
Ollama+LangChain构建本地知识库-----项目实战开始 项目开源!源码如下!
本文介绍了如何使用本地部署的大模型(qwen3)构建个人知识库。首先确保已通过ollama部署本地模型并准备知识库文件。项目结构包括文档目录、配置文件和主程序入口。通过安装langchain等库实现功能,使用Chroma存储向量数据。核心代码包含配置管理、文档加载与分割、对话链创建等功能。系统支持多格式文档处理,具有token计数和对话历史管理能力。运行后生成本地数据库,使AI能基于用户提供的内容
在前一篇文章我们使用了ollama部署了本地大模型,这次我们使用本地部署的大模型——“qwen3"来构建自己的知识库。如果有伙伴不知道如何使用ollama部署本地大模型 请看前一篇文章:使用Ollama部署本地大模型-CSDN博客
1、基础准备
本文默认已下载python,pycharm,ollama,LLM。运行了本地部署的模型,如果没有启动可以按住win+R (Win键通常位于键盘的左下角,位于Ctrl键和Alt键之间,图案是Windows的徽标)
输入CMD打开命令行,然后输入 ollama run qwen3(这里可以替换为各自下载的模型)。准备好知识库的测试文件,使用的是Windows系统
2、项目准备
2.1 新建一个项目,项目的目录如下
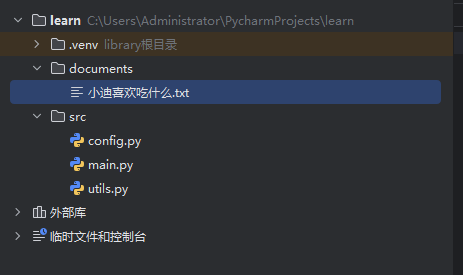
documents中的文件是提交的知识文件内容
config.py是配置信息
utils.py是工具函数集
main.py是主程序入口
2、2 下载相应的资源
输入这行命令在pycharm的终端,下载相对应的库
pip install langchain langchain_community tiktoken langchain_ollama langchain_chroma -i https://mirrors.aliyun.com/pypi/simple/
使用命令行 输入 ollama pull nomic-embed-text 即可下载Ollama的嵌入模型
(老规矩,下载速度慢了,就重启命令行,并重新输入命令即可加快下载速度)

3、具体实现
3、1 config.py
import os
class Config:
# Ollama配置
OLLAMA_BASE_URL = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434")
MODEL_NAME = os.getenv("MODEL_NAME", "qwen3")
# ChromaDB配置
PERSIST_DIRECTORY = "chroma_db"
CHROMA_SETTINGS = {
"persist_directory": PERSIST_DIRECTORY,#向量数据库存储路径
"anonymized_telemetry": False,
}
CHUNK_SIZE = 800 # 每个chunk的字符数(建议800-1200)
CHUNK_OVERLAP = 150 # chunk之间的重叠字符数(建议10-20% of CHUNK_SIZE)
SEPARATORS = ["\n\n", "\n", "。", "!", "?", " ", ""] # 中文友好分隔符
# Embedding配置
EMBEDDING_MODEL_NAME = "nomic-embed-text" # Ollama支持的专用嵌入模型
# Document loader配置
DOCUMENT_DIRECTORY = "../documents"
ALLOWED_EXTENSIONS = [".pdf", ".txt", ".md",".csv",".doc", ".docx"]
# 对话管理配置
MAX_TOKENS = 10000 # 对话token上限
MAX_TOKEN_LIMIT = 5000 # 记忆token限制
MEMORY_KEY = "chat_history"
RETRIEVER_K = 5 #检索5个相关性最大的文件3.2 main.py
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_ollama import OllamaEmbeddings, ChatOllama
from langchain_chroma import Chroma
import tiktoken
import os
from config import Config
from utils import load_documents, split_documents
class TokenCounter:
"""Token计数器"""
def __init__(self):
self.encoder = tiktoken.get_encoding("cl100k_base")
self.total_tokens = 0
def count(self, text: str) -> int:
"""计算文本的token数量"""
return len(self.encoder.encode(text))
def add(self, text: str):
"""增加token计数"""
self.total_tokens += self.count(text)
def reset(self):
"""重置计数器"""
self.total_tokens = 0
def initialize_knowledge_base(recreate: bool = False):
"""初始化知识库"""
config = Config()
persist_dir = config.PERSIST_DIRECTORY
if os.path.exists(persist_dir) and not recreate:
print("加载现有向量库...")
try:
return Chroma(
persist_directory=persist_dir,
embedding_function=OllamaEmbeddings(
base_url=config.OLLAMA_BASE_URL,
model=config.EMBEDDING_MODEL_NAME
)
)
except Exception as e:
print(f"加载失败,将重建: {str(e)}")
recreate = True
print("创建新向量库...")
documents = load_documents(config)
if not documents:
raise ValueError("文档目录中未找到任何文档")
texts = split_documents(documents, config)
print(f"已处理 {len(texts)} 个文本块")
embeddings = OllamaEmbeddings(
base_url=config.OLLAMA_BASE_URL,
model=config.EMBEDDING_MODEL_NAME,
)
if not os.path.exists(persist_dir):
os.makedirs(persist_dir)
return Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory=persist_dir
)
def trim_chat_history(messages, token_counter, max_tokens):
"""自定义对话历史修剪函数"""
total_tokens = 0 #累计token计数器
trimmed_messages = [] #保存修建后的消息列表
# 从最新消息开始反向计算
for msg in reversed(messages): #反向变例,确保优先保留最近的对话历史
msg_tokens = token_counter.count(msg.content)
if total_tokens + msg_tokens <= max_tokens: #保证不超过最大的token限制
trimmed_messages.insert(0, msg) # 保持原始顺序
total_tokens += msg_tokens
else:
break
return trimmed_messages
def create_conversational_chain(db, token_counter):
"""创建带记忆的对话链"""
config = Config()
llm = ChatOllama(
base_url=config.OLLAMA_BASE_URL,
model=config.MODEL_NAME,
temperature=0.4
)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的知识助手,请根据上下文和对话历史回答问题。"),
MessagesPlaceholder(variable_name=config.MEMORY_KEY),
("human", "上下文:\n{context}\n\n问题: {question}")
])
chain = (
RunnablePassthrough.assign(
chat_history=lambda x: trim_chat_history(
x.get(config.MEMORY_KEY, []),
token_counter,
config.MAX_TOKEN_LIMIT
)
)
| prompt
| llm
)
return chain
def main():
try:
config = Config()
token_counter = TokenCounter()
chat_history = [] # 存储对话历史
print("正在初始化知识库...")
db = initialize_knowledge_base(recreate=False)
qa_chain = create_conversational_chain(db, token_counter)
print("\n系统已就绪。输入'new'开始新对话或'quit'退出。")
while True:
try:
query = input("\n请输入问题: ").strip()
if query.lower() == 'quit':
break
if query.lower() == 'new':
chat_history.clear()
token_counter.reset()
print("\n已开始新对话。")
continue
if token_counter.total_tokens >= config.MAX_TOKENS:
print("\n 对话长度已达上限,请开始新对话。")
continue
# 检索相关文档
retrieved_docs = db.as_retriever(
search_kwargs={"k": config.RETRIEVER_K}
).invoke(query)
context = "\n".join(doc.page_content for doc in retrieved_docs)
# 调用对话链
response = qa_chain.invoke({
"question": query,
"context": context,
config.MEMORY_KEY: chat_history
})
# 更新token计数
token_counter.add(query)
token_counter.add(response.content)
# 更新对话历史
chat_history.extend([
HumanMessage(content=query),
AIMessage(content=response.content)
])
# 显示结果
print("\n回答:", response.content)
if retrieved_docs:
print("\n来源文档:")
for doc in retrieved_docs:
print(f"- {doc.metadata['source']} (页码: {doc.metadata.get('page', 'N/A')}")
print(f"\n[Token使用量: {token_counter.total_tokens}/{config.MAX_TOKENS}]")
except Exception as e:
print(f"\n错误: {str(e)}")
except KeyboardInterrupt:
print("\n正在退出...")
except Exception as e:
print(f"严重错误: {str(e)}")
if __name__ == "__main__":
main()3.3 utils.py
import os
from langchain_community.document_loaders import PyPDFLoader, TextLoader, UnstructuredMarkdownLoader, CSVLoader,UnstructuredWordDocumentLoader #使用langchain的文档加载器处理不同格式
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_documents(config):
"""加载文档目录中的所有文件"""
# 添加路径验证
if not os.path.exists(config.DOCUMENT_DIRECTORY):
raise ValueError(f"文档目录不存在: {config.DOCUMENT_DIRECTORY}")
if not os.path.isdir(config.DOCUMENT_DIRECTORY):
raise ValueError(f"文档路径不是目录: {config.DOCUMENT_DIRECTORY}")
documents = []
for file in os.listdir(config.DOCUMENT_DIRECTORY):
file_path = os.path.join(config.DOCUMENT_DIRECTORY, file)
_, ext = os.path.splitext(file) #os.path.splitext 获取文件扩展名
#检查文件是否属于允许的扩展名,如果不属于则跳过该文件
if ext.lower() not in config.ALLOWED_EXTENSIONS:
continue
try:
if ext.lower() == ".pdf":
loader = PyPDFLoader(file_path)
elif ext.lower() == ".txt":
loader = TextLoader(file_path, encoding="utf-8")
elif ext.lower() == ".md":
loader = UnstructuredMarkdownLoader(file_path)
elif ext.lower() == ".csv":
loader = CSVLoader(file_path)
elif ext.lower()==".doc":
loader = UnstructuredWordDocumentLoader(file_path)
elif ext.lower()==".docx":
loader = UnstructuredWordDocumentLoader(file_path)
documents.extend(loader.load()) #获取文档内容
except Exception as e:
print(f"Error loading {file_path}: {str(e)}")
return documents
def split_documents(documents, config):
"""文本分割函数"""
text_splitter = RecursiveCharacterTextSplitter( #使用递归字符分割器处理文档
chunk_size=config.CHUNK_SIZE, #配置切分文块的大小
chunk_overlap=config.CHUNK_OVERLAP,#文本块的重叠量,有助于保持上下文连贯
length_function=len, #用于计算文本长度的函数,这里使用python的内置函数len
separators=config.SEPARATORS, # 中文优先的分隔符
is_separator_regex=False, #是否是正则表达式
)
# 分割文档并打印统计信息
chunks = text_splitter.split_documents(documents)
print(f"\n分割统计:")
print(f"- 原始文档数: {len(documents)}")
print(f"- 生成chunk数: {len(chunks)}")
print(f"- 平均chunk长度: {sum(len(c.page_content) for c in chunks) // len(chunks)}字符")
return chunks4、运行程序
4、1开始运行

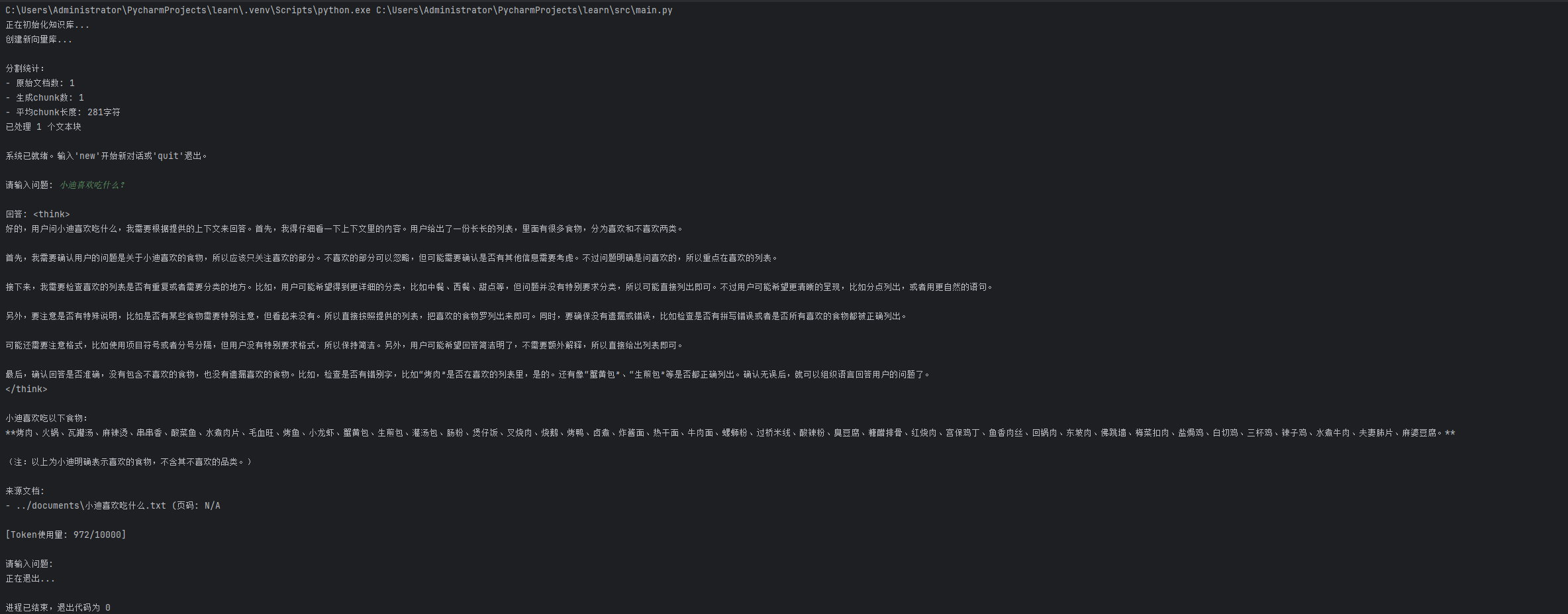
4、2运行结果
这就代表本地知识库构建完成,AI可以获取到你的内容
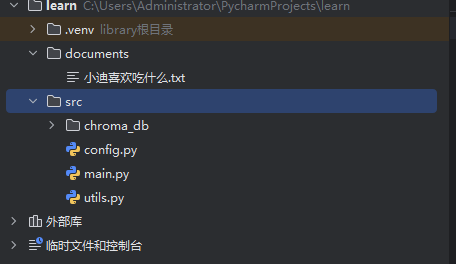
在第一次运行之后,src的目录下面会出现chroma_db的文件,这里是本地的数据库
到这里我们就成功的部署了简易的本地知识库,如果大家有问题的话欢迎随时交流。

一站式 AI 云服务平台
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)