
【人工智能项目】使用AutoML进行数据预测实战
【人工智能项目】使用AutoML的EfficientNet实战数据预测实例本次使用AutoML技术进行数据预测的实例,在代码开始之前先来讲述下什么是AotoML。AutoMLH2O是一个开源的、内存、分布式、快速和可扩展的机器学习和预测分析平台,允许诸位在大数据上构建机器学习模型,并在企业环境中轻松实现这些模型的搭建。H2O的核心代码是用Java编写的。在H2O中,使用分布式的Key/Value存
【人工智能项目】使用AutoML的EfficientNet实战数据预测实例

本次使用AutoML技术进行数据预测的实例,在代码开始之前先来讲述下什么是AotoML。
AutoML
H2O是一个开源的、内存、分布式、快速和可扩展的机器学习和预测分析平台,允许诸位在大数据上构建机器学习模型,并在企业环境中轻松实现这些模型的搭建。
H2O的核心代码是用Java编写的。在H2O中,使用分布式的Key/Value存储来访问和引用所有节点和机器上的数据、模型、对象等。这些算法是在H2O的分布式Map / Reduce框架之上实现的,并且利用Java Fork / Join框架来实现多线程。数据是并行读取的,并分布在整个集群中,并以压缩的方式以列状格式存储在内存中。 H2O的数据解析器具有内置的智能功能,可以猜测传入数据集的模式,并支持以多种格式从多个源获取数据。
H2O的REST API允许外部程序或脚本通过HTTP上的JSON访问H2O的所有功能。 Rest API使用H2O的Web界面(Flow UI),R binding(H2O-R)和Python binding(H2O-Python)。
AutoML初始化工作
导包
import h2o
from h2o.automl import H2OAutoML
import pandas as pd
初始化
h2o.init()
Checking whether there is an H2O instance running at http://localhost:54321 … not found.
Attempting to start a local H2O server…
Java Version: openjdk version “11.0.4” 2019-07-16; OpenJDK Runtime Environment (build 11.0.4+11-post-Ubuntu-1ubuntu218.04.3); OpenJDK 64-Bit Server VM (build 11.0.4+11-post-Ubuntu-1ubuntu218.04.3, mixed mode, sharing)
Starting server from /usr/local/lib/python3.6/dist-packages/h2o/backend/bin/h2o.jar
Ice root: /tmp/tmpqlgc73ix
JVM stdout: /tmp/tmpqlgc73ix/h2o_unknownUser_started_from_python.out
JVM stderr: /tmp/tmpqlgc73ix/h2o_unknownUser_started_from_python.err
Server is running at http://127.0.0.1:54321
Connecting to H2O server at http://127.0.0.1:54321 … successful.
H2O cluster uptime: 02 secs
H2O cluster timezone: Etc/UTC
H2O data parsing timezone: UTC
H2O cluster version: 3.26.0.10
H2O cluster version age: 16 days
H2O cluster name: H2O_from_python_unknownUser_liglkn
H2O cluster total nodes: 1
H2O cluster free memory: 3 Gb
H2O cluster total cores: 2
H2O cluster allowed cores: 2
H2O cluster status: accepting new members, healthy
H2O connection url: http://127.0.0.1:54321
H2O connection proxy: {‘http’: None, ‘https’: None}
H2O internal security: False
H2O API Extensions: Amazon S3, XGBoost, Algos, AutoML, Core V3, TargetEncoder, Core V4
Python version: 3.6.8 final
导入带训练和预测的文件
df_train = h2o.import_file("./train.csv")
Parse progress: |█████████████████████████████████████████████████████████| 100%
df_test = h2o.import_file("./2.csv")
Parse progress: |█████████████████████████████████████████████████████████| 100%
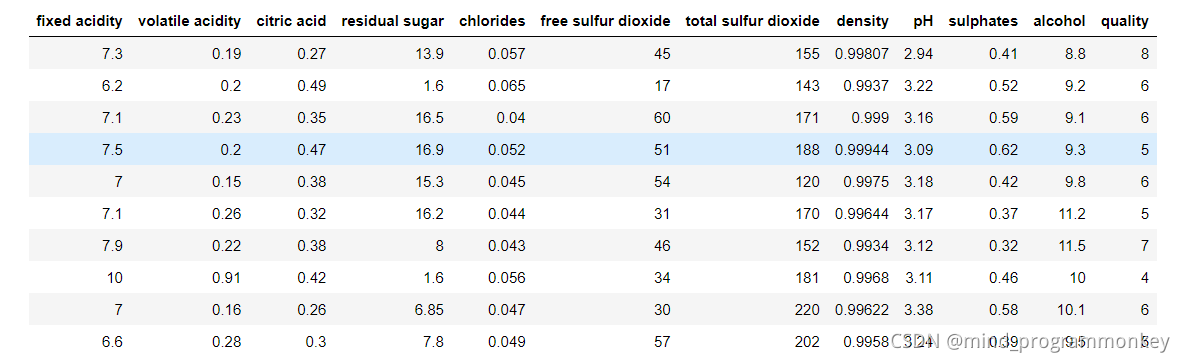
查看导入文件的结构
df_train.head()
定义x和y变量
y = "quality"
x = df_train.columns
x.remove(y)
查看x和y代表的列
x,y
([‘fixed acidity’,
‘volatile acidity’,
‘citric acid’,
‘residual sugar’,
‘chlorides’,
‘free sulfur dioxide’,
‘total sulfur dioxide’,
‘density’,
‘pH’,
‘sulphates’,
‘alcohol’],
‘quality’)
AutoML模型训练
aml = H2OAutoML()
aml.train(x,y,training_frame=df_train)
AutoML progress: |████████████████████████████████████████████████████████| 100%
lb = aml.leaderboard
lb.head(rows=lb.nrows)
预测
predict = aml.predict(df_test)
stackedensemble prediction progress: |████████████████████████████████████| 100%
preds = predict.as_data_frame()
preds = np.array(preds)
preds[:,0].shape
np.round(preds[:,0])
import numpy as np
id = np.arange(1500)+1
df = pd.DataFrame({"id":id,"predict":np.round(preds[:,0])})
df.to_csv("submit10.csv",index=None,header=None)

一站式 AI 云服务平台
更多推荐



 3
3 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)