
LangChain+LLM本地知识库问答:从企业单文档问答到批量文档问答
LangChain+LLM本地知识库问答:从企业单文档问答到批量文档问答
过去半年,随着ChatGPT的火爆,直接带火了整个LLM这个方向,然LLM毕竟更多是基于过去的经验数据预训练而来,没法获取最新的知识,以及各企业私有的知识
为了获取最新的知识,ChatGPT plus版集成了bing搜索的功能,有的模型则会调用一个定位于 “链接各种AI模型、工具”的langchain的bing功能
为了处理企业私有的知识,要么基于开源模型微调,要么更可以基于langchain里集成的向量数据库和LLM搭建本地知识库问答(此处的向量数据库的独特性在哪呢?举个例子,传统数据库做图片检索可能是通过关键词去搜索,向量数据库是通过语义搜索图片中相同或相近的向量并呈现结果)
本文则侧重讲解
什么是LangChain及langchain的整体组成架构
通过langchain-ChatGLM构建本地知识库问答的基本流程,与每个流程背后的逻辑
解读langchain-ChatGLM项目的关键源码,不只是把它当做一个工具使用,因为对工具的原理更了解,则对工具的使用更顺畅
一开始解读不易,因为涉及的项目、技术点不少,所以一开始容易绕晕,好在根据该项目的流程一步步抽丝剥茧之后,给大家呈现了清晰的代码架构
过程中,我从接触该langchain-ChatGLM项目到整体源码梳理清晰并写清楚历时了近一周,而大家有了本文之后,可能不到一天便可以理清了(提升近7倍效率) ,这便是本文的价值和意义之一
langchain-ChatGLM项目的升级版:langchain-Chatchat
我司基于langchain-chatchat二次开发的企业多文档知识库问答系统
第一部分 LangChain的整体组成架构:LLM的外挂/功能库
通俗讲,所谓langchain ,即把AI中常用的很多功能都封装成库,且有调用各种商用模型API、开源模型的接口,支持以下各种组件
初次接触的朋友一看这么多组件可能直接晕了(封装的东西非常多,感觉它想把LLM所需要用到的功能/工具都封装起来),为方便理解,我们可以先从大的层面把整个langchain库划分为三个大层:基础层、能力层、应用层
1.1 基础层:models、LLMs、index
1.1.1 Models:模型
各种类型的模型和模型集成,比如OpenAI的各个API/GPT-4等等,为各种不同基础模型提供统一接口
比如通过API完成一次问答

1.1.2 LLMS层
这一层主要强调对models层能力的封装以及服务化输出能力,主要有:
各类LLM模型管理平台:强调的模型的种类丰富度以及易用性
一体化服务能力产品:强调开箱即用
差异化能力:比如聚焦于Prompt管理(包括提示管理、提示优化和提示序列化)、基于共享资源的模型运行模式等等
1.1.3 Index(索引):Vector方案、KG方案
对用户私域文本、图片、PDF等各类文档进行存储和检索(相当于结构化文档,以便让外部数据和模型交互),具体实现上有两个方案:一个Vector方案、一个KG方案
1.1.3.1 Index(索引)之Vector方案
对于Vector方案:即对文件先切分为Chunks,在按Chunks分别编码存储并检索,可参考此代码文件:langchain/libs/langchain/langchain/indexes /vectorstore.py
1.1.3.2 Index(索引)之KG方案
对于KG方案:这部分利用LLM抽取文件中的三元组,将其存储为KG供后续检索,可参考此代码文件:langchain/libs/langchain/langchain/indexes /graph.py
1.2 能力层:Chains、Memory、Tools
如果基础层提供了最核心的能力,能力层则给这些能力安装上手、脚、脑,让其具有记忆和触发万物的能力,包括:Chains、Memory、Tool三部分
1.2.1 Chains:链接
简言之,相当于包括一系列对各种组件的调用,可能是一个 Prompt 模板,一个语言模型,一个输出解析器,一起工作处理用户的输入,生成响应,并处理输出
具体而言,则相当于按照不同的需求抽象并定制化不同的执行逻辑,Chain可以相互嵌套并串行执行,通过这一层,让LLM的能力链接到各行各业
比如与Elasticsearch数据库交互的:elasticsearch_database
比如基于知识图谱问答的:graph_qa
其中的代码文件:chains/graph_qa/base.py 便实现了一个基于知识图谱实现的问答系统,具体步骤为
首先,根据提取到的实体在知识图谱中查找相关的信息「这是通过 self.graph.get_entity_knowledge(entity) 实现的,它返回的是与实体相关的所有信息,形式为三元组」
然后,将所有的三元组组合起来,形成上下文
最后,将问题和上下文一起输入到qa_chain,得到最后的答案
1.2.2 Memory:记忆
简言之,用来保存和模型交互时的上下文状态,处理长期记忆
具体而言,这层主要有两个核心点:
对Chains的执行过程中的输入、输出进行记忆并结构化存储,为下一步的交互提供上下文,这部分简单存储在Redis即可
根据交互历史构建知识图谱,根据关联信息给出准确结果,对应的代码文件为:memory/kg.py
1.2.2 Memory:记忆
简言之,用来保存和模型交互时的上下文状态,处理长期记忆
具体而言,这层主要有两个核心点:
对Chains的执行过程中的输入、输出进行记忆并结构化存储,为下一步的交互提供上下文,这部分简单存储在Redis即可
根据交互历史构建知识图谱,根据关联信息给出准确结果,对应的代码文件为:memory/kg.py
此外,关于Wikipedia可以关注下这个代码文件:langchain/docstore/wikipedia.py ...
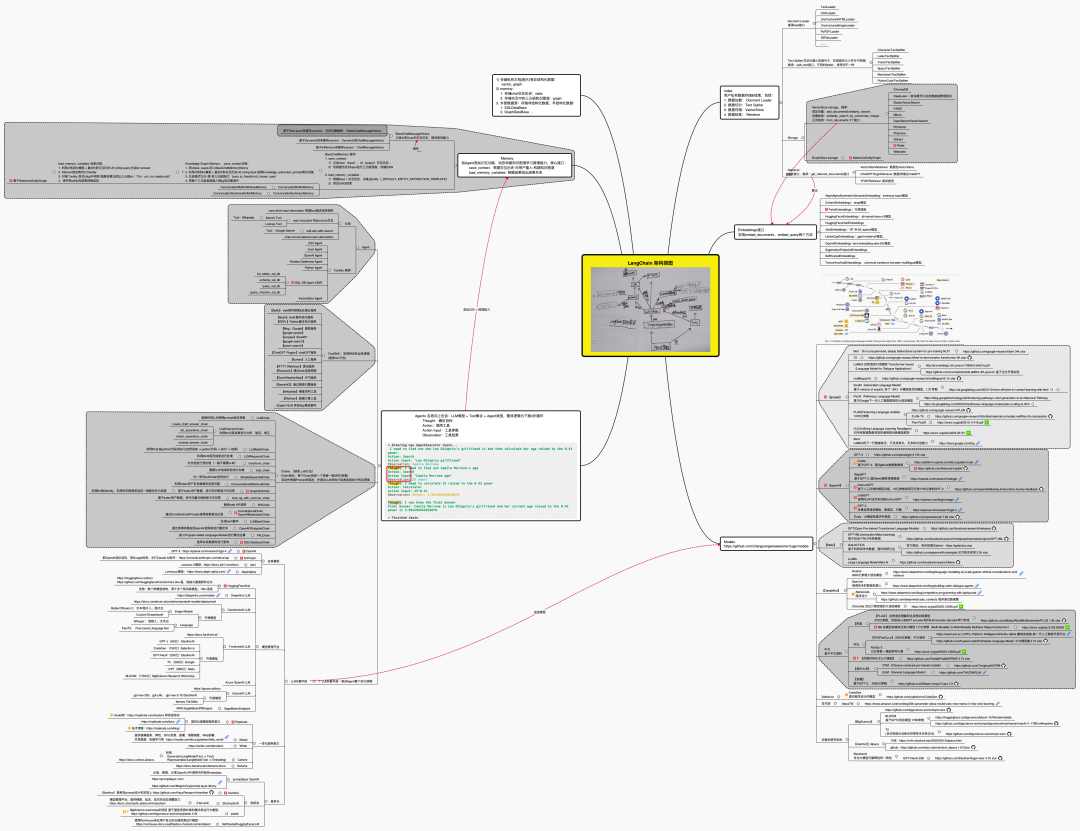
最终langchain的整体技术架构可以如下图所示 (查看高清大图,此外,这里还有另一个架构图)
第二部分 基于LangChain + ChatGLM-6B(23年7月初版)的本地知识库问答
2.1 核心步骤:如何通过LangChain+LLM实现本地知识库问答
2023年7月,GitHub上有一个利用 langchain 思想实现的基于本地知识库的问答应用:langchain-ChatGLM (这是其GitHub地址,当然还有和它类似的但现已支持Vicuna-13b的项目,比如LangChain-ChatGLM-Webui ),目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案
该项目受 GanymedeNil 的项目 document.ai,和 AlexZhangji 创建的 ChatGLM-6B Pull Request 启发,建立了全流程可使用开源模型实现的本地知识库问答应用。现已支持使用 ChatGLM-6B、 ClueAI/ChatYuan-large-v2 等大语言模型的接入
该项目中 Embedding 默认选用的是 GanymedeNil/text2vec-large-chinese,LLM 默认选用的是 ChatGLM-6B,依托上述模型,本项目可实现全部使用开源模型离线私有部署
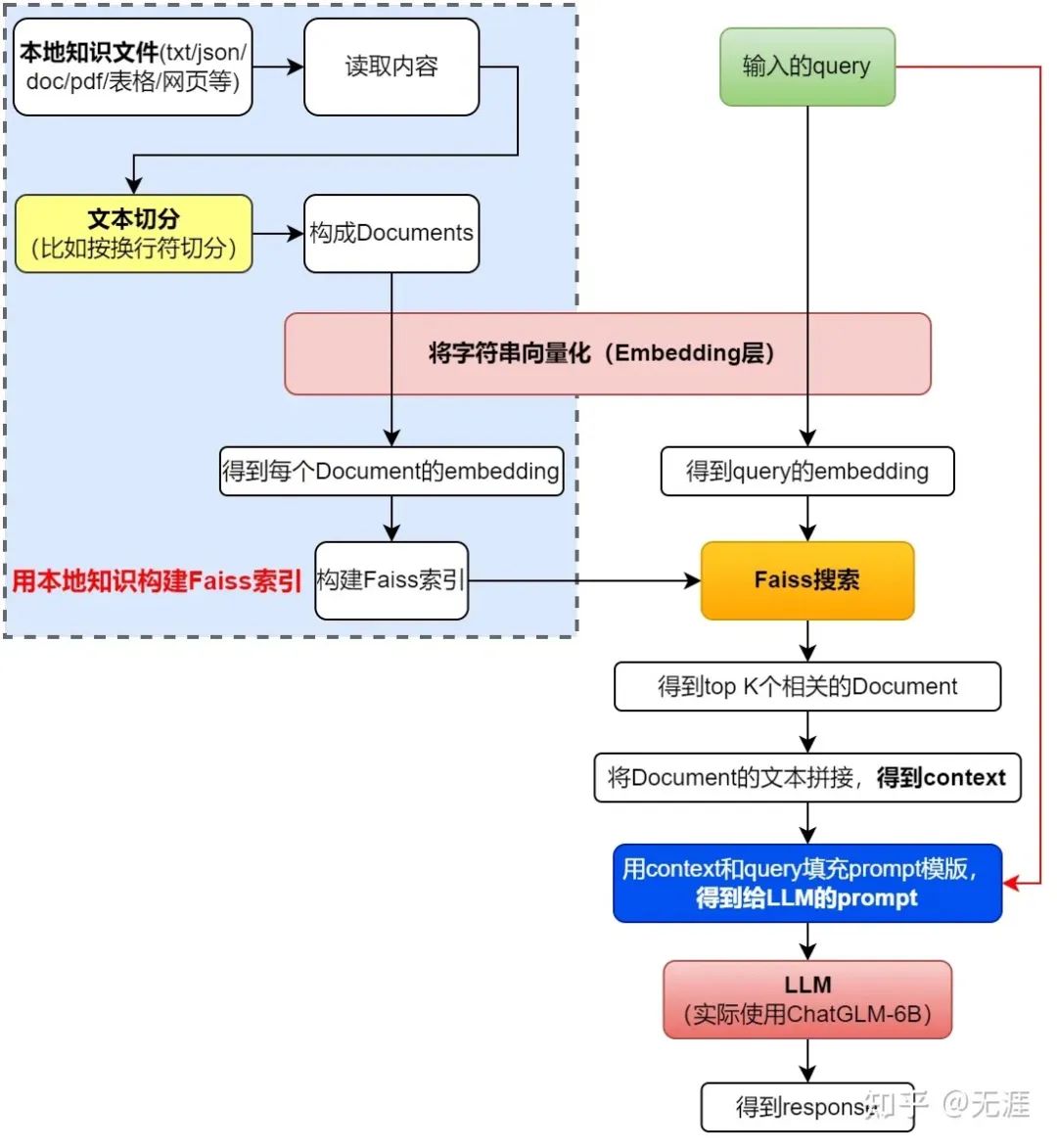
本项目实现原理如下图所示 (与基于文档的问答 大同小异,过程包括:1 加载文档 -> 2 读取文档 -> 3/4文档分割 -> 5/6 文本向量化 -> 8/9 问句向量化 -> 10 在文档向量中匹配出与问句向量最相似的top k个 -> 11/12/13 匹配出的文本作为上下文和问题一起添加到prompt中 -> 14/15提交给LLM生成回答 )
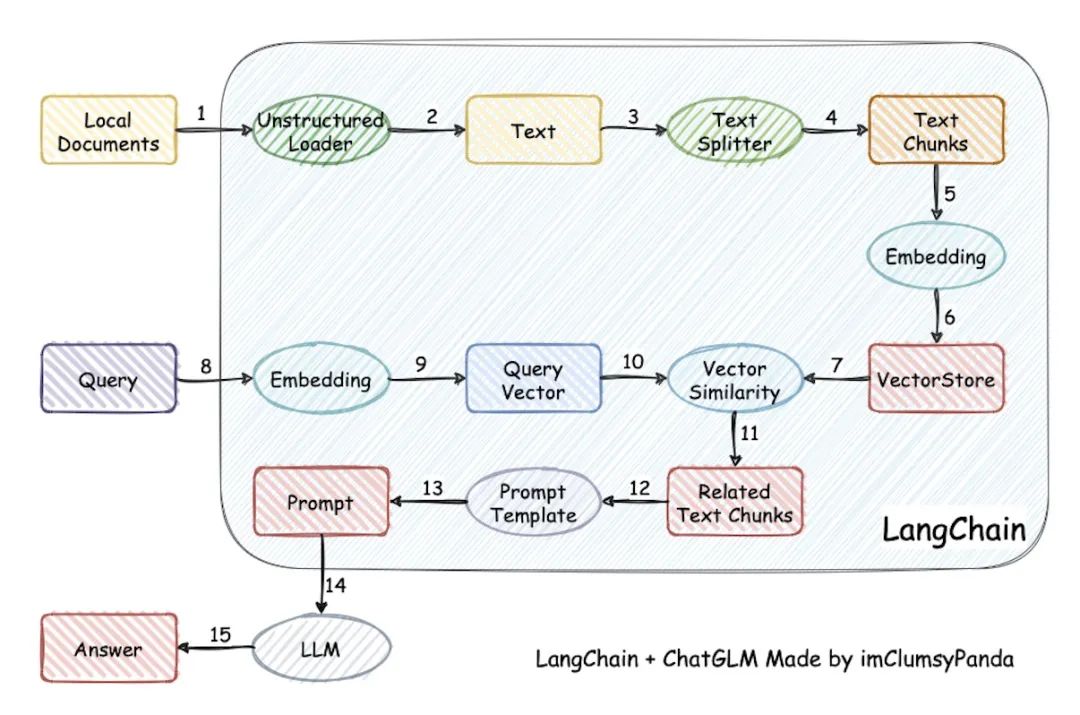
第一阶段:加载文件-读取文件-文本分割(Text splitter)
加载文件:这是读取存储在本地的知识库文件的步骤
读取文件:读取加载的文件内容,通常是将其转化为文本格式
文本分割(Text splitter):按照一定的规则(例如段落、句子、词语等)将文本分割
第二阶段:文本向量化(embedding)-存储到向量数据库
文本向量化(embedding):这通常涉及到NLP的特征抽取,可以通过诸如TF-IDF、word2vec、BERT等方法将分割好的文本转化为数值向量
存储到向量数据库:文本向量化之后存储到数据库vectorstore (FAISS,下一节会详解FAISS)
第三阶段:问句向量化
这是将用户的查询或问题转化为向量,应使用与文本向量化相同的方法,以便在相同的空间中进行比较
第四阶段:在文本向量中匹配出与问句向量最相似的top k个
这一步是信息检索的核心,通过计算余弦相似度、欧氏距离等方式,找出与问句向量最接近的文本向量
第五阶段:匹配出的文本作为上下文和问题一起添加到prompt中
这是利用匹配出的文本来形成与问题相关的上下文,用于输入给语言模型
第六阶段:提交给LLM生成回答
最后,将这个问题和上下文一起提交给语言模型(例如GPT系列),让它生成回答
比如知识查询
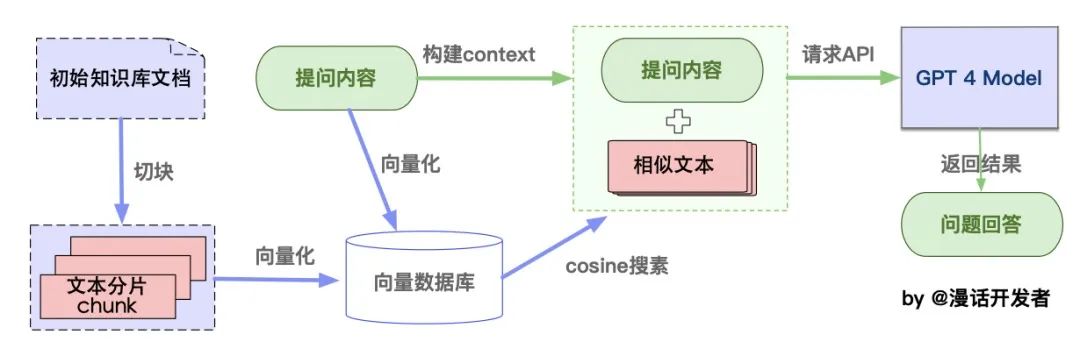
如你所见,这种通过组合langchain+LLM的方式,特别适合一些垂直领域或大型集团企业搭建通过LLM的智能对话能力搭建企业内部的私有问答系统,也适合个人专门针对一些英文paper进行问答,比如比较火的一个开源项目:ChatPDF,其从文档处理角度来看,实现流程如下:
2.2 Facebook AI Similarity Search(FAISS):高效向量相似度检索
Faiss的全称是Facebook AI Similarity Search (官方介绍页、GitHub地址),是FaceBook的AI团队针对大规模相似度检索问题开发的一个工具,使用C++编写,有python接口,对10亿量级的索引可以做到毫秒级检索的性能
简单来说,Faiss的工作,就是把我们自己的候选向量集封装成一个index数据库,它可以加速我们检索相似向量TopK的过程,其中有些索引还支持GPU构建
2.2.1 Faiss检索相似向量TopK的基本流程
Faiss检索相似向量TopK的工程基本都能分为三步:
得到向量库
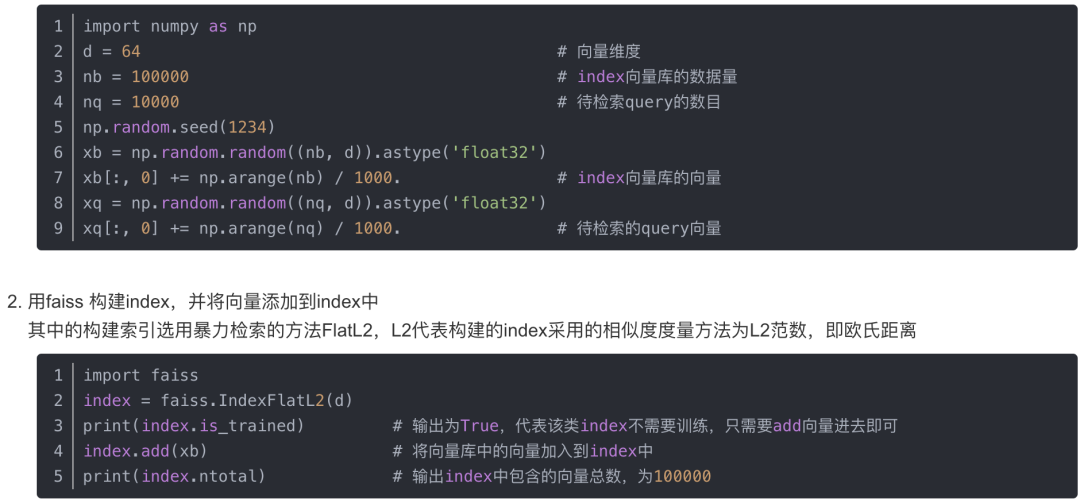
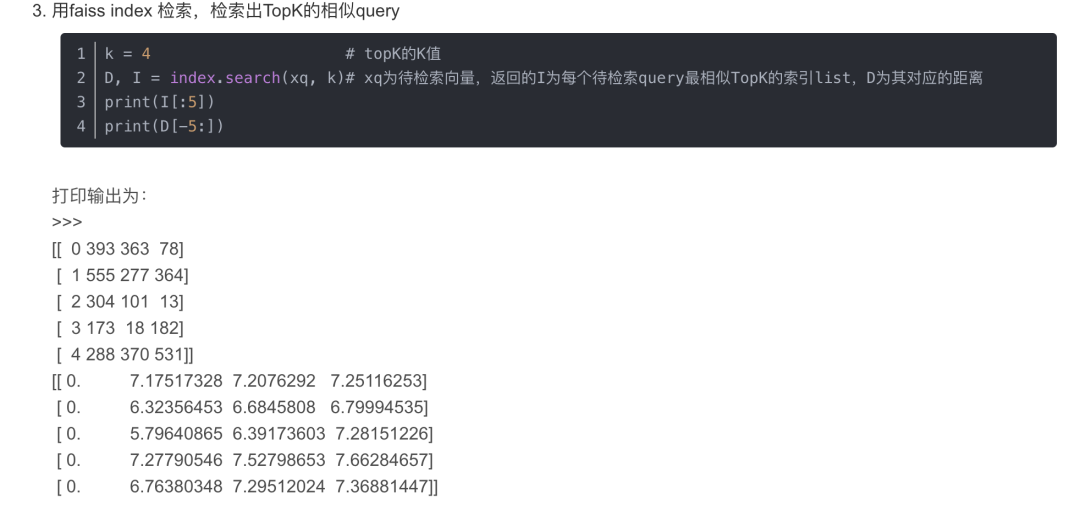

此文,现在faiss官方支持八种度量方式,分别是:
METRIC_INNER_PRODUCT(内积)
METRIC_L1(曼哈顿距离)
METRIC_L2(欧氏距离)
METRIC_Linf(无穷范数)
METRIC_Lp(p范数)
METRIC_BrayCurtis(BC相异度)
METRIC_Canberra(兰氏距离/堪培拉距离)
METRIC_JensenShannon(JS散度)
2.2.2.1 Flat :暴力检索
优点:该方法是Faiss所有index中最准确的,召回率最高的方法,没有之一;
缺点:速度慢,占内存大。
使用情况:向量候选集很少,在50万以内,并且内存不紧张。
注:虽然都是暴力检索,faiss的暴力检索速度比一般程序猿自己写的暴力检索要快上不少,所以并不代表其无用武之地,建议有暴力检索需求的同学还是用下faiss。
构建方法:

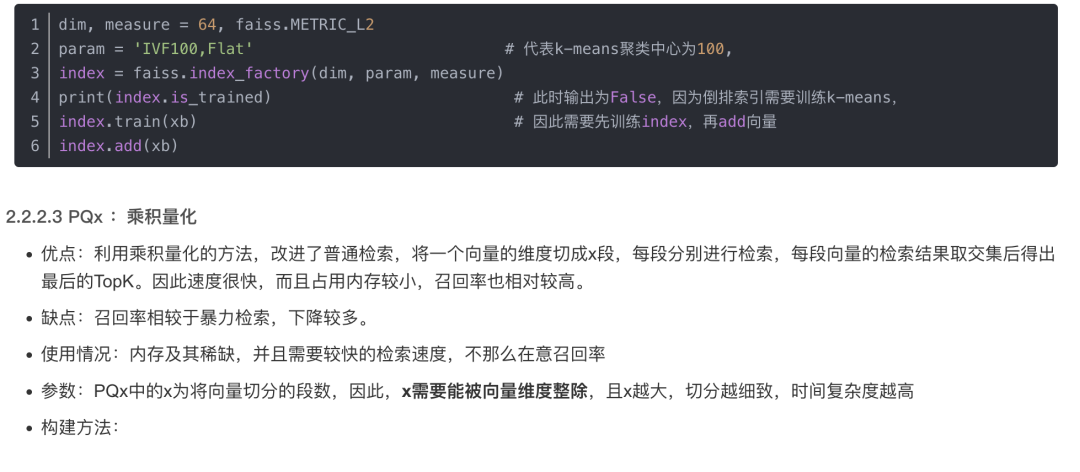
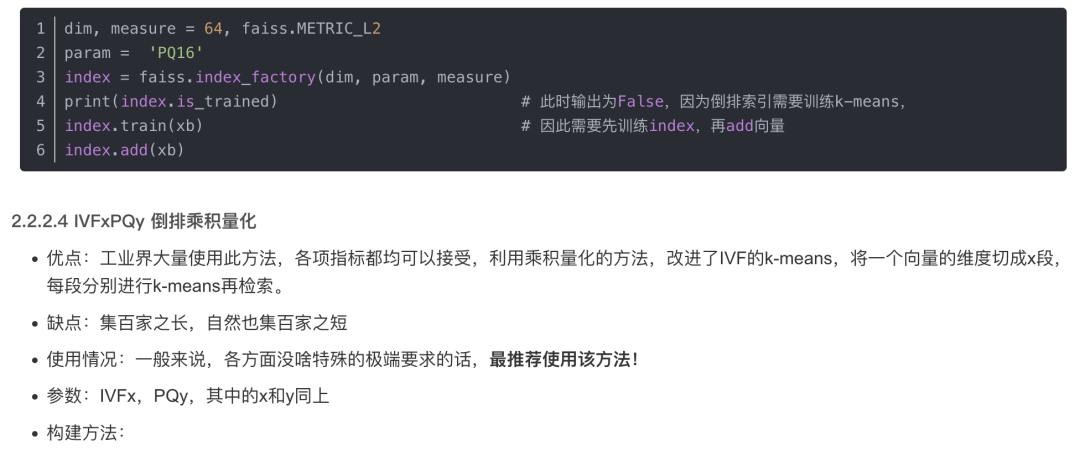
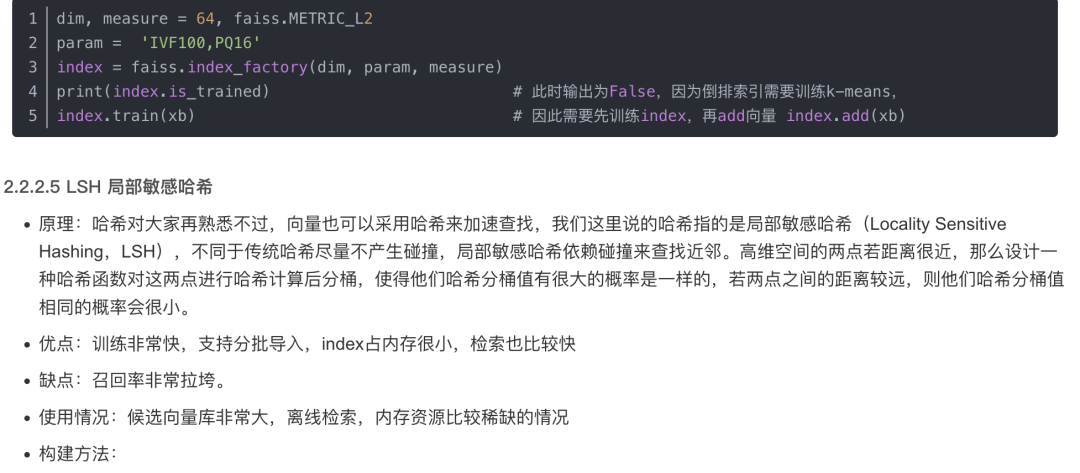
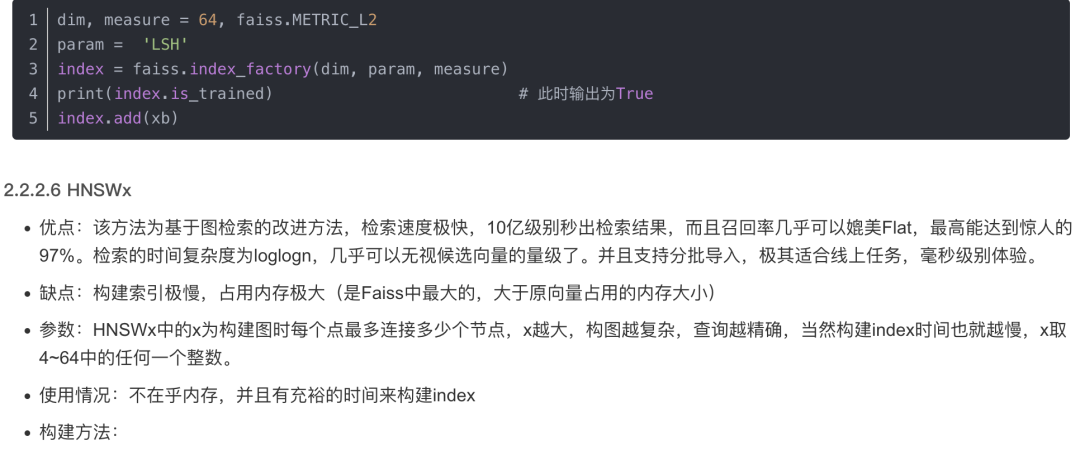

2.3 项目部署:langchain + ChatGLM-6B搭建本地知识库问答
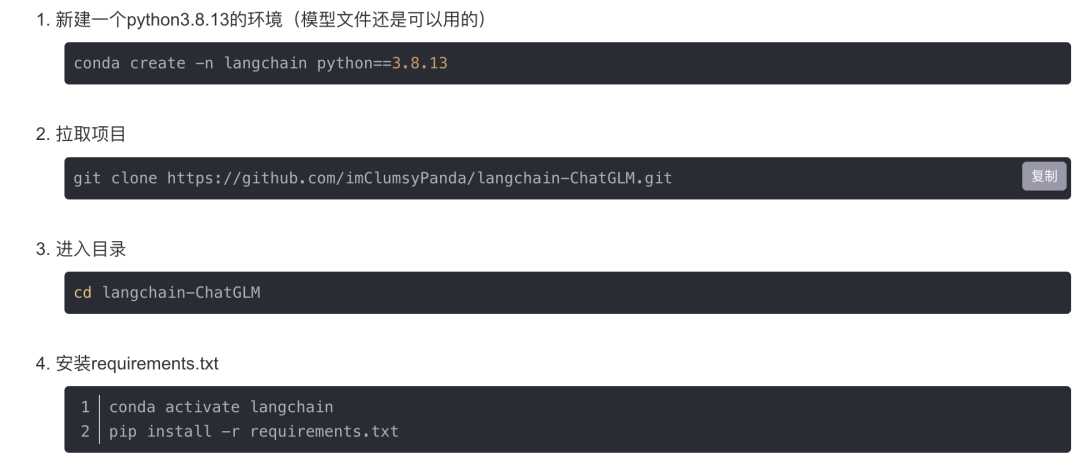
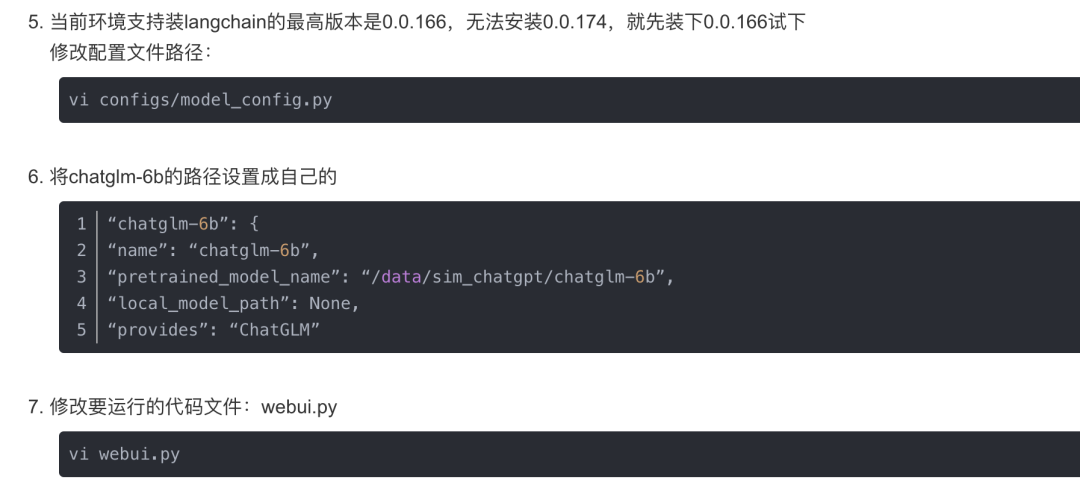
2.3.1 部署过程一:支持多种使用模式
其中的LLM模型可以根据实际业务的需求选定,本项目中用的ChatGLM-6B,其GitHub地址为:https://github.com/THUDM/ChatGLM-6B
ChatGLM-6B 是⼀个开源的、⽀持中英双语的对话语⾔模型,基于 General LanguageModel (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)
ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答

对应输出:
占用显存情况:大约15个G
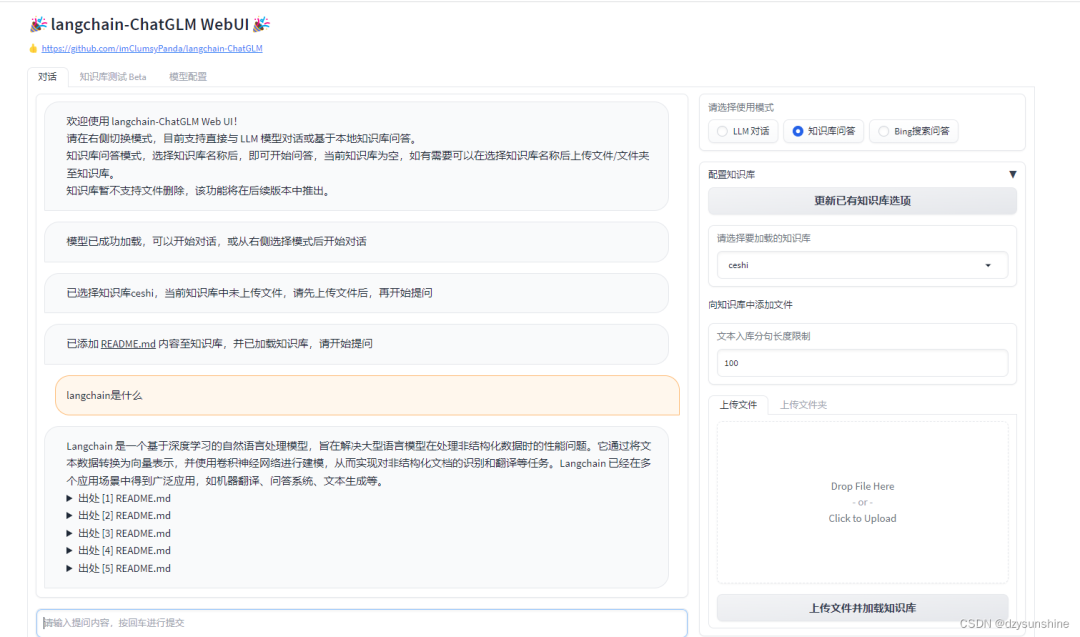
2.3.2 部署过程二:支持多种社区上的在线体验
项目地址:https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui
HUggingFace社区在线体验:https://huggingface.co/spaces/thomas-yanxin/LangChain-ChatLLM
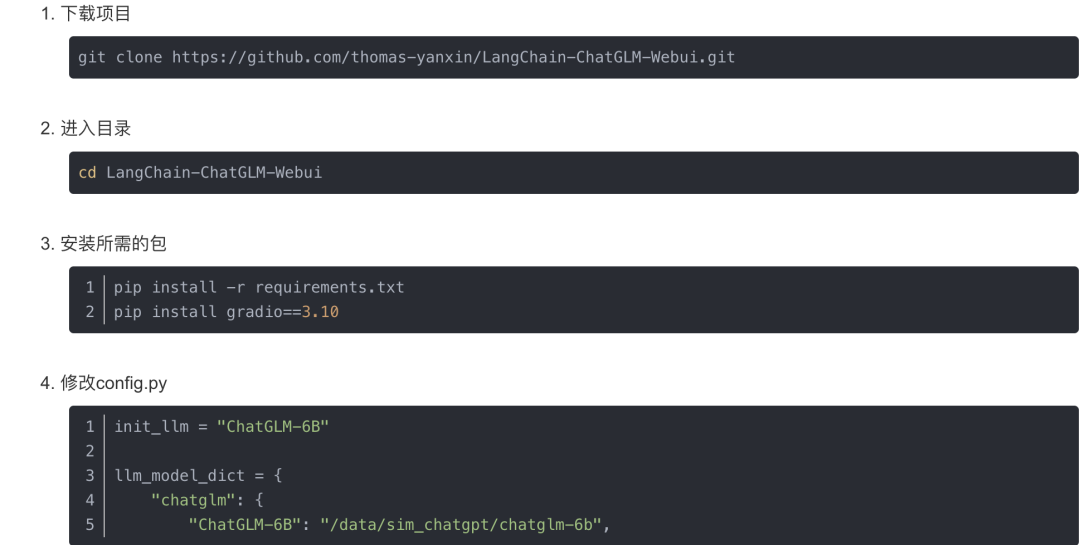

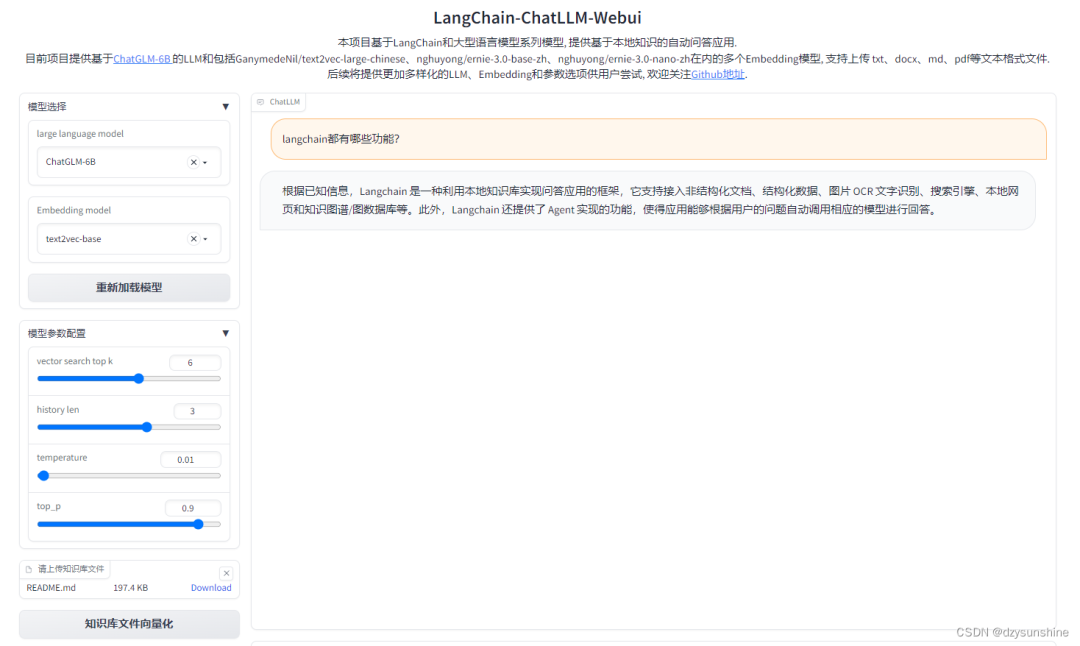
再回顾一遍langchain-ChatGLM这个项目的架构图
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一站式 AI 云服务平台
更多推荐

 18
18 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)