SELECT @@tx_isolation; -- MySQL 8.0之前版本查看全局隔离级别:
SELECT @@global.transaction_isolation;
-- 或者
SELECT @@global.tx_isolation; -- MySQL 8.0之前版本38)事务并发问题
1. 脏读(Dirty Read):
-
定义:一个事务读取了另一个未提交事务修改过的数据
-
场景:
-
事务A修改了某行数据但未提交
-
事务B读取了事务A修改后的数据
-
事务A回滚,事务B读取到的数据实际上是无效的
-
2. 不可重复读(Non-repeatable Read):
-
定义:同一事务内,多次读取同一数据返回不同结果
-
场景:
-
事务A第一次读取某行数据
-
事务B修改了该行数据并提交
-
事务A再次读取同一行数据,发现数据已改变
-
3. 幻读(Phantom Read):
-
定义:同一事务内,相同的查询条件返回不同的行集
-
场景:
-
事务A查询符合某个条件的多行数据
-
事务B插入或删除了符合该条件的行并提交
-
事务A再次查询,发现行数变化了
-
4. 丢失更新(Lost Update):
-
定义:两个事务同时更新同一数据,后提交的事务覆盖了先提交的事务的更新
-
场景:
-
事务A和事务B同时读取某行数据
-
事务A先修改数据并提交
-
事务B随后修改数据并提交,覆盖了事务A的修改
-
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 丢失更新 |
|---|---|---|---|---|
| READ UNCOMMITTED (读未提交) | ✓ | ✓ | ✓ | ✓ |
| READ COMMITTED (读已提交) | × | ✓ | ✓ | ✓ |
| REPEATABLE READ (可重复读) | × | × | ✓ | × |
| SERIALIZABLE (串行化) | × | × | × | × |
-
可重复读在MySQL中通过多版本并发控制(MVCC)和间隙锁(Gap Lock)避免了幻读问题
-
丢失更新问题通常需要通过应用层逻辑或乐观锁/悲观锁来解决
各隔离级别特点及应用场景:
-
READ UNCOMMITTED:
-
性能最好,但数据一致性最差
-
适用于对数据准确性要求不高但要求高并发的场景
-
-
READ COMMITTED:
-
避免了脏读
-
Oracle等数据库的默认级别
-
适用于大多数OLTP系统
-
-
REPEATABLE READ:
-
MySQL的默认级别
-
避免了脏读和不可重复读
-
通过MVCC和间隙锁也避免了幻读
-
-
SERIALIZABLE:
-
完全串行执行,性能最差
-
数据一致性最好
-
适用于对数据一致性要求极高的场景
-
39)存储引擎
MySQL支持多种存储引擎,每种引擎都有其特点和适用场景。存储引擎是MySQL的核心组件,负责数据的存储、检索和管理。
常见存储引擎对比:
| 特性 | InnoDB | MyISAM | MEMORY | ARCHIVE | CSV |
|---|---|---|---|---|---|
| 事务支持 | 支持(ACID) | 不支持 | 不支持 | 不支持 | 不支持 |
| 锁机制 | 行级锁 | 表级锁 | 表级锁 | 行级锁 | 表级锁 |
| 外键支持 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| MVCC | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 缓存 | 数据+索引 | 仅索引 | 内存中 | 无 | 无 |
| 存储限制 | 64TB | 256TB | 内存大小 | 无 | 系统限制 |
| 崩溃恢复 | 支持 | 有限支持 | 数据丢失 | 支持 | 有限支持 |
| 全文索引 | 5.6+支持 | 支持 | 不支持 | 不支持 | 不支持 |
| 适用场景 | 事务型应用 | 只读/读密集型 | 临时表/缓存 | 日志/归档 | 数据交换 |
1. InnoDB (默认引擎):
特点:
-
支持事务处理(ACID兼容)
-
行级锁定和外键约束
-
支持MVCC(多版本并发控制)
-
自动崩溃恢复
-
聚集索引(主键索引直接包含数据)
适用场景:
-
需要事务支持的应用
-
高并发读写操作
-
需要外键约束的应用
-
需要崩溃后自动恢复的场景
2. MyISAM:
特点:
-
表级锁定
-
全文索引支持
-
较高的读取性能
-
不支持事务
-
数据文件(.MYD)和索引文件(.MYI)分离
适用场景:
-
只读或读多写少的应用
-
需要全文索引的应用(MySQL 5.6前)
-
数据仓库类应用
3. MEMORY (HEAP):
特点:
-
数据存储在内存中
-
表级锁定
-
不支持BLOB/TEXT类型
-
服务器重启后数据丢失
-
哈希索引默认
适用场景:
-
临时表
-
缓存小型数据集
-
快速查找的只读数据
4. ARCHIVE:
特点:
-
只支持INSERT和SELECT
-
高压缩比(10:1)
-
行级锁定
-
不支持索引(除自增主键)
适用场景:
-
日志和审计数据存储
-
历史归档数据
-
很少查询的大量数据
如何选择存储引擎?
-
常规OLTP应用:优先选择InnoDB
-
支持事务
-
行级锁定
-
崩溃恢复
-
-
只读/分析型应用:可考虑MyISAM
-
读取速度快
-
全表扫描性能好
-
-
临时数据处理:可使用MEMORY引擎
-
内存速度快
-
临时计算结果存储
-
-
归档存储:ARCHIVE引擎
-
高压缩比
-
节省存储空间
-
查看支持的存储引擎:
SHOW ENGINES;查看表的存储引擎:
SHOW TABLE STATUS LIKE '表名'; -- 或 SHOW CREATE TABLE 表名;修改表的存储引擎:
ALTER TABLE 表名 ENGINE = InnoDB;
40)视图
视图(VIEW)是MySQL中非常重要的数据库对象,它提供了一种虚拟表的方式来组织和简化数据访问。
1. 什么是视图:
-
视图是基于SQL语句的结果集的虚拟表
-
视图不实际存储数据,数据来自基表
-
视图可以像普通表一样被查询、过滤和连接
2. 视图的特点:
-
简化复杂查询:封装复杂SQL,使查询更简单
-
数据安全:隐藏敏感列,只暴露必要数据
-
逻辑独立性:基表结构变化不影响应用程序
-
多表统一访问:将多个表的数据整合为一个虚拟表
创建视图:
CREATE [OR REPLACE] VIEW 视图名 [(列名1, 列名2, ...)]
AS
SELECT语句
[WITH [CASCADED | LOCAL] CHECK OPTION];示例:
CREATE VIEW myview AS
SELECT `name`
FROM student
修改视图:
ALTER VIEW 视图名 [(列名1, 列名2, ...)]
AS
SELECT语句
[WITH CHECK OPTION];删除视图:
DROP VIEW [IF EXISTS] 视图名;查看视图定义:
SHOW CREATE VIEW 视图名;41)用户管理
MySQL用户管理是数据库安全的重要组成部分,涉及用户账号的创建、权限分配、密码策略等多个方面。
创建用户:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';CREATE USER 'dev_user'@'localhost' IDENTIFIED BY 'Password123!';
CREATE USER 'remote_user'@'192.168.1.%' IDENTIFIED BY 'SecurePass456';修改用户:
-- 修改用户名
RENAME USER 'old_user'@'host' TO 'new_user'@'host';
-- 修改密码(MySQL 5.7+)
ALTER USER 'username'@'host' IDENTIFIED BY 'new_password';
-- 修改密码(MySQL 5.6及以下)
SET PASSWORD FOR 'username'@'host' = PASSWORD('new_password');删除用户:
DROP USER 'username'@'host';查看用户列表:
SELECT User, Host FROM mysql.user;42)权限管理
权限授予:
GRANT 权限类型 ON 数据库.表 TO 'username'@'host';-- 授予特定数据库的所有权限
GRANT ALL PRIVILEGES ON mydb.* TO 'dev_user'@'localhost';
-- 授予特定表的SELECT权限
GRANT SELECT ON mydb.employees TO 'report_user'@'%';
-- 授予多个权限
GRANT SELECT, INSERT, UPDATE ON mydb.* TO 'app_user'@'192.168.1.%';权限回收:
REVOKE 权限类型 ON 数据库.表 FROM 'username'@'host';REVOKE INSERT ON mydb.* FROM 'app_user'@'192.168.1.%';查看用户权限:
SHOW GRANTS FOR 'username'@'host';
一站式 AI 云服务平台
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)