
人工智能发展历程
AI
目录
文章目录
人工智能发展流派
人工智能的发展历程中,主要形成了三大技术流派:符号主义、联结主义和行为主义。它们在理论基础、研究方向和应用场景上各有侧重,并随着技术的发展交叉融合形成新的研究方向。
- 符号主义:以规则见长,在可解释性要求高的领域持续发力;
- 联结主义:依托数据与算力,主导当前 AI 技术前沿;
- 行为主义:聚焦物理世界交互,推动机器人技术进步。 未来,技术融合(如知识增强的深度学习)和场景创新(如人机协作设计)将成为突破方向。
符号主义(Symbolicism)
核心理念:通过 “逻辑符号” 和 “规则系统” 模拟人类抽象思维,强调知识的显式表示与推理能力。
发展历程:
- 黄金时期:20世纪70-80年代,以专家系统(如IBM深蓝)为代表,通过知识库和推理机解决特定领域问题。
- 瓶颈与复兴:因手动构建知识库成本高、泛化能力弱而衰落,但近年与联结主义结合,形成知识图谱等混合模型。
发展方向:
- 知识工程与混合推理:结合深度学习,构建可解释的知识图谱(如医疗诊断系统)。
- 逻辑与规则的自动化学习:研究如何从数据中自动提取规则,降低人工干预成本。
应用场景:
- 医疗诊断:基于规则的辅助诊断系统(如黑色素瘤早期筛查)。
- 金融风控:通过逻辑规则评估风险维度,如蚂蚁集团0.1秒内完成百项风险评估。
- 博弈领域:如深蓝击败国际象棋冠军,依赖预编程规则与棋谱库。
联结主义(Connectionism)
核心理念:模仿人脑神经网络结构,通过数据驱动学习特征与模式,以深度学习为代表。
发展历程:
- 早期探索:1957年感知机模型因无法处理非线性问题遇冷,1980年代反向传播算法(BP)推动复兴。
- 爆发期:2010年后,算力与大数据支撑深度学习突破,在图像识别、自然语言处理等领域占据主导。
发展方向:
- 大模型与通用智能(AGI):如GPT系列、盘古气象大模型,向多模态、跨领域通用化发展。
- 模型轻量化与专用化:优化计算效率,发展领域专用模型(如医疗影像分析)。
应用场景:
- 计算机视觉:ImageNet竞赛中ResNet模型错误率降至3.57%,推动工业质检精度超99.97%。
- 自然语言处理:ChatGPT实现对话生成,GitHub Copilot提升代码编写效率55%。
- 自动驾驶:特斯拉Autopilot依赖2000多个神经网络模型实现环境感知。
行为主义(Actionism)
核心理念:通过环境交互与反馈机制学习智能行为,强调 “感知-动作” 闭环,以强化学习为核心。
发展历程:
-
早期实践:1989年麻省理工学院六足机器人Genghis,依赖简单控制规则适应复杂地形。
-
现代突破:波士顿动力Atlas机器人通过强化学习实现92.3%复杂地形行动成功率。
发展方向:
- 具身智能:赋予AI物理载体(如人形机器人),实现动态环境适应。
- 群体智能协作:多智能体协同完成复杂任务(如物流机器人集群)。
应用场景:
- 机器人控制:工业机械臂协同作业、养老助行设备(如外骨骼)。
- 智能物流:AGV 小车通过环境感知优化路径,提升仓储效率。
- 游戏 AI:AlphaGo利用强化学习击败围棋冠军,推动策略优化算法发展。
交叉融合
- 多模态融合:结合符号主义的逻辑推理与联结主义的特征学习,例如医疗AI同时分析CT影像(视觉)与病历文本(语言)。
- 跨领域协同:智能工厂集成感知(传感器)、决策(调度算法)与行为控制(机械臂),产能提升30%。
- 伦理与可解释性:符号主义助力解决深度学习“黑箱”问题,构建可信AI系统。
人工智能发展史时间线

一、理论奠基与萌芽期(1940s-1956)
1943 年:人工神经元数据模型的提出
美国神经科学家沃伦·斯特·麦卡洛克(Warren McCulloch)和逻辑学家沃尔特·皮茨(Walter Pitts)提出第一个简化的神经元数学模型,称为 M-P 模型,为神经网络奠定了数学基础。
MP 模型将神经元视为二进制开关,通过加权输入和阈值来判断神经元的激活状态。
- 加权输入:
- 阈值:
- 激活条件:加权输入≥ 阈值
联接主义 AI 学派(Connectionism):又称:仿生学派或生理学派。 源于仿生学,特别是人脑模型的研究。核心思想是:认为人的智能归结为人脑的高层活动的结果,强调智能活动是由大量简单的单元通过复杂链接后并行运行的结果,其原理是神经网络及神经网络间的连接机制与学习算法。代表成果:人工神经网络,深度神经网络。
神经元数学模型:神经元数学模型是神经网络的基础。每个神经元将最初的输入值乘以一定的权重,并加上其他输入到这个神经元里的值(并结合其他信息值),最后算出一个总和,再经过神经元的偏差调整,最后用激励函数把输出值标准化。这一模型模拟了生物神经元的信息处理过程。
1950 年:图灵测试与计算理论
艾伦·图灵(Alan Turing)提出了 “图灵测试”,通过自然语言对话来判断机器是否具有人类智能,定义了机器智能的哲学标准。使得机器智能的概念开始被广泛认知。
同年,图灵还提出通用图灵机理论,证明计算机可模拟任何逻辑过程。
同年,克劳德·香农提出了计算机下棋的构想。
1956 年:达特茅斯会议与 AI 学科的诞生
约翰·麦卡锡(John McCarthy)和马文·明斯基(Marvin Minsky)在达特茅斯会议中 “人工智能” 这一术语被正式提出,正式将 “人工智能” 定性为一门专业学科。
当时 AI 主流的研究方向聚焦在符号逻辑主义(Symbolic AI),主张通过规则与推理来模拟人类的思维。例如早期逻辑理论家(Logic Theorist)程序使用符号推理证明数学定理,验证符号主义的可行性。
二、符号主义黄金期与第一次寒冬(1956-1980)
1957 年:感知机模型
弗兰克·罗森布拉特(Frank Rosenblatt)基于 MP 模型再进一步发明并在 IBM-704 计算机上实现了一种新的神经元数学模型,称为感知机模型(Perceptron),现在也将其称为一种单层神经网络,这是早期神经网络研究的一个重要里程碑。
感知机模型支持通过权重的调整来实现线性的分类。数学公式如下:
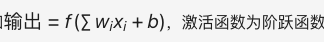
但感知机模型无法解决异或(XOR)等非线性的分类问题,这也成为了后续业界批评的焦点。
感知机是二分类的线性模型,其输入是实例的特征向量,输出的是事例的类别(+1和-1)。感知机学习的目标是求得一个能够将训练数据集正实例点和负实例点完全正确分开的分离超平面。如果数据是线性可分的,感知机就能找到一个这样的超平面。感知机由Rosenblatt于1957年提出,是神经网络和支持向量机的基础。
线性分类:指存在一个线性方程可以把待分类数据分开。线性分类模型的核心思想是将输入特征和输出类别之间的关系建模为一个线性关系,从而实现对数据集的分类。常见的线性分类方法有感知机、最小二乘法等。
非线性分类:指不存在一个线性分类方程把数据分开。对于非线性可分的数据,一般的方法是先对数据进行空间映射,把数据映射到可以进行线性分类的空间中去,然后再用线性分类方法进行处理。
1958 年:LISP 符号逻辑编程语言与逻辑回归模型
约翰·麦卡锡是一名符号逻辑编程科学家,开发了 LISP 编程语言,作为符号逻辑主义 AI 研究的主要工具。
同年,大卫·考克斯提出了逻辑回归模型,这是一种线性分类模型,结构与感知机相似,但使用了 Sigmoid 激活函数来替代阶跃函数,目的是最大化线性分类的准确性。Sigmoid 函数的数学公式如下: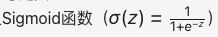
逻辑回归模型:是一种广义的线性回归模型,它通过使用逻辑函数(通常是sigmoid函数)来预测一个事件发生的概率。逻辑回归模型在分类问题中广泛应用,尤其是二分类问题。
1959 年:机器学习的定义
同期,亚瑟·塞缪尔提出了机器学习的概念,一个旨在让计算机能够自主学习而无需显式编程的研究领域。
机器学习:它使计算机能够在不进行明确编程的情况下从数据中学习并做出预测或决策。机器学习算法通过从训练数据中学习规律,然后应用这些规律对新数据进行预测或分类。
1961 年:基于 AI 的模式识别
伦纳德·乌尔和查尔斯·沃斯勒发表了一篇关于模式识别的论文,描述了他们尝试利用机器学习或自组织过程来设计模式识别程序。
1967 年:KNN 分类算法
托马斯等人提出了K最近邻(KNN)算法,这是一种基于实例最近邻数据的分类方法。
K最近邻(KNN)算法:是一种基于实例的学习算法,用于分类和回归问题。它的原理是根据样本之间的距离来进行预测。具体地,对于给定的未知样本,计算它与训练集中每个样本的距离,然后选择K个距离最近的样本进行投票或计算平均值,以确定待分类样本的类别或预测其数值。
1968 年:专家系统 DENDRAL
爱德华·费根鲍姆使用 LISP 语言开发了第一个专家系统 DENDRAL,并定义了 “知识库” 这一概念。该系统在化学领域拥有丰富的知识,能够通过质谱数据推断分子结构,这标志着人工智能史上第二次浪潮的开始。
DENDRAL 通过规则库(IF-THEN 规则)与反向推理链来模拟专家决策,从质谱数据推断分子结构。
作为逻辑符号主义 AI 技术的首个落地应用,标志了基于逻辑符号主义 AI 技术的知识工程的兴起。
1966 年:感知机模型的局限性引发了第一次 AI 寒冬
马文·明斯基和佩珀特发表了著作《感知器》,在书中证明单层感知机模型无法解决 XOR 此类非线性分类问题,这一发现导致神经网络研究进入了一个长达十年的低谷期。
XOR问题:是一个经典的机器学习问题。XOR问题的特点是两个输入变量的输出结果是它们不同则为真(1),相同则为假(0)。这个问题不能用简单的线性分类器解决,因为它是一个非线性问题。
由于感知机模型的局限性,导致了业界 AI 投资和研究的方向转为符号逻辑主义 AI,但实际上专家系统的商业化困难重重,(如 XCON 仅适用于特定硬件配置),继而引发第一次 AI 寒冬。
同年,麻省理工学院的约瑟夫·魏岑鲍姆开发了 ELIZA 程序,使得人与计算机之间的自然语言对话成为可能,ELIZA 通过关键词匹配规则来生成回复。
1974 年:误差反向传播(BP 算法)的雏形
哈佛大学的保罗·沃博斯在其博士论文中首次提出了误差反向传播算法(BP 算法)的雏形,BP 算法的核心思想是通过链式法则来计算梯度,利用误差的导数(梯度)来调整权重,以期逐步减少误差,最终使人工神经网络具备 “万能近似” 的能力。但最初受限于算力未受重视。
是一种用于训练人工神经网络的算法。它通过计算网络输出与实际输出之间的误差,并将这个误差反向传播到网络的每一层,从而调整网络的权重和偏置,使网络的输出更接近实际输出。BP算法是神经网络训练中最常用的算法之一。
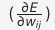
1975年:框架理论
马文·明斯基在论文《框架理论》中提出了结构化知识表示的学习框架,影响后续知识图谱发展。这成为了人工智能研究的一个关键转折点。
兰德尔·戴维斯致力于开发和维护庞大的知识库,并提出通过集成面向对象的模型可以增强知识库的开发、维护和应用的一致性。
1976 年:医疗专家系统 MYCIN
斯坦福大学的爱德华·肖特利夫等开发了首个用于诊断和治疗血液感染的医疗专家系统 MYCIN。
MYCIN 是一种基于规则的医学诊断专家系统,使用了 500 条医学规则和反向推理链,引入置信度计算(概率推理)来处理不确定性,继而辅助医生诊断,诊断准确率达 69%(高于人类专家)。
但因其依赖人工地编码知识,知识库维护成本高昂,难以扩展至复杂领域,无法大规模应用。
斯坦福大学的勒纳特发表了论文《启发式搜索在数学中的应用》,介绍了一个名为 “AM” 的程序,该程序利用大量启发式规则来探索新的数学概念,并重新发现了数百个数学中的标准概念和定理。
1979 年:人工智能下棋程序
汉斯·贝利纳开发的计算机程序在双陆棋比赛中战胜了世界冠军,这一成就标志着人工智能发展的一个重要里程碑。随后,在罗德尼·布鲁克斯和其他人的努力下,基于行为的机器人学迅速崛起,成为人工智能的一个重要分支。同时,格瑞·特索罗开发的自学双陆棋程序也为后来的强化学习研究奠定了基础。
强化学习:是一种机器学习技术,它通过与环境的交互来学习行为策略。在强化学习中,智能体(agent)通过尝试不同的行为来最大化某种累积奖励。强化学习在机器人控制、游戏AI等领域有广泛应用。
三、连接主义复兴与机器学习崛起(1980-2006)
1980 年:首届机器学习国际研讨会
卡内基梅隆大学(CMU)举办了首届机器学习国际研讨会,这标志着机器学习研究在全球范围内的兴起。
1982 年:Hopfield 网络与能量函数
约翰·霍普菲尔德(John Hopfield)发明了 Hopfield 网络,这是最早的递归神经网络(RNN)的原型。霍普菲尔德神经网络模型是一种单层反馈神经网络,具有从输出到输入的反馈连接,它的出现极大地激发了神经网络领域的兴趣。
引入了能量函数的概念,公式如下: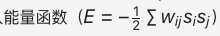
Hopfield 网络通过迭代更新神经元状态收敛到能量最小值,以此来解决组合优化问题(如旅行商问题) 。
递归神经网络(RNN):是一种能够处理序列数据的神经网络。它通过引入循环连接来捕捉序列中的时间依赖关系。RNN在语音识别、自然语言处理等领域有广泛应用。
1983 年:随机霍普菲尔德网络
特伦斯·谢诺夫斯基和杰弗里·欣顿等人发明了玻尔兹曼机,也称为随机霍普菲尔德网络,这是一种无监督模型,用于对输入数据进行重构以提取数据特征进行预测分析。
无监督模型:一种机器学习模型,它用于从未标记的数据中学习数据的结构和分布。无监督学习的主要任务包括聚类、降维等。常见的无监督学习算法有K均值聚类、主成分分析等。
有监督模型:是一种机器学习模型,它使用标记的数据集进行训练。在有监督学习中,模型通过学习输入和输出之间的映射关系来进行预测或分类。常见的有监督学习算法有线性回归、逻辑回归、支持向量机等。
1985 年:贝叶斯网络
朱迪亚·珀尔提出了贝叶斯网络,他以倡导人工智能的概率方法和发展贝叶斯网络而闻名,还因发展了一种基于结构模型的因果和反事实推理理论而受到赞誉。
贝叶斯网络是一种模拟人类推理过程中因果关系的不确定性处理模型,如常见的朴素贝叶斯分类算法就是贝叶斯网络最基本的应用。
1986 年:反向传播算法的普及
Rumelhart、Hinton 和 Williams 提出了多层感知机(MLP)与反向传播(BP)训练相结合的理念,解决了单层感知器无法进行非线性分类的问题,开启了神经网络的新高潮;
通过链式法则计算损失函数对网络权重的梯度,逐层反向传播误差信号,解决多层网络训练难题,推动神经网络实用化。数学表达式为:
1989 年:万能近似定理的提出
乔治·西本科,提出万能近似定理,证明了单隐藏层神经网络可逼近任意的连续函数,奠定了深度学习理论基础。
乔治·西本科证明了 “万能近似定理”,简单来说,多层前馈网络可以近似任意函数,其表达力与图灵机等价,从根本上消除了对神经网络表达力的质疑;
深度学习:是一种机器学习技术,它使用深层神经网络来模拟人脑的学习过程。深度学习通过构建多层次的神经网络结构,能够自动地提取数据的特征并进行复杂的模式识别。深度学习在自然语言处理、计算机视觉等领域取得了重大突破。
1989 年:卷积神经网络(CNN)
扬·勒丘恩结合反向传播算法与权值共享的卷积神经层发明了卷积神经网络(CNN),并首次将CNN成功应用于美国邮局的手写字符识别系统中。CNN通常由输入层、卷积层、池化层和全连接层组成,卷积层负责提取图像中的局部特征,池化层用于降低参数量级,全连接层则输出结果。
卷积神经网络(CNN):一种专门用于处理图像数据的神经网络。它通过卷积层、池化层等结构来捕捉图像中的局部特征和空间关系。CNN在图像分类、目标检测等领域有卓越的性能。
1995 年:支持向量机(SVM)
Cortes 和 Vapnik 提出了支持向量机,通过核函数(如高斯核)将数据映射到高维空间,寻找最大间隔超平面进行分类,核函数处理非线性问题。优化目标为:
它在处理小样本、非线性及高维模式识别问题时展现了显著的优势,并能扩展到函数拟合等其他机器学习问题。SVM是在感知机基础上的改进,基于统计学习理论的VC维理论和结构风险最小化原则,与感知机的主要区别在于SVM寻找的是最大化样本间隔的超平面,具有更强的泛化能力,并通过核函数处理线性不可分问题;
1997 年:深蓝超级计算机
IBM 的深蓝超级计算机战胜了国际象棋世界冠军加里·卡斯帕罗夫,深蓝通过穷举所有可能的走法并执行深度搜索来实现智能。
1997 年:LSTM 网络
Sepp Hochreiter 和 Jürgen Schmidhuber 提出了长短期记忆网络(LSTM),这是一种复杂的循环神经网络,通过引入遗忘门、输入门和输出门等门控机制来解决 RNN 长序列训练中的梯度消失问题。提升序列建模能力。
1998 年:语义网
蒂姆·伯纳斯-李提出了语义网的概念,目的是通过添加计算机可理解的语义元数据,使互联网成为一个基于语义链接的通用信息交换媒介。通过 RDF 三元组(实体-关系-实体)构建结构化知识库,推动符号主义与连接主义的融合。
2003 年:LDA 主题模型
David Blei, Andrew Ng 和 Michael I. Jordan 提出了 LDA,这是一种无监督学习方法,用于推测文档的主题分布。公式化表示为: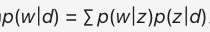
四、深度学习革命与大模型时代(2006 至今)
2006 年:深度信念网络(DBN)
杰弗里·辛顿(Geoffrey Hinton)和他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度信念网络(DBN)的概念,采用受限玻尔兹曼机(RBM)对多层神经网络进行逐层预训练,通过对比散度算法调整权重,解决梯度消失问题和深层网络初始化难题。为深层网络训练提供可行方案。
开启了深度学习在学术界和工业界的浪潮,辛顿也因此被誉为深度学习之父。深度学习使用多层隐藏层网络结构,通过大量的向量计算来学习数据的高阶表示。
2010 年:迁移学习
Sinno Jialin Pan 和 Qiang Yang 发表了关于迁移学习的调查文章。迁移学习是利用已有知识(如训练好的网络权重)来学习新知识以适应特定目标任务的方法,核心在于找到已有知识和新知识之间的相似性。
2011 年:IBM Watson问答机器人
IBM Watson 问答机器人参与 Jeopardy 回答测验比赛最终赢得了冠军。Waston 是一个集自然语言处理、知识表示、自动推理及机器学习等技术实现的电脑问答(Q&A)系统。
2012 年:AlexNet 与卷积神经网络(CNN)
Hinton 和他的学生 Alex Krizhevsky 设计的 AlexNet 神经网络模型在 ImageNet 竞赛大获全胜,第一个深度神经网络算法,这是史上第一次有模型在 ImageNet 数据集表现如此出色,并引爆了神经网络的研究热情。
AlexNet 是一个经典的卷积神经网络(CNN)模型,主要应用于计算机视觉领域。在数据、算法及算力层面均有较大改进,创新地应用了 Data Augmentation、ReLU、Dropout 和 LRN 等方法,并使用 GPU 加速网络训练。
使用 ReLU 激活函数加速收敛,引入 Dropout 层随机屏蔽神经元防止过拟合,并应用了 GPU 加速训练,使其在 ImageNet 竞赛中实现 Top-5 错误率 15.3% 的突破。

AlexNet神经网络模型:是一种深度卷积神经网络模型,它在2012年的ImageNet图像分类竞赛中取得了显著的成绩。AlexNet通过引入ReLU激活函数、Dropout等技术,提高了神经网络的性能和泛化能力。
2012 年:谷歌知识图谱
谷歌正式发布谷歌知识图谱(Google Knowledge Graph),它是 Google 的一个从多种信息来源汇集的知识库,通过 Knowledge Graph 来在普通的字串搜索上叠一层相互之间的关系,协助使用者更快找到所需的资料的同时,也可以知识为基础的搜索更近一步,以提高 Google 搜索的质量。
知识图谱是结构化的语义知识库,是符号主义思想的代表方法,用于以符号形式描述物理世界中的概念及其相互关系。其通用的组成单位是 RDF 三元组(实体-关系-实体),实体间通过关系相互联结,构成网状的知识结构。
2013 年:变分自编码器
Durk Kingma 和 Max Welling 在 ICLR 上以文章《Auto-Encoding Variational Bayes》提出变分自编码器(Variational Auto-Encoder,VAE)。VAE 基本思路是将真实样本通过编码器网络变换成一个理想的数据分布,然后把数据分布再传递给解码器网络,构造出生成样本,模型训练学习的过程是使生成样本与真实样本足够接近。
2014 年:生成对抗网络
Goodfellow 及 Bengio 等人提出生成对抗网络(Generative Adversarial Network,GAN),被誉为近年来最酷炫的神经网络。
GAN 是基于强化学习(RL)思路设计的,由生成网络(Generator, G)和判别网络(Discriminator, D)两部分组成:
- 生成网络构成一个映射函数 G: Z→X(输入噪声 z, 输出生成的伪造数据 x)
- 判别网络判别输入是来自真实数据还是生成网络生成的数据
在这样训练的博弈过程中,提高两个模型的生成能力和判别能力。
生成对抗网络:是一种深度学习模型,它由生成器和判别器两个网络组成。生成器负责生成逼真的数据样本,而判别器则负责区分真实数据和生成数据。GAN在图像生成、视频合成等领域有广泛的应用。
2015 年:深度学习的联合综述《Deep learning》
为纪念人工智能概念提出 60 周年,深度学习三巨头 LeCun、Bengio 和 Hinton(他们于 2018 年共同获得了图灵奖)推出了深度学习的联合综述《Deep learning》。
文中指出深度学习就是一种特征学习方法,把原始数据通过一些简单的但是非线性的模型转变成为更高层次及抽象的表达,能够强化输入数据的区分能力。通过足够多的转换的组合,非常复杂的函数也可以被学习。
2015 年:ResNet 残差网络
Microsoft Research 的 Kaiming He 等人提出的残差网络(ResNet)在 ImageNet 大规模视觉识别竞赛中获得了图像分类和物体识别的优胜。残差网络的主要贡献是发现了网络不恒等变换导致的 “退化现象(Degradation)”,并针对退化现象引入了 “快捷连接(Shortcut connection)”,缓解了在深度神经网络中增加深度带来的梯度消失问题。支持多达千层的深度网络训练。
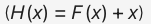
残差网络(ResNet):是一种深度卷积神经网络模型,它通过引入残差连接来解决深层神经网络中的梯度消失和梯度爆炸问题。ResNet在图像分类、目标检测等任务中取得了优异的性能。
同年,谷歌开源 TensorFlow 框架。它是一个基于数据流编程(dataflow programming)的符号数学系统,通过数据流图与自动微分来降低了深度学习工程门槛。被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库 DistBelief。
同年,马斯克等人共同创建 OpenAI。它是一个非营利的研究组织,使命是确保通用人工智能 (AGI,即一种高度自主且在大多数具有经济价值的工作上超越人类的系统)将为全人类带来福祉。孕育了 GPT 系列大模型。
2016 年:联邦学习
Google 发明了联邦学习,通过差分隐私 + 同态加密,实现分布式数据训练。
谷歌提出联邦学习方法,它在多个持有本地数据样本的分散式边缘设备或服务器上训练算法,而不交换其数据样本。联邦学习保护隐私方面最重要的三大技术分别是:
- 差分隐私 ( Differential Privacy)
- 同态加密 ( Homomorphic Encryption )
- 隐私保护集合交集 ( Private Set Intersection )
能够使多个参与者在不共享数据的情况下建立一个共同的、强大的机器学习模型,从而解决数据隐私、数据安全、数据访问权限和异构数据的访问等关键问题。
联邦学习:是一种分布式机器学习框架,它允许多个客户端在保护各自数据隐私的前提下共同训练一个全局模型。联邦学习通过聚合来自不同客户端的模型更新来更新全局模型,从而实现了数据隐私保护和模型性能提升的双重目标。
同年,Google 发布了 AlphaGo(DeepMind),与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以 4 比 1 的总比分获胜。AlphaGo 是一款围棋人工智能程序,其主要工作原理是“深度学习”,由以下四个主要部分组成:
a. 策略网络(Policy Network),预测走法,给定当前局面,预测并采样下一步的走棋;
b. 快速走子(Fast rollout)目标和策略网络一样,但在适当牺牲走棋质量的条件下,速度要比策略网络快1000倍;
c. 价值网络(Value Network),评估胜率,估算当前局面的胜率;
d. 蒙特卡洛树搜索(Monte Carlo Tree Search)树搜索估算每一种走法的胜率。
2017 年:Transformer 架构
Google 的 Vaswani 等人发明了 Transformer 架构。
Transformer 架构基于自注意力机制(Self-Attention),计算输入序列中每个位置的关系权重如下,并行化处理序列数据,取代 RNN 的时序依赖,成为 GPT 和 BERT 等 AI 模型的核心。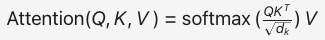
2022 年:ChatGPT 与生成式 AI
OpenAI 团队,基于 Transformer 的生成式预训练(GPT-3.5 架构),使用人类反馈强化学习(RLHF)对齐模型输出与人类价值观,参数量达 1750 亿,支持多轮对话和复杂任务推理。被称为大模型。
五、当前前沿方向(2020s)
2020年:CLIP模型(OpenAI)
- 多模态融合:对比学习对齐文本-图像嵌入空间,支持零样本分类。
- 技术原理:通过跨模态注意力机制对齐文本、图像、音频的嵌入空间,例如CLIP模型将图像和文本映射到同一向量空间实现零样本分类。
2022年:波士顿动力Atlas
- 具身智能(Embodied AI)
- 研究方向:物理世界交互
- 突破:模型预测控制(MPC)+ 强化学习,实现动态环境下的平衡与运动。
- 技术原理:结合强化学习和三维环境模拟(如MuJoCo),训练机器人通过试错学习抓取、导航等技能,例如波士顿动力Atlas的动态平衡控制。
AI 伦理与可解释性:
- 技术原理:采用SHAP(Shapley Additive Explanations)值量化特征贡献,或通过LIME(Local Interpretable Model-agnostic Explanations)生成局部可解释模型,提升黑箱模型的透明度。
总结与引用
人工智能发展历经符号主义、连接主义到深度学习的范式转变,关键技术节点包括:
理论奠基:图灵测试(1950)、达特茅斯会议(1956) ;
技术突破:反向传播(1986) 、AlexNet(2012) 、Transformer(2017) 。
应用扩展:AlphaGo(2016) 、ChatGPT(2022)
人工智能的发展呈现螺旋上升特征:
- 理论-工程循环:符号主义(规则推理)→ 连接主义(数据驱动)→ 多模态融合(知识+感知)。
- 核心驱动力:算力提升(CPU→GPU→TPU)、数据爆发(互联网→物联网)、算法创新(BP→Transformer)。
- 未来挑战:
- 技术层面:小样本学习、因果推理、具身智能。
- 社会层面:伦理对齐、就业冲击、超级智能风险。
未来趋势聚焦多模态、具身智能与伦理治理,技术原理的深化与工程化落地将推动AI向通用人工智能(AGI)迈进。

一站式 AI 云服务平台
更多推荐



 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)