
大语言模型LLM关键技术以及微调、推理和部署代码
大语言模型(LLM)技术综述:从基础架构到部署应用 本文系统介绍了大语言模型(LLM)的核心技术及其应用流程。首先剖析了Transformer模型的基础架构,包括自注意力机制、归一化方法(LayerNorm/RMSNorm)、位置编码(RoPE)、多头注意力变体(MHA/MQA/GQA)以及优化技术如FlashAttention和KVCache机制。在模型开发环节,详细讲解了HuggingFace
目录
大语言模型(LLM)是近年来人工智能领域的核心突破,其关键技术涵盖模型结构设计、高效训练、推理部署、对齐优化、多模态融合等多个层面。在结构上,LLM以Transformer为基础,主流采用Decoder-only架构,结合多头自注意力机制、RoPE位置编码和残差连接,能够高效建模长距离依赖。随着需求增长,支持128K甚至百万级上下文长度的长上下文建模技术(如FlashAttention、ALiBi、Dynamic RoPE)成为主流。
训练方面,LLM依赖大规模高质量语料(10~20T tokens)进行自回归预训练,辅以FSDP、ZeRO等并行策略实现数百亿参数的训练。混合精度(BF16/FP16)进一步提升训练效率。在参数高效微调方面,LoRA、QLoRA、Adapter等方法允许低成本定制模型。对齐技术则采用“预训练→SFT→RLHF/DPO”三阶段流程,通过人类反馈或偏好学习提升模型安全性、遵循性与实用性。
部署优化方面,FlashAttention-3与PagedAttention通过重构KV缓存与内存调度,大幅降低显存与延迟。vLLM等推理框架提升了多并发与吞吐性能,TensorRT-LLM、FasterTransformer等工具则支持INT4/FP8等低比特部署。在多模态方向,Q-Former与视觉编码器桥接语言与图像,推动视觉语言模型发展。未来LLM将继续向长上下文、多专家模型(MoE)、跨模态融合和高效能部署方向演进。
1. transformer基础知识
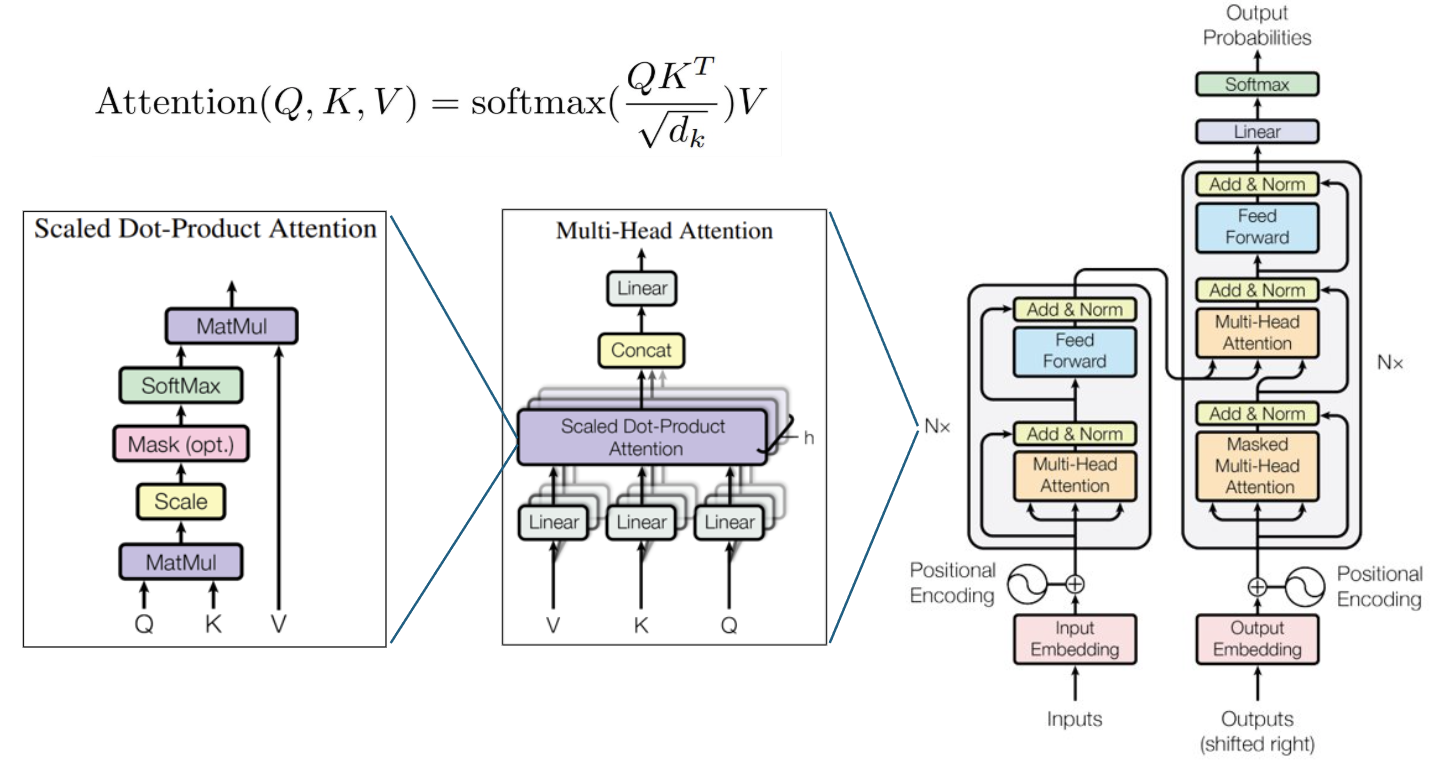
LLM算法的核心是transformer模型,典型的transformer结构如下图所示,模型主要由编码器(Encoder)和解码器(Decoder)组成,两者通过自注意力机制和前馈神经网络交替堆叠。
编码器输入的序列首先通过词嵌入(Embedding)转化为向量表示,再加入位置编码(Positional Encoding),位置编码用于传递单词在序列中的位置信息。然后将输入向量经过LayerNorm进行归一化,通过MLP将输入向量映射为Query、Key和Value。之后将QKV分为多头进行自注意力计算,输出经过线性变换后通过残差与输入向量连接,最后Multi-Head Attention模块的输出经过FFN模块输入给下一层。FFN包括两层MLP将特征先升维,升维维度一般是4*d,然后再降维,经过LayerNorm后与MHA的输出残差连接后输出。
解码器结构与编码器结构非常类似,不同的地方在于解码器的输入向量先经过Masked Multi-Head Attention模块进行自注意力的计算,其中masked含义是确保每个 token 只能看到自己及之前的 token,后面的token无法看到,然后再与解码器的输出进行交叉注意力,之后再输入给FFN模块,最终经过多层计算后由输出头解码出预测。
1.1 归一化(LayerNorm & RMSNorm)
LayerNorm算法:
假设输入某个 token 的 embedding 向量:
γ 和 β 是可学习参数(scale 和 bias),与维度 d 相同,ε 是防止除以 0 的小常数(如 1e-5),其中
所有batch的token共享γ 和 β参数。
RMSNorm算法:
RMSNorm只做 L2 归一化,不减均值,实测表明在有残差的情况下 RMS 足以稳定梯度,可以提高计算效率,所以近年大语言模型常采用RMSNorm归一化方案。
1.2 位置编码(position embedding)
Transformer的自注意力机制本身是无序列感知,正弦位置编码为输入的序列中的每个位置添加位置信息,通过正弦和余弦函数生成一组固定的编码,用于表示不同位置的唯一性,相当于每个token的每一个特征都有一个位置编码,它是绝对位置编码,不需要训练,位置编码只在编解码器第一层时加入。
- pos 表示位置(序列中的位置)。
- i 表示维度索引,i 是偶数时表示使用正弦函数,奇数时使用余弦函数。
- d 是位置编码的维度(通常是模型的隐藏层维度)。
- 这里的 10000 是一个超参数,用于缩放位置差异的影响,使得位置编码适用于较长的序列。
1.3 多头注意力
多头注意力通过多个注意力头并行计算,每个头在不同的子空间中独立地关注输入的不同部分,最终,将所有注意力头的输出拼接起来,并通过一个线性层进行映射。假设Q,K,V的维度为(N,d),其中N是序列长度,d是特征维度。设定头的数量为h,每个头的维度为,使用不同的线性变换矩阵,将查询、键、值映射到多个子空间:
对于每个头进行注意力计算,然后将每个头的输出拼接在一起。
MHA&MQA&GQA
多查询注意力(MQA)、分组查询注意力(GQA)是Transformer中多头注意力(MHA)的变种,它们提高了解码器的推理效率,降低了模型的显存开销,目前在大模型中广泛应用。MQA的原理很简单,它将原生Transformer每一层多头注意力的Key线性映射矩阵、Value线性映射矩阵改为该层下所有头共享,也就是说K、V矩阵每层只有一个,这种方式大幅减小了参数数量,带来推理加速的同时会造成模型性能损失,且在训练过程使得模型变得不稳定,因此在此基础上提出了GQA,它将Query进行分组,每个组内共享一组Key、Value,令组的数量为N,若N等于1此时等效于MQA,若N等于Query头的数量,此时退化为MHA。GQA是推理效率和模型性能的trade-off。
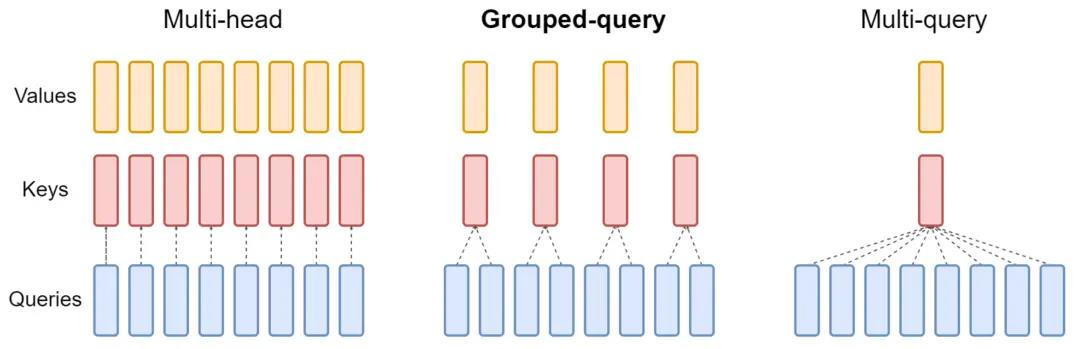
MQA能够加速Transformer的推理,但是会有一定的性能损失,而GQA通过设置合适的分组大小,可以和MQA的推理性能几乎相等,同时逼近MHA的模型性能。MQA和GQA并没有降低Attention的计算量(FLOPs),因为Key、Value映射矩阵会以广播变量的形式拓展到和MHA和一样,因此计算量不变,只是Key、Value参数共享,共享降低了KV矩阵的读写时间,更大的优势是降低了GPU存储的使用量。
1.4 掩码(Masking)
在Transformer模型中,掩码是一个关键机制,在处理序列数据时可以限制信息的传递,尤其是在序列生成任务中,通常在两个主要场景中使用:
自注意力掩码(Self-Attention Masking):用于限制模型在计算当前词的表示时只能访问当前词及其之前的词,而不能访问未来的词。掩码矩阵𝑀通常是一个上三角矩阵,它的作用是屏蔽未来的词。在计算注意力时,掩码矩阵中的大于当前时间步的元素会被置为负无穷大(或比较大的负值),确保它们在 softmax 计算时得到 0 的权重,从而不影响当前时间步的注意力。
序列对齐掩码(Padding Masking):用于处理不同长度的输入序列,确保模型不会被填充的部分干扰。对于输入序列中的填充部分,通常使用一个专门的标记( 0 或一个特殊的填充符),在计算注意力时,我们通过填充掩码来确保这些填充位置不会参与到注意力的计算中。如对于一个序列[1,2,3,0,0],如果其最后两个token是padding的话,则生成其掩码矩阵P如下。
1.5 FlashAttention机制
FlashAttention 是一种针对自注意力计算的高效优化方法,旨在解决传统自注意力计算中内存占用过高和计算效率较低的问题,尤其在处理大规模 Transformer 模型时。它通过优化内存访问模式、利用并行计算、以及分块处理机制,显著提高了推理效率并减少了内存需求。传统计算注意力的方法如果输入序列非常长,计算会需要大量的内存来存储中间结果(尤其是当序列长度N很大时),这会导致显著的内存消耗和计算瓶颈。FlashAttention 通过将Query (Q)分块处理,每次只计算一部分 Query 的点积,而不是计算整个矩阵。这样可以避免在内存中存储整个矩阵。
1.6 KV Cache机制
在 Transformer 中,自注意力(Self-Attention)机制的关键操作是通过输入序列中的每个词(token)生成 Query(Q)、Key(K)、和 Value(V) 向量。然后,基于这些向量进行相似度计算,以得到注意力权重并生成新的词表示。在推理过程中,随着每次生成新的 token,模型需要重新计算所有之前生成的 token 的 Key 和 Value 向量。这是一个非常计算密集的过程,尤其在处理长序列时,计算复杂度会迅速增加。为了提高推理效率,尤其是在 自回归生成任务(如文本生成)中,KV Cache 会缓存之前计算的 Key 和 Value 向量,从而避免在每次推理时重新计算所有的注意力信息。
2. 模型选择和微调
从零开始训练一个LLM模型通常需要极大的计算资源(例如数百个GPU或TPU、数周甚至数月的训练时间)和海量的标注数据,大多数情况下不会直接训练基础模型,而是对开源基础模型进行微调。Hugging Face是目前最流行的深度学习模型库之一,提供了大量的开源预训练模型,支持多种任务开发,而且还有非常方便的训练和部署接口。
2.1 Hugging Face模型后缀含义
Hugging Face上有非常丰富的模型,第一次接触可能会比较疑惑,这里介绍一些典型后缀的含义。
| 后缀 | 含义 | 内容 | 示例 |
| hf | Hugging Face | 标准 PyTorch 或 Safetensors 模型 | llama3-8b-hf |
| GGUF | GGUF format | 量化模型,适用于 llama.cpp / Ollama | llama3-8b-q4_K_M.gguf |
| instruct | Instruction-tuned | 聊天/指令跟随微调版 | mistral-7b-instruct |
| chat | 聊天模型 | 专门对话任务调优过的版本 | llama-2-13b-chat |
| base | 预训练基础模型 | 未微调的原始语言模型 | mistral-7b-base |
| dpo | Direct Preference Optimization | 经过偏好优化(RLHF替代) | openhermes-2.5-dpo |
| qlora | QLoRA微调模型 | 支持高效微调(4bit)权重 | llama3-8b-qlora |
| lora | LoRA adapter | 微调 adapter 层(需 merge) | guanaco-lora-7b |
| merged | 合并模型 | base + adapter 已合并 | llama3-openchat-merged |
| int4 / int8 | 量化类型 | 用于轻量部署 / GGUF 之外的 INT 模型 | int4-awq |
| awq | Activation-aware quant | 更智能的量化技术 | baichuan2-awq |
| q4_K_M / q5_1 / q8_0 | GGUF 量化等级 | q4_K_M 较推荐,q8_0 精度高但模型大 | llama3-q4_K_M.gguf |
| moe | Mixture of Experts | 多专家模型 | mixtral-8x7b |
| slim / tiny / mini | 精简模型 | 更小模型(3B、1B以下) | phi-2、tinystories |
| code | 编码任务优化 | 用于代码生成 | codellama-13b-instruct |
| vllm | 适配 vLLM 推理库 | 支持 tensor parallel / KV缓存优化 | llama3-vllm |
safetensors:使用了格式验证和元数据检查机制,避免了在载入模型时加载潜在的恶意代码,相比pth更安全;
instruct:单轮指令完成,无上下文记忆,主要用于完成特定任务;
chat:多轮对话,上下文感知,主要用于聊天机器人;
MoE(Mixture of Experts): 混合专家架构,通过选择性激活模型的部分专家网络来提高计算效率和降低资源消耗。门控网络是MoE架构中的一个重要组件,根据输入生成一个概率分布,然后选择 概率较大的部分专家网络来进行计算。
2.2 模型推理
Hugging Face有丰富的LLM模型,以meta-llama/Llama-3.2-1B-Instruct为例,典型的文件如下:
| 名称 | 含义 |
| model.safetensors | 模型的权重文件 |
|
config.json |
模型结构文件 |
| generation_config.json | 定义推理时的默认生成参数 |
| tokenizer.json | 主 tokenizer 文件,包含词表(vocab)、merges、编码规则 |
| tokenizer_config.json | 辅助 tokenizer 配置,定义特殊 token、bos/eos ID、pretokenizer、normalizer 设置 |
| special_tokens_map.json | 明确标记哪些 token 是 <pad>、<eos>、<bos>、<unk> 等,供 HuggingFace 自动识别 |
可以将模型下载到本地,或者直接指定hugging face同名的文件夹进行自动下载,推理时可以分别加载model和tokenzier,也可以直接使用pipline,注意因为是instruct版本,输入需要和微调输入格式匹配,采用{"role": "user", "content": "Who are you?"}进行提问。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = "./llm/Llama-3.2-1B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
device_map="auto"
)
messages = [
{"role": "user", "content": "Who are you?"}
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True # 会在结尾加 <assistant> token
)
input_ids = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
output_ids = model.generate(
**input_ids,
max_new_tokens=128,
temperature=0.7,
top_p=0.9
)
response = tokenizer.decode(output_ids[0][input_ids["input_ids"].shape[-1]:],
skip_special_tokens=True)
print("Assistant:", response.strip())
import torch
from transformers import pipeline
model_id = "/home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct/"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages=[
{
"role": "user",
"content": "who are you?"
}
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"])输出结果都为:
Assistant: I'm an artificial intelligence model known as Llama. Llama stands for "Large Language Model Meta AI.”2.3 模型微调
预训练的大模型具有很强的语言生成能力,但在处理某些专业任务时可能并不完美,这就需要收集专业领域的小样本数据集,对基础模型进行微调,提高模型在特定任务上的表现,但同时需要避免通用模型能力的降低,这个过程一般称作SFT(Supervised Fine-Tuning,有监督微调)。
准备数据:需要准备用于微调的数据集,并确保它符合模型的输入格式。meta-llama/Llama-3.2-1B-Instruct已经在一定的数据格式下进行了微调,如何仍然需要微调,需要保持数据格式一致,例如我们生成了1000条地理知识的问答进行微调,格式如下。
[
{
"messages": [
{
"role": "user",
"content": "Which country is the largest in Africa by area?"
},
{
"role": "assistant",
"content": "The largest country in Africa by area is Algeria."
}
]
},
{
"messages": [
{
"role": "user",
"content": "What is the largest ocean in the world?"
},
{
"role": "assistant",
"content": "The largest ocean in the world is the Pacific Ocean."
}
]
}
]
模型训练:大模型微调如果对所有参数进行微调训练,不但训练时间长,而且容易过拟合到新的数据,造成模型能力下降,因此一般采用LoRA(Low-Rank Adaptation)大模型微调方法。LoRA 方法在原始模型中插入了一些低秩矩阵,这些矩阵的维度远小于原始参数矩阵,同时冻结原有模型的大部分参数,只训练这部分低秩矩阵,LoRA 就能够在不修改原模型权重的情况下,增加模型的表达能力,适应特定的下游任务,其原理如下:
用两个小矩阵(LoRA adapter)来模拟对原始参数的微调,几乎没有精度损失(<0.5%),训练参数只有原来的0.1%,可以使用几千条甚至几百条数据进行微调就可以达到不错的效果。还有一种方式是QLoRA,先将原模型量化为 4-bit,再基于 LoRA 做微调,更省显存,适合更低成本训练。下面是使用LoRA进行训练的代码示例:
# example for llama lora finetune
from datasets import Dataset
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model, TaskType
from torch.nn.utils.rnn import pad_sequence
import torch
import json
MODEL_DIR = "./Llama-3.2-1B-Instruct"
DATA_PATH = "./datasets/geography_qa_data.json"
OUTPUT_DIR = "./result/llama3-geo-lora"
MAX_LEN = 1024
# load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR, trust_remote_code=True, use_fast=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
MODEL_DIR,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
# load data
with open(DATA_PATH, "r", encoding="utf-8") as f:
raw_data = json.load(f)
def tokenize_and_label(batch):
input_ids_list, labels_list = [], []
SID = tokenizer.convert_tokens_to_ids("<|start_header_id|>")
EID = tokenizer.convert_tokens_to_ids("<|end_header_id|>")
EOT = tokenizer.convert_tokens_to_ids("<|eot_id|>")
for messages in batch["messages"]:
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)
enc = tokenizer(text, add_special_tokens=False)
ids = enc["input_ids"]
labels = [-100] * len(ids)
# 在 token 序列中扫描:仅标注 assistant 正文
i = 0
while i < len(ids):
if ids[i] == SID:
# 找到 <|start_header_id|> ... <|end_header_id|> 之间的角色字符串
j = i + 1
while j < len(ids) and ids[j] != EID:
j += 1
role_text = tokenizer.decode(ids[i+1:j]).strip().lower()
k = j + 1 # header 结束后正文起点(一般后面会有一个换行)
# 向后寻找到本条消息的 EOT
t = k
while t < len(ids) and ids[t] != EOT:
t += 1
if "assistant" in role_text:
# 只监督 assistant 正文(不包含 header 和 EOT)
for p in range(k, t):
labels[p] = ids[p]
# 跳过到 EOT 后的下一个 token
i = t + 1
else:
i += 1
# 4) 统一右截断
if len(ids) > MAX_LEN:
ids = ids[:MAX_LEN]
labels = labels[:MAX_LEN]
input_ids_list.append(ids)
labels_list.append(labels)
return {"input_ids": input_ids_list, "labels": labels_list}
dataset = Dataset.from_list(raw_data).map(
tokenize_and_label,
batched=True,
remove_columns=["messages"]
)
# paddig mask
def data_collator(features):
pad_id = tokenizer.pad_token_id or tokenizer.eos_token_id
input_ids = [torch.tensor(f["input_ids"], dtype=torch.long) for f in features]
labels = [torch.tensor(f["labels"], dtype=torch.long) for f in features]
input_ids = pad_sequence(input_ids, batch_first=True, padding_value=pad_id)
labels = pad_sequence(labels, batch_first=True, padding_value=-100)
attention_mask = (input_ids != pad_id).long()
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels,
}
# inject LoRA
peft_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM,
)
model = get_peft_model(model, peft_config)
# train for finetune
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
save_steps=100,
num_train_epochs=2,
learning_rate=2e-4,
fp16=True,
save_total_limit=2,
report_to="none",
remove_unused_columns=False,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
)
trainer.train()
# save model
model = model.merge_and_unload()
model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
2.4 模型量化和部署
2.4.1 模型量化
完成模型的微调后,需要将模型部署到生产端进行服务。由于LLM模型一般都比较大,在算力限制较大的环境下需要对模型进行量化,量化分为训练后量化和训练阶段量化。训练后量化PTQ(Post-Training Quantization):直接将 FP32 或 FP16 的模型离线量化为 INT8 或 INT4,用于推理,不改动原始模型结构,不需要再次训练,速度快,部署方便,但精度会略有下降。QAT(Quantization-Aware Training):在训练阶段就模拟量化过程,训练完直接是 INT8/INT4 的部署模型。由于训练后量化不需要再次训练,部署方便,同时精度一般下降比较少(<0.5%),所以在实际开发中一般采用训练后量化。其中在hugging face上常见的一种量化模型格式是GGUF ( Grokking GGML Unified Format),它是LLM模型量化后的通用存储格式,由llama.cpp项目主导,旨在替代早期的.bin、.ggml格式,支持更多功能、更好的兼容性。仍然以meta-llama/Llama-3.2-1B-Instruct为例,展示量化过程,首先下载llama.cpp工程,并编译可执行文件。
git clone https://github.com/ggml-org/llama.cpp.git
https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
cmake .. -DGGML_CUDA=ON
cmake --build . --config Releasellama.cpp支持从.pth或者.bin文件转为GGUF文件,不支持从safetensors直接转换,当前下载的文件可以导入到pytorch进行导出或者直接使用llama.cpp下的convert_hf_to_gguf.py将模型文件转化为float16的文件,然后在进行量化转换。
python3 convert_hf_to_gguf.py .llm/Llama-3.2-1B-Instruct --outfile ./llm/Llama-3.2-1B-Instruct/gguf_output/llama3-1b-f16.gguf --outtype f16
./llama-quantize /home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct/gguf_output/llama3-1b-f16.gguf /home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct/gguf_output/llama3-1b-Q4_K_M.gguf Q4_K_M
llama.cpp支持的量化类型如下:
Allowed quantization types:
2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B
3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B
8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B
9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
31 or IQ1_M : 1.75 bpw quantization
36 or TQ1_0 : 1.69 bpw ternarization
37 or TQ2_0 : 2.06 bpw ternarization
10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B
21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B
12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B
13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B
15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B
17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B
18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B
7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B
1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7B
2.4.2 模型部署
其实前面章节已经展示了LLM模型如何在pytorch中进行推理和部署,但由于pytorch是通用的推理框架,很多结构不会进行深度优化,推理速度会比较慢,因此有专门的推理框架进行模型的部署。根据不同的用途,模型部署有不同的框架,例如基于ollama部署、llama.cpp部署、tensorRT-LLM部署、vLLM部署,这里对其中几种方式进行简单介绍。
2.4.2.1 ollama部署
Ollama 主要提供一个高效的框架,用于将多个预训练的大型语言模型提供为 API 服务,它的功能与docker非常类似,只是管理的对象是推理模型,ollama底层使用的llama.cpp。它允许开发者轻松集成、部署以及使用各种 LLM,包括用于问答、文本生成、情感分析等各种自然语言处理任务。Ollama为多个大型语言模型提供优化的推理引擎,支持多个操作系统,提供了简单易用的Python和CLI接口,支持量化模型推理,提供了便捷的部署工具,使得开发者可以将 LLM 模型快速部署到不同的环境中(本地服务器、云端等),这里主要介绍下本地服务器端如何部署,首先是安装ollama以及python接口:
curl -fsSL https://ollama.com/install.sh | sh
pip install ollamaollama不能直接运行safesensors或者GGUF格式的模型,需要通过构型导入构建的方式进行模型推理。首先建立一个配置文件Modelfile,格式如下:FROM是LLM文件所在的目录,PARAMETER是创建推理模型时的输入参数,通过ollama命令即可创建模型实例,ollama list和ollama rm可以查看或者删除模型,ollama run可以直接进行推理。
FROM ./Llama-3.2-1B-Instruct
PARAMETER temperature 0.7
PARAMETER top_p 0.9 ollama create new_llama_infer -f Modelfile
或
ollama create new_llama_infer #Modelfile是默认名称NAME ID SIZE MODIFIED
new_llama_infer:latest cdef256b374a 2.5 GB 10 seconds ago
llama3.2-1b-instruct-trans:latest cc9f281b8335 2.5 GB 30 hours ago ollama run llama3.2-1b-instruct-trans
>>> '<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 04 Aug 2025\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWho are you?<|e
... ot_id|><|start_header_id|>assistant<|end_header_id|>\n\n'
Hello, I'm an artificial intelligence model known as Llama. Llama stands for 'Large Language Model Meta AI.'
通过python接口进行推理代码如下:
import ollama
from transformers import AutoTokenizer
model_dir = "/home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
messages = [ {"role": "user", "content": "Who are you?"}]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True # 会在结尾加 <assistant> token
)
# response = ollama.chat("llama3.2-1b-instruct-trans", messages=messages)
response = ollama.generate("llama3.2-1b-instruct-trans", prompt)
print(response['response'])输出结果与之前的结果一致:
I'm an artificial intelligence model known as Llama. Llama stands for "Large Language Model Meta AI."2.4.2.2 TensorRT-LLM
TensorRT-LLM是NVIDIA为大语言模型(LLM)推理而设计的高性能推理框架,支持 LLaMA、OPT、GPT-NeoX、GPT-J、BLOOM、ChatGLM 等众多模型,结合 TensorRT 实现极致的 GPU 推理性能。它支持FP32、FP16以及INT8(需校准),但不支持GGUF等等低比特自定义量化格式。
首先我们下载TensorRT-LLM的源码并安装python库,然后进入更新子模块,下载大文件,然后通过convert_checkpoint.py将模型转换为TensorRT可以识别的权重文件,然后通过trtllm-build将权重文件转换为引擎文件,可以通过指令直接运行引擎文件,输出结果与之前相同。
git clone https://github.com/NVIDIA/TensorRT-LLM.git
git submodule update --init --recursive
git lfs pull
pip3 install --upgrade pip setuptools && pip3 install tensorrt_llm
python3 ./examples/models/core/llama/convert_checkpoint.py \
--model_dir /home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct \
--output_dir ./llama_trt_weights \
--dtype float16
trtllm-build --checkpoint_dir ./llama_trt_weights \
--output_dir ./llama_trt_weights/trt_engines/ \
--gemm_plugin auto
python examples/run.py \
--engine_dir ./llama_trt_weights/trt_engines/ \
--tokenizer_dir /home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct \
--input_text '<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 04 Aug 2025\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWho are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n' \
--max_output_len 64 输出结果:
Input [Text 0]: "<|begin_of_text|><|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 04 Aug 2025\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWho are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
Output [Text 0 Beam 0]: "I'm an artificial intelligence model known as Llama. Llama stands for "Large Language Model Meta AI.""
python接口代码:
import torch
from transformers import AutoTokenizer
# 运行时选择:优先用 C++ runtime,若不可用再退回 Python runtime
from tensorrt_llm.runtime import PYTHON_BINDINGS, ModelRunner
if PYTHON_BINDINGS:
from tensorrt_llm.runtime import ModelRunnerCpp
def build_runner(engine_dir: str,
max_batch_size: int,
max_input_len: int,
max_output_len: int):
if PYTHON_BINDINGS:
# C++ runtime(更快,显存管理也更省)
runner = ModelRunnerCpp.from_dir(
engine_dir=engine_dir,
max_batch_size=max_batch_size,
max_input_len=max_input_len,
max_output_len=max_output_len,
max_beam_width=1,
kv_cache_free_gpu_memory_fraction=0.85,
max_tokens_in_paged_kv_cache=4096,
enable_chunked_context=True
)
else:
# Python runtime(功能全,但略慢;显存控制项少一些)
runner = ModelRunner.from_dir(
engine_dir=engine_dir,
max_output_len=max_output_len
)
return runner
def main():
engine_dir = "./TensorRT-LLM/llama_trt_weights/trt_engines"
hf_model_dir = "/home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(hf_model_dir, use_fast=True)
messages = [ {"role": "user", "content": "Who are you?"} ]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True, # 自动补 assistant 起始头
)
input_ids = tokenizer(prompt, add_special_tokens=False, return_tensors="pt").input_ids[0].to(torch.int32)
max_batch_size = 1
max_input_len = min(len(input_ids), 2048)
max_output_len = 128
runner = build_runner(engine_dir, max_batch_size, max_input_len, max_output_len)
# 推理
with torch.no_grad():
outputs = runner.generate(
batch_input_ids=[input_ids], # batch of 1
max_new_tokens=64, # 期望生成的 token 数
end_id=tokenizer.eos_token_id, # 结束 token
pad_id=(tokenizer.pad_token_id or 0),
temperature=0.0, # 关闭采样,便于复现
top_p=1.0,
num_beams=1,
return_dict=True,
output_sequence_lengths=True,
)
# -------- 4) 取结果并解码 --------
# outputs["output_ids"] 形状: [batch * num_return_sequences, num_beams, max_seq_len]
out_ids = outputs["output_ids"][0][0] # 第 0 个样本、第 0 个 beam
gen_ids = out_ids[len(input_ids):] # 去掉前缀 prompt 部分
text = tokenizer.decode(gen_ids, skip_special_tokens=True)
print(text)
if __name__ == "__main__":
main()
输出结果以前面结果一致:
I'm an artificial intelligence model known as Llama. Llama stands for "Large Langauge Model Meta AI."C++代码接口:
tensorrt-llm目前更新的比较快,有些接口做的还不是很完善,因此在编译时尽量保证版本匹配,这里tensorrt使用的是10.11.0.33,tensorrt-llm的版本是0.21,cuda版本是12.9,pynvml是12.0.0,cuda-python版本12.9.0,下载的tensorrt-llm代码也是0.21,下载完成后进入到 python ./TensorRT-LLM/scripts/build_wheel.py运行进行tensorrt-llm的c++编译,编译完成后到TensorRT-LLM/examples/cpp/executor编译参考例子,tensorrt-llm没有tokenizer,使用另外一个库tokenziers-cpp,编译后可以直接运行可执行程序,模型路径指向刚刚生成的engine路径。
git clone https://github.com/mlc-ai/tokenizers-cpp.git
./executorExampleBasic /home/wangyl/docker_program/trtllm/TensorRT-LLM/Pretrained_model/llama_trt_engine/
/*
* SPDX-FileCopyrightText: Copyright (c) 2022-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
* SPDX-License-Identifier: Apache-2.0
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include <string>
#include <fstream>
#include <iostream>
#include "tensorrt_llm/common/logger.h"
#include "tensorrt_llm/executor/executor.h"
#include "tensorrt_llm/plugins/api/tllmPlugin.h"
#include "tokenizers_cpp.h"
namespace tlc = tensorrt_llm::common;
namespace tle = tensorrt_llm::executor;
using namespace tokenizers;
static std::string LoadBytesFromFile(const std::string& path) {
std::ifstream ifs(path, std::ios::binary);
if (!ifs) { throw std::runtime_error("open failed: " + path); }
return std::string{std::istreambuf_iterator<char>(ifs), std::istreambuf_iterator<char>()};
}
std::string build_chat_prompt(const std::string& user_message,
const std::string& sys_message =
"You are a helpful assistant.",
const std::string& today = "07 Aug 2025",
const std::string& cutoff = "December 2023")
{
std::string prompt;
prompt += "<|begin_of_text|>";
prompt += "<|start_header_id|>system<|end_header_id|>\n\n";
prompt += "Cutting Knowledge Date: " + cutoff + "\n";
prompt += "Today Date: " + today + "\n\n";
prompt += "<|eot_id|>";
prompt += "<|start_header_id|>user<|end_header_id|>\n\n";
prompt += user_message;
prompt += "<|eot_id|>";
prompt += "<|start_header_id|>assistant<|end_header_id|>\n\n";
return prompt;
}
int main(int argc, char* argv[])
{
// Register the TRT-LLM plugins
initTrtLlmPlugins();
if (argc != 2)
{
TLLM_LOG_ERROR("Usage: %s <dir_with_engine_files>", argv[0]);
return 1;
}
std::string blob = LoadBytesFromFile("/home/wangyl/docker_program/trtllm/TensorRT-LLM/Pretrained_model/origin/tokenizer.json");
auto tok = Tokenizer::FromBlobJSON(blob);
// Create the executor for this engine
tle::SizeType32 beamWidth = 1;
auto executorConfig = tle::ExecutorConfig(beamWidth);
auto trtEnginePath = argv[1];
auto executor = tle::Executor(trtEnginePath, tle::ModelType::kDECODER_ONLY, executorConfig);
// Create the request
std::string prompt = build_chat_prompt("Who are you?");
std::vector<int32_t> ids = tok->Encode(prompt);
tle::VecTokens inputTokens(ids.begin(), ids.end());
tle::SizeType32 maxNewTokens = 100;
auto request = tle::Request(inputTokens, maxNewTokens);
request.setEndId(128009);
request.setStopWords({ {128001}, {128008}});
// Enqueue the request
auto requestId = executor.enqueueRequest(request);
// Wait for the response
auto responses = executor.awaitResponses(requestId);
// Get outputTokens
auto outputTokens = responses.at(0).getResult().outputTokenIds.at(beamWidth - 1);
std::string text = tok->Decode(outputTokens);
std::cout << "decoded: " << text << "\n";
// TLLM_LOG_INFO("Output tokens: %s", tlc::vec2str(outputTokens).c_str());
return 0;
}
2.4.2.3 llama.cpp部署
llama.cpp 是一个高效、轻量级的 C++ 库,用于加载和推理 LLaMA 模型(Meta 的 LLaMA 系列语言模型)。它的目标是通过简化的接口和高效的内存管理,使得 LLaMA 模型能够在不同的硬件平台上(包括 CPU 和 GPU)快速运行,使用之前编译好的执行文件可以直接进行初始模型或者各种量化模型运行。
./llama-cli -m /home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct/gguf_output/llama3-1b-f16.gguf
./llama-cli -m /home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct/gguf_output/llama3-1b-Q4_K_M.ggufpython接口:
from llama_cpp import Llama
from transformers import AutoTokenizer
model_dir = "/home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
# 加载模型
llama = Llama(model_path="/home/wangyl/docker_program/llm/Llama-3.2-1B-Instruct/gguf_output/llama3-1b-Q4_K_M.gguf")
messages = [
{"role": "user", "content": "Who are you?"}
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True # 会在结尾加 <assistant> token
)
n_predict = 1000
# 进行推理
response = llama(prompt, max_tokens=n_predict)
# 输出结果
print(response)c++接口:
#include "llama.h"
#include <cstdio>
#include <cstring>
#include <string>
#include <vector>
static void print_usage(char * prog_name) {
printf("\nUsage: %s -m model.gguf [-n n_predict] [-ngl n_gpu_layers] [prompt]\n", prog_name);
}
std::string build_chat_prompt(const std::string& user_message) {
std::string prompt;
// 添加 <|begin_of_text|> 和 system 信息
prompt += "<|start_header_id|>system<|end_header_id|>\n\n";
prompt += "Cutting Knowledge Date: December 2023\n";
prompt += "Today Date: 04 Aug 2025\n\n";
// 添加 <|eot_id|> 标记后结束 system 部分
prompt += "<|eot_id|>";
// 添加 user 信息
prompt += "<|start_header_id|>user<|end_header_id|>\n\n";
prompt += user_message + "\n"; // 插入用户消息
prompt += "<|eot_id|>";
// 添加 assistant 信息
prompt += "<|start_header_id|>assistant<|end_header_id|>\n\n";
return prompt;
}
int main(int argc, char ** argv) {
std::string model_path, prompt = "Hello my name is";
int ngl = 99, n_predict = 32;
for (int i = 1; i < argc; ++i) {
if (strcmp(argv[i], "-m") == 0 && i + 1 < argc) {
model_path = argv[++i];
} else if (strcmp(argv[i], "-n") == 0 && i + 1 < argc) {
n_predict = std::stoi(argv[++i]);
} else if (strcmp(argv[i], "-ngl") == 0 && i + 1 < argc) {
ngl = std::stoi(argv[++i]);
} else {
prompt = argv[i];
break;
}
}
prompt = build_chat_prompt(prompt);
if (model_path.empty()) {
print_usage(argv[0]);
return 1;
}
// Load dynamic backends
ggml_backend_load_all();
// Initialize the model
llama_model_params model_params = llama_model_default_params();
model_params.n_gpu_layers = ngl;
llama_model * model = llama_model_load_from_file(model_path.c_str(), model_params);
if (!model) {
fprintf(stderr, "Error: unable to load model\n");
return 1;
}
// Tokenize the prompt
const llama_vocab * vocab = llama_model_get_vocab(model);
int n_prompt = -llama_tokenize(vocab, prompt.c_str(), prompt.size(), NULL, 0, true, true);
std::vector<llama_token> prompt_tokens(n_prompt);
llama_tokenize(vocab, prompt.c_str(), prompt.size(), prompt_tokens.data(), n_prompt, true, true);
// Initialize the context
llama_context_params ctx_params = llama_context_default_params();
ctx_params.n_ctx = n_prompt + n_predict - 1;
ctx_params.n_batch = n_prompt;
ctx_params.no_perf = false;
llama_context * ctx = llama_init_from_model(model, ctx_params);
if (!ctx) {
fprintf(stderr, "Error: failed to create the llama_context\n");
return 1;
}
// Initialize the sampler and add the greedy sampler
llama_sampler * smpl = llama_sampler_chain_init(llama_sampler_chain_default_params());
llama_sampler_chain_add(smpl, llama_sampler_init_greedy());
// Print the prompt token-by-token
for (auto id : prompt_tokens) {
char buf[128];
int n = llama_token_to_piece(vocab, id, buf, sizeof(buf), 0, true);
std::string s(buf, n);
printf("%s", s.c_str());
}
// Prepare the first batch
llama_batch batch = llama_batch_get_one(prompt_tokens.data(), prompt_tokens.size());
// Main loop to generate tokens
const auto t_main_start = ggml_time_us();
int n_decode = 0;
llama_token new_token_id;
while (n_decode < n_predict) {
if (llama_decode(ctx, batch)) {
fprintf(stderr, "Error: failed to eval\n");
return 1;
}
// Sample the next token
new_token_id = llama_sampler_sample(smpl, ctx, -1);
if (llama_vocab_is_eog(vocab, new_token_id)) break;
// Print the new token
char buf[128];
int n = llama_token_to_piece(vocab, new_token_id, buf, sizeof(buf), 0, true);
std::string s(buf, n);
printf("%s", s.c_str());
fflush(stdout);
// Prepare the next batch
batch = llama_batch_get_one(&new_token_id, 1);
n_decode++;
}
printf("\n");
// Print performance stats
const auto t_main_end = ggml_time_us();
fprintf(stderr, "Decoded %d tokens in %.2f s, speed: %.2f t/s\n",
n_decode, (t_main_end - t_main_start) / 1000000.0f, n_decode / ((t_main_end - t_main_start) / 1000000.0f));
llama_perf_sampler_print(smpl);
llama_perf_context_print(ctx);
// Clean up
llama_sampler_free(smpl);
llama_free(ctx);
llama_model_free(model);
return 0;
}
输出结果:
> who are you?
I'm an artificial intelligence model known as Llama. Llama stands for "Large Language Model Meta AI."
一站式 AI 云服务平台
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)