
【搭建AI大模型】本地私有化RAG知识库搭建—基于Ollama+AnythingLLM保姆级教程
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了信息检索和语言模型的技术,它通过从大规模的知识库中检索相关信息,并利用这些信息来指导语言模型生成更准确和深入的答案。这种方法在2020年由Meta AI研究人员提出,旨在解决大型语言模型(LLM)在信息滞后、模型幻觉、私有数据匮乏和内容不可追溯等问题。
一、关于RAG
1.1 简介
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了信息检索和语言模型的技术,它通过从大规模的知识库中检索相关信息,并利用这些信息来指导语言模型生成更准确和深入的答案。这种方法在2020年由Meta AI研究人员提出,旨在解决大型语言模型(LLM)在信息滞后、模型幻觉、私有数据匮乏和内容不可追溯等问题。
即:RAG 就是可以开卷回复的 LLM

1.2 发展
RAG技术的发展历程可以分为三个主要阶段:
-
Naive RAG:这是RAG技术的基础阶段,它包括了索引(Indexing)、检索(Retrieval)和生成(Generation)三个基本步骤。在这个阶段,RAG通过整合外部知识库来增强LLMs,但是存在一些限制,例如准确性低、召回低、组装prompt的问题以及灵活性问题。
-
Advanced RAG:为了解决Naive RAG的不足,Advanced RAG阶段引入了预检索和后检索策略,改进了索引方法,并引入了各种方法来优化检索过程。这一阶段的RAG通过更精细的数据清洗、设计文档结构和添加元数据等方法提升文本的一致性、准确性和检索效率。
-
Modular RAG:在模块化RAG阶段,RAG结构提供了更大的灵活性和适应性。它整合了各种方法来增强功能模块,例如加入搜索模块进行相似性检索,并在检索器中应用微调方法。模块化RAG允许通过多个模块进行序列化流水线或端到端训练,提供了更大的灵活性和适应性。
随着技术的发展,RAG技术也在不断进步,包括个性化、可自定义行为、可扩展性、混合模型和实时的低延迟部署等方面。这些趋势预示着RAG技术将在未来变得更加智能和高效,为各种应用程序提供更多样化的支持。RAG技术的应用已经不仅仅局限于问答系统,其影响力正在扩展到更多领域,如推荐系统、信息抽取和报告生成等。

1.3 背景
自 ChatGPT 发布以来,大型语言模型(Large Language Model,LLM,大模型)得到了飞速发展,它在处理复杂任务、增强自然语言理解和生成类人文本等方面的能力让人惊叹,几乎各行各业均可从中获益。
然而,在一些垂直领域,这些开源或闭源的通用基础大模型也暴露了一些问题,主要体现在以下 3 个方面:
-
知识的局限性: 大模型的知识源于训练数据,目前主流大模型(如:通义千问、文心一言等)的训练数据基本来源于网络公开的数据。因此,非公开的、离线的、实时的数据大模型是无法获取到(如:团队内部实时业务数据、私有的文档资料等),这些数据相关的知识也就无从具备。
-
幻觉问题: 大模型生成人类文本底层原理是基于概率(目前还无法证明大模型有意识),所以它有时候会一本正经地胡说八道,特别是在不具备某方面的知识情况下。当我们也因缺乏这方面知识而咨询大模型时,大模型的幻觉问题会各我们造成很多困扰,因为我们也无法区分其输出的正确性。
-
数据的安全性: 对于个人、创新团队、企业来说,数据安全至关重要,老牛同学相信没有谁会愿意承担数据泄露的风险,把自己内部私有数据上传到第三方平台进行模型训练。这是一个矛盾:我们既要借助通用大模型能力,又要保障数据的安全性!
为了解决以上通用大模型问题,检索增强生成(Retrieval-Augmented Generation,RAG)方案就应运而生。
1.4 工作原理

RAG 的主要流程主要包含以下 2 个阶段:
-
数据准备:首先需要准备知识文档,这可能包括多种格式的文档,如Word文档、TXT文件、PDF文件等。这些文档需要通过文档加载器或多模态模型(如OCR技术)转换为纯文本数据。然后,将这些文本分割成多个文本块,以便更高效地处理和检索信息。
-
嵌入模型:嵌入模型的核心任务是将文本转换为向量形式。这些向量能够捕捉到句子的上下文关系和核心含义,使得通过计算向量之间的差异来识别语义上相似的句子成为可能。
-
向量数据库:通过嵌入模型生成的所有向量都会被存储在向量数据库中。这种数据库优化了处理和存储大规模向量数据的效率,使得在面对海量知识向量时,能够迅速检索出与用户查询最相关的信息。
-
查询检索:用户的问题会被输入到嵌入模型中进行向量化处理,然后在向量数据库中搜索与该问题向量语义上相似的知识文本或历史对话记录并返回。
-
生成回答:将用户提问和检索到的信息结合,构建出一个提示模版,输入到大语言模型中,生成模型根据这些信息生成答案。
RAG的原理在于利用情境学习(In-Context Learning)的原理,通过检索算法找到的信息作为上下文,帮助大模型回答用户问询。这种方法特别适用于需要大量知识的任务,并且可以通过引用信息来源,增强用户对模型输出的信任。
在实际应用中,RAG可以通过多种优化策略来提高性能,包括数据清洗、分层导航小世界、查询转换、重排模型等。这些优化策略可以在AI开发框架如langchain和LLamaIndex中找到具体实现。
1.5 实现方案
目前市面上存在多个RAG(Retrieval-Augmented Generation)开源框架,它们提供了不同的功能和特性,以支持开发者构建和优化RAG系统。以下是一些流行的RAG实现框架,它们各有特点和优势:
-
LangChain:这是一个功能全面的框架,提供了从数据处理到用户界面的全栈解决方案。它支持多种大模型、嵌入模型和向量数据库,非常适合需要高度定制化和复杂工作流的企业级用户。
-
QAnything:由网易出品,支持任何格式文件或数据库的本地知识库问答系统,特点是加入rerank,后期更新也加入了文档理解,支持离线安装使用,适合需要数据安全保障的场景。
-
RAGFlow:基于深度文档理解构建的开源RAG引擎,提供精简的RAG工作流程,支持多种文档数据类型,具有OCR功能和多种文档切分模板。
-
FastGPT:提供数据处理、模型调用等能力,支持通过Flow可视化进行工作流编排,实现复杂的问答场景。
-
AnythingLLM:由Mintplex Labs开发,是一个全栈应用程序,支持现成的商业大语言模型或流行的开源大语言模型,可以构建私有ChatGPT。
-
Langchain-Chatchat:基于ChatGLM等大语言模型与Langchain等应用框架实现的开源、可离线部署的RAG大模型知识库项目。
这里选择AnythingLLM框架,如下介绍AnythingLLM部署及配置流程
二、Docker Desktop安装配置
这里之前文章有介绍,可参考,这里不再赘述
三、AnythingLLM 安装及配置
开始安装和部署AnythingLLM框架,包含以下 3 步:
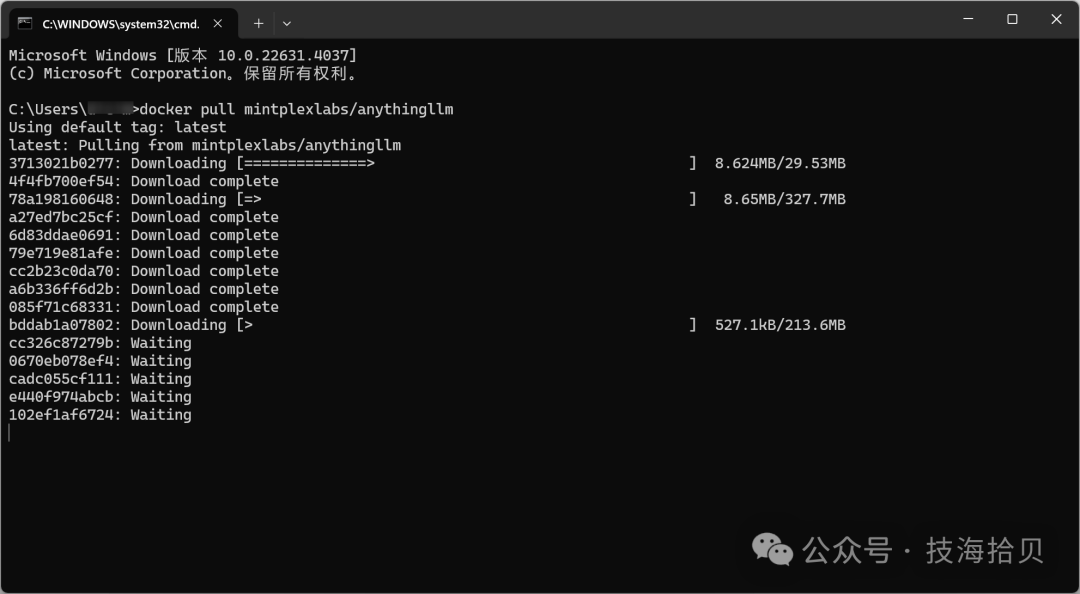
4.1 拉取镜像
docker pull mintplexlabs/anythingllm
4.2 启动镜像
Windows环境, 通过PowerShell执行如下命令
# Run this in powershell terminal
$env:STORAGE_LOCATION="$HOME\Documents\anythingllm"; `
If(!(Test-Path $env:STORAGE_LOCATION)) {New-Item $env:STORAGE_LOCATION -ItemType Directory}; `
If(!(Test-Path "$env:STORAGE_LOCATION\.env")) {New-Item "$env:STORAGE_LOCATION\.env" -ItemType File}; `
docker run -d -p 3001:3001 `
--cap-add SYS_ADMIN `
-v "$env:STORAGE_LOCATION`:/app/server/storage" `
-v "$env:STORAGE_LOCATION\.env:/app/server/.env" `
-e STORAGE_DIR="/app/server/storage" `
mintplexlabs/anythingllm;
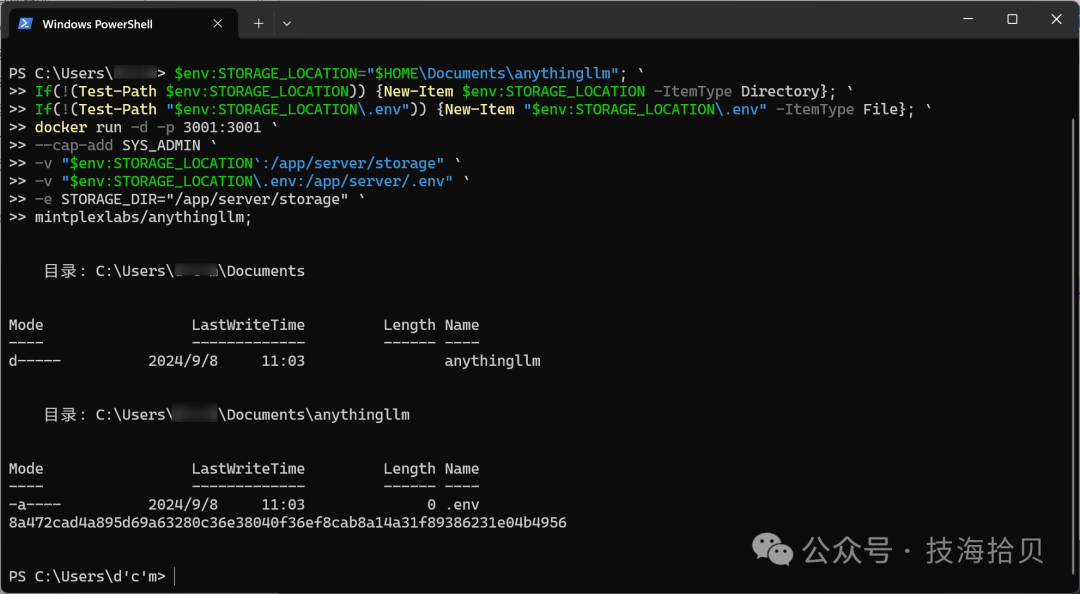
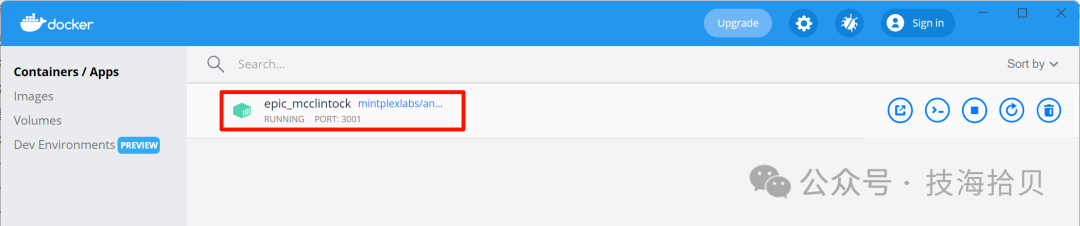
启动完成,通过浏览器打开如下网址:http://localhost:3001,进入AnythingLLM web界面
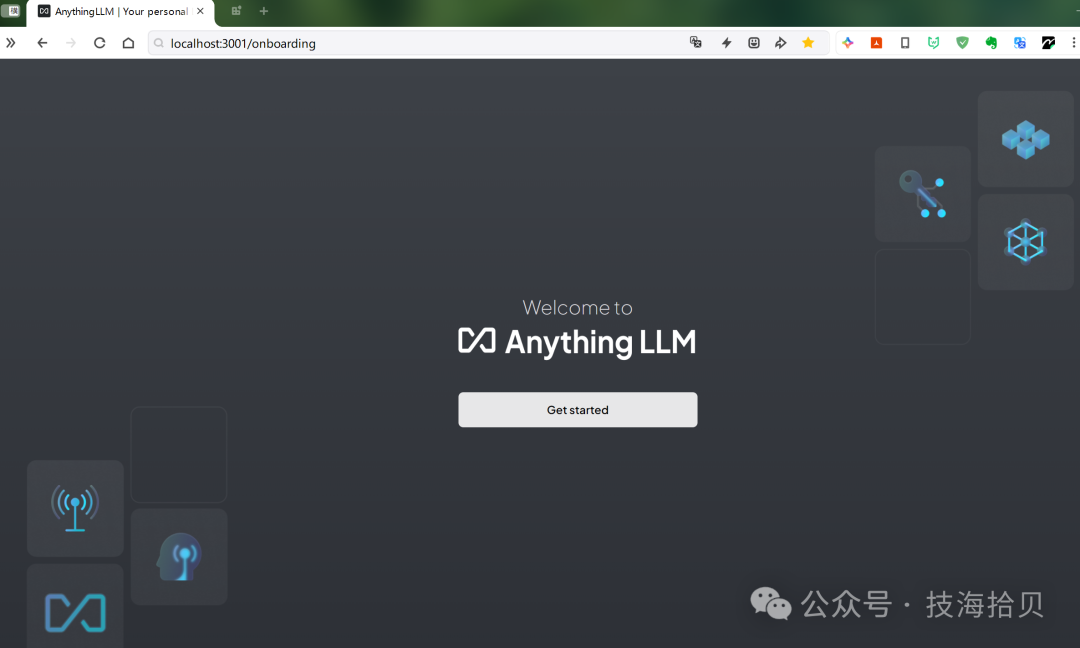
4.3 配置
点击开始,这里选择ollama,如果本地已启动ollama,则会检测到
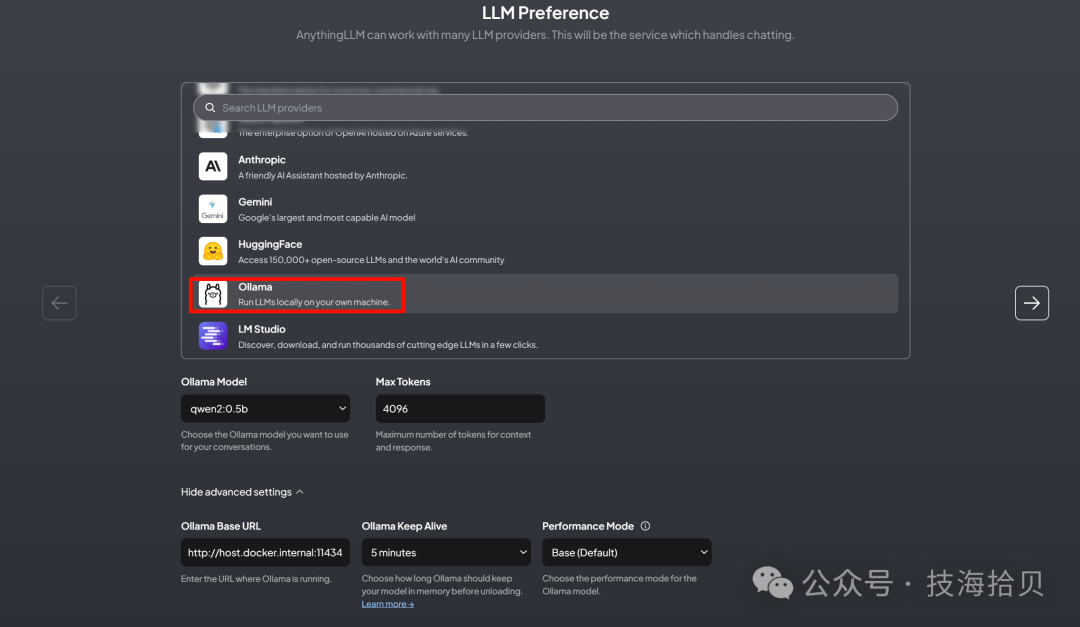
这里可以根据情况,配置当前用户使用,还是团队使用
创建工作区
五、导入数据和使用
5.1 导入内部数据
创建一个word或txt文件,文本内容如下
自ChatGPT发布以来,大型语言模型(Large Language Model,LLM,大模型)得到了飞速发展,它在解决复杂任务、增强自然语言理解和生成类人文本等方面的能力让人惊叹,几乎各行各业均可从中获益。
然而,在一些垂直领域,这些开源或闭源的通用的基础大模型也暴露了一些问题,主要有以下3个方面:
1. **知识的局限性:** 大模型的知识源于训练数据,目前主流大模型(如:通义千问、文心一言等)的训练数据基本来源于网络公开的数据。因此,非公开的、离线的、实时的数据大模型是无法获取到(如:团队内部实时业务数据、私有的文档资料等),这些数据相关的知识也就无从具备。
2. **幻觉问题:** 大模型生成人类文本底层原理是基于概率(目前还无法证明大模型有意识),所以它有时候会**一本正经地胡说八道**,特别是在不具备某方面的知识情况下。当我们也因缺乏这方面知识而咨询大模型时,大模型的幻觉问题会各我们造成很多困扰,因为我们也无法区分其输出的正确性。
3. **数据的安全性:** 对于个人、创新团队、企业来说,**数据安全**至关重要,老牛同学相信没有谁会愿意承担数据泄露的风险,把自己内部私有数据上传到第三方平台进行模型训练。这是一个矛盾:我们既要借助通用大模型能力,又要保障数据的安全性!
为了解决以上3个大模型通用问题,**检索增强生成**(Retrieval-Augmented Generation,**RAG**)方案就应运而生了!
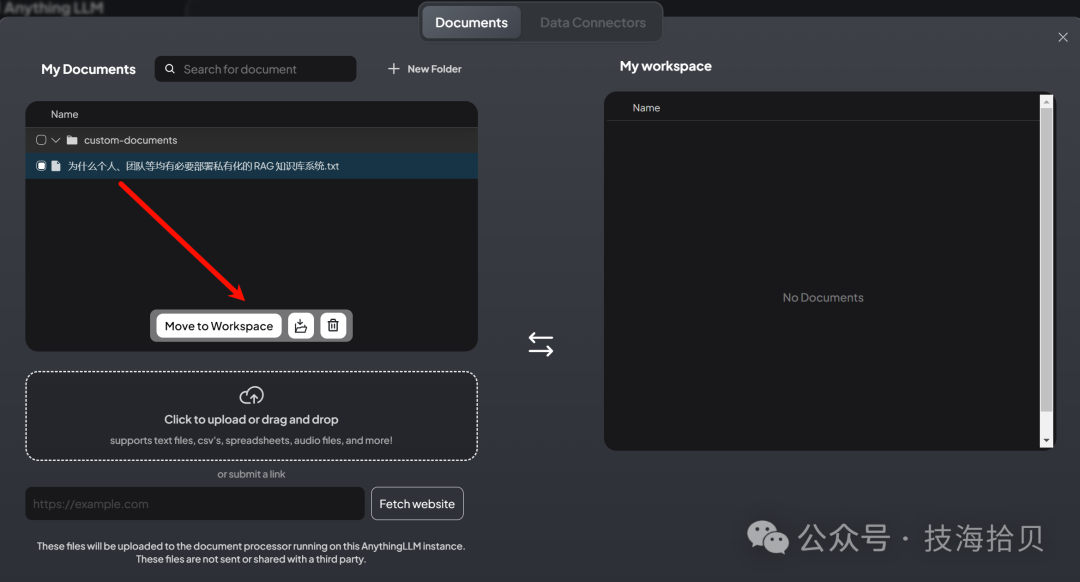
在工作区,上传上述文件

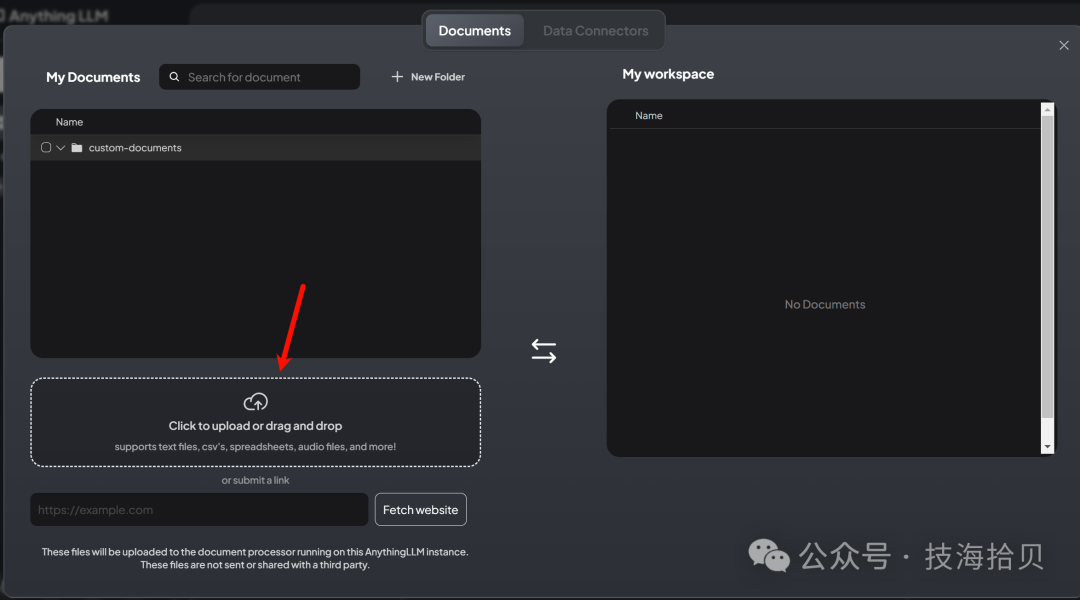
上传后移动到工作区
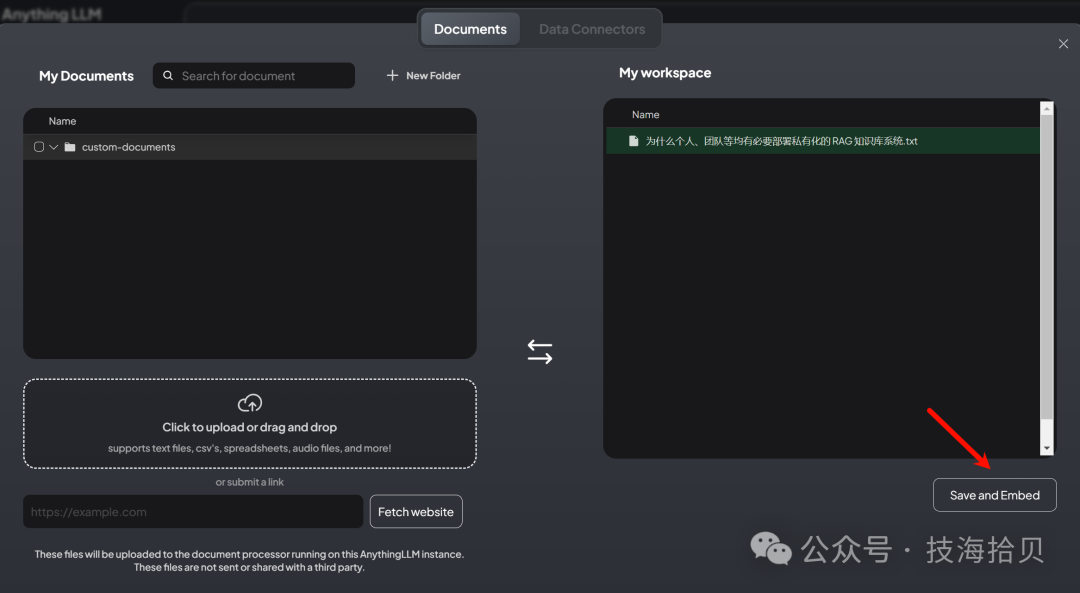
最后保存,需要一段时间
5.2 内部数据使用和验证
到对话界面,输入问题,
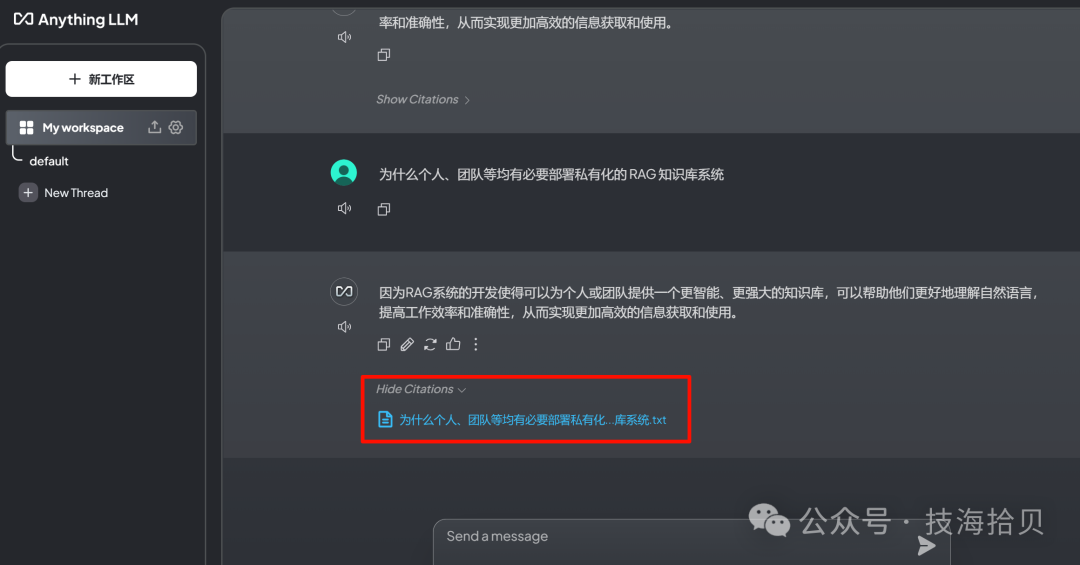
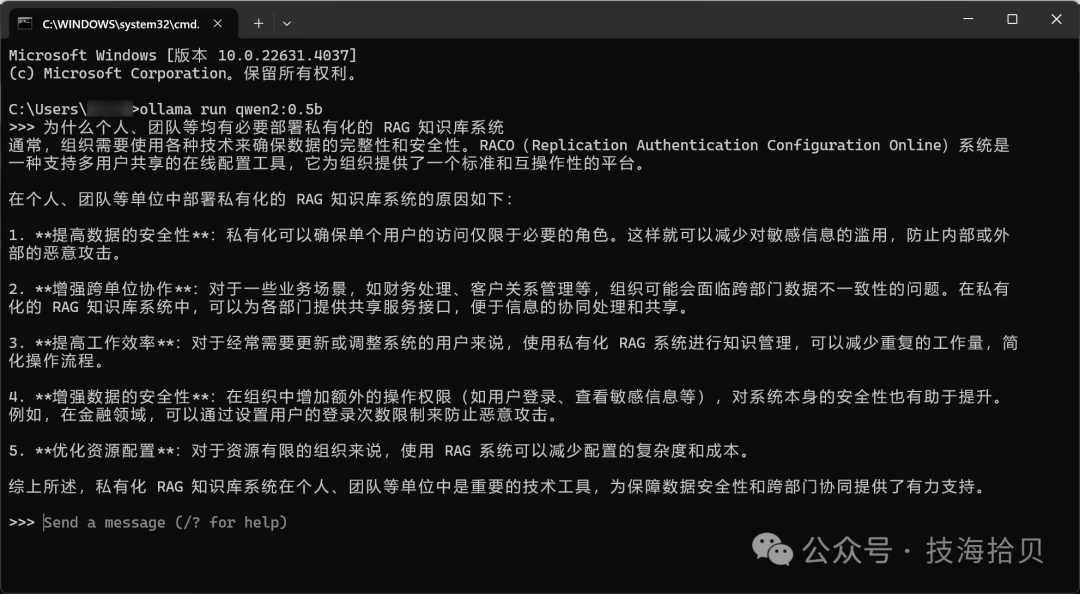
直接调用通义千文底层模型,同样的问题,查看回答,与上述对比有差异
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一站式 AI 云服务平台
更多推荐

 5
5 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)