
前端也能从0搭建知识库并实现RAG!
通过以上步骤,我们成功搭建了一个基于Node.js的知识库,并实现了RAG系统。通过加入Rerank和混合查询功能,我们进一步提升了系统的检索效果。大家好,我是Peter Tan,今天为大家带来一篇技术文章,教你如何用Node.js搭建自己的知识库,并实现一个RAG(Retrieval-Augmented Generation)系统。: Peter Tan,资深前端工程师,擅长Node.js、Re
手把手教你用Node.js搭建自己的知识库并实现一个RAG
大家好,我是Peter Tan,今天为大家带来一篇技术文章,教你如何用Node.js搭建自己的知识库,并实现一个RAG(Retrieval-Augmented Generation)系统。
最后我们还会加入Rerank(重排序)和混合查询功能,并通过Mock数据演示整个流程。
我们将使用Node.js、Express.js、Qdrant数据库等技术栈,一步步实现这个系统。
整体架构
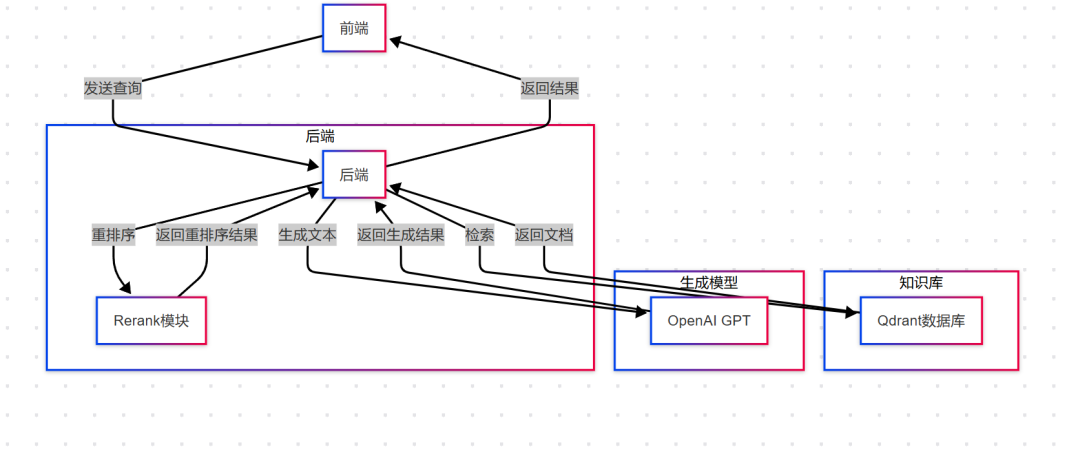
graph TD
A[前端] -->|发送查询| B[后端]
B -->|检索| C[知识库]
C -->|返回文档| B
B -->|重排序| D[Rerank模块]
D -->|返回重排序结果| B
B -->|生成文本| E[生成模型]
E -->|返回生成结果| B
B -->|返回结果| A
subgraph 后端
B[后端]
D[Rerank模块]
end
subgraph 知识库
C[Qdrant数据库]
end
subgraph 生成模型
E[OpenAI GPT]
end流程
graph TD
A[用户输入查询] --> B[检索相关文档]
B --> C[重排序文档]
C --> D[生成文本]
D --> E[返回生成结果]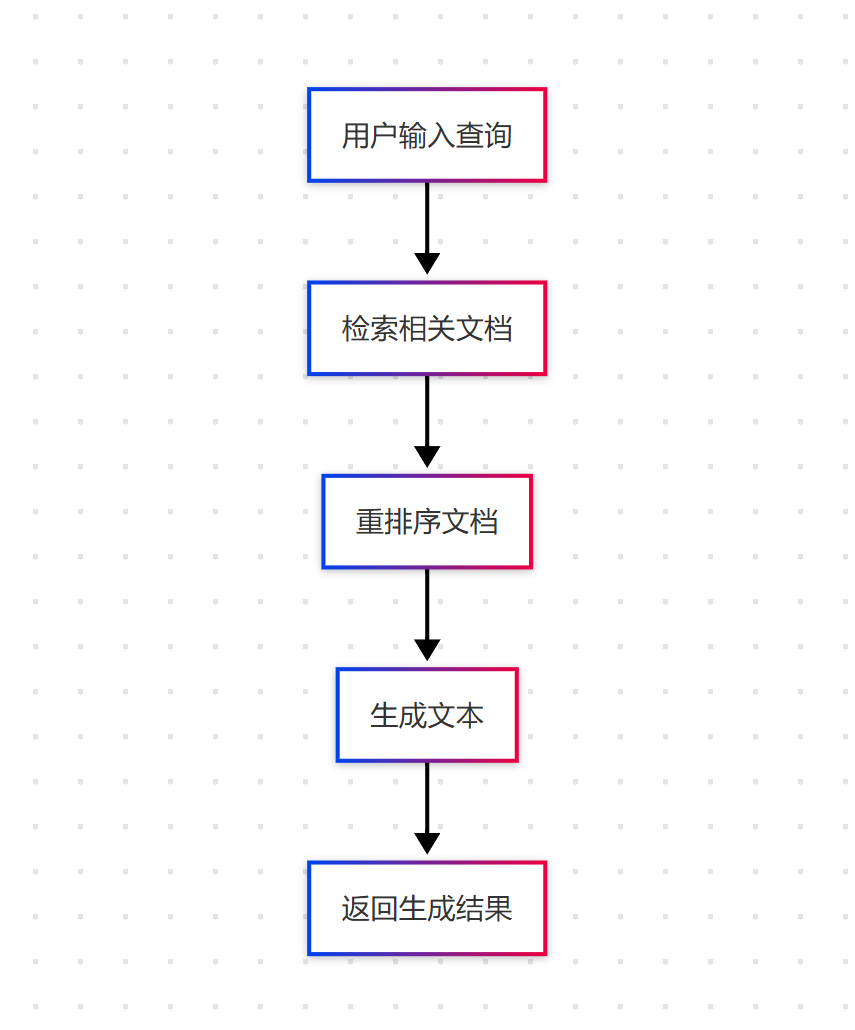
技术栈
-
Node.js: 作为后端运行时环境,提供高效的异步I/O操作。
-
Express.js: 用于构建RESTful API,处理HTTP请求和响应。
-
Qdrant: 一个高性能的向量数据库,用于存储和检索知识库中的向量数据。
-
ReACT架构: 一种结合了检索和生成的AI模型架构。
-
Rerank: 对检索结果进行重排序,提升结果的相关性。
-
混合查询: 结合关键词搜索和向量搜索,提升检索效果。
-
Mock数据: 用于模拟真实数据,方便开发和测试。
步骤一:搭建Node.js环境
如果你还没有搭建Node.js环境,可以直接使用以下命令初始化项目:
# 创建一个新的Node.js项目
mkdir my-knowledge-base
cd my-knowledge-base
npm init -y
# 安装必要的依赖
npm install express qdrant-client openai axios步骤二:创建Express.js服务器
我们创建一个简单的Express.js服务器来处理HTTP请求。
const express = require('express');
const app = express();
const port = 3000;
app.use(express.json());
app.get('/', (req, res) => {
res.send('Hello, World!');
});
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});步骤三:集成Qdrant数据库
Qdrant是一个高性能的向量数据库,非常适合用于存储和检索知识库中的向量数据。我们需要安装Qdrant客户端并连接到数据库。
const { QdrantClient } = require('qdrant-client');
const qdrant = new QdrantClient({ url: 'http://localhost:6333' });
// 创建一个新的集合
qdrant.createCollection('knowledge-base', {
vectors: {
size: 768, // 假设我们使用768维的向量
distance: 'Cosine',
},
});步骤四:实现RAG系统
RAG系统的核心是结合检索和生成。我们首先需要从知识库中检索相关信息,然后使用生成模型生成文本。
const openai = require('openai');
openai.apiKey = 'your-openai-api-key';
// 检索相关文档
async function retrieveDocuments(query) {
const queryVector = await getQueryVector(query); // 获取查询的向量表示
const searchResults = await qdrant.search('knowledge-base', {
vector: queryVector,
top: 10, // 返回前10个最相关的文档
});
return searchResults;
}
// 生成文本
async function generateText(query, documents) {
const prompt = `Query: ${query}\nDocuments: ${documents.join('\n')}`;
const response = await openai.Completion.create({
model: 'text-davinci-003',
prompt: prompt,
max_tokens: 150,
});
return response.choices[0].text;
}
// 获取查询的向量表示
async function getQueryVector(query) {
// 这里可以使用预训练的模型将查询转换为向量
// 例如,使用OpenAI的Embedding API
const response = await openai.Embedding.create({
input: query,
model: 'text-embedding-ada-002',
});
return response.data[0].embedding;
}步骤五:实现Rerank功能
Rerank功能可以对检索结果进行重排序,提升结果的相关性。我们可以使用开源的Rerank模型(如Cohere Rerank)或自定义规则来实现。
// 使用Cohere Rerank API进行重排序
async function rerankDocuments(query, documents) {
const cohere = require('cohere-ai');
cohere.init('your-cohere-api-key');
const response = await cohere.rerank({
query: query,
documents: documents,
top_n: 5, // 返回前5个最相关的文档
});
return response.results;
}步骤六:实现混合查询
混合查询结合了关键词搜索和向量搜索,可以提升检索效果。我们可以使用Qdrant的混合查询功能来实现。
// 混合查询:结合关键词搜索和向量搜索
async function hybridSearch(query) {
const queryVector = await getQueryVector(query);
// 向量搜索
const vectorResults = await qdrant.search('knowledge-base', {
vector: queryVector,
top: 10,
});
// 关键词搜索(假设我们有一个关键词索引)
const keywordResults = await qdrant.search('knowledge-base', {
filter: {
must: [
{
key: 'text',
match: {
value: query,
},
},
],
},
top: 10,
});
// 合并结果并去重
const combinedResults = [...vectorResults, ...keywordResults];
const uniqueResults = Array.from(new Set(combinedResults.map(JSON.stringify))).map(JSON.parse);
return uniqueResults;
}步骤七:使用Mock数据进行测试
为了测试我们的系统,我们可以使用Mock数据来模拟真实场景。
// 生成Mock数据
async function generateMockData() {
const mockData = [
{ id: 1, text: 'Node.js是一个基于Chrome V8引擎的JavaScript运行时。', vector: await getQueryVector('Node.js是一个基于Chrome V8引擎的JavaScript运行时。') },
{ id: 2, text: 'Express.js是一个基于Node.js的Web应用框架。', vector: await getQueryVector('Express.js是一个基于Node.js的Web应用框架。') },
{ id: 3, text: 'Qdrant是一个高性能的向量数据库。', vector: await getQueryVector('Qdrant是一个高性能的向量数据库。') },
];
// 将Mock数据插入Qdrant
await qdrant.upsert('knowledge-base', {
points: mockData,
});
}
// 初始化Mock数据
generateMockData();步骤八:整合所有功能
最后,我们将所有功能整合到一个API中,用户可以通过发送HTTP请求来获取生成的文本。
app.post('/rag', async (req, res) => {
const { query } = req.body;
// 混合查询
const documents = await hybridSearch(query);
// Rerank
const rerankedDocuments = await rerankDocuments(query, documents);
// 生成文本
const generatedText = await generateText(query, rerankedDocuments);
res.json({ generatedText });
});总结
通过以上步骤,我们成功搭建了一个基于Node.js的知识库,并实现了RAG系统。通过加入Rerank和混合查询功能,我们进一步提升了系统的检索效果。希望这篇文章对你有所帮助,如果你有任何问题或建议,欢迎在评论区留言。
感谢大家的阅读,我们下次再见!
作者简介: Peter Tan,资深前端工程师,擅长Node.js、React等技术,目前专注于AI应用的研究与开发。个人微信号:PeterTan6666,微信公众号:【前端巅峰】。

一站式 AI 云服务平台
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)