
Anaconda的开发环境介绍以及简单爬虫的应用
开发环境的介绍anaconda基于数据分析和机器学习的集成环境jupteranaconda提供的一个基于浏览器的可视化开发工具jupter的基本使用在终端汇总录入jupter notebook的指令启动Jupter可视化开发工具jupter notebook的指令录入对应的默认的目录结构就是终端对应的目录结构new->textfile :新建一个任意后缀名的文本文件new->pytho
·
开发环境的介绍
- anaconda
- 基于数据分析和机器学习的集成环境
- jupter
- anaconda提供的一个基于浏览器的可视化开发工具
jupter的基本使用
- 在终端汇总录入jupter notebook的指令启动Jupter可视化开发工具
- jupter notebook的指令录入对应的默认的目录结构就是终端对应的目录结构
- new->text file :新建一个任意后缀名的文本文件
- new->python 3 : 新建一个基于jupter的源文件(xxx.ipynb)
- cell : jupter源文件的一个编辑行
- cell 是可以分为两种不同的模式:
- code:用来编写和执行代码
- Markdown :编写笔记
- 快捷键的使用
- 插入cell :a,b
- 删除cell :x
- 执行cell :shift+enter
- 切换cell的模式:
- y :将Markdown模式的cell切换到code模式
- m :将code切换成Markdown
- 打开帮助文档:
- shift+tab
爬虫的相关概念
- 爬虫:就是通过编写程序,让其模拟浏览器上网,然后去互联网上抓取数据的过程
- 模拟:浏览器就是一款天然的爬虫工具
- 抓取:抓取一整张数据,抓取一整张数据中的局部数据
- 爬虫的分类:
- 通用爬虫:(数据的爬取)
- 抓取一整张页面源码数据
- 聚焦爬虫:(数据解析)
- 抓取局部的指定数据。是建立在通用爬虫基础之上的!
- 增量式爬虫:(数据的更新)
- 监测网站数据更新的情况!抓取网站最新更新出来的数据
- 分布式爬虫:
- 通用爬虫:(数据的爬取)
- 反爬机制:
- 一些网站后台会设定相关的机制阻止爬虫程序进行数据的爬取。这些机制是网站后台设定的反爬机制。
- 反反爬策略
- 爬虫需要制定相关的策略破解反爬机制,从而可以爬取到网站的数据。
- 第一个反爬机制:
- robots协议是一个存在于服务器的一个文本协议。指明了该网站中哪些数据可以爬取,哪些不可以爬取
requests模块
- urllib模块:基于模拟浏览器上网的模块。网络请求的模块
- requests模块:基于网络请求的模块
- 作用:模拟浏览器上网
- requests模块的编码流程:
- 指定url
- 发起请求
- 获取响应数据(爬取到的数据)
- 持久化存储
# 导入requests包
import requests
# 1.爬取搜狗首页的页面源码数据
url = 'https://www.sogou.com/'
response = requests.get(url=url)
page_text = response.text # text返回的是字符串形式的响应数据
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
# 2.简易的网页采集器
# 设计到的知识点:参数动态化,UA伪装,乱码的处理
word = input('enter a key word:')
url = 'https://www.sogou.com/web'
# 参数动态化:将请求参数封装成字段作用到get方法的params参数中
params = {
'query':word
}
response = requests.get(url=url,params=params)
page_text = response.text
fileName = word+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(word,'下载成功!')
以上代码通过输入搜索的关键词,效果图如下: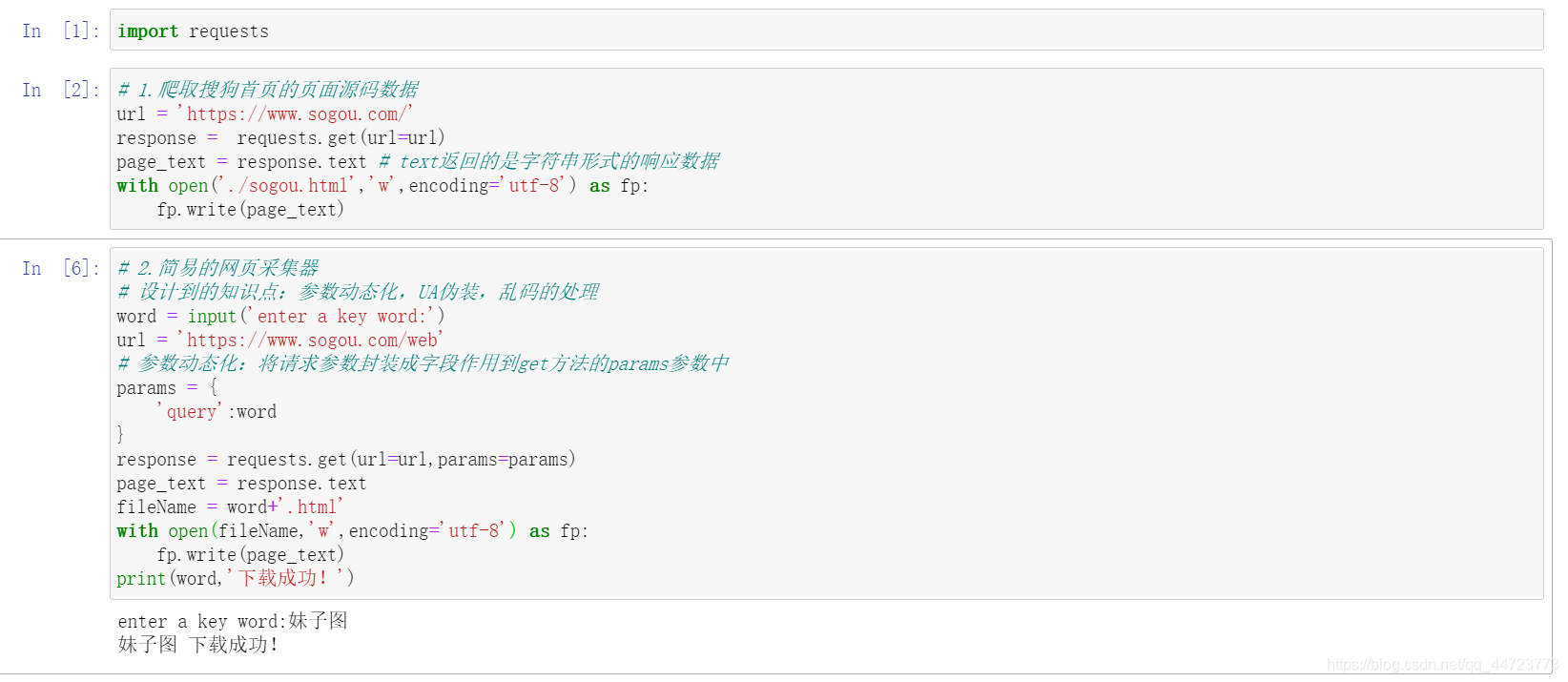
回到文件夹所在位置,可以看到刚才爬取的网页,打开后看到的效果如下:
- 上述代码出现的问题:
- 乱码问题
- 爬取数据丢失
那么下面是对乱码的处理:
# 乱码处理
word = input('enter a key word:')
url = 'https://www.sogou.com/web'
# 参数动态化:将请求参数封装成字段作用到get方法的params参数中
params = {
'query':word
}
response = requests.get(url=url,params=params)
# 可以修改响应数据的编码
response.encoding = 'utf-8' # 手动修改了响应对象的编码格式
page_text = response.text
fileName = word+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(word,'下载成功!')
处理完乱码后,但是还是没有出现想要的效果
- 什么叫异常的访问请求?
- 在爬虫中正常的访问请求指的是通过真实的浏览器发起的访问请求。
- 异常的访问请求:通过非浏览器发起的请求。(爬虫程序模拟的请求发送)
- 正常的访问请求和异常的访问请求的判别方式是什么?
- 是通过请求头中的User-Agent判别。
- User-Agent:请求载体的身份标识
- 目前请求的载体可以是:浏览器,爬虫
- 反爬机制:
- UA检测:网站后台会检测请求载体的身份标识(UA)是不是浏览器
- 是:正常的访问请求
- 不是:异常的访问请求
- 反反爬策略:
- UA伪装:
- 将爬虫对于的请求载体身份标识伪装/篡改成浏览器的身份标识
- User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36
- UA伪装:
import requests
# UA伪装
word = input('enter a key word:')
url = 'https://www.sogou.com/web'
# 参数动态化:将请求参数封装成字段作用到get方法的params参数中
params = {
'query':word
}
# UA伪装
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
# 将伪装的UA作用到了请求的请求头中
response = requests.get(url=url,params=params,headers=headers)
# 可以修改响应数据的编码
response.encoding = 'utf-8' # 手动修改了响应对象的编码格式
page_text = response.text
fileName = word+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(word,'下载成功!')
总结
- 总结:
- get方法的参数:
- url
- params
- headers
- get方法的返回值:
- response - response的属性:
- text :字符串形式的响应数据
- get方法的参数:

一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)