
Flink(1):开发环境的搭建(Java和scala)
一、实现功能流式开发Flink开发环境的搭建。二、实现步骤:Java开发环境【参考官网:https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/projectsetup/java_api_quickstart.html】1.本地环境(1)官网要求Maven 3.0.4 (or higher) and ...
一、实现功能
流式开发Flink开发环境的搭建。
二、实现步骤:Java开发环境
【参考官网:https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/projectsetup/java_api_quickstart.html】
1.本地环境
(1)官网要求
Maven 3.0.4 (or higher) and Java 8.x
(2)本地环境
Maven:3.3.9
Java 1.8
2.创建java项目
(1)进入项目目录,运行maven命令
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.7.2 \
-DarchetypeCatalog=local本地:
E:\Tools\WorkspaceforMyeclipse\flink_project>mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.7.2 -DarchetypeCatalog=local备注:添加DarchetypeCatalog参数,使创建项目更加快
(2)输入GAV对应参数
Define value for property 'groupId': com.bd.flink
Define value for property 'artifactId': flink-pro
Define value for property 'version' 1.0-SNAPSHOT: : 1.0
Define value for property 'package' com.bd.flink: :
Confirm properties configuration:
groupId: com.bd.flink
artifactId: flink-pro
version: 1.0
package: com.bd.flink
Y: : Y(3)查看创建结果
E:\Tools\WorkspaceforMyeclipse\flink_project>tree
卷 本地磁盘 的文件夹 PATH 列表
卷序列号为 0003-6793
E:.
└─flink-pro
└─src
└─main
├─java
│ └─com
│ └─bd
│ └─flink
└─resources3.导入idea
File-》Open-》导入项目pom.xml
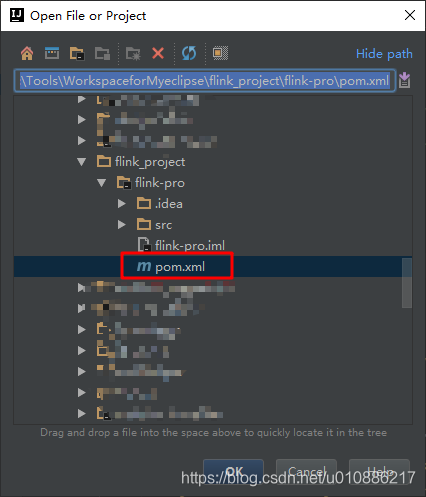
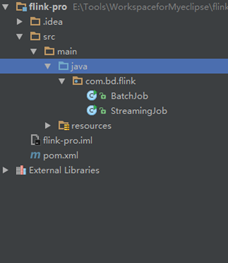
查看项目结构
4.项目打包
(1)使用maven命令
进入项目根目录,执行
E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro>mvn clean package
打包结果
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ flink-pro ---
[INFO] Building jar: E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro\target\flink-pro-1.0.jar
[INFO]
[INFO] --- maven-shade-plugin:3.0.0:shade (default) @ flink-pro ---
[INFO] Excluding org.slf4j:slf4j-api:jar:1.7.15 from the shaded jar.
[INFO] Excluding org.slf4j:slf4j-log4j12:jar:1.7.7 from the shaded jar.
[INFO] Excluding log4j:log4j:jar:1.2.17 from the shaded jar.
[INFO] Replacing original artifact with shaded artifact.
[INFO] Replacing E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro\target\flink-pro-1.0.jar with E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro\target\flink-pro-1.0-shaded.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 11.005 s
[INFO] Finished at: 2019-11-30T16:24:20+08:00
[INFO] Final Memory: 25M/184M
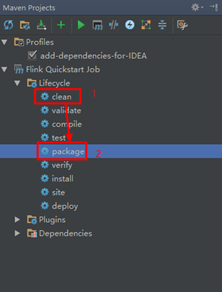
[INFO] ------------------------------------------------------------------------(2) 使用idea的maven打包工具
View-》Tools Windows-》Maven Projects-》clean+package
5.java开发WordCount项目实例
(1)四步
第一步:创建开发环境(set up the batch execution environment)
第二步:读取数据
第三步:开发业务逻辑(transform operations)
第四步:执行程序(execute program)
(2)代码
package com.bd.flink._1130application;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* Created by Administrator on 2019/11/30.
* wordcount代码:java实现
*/
public class BatchWCJava {
public static void main(String[] args) throws Exception {
String input="data\\hello.txt";
//第一步:创建开发环境(set up the batch execution environment)
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//第二步:读取数据
DataSource<String> text=env.readTextFile(input);
//第三步:开发业务逻辑(transform operations)
text.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] tokens=value.toLowerCase().split(" ");
for (String token : tokens) {
if(token.length()>0){
collector.collect(new Tuple2<String,Integer>(token,1));
}
}
}
}).groupBy(0).sum(1).print();
// 第四步:执行程序(execute program)
// execute(), count(), collect(), 或者print()都是执行算子,运行即可
// env.execute("Flink Batch Java API Skeleton");
}
}(3)运行结果
其中flink_project\flink-pro\data\hello.txt内容
flink hadoop storm
flume spark streaming
is excellent执行结果
(is,1)
(streaming,1)
(excellent,1)
(hadoop,1)
(flink,1)
(flume,1)
(storm,1)
(spark,1)三、实现步骤:scala环境
1.本地环境
(1)官网要求
Maven 3.0.4 (or higher) and Java 8.x
(2)本地环境
Maven:3.3.9
Java 1.8
2.创建java项目
(1)进入项目目录,运行maven命令
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=1.7.2 \
-DarchetypeCatalog=local本地:
E:\Tools\WorkspaceforMyeclipse\flink_project>mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeVersion=1.7.2 -DarchetypeCatalog=local备注:添加DarchetypeCatalog参数,使创建项目更加快
(2)输入GAV对应参数
Define value for property 'groupId': com.bd.flink
Define value for property 'artifactId': flink-pro-scala
Define value for property 'version' 1.0-SNAPSHOT: : 1.0
Define value for property 'package' com.bd.flink: :
Confirm properties configuration:
groupId: com.bd.flink
artifactId: flink-pro-scala
version: 1.0
package: com.bd.flink
Y: : Y(3)查看创建结果
E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro-scala>tree
卷 本地磁盘 的文件夹 PATH 列表
卷序列号为 0003-6793
E:.
└─src
└─main
├─resources
└─scala
└─com
└─bd
└─flink3.导入idea
File-》Open-》导入项目pom.xml
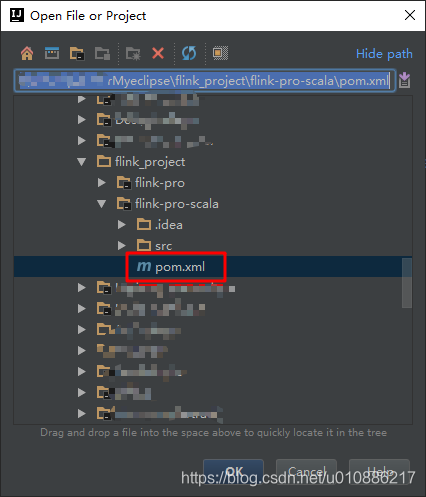
查看项目结构
4.项目打包
(1)使用maven命令
进入项目根目录,执行
E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro-scala>mvn clean package 打包结果
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ flink-pro-scala ---
[INFO] Building jar: E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro-scala\target\flink-pro-scala-1.0.jar
[INFO]
[INFO] --- maven-shade-plugin:3.0.0:shade (default) @ flink-pro-scala ---
[INFO] Excluding org.slf4j:slf4j-api:jar:1.7.15 from the shaded jar.
[INFO] Excluding org.slf4j:slf4j-log4j12:jar:1.7.7 from the shaded jar.
[INFO] Excluding log4j:log4j:jar:1.2.17 from the shaded jar.
[INFO] Replacing original artifact with shaded artifact.
[INFO] Replacing E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro-scala\target\flink-pro-scala-1.0.jar with E:\Tools\WorkspaceforMyeclipse\flink_project\flink-pro-scala\target\flink-pro-scala-1.0-shaded.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 24.117 s
[INFO] Finished at: 2019-11-30T18:02:59+08:00
[INFO] Final Memory: 16M/199M
[INFO] ------------------------------------------------------------------------(2)使用idea的maven打包工具
View-》Tools Windows-》Maven Projects
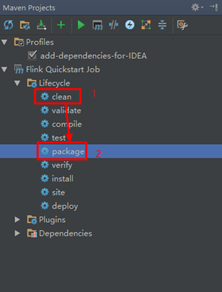
5.修改scala版本
自动生成scala版本默认为2.11.12
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.7.2</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.12</scala.version>
</properties>而本地开发环境的式11.8,所以会报错:Cannot resolve reference read TextFile with such signature
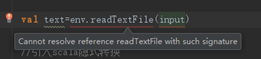
解决方法:即修改为2.11.8
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.7.2</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<!--<scala.version>2.11.12</scala.version>-->
<scala.version>2.11.8</scala.version>
</properties>6.scala开发WordCount项目实例
(1)四步
第一步:创建开发环境
第二步:读取数据
第三步:开发业务逻辑(transform operations)
第四步:执行程序(execute program)
(2)代码
package com.bd.flink._1130WordCount
import org.apache.flink.api.scala.ExecutionEnvironment
/**
* Created by Administrator on 2019/11/30.
*/
object BatchWordCountScala {
def main(args: Array[String]): Unit = {
val input="data\\hello.txt"
//第一步:创建开发环境
val env=ExecutionEnvironment.getExecutionEnvironment
//第二步:读取数据
val text=env.readTextFile(input)
//第三步:开发业务逻辑(transform operations)
//引入scala隐式转换
import org.apache.flink.api.scala._
text.flatMap(_.toLowerCase.split(" "))
.filter(_.nonEmpty)
.map((_,1))
.groupBy(0)
.sum(1).print()
//第四步:执行程序(execute program)
//本地print为一个执行操作
}
}
(3)运行结果
其中flink_project\flink-pro\data\hello.txt内容
flink hadoop storm
flume spark streaming
is excellent执行结果
(is,1)
(streaming,1)
(excellent,1)
(hadoop,1)
(flink,1)
(flume,1)
(storm,1)
(spark,1)

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)