
预训练,微调和知识库的区别
预训练,微调和知识库的区别
·
DeepSeek+知识库
- 实现方式:Ollama、AnythingLLM、DeepSeek-R1:7B、
知识库(MSN新闻)
- 实现效果:


-
DeepSeek+Fine-tuning
- 实现方式:DeepSeek-R1-Distill-Qwen-7B、Lora、medical-o1-reasoning-SFT(医疗)
- 实现效果:
选择的模型是蒸馏后 DeepSeek-R1-Distill-Qwen-7B 模型,显卡选择的是vGPU-32GB。数据集是medical-o1-reasoning-SFT(医疗)。数据集格式如下:

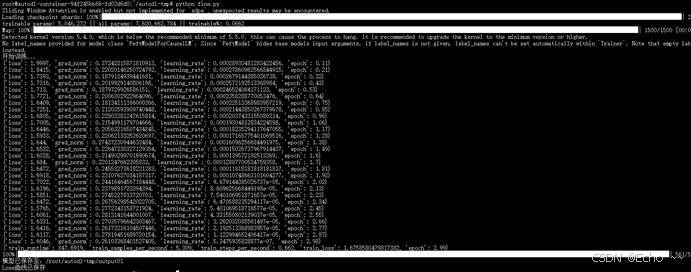
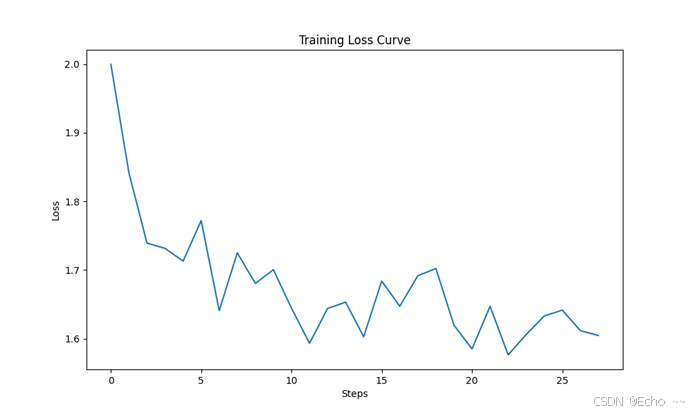
模型微调过程以及loss曲线如下:
直接比较「微调模型」和「原始模型」对同一个问题生成的回答内容进行比较。因此我们可以统一提示词,统一相关的问题,然后比较生成的答案。结果如下所示

使用 bertscore (用于衡量生成文本与参考文本之间的语义相似性)对模型进行比较。选择的 bert 模型是最基础的 bert-base-chinese 模型,结果如下。可以看到利用 bertscore 比较数据集的参考答案与模型生成答案的相似性来看,LoRA微调后的结果和原始模型相比还是有细微的差异,随着 LoRA 微调的训练轮次加深,这个结果的差异会进一步加大。
![]()
DeepSeek+Pre-training
- 实现代码:简化版DeepSeek
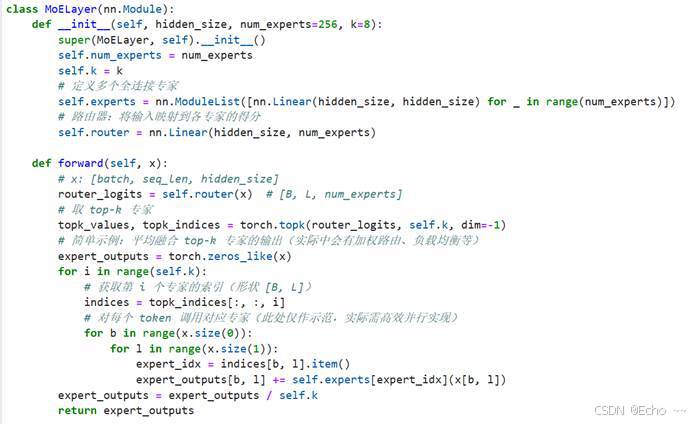
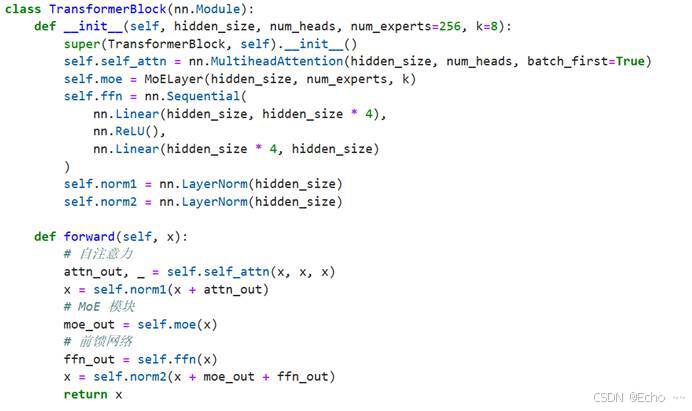
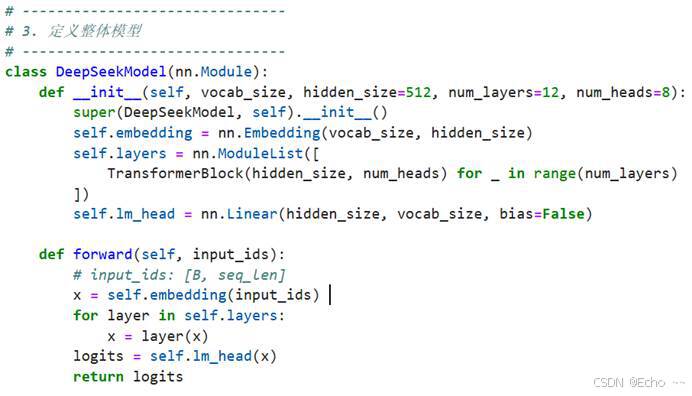
训练参数:
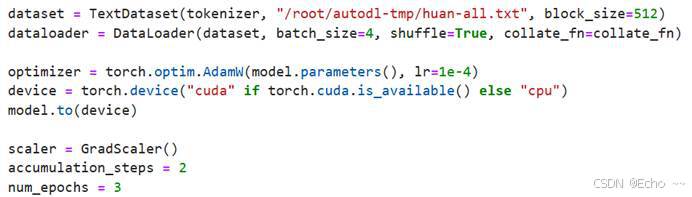
- 实现效果:由于只训练了3轮,效果较差(训练成本太高)
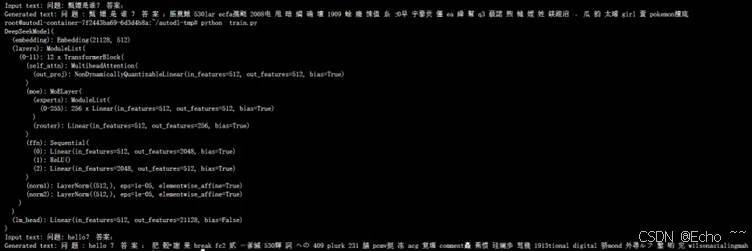
- 总结
|
维度 |
预训练 |
微调 |
知识库 |
|
核心作用 |
学习通用语言能力 |
适配特定任务或领域 |
提供外部事实性知识 |
|
数据依赖 |
大规模无监督数据 |
领域标注数据 |
结构化/非结构化知识 |
|
更新方式 |
全参数训练(高成本) |
参数微调(低成本) |
独立增删改查(灵活) |
|
知识形式 |
隐含在模型参数中 |
隐含在模型参数中 |
显式存储(可解释) |
|
实时性 |
依赖训练数据时间 |
依赖微调数据时间 |
可实时更新 |
|
典型技术 |
Transformer、LLM |
LoRA、Prompt |
向量数据库 |
|
效果 |
模型具备通用语言理解能力,但缺乏垂直领域知识或任务针对性。 |
显著提升特定任务的性能。可能牺牲泛化性。 |
增强回答的事实准确性(引用最新数据),但依赖知识库质量,且逻辑推理能力仍受限于模型本身。 |
预训练是模型的“基础教育”,微调是“专业培训”,知识库是“外部参考资料”。

一站式 AI 云服务平台
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)