
Higgs Audio:最佳多扬声器对话式人工智能就在这里
没有付费专区,没有等待名单,没有锁定在 API 后面的半生不熟的预览。您可以下载该模型,检查它,如果您便宜,可以在 Jetson Orin Nano 上运行它,或者如果您想要完整的 4090B 参数版本,则使用完整的 RTX 3。但是尝试生成一个 20 分钟的播客或一个完整的故事,你就会开始听到漂移,声音发生变化,节奏减弱,情绪变得平淡。像是有脉搏的东西 播客、语音代理、音频剧、语言学习工具,也许
哎呀,2025 年将是音频人工智能之年。几乎每周我们都会在音频空间领域获得突破性的模型。而这次我们又有了另一个类似于芝麻CSM 1B的对话式AI模型。那就是希格斯音频。
Higgs Audio V2 则不同。而不是以“下一代人工智能革命”的方式。这是不同的,因为这一次,它感觉就像在说话之前就在听。
这东西有深度。不仅体现在数据上,还体现在它如何传递情感、在对话中做出反应以及进行对话而不听起来像是在等待哔哔声。这就是为什么它很重要。
我关于模型上下文协议的第二本书已经出版
训练了 1000 万小时:
大多数模型都使用抓取的 YouTube 字幕、播客等进行训练。Higgs Audio V2 获得了 1000 万小时的过滤、注释和处理音频。没有被人类贴上标签。他们构建了一个管道,使用内部模型自动标记音调、声音事件(如笑声或音乐)和语义含义。
该管道制作了他们称之为 AudioVerse 的东西,不是一个流行词,只是一堆数据的名称。而且那堆不仅仅是大。它很干净。这比规模更重要。你可以将噪音塞进模型中,它就会学会自信地喊垃圾。
Higgs-Audio 是情感的
无需再次训练。无需插入单独的“情绪模型”。 。
它知道如何说某事,而不仅仅是该说什么。
你问一个问题吗?这听起来很奇怪。
你写了一句悲伤的台词?听起来好像有人刚刚离开了。
你想要旁白吗?5分钟后它不会倒塌。
他们称之为“零样本表达性演讲”。我称之为它首先应该发挥作用。
多发言者对话
这是一个游戏规则的改变者。大多数多扬声器 TTS 听起来像是复制粘贴的声音轮流朗读。他们没有回应对方。Higgs Audio V2 不仅可以切换声音,还可以匹配能量,同步说话者之间的情绪,并在需要时调整句子中间。
是的,它可以进行语音克隆。给它一个剪辑,它就会像那个人一样说话。给它两个剪辑,它会保持完整的对话。不给它任何剪辑,它仍然分配可信的声音。
长格式音频
大多数型号都可以为您提供听起来不错的 10 秒演示。但是尝试生成一个 20 分钟的播客或一个完整的故事,你就会开始听到漂移,声音发生变化,节奏减弱,情绪变得平淡。
您可以使用参考音频(为了一致性)来调节 Higgs-Audio,或者用说明提示它(为了音调)。它记得它是如何开始的。它使声音保持一致。听起来好像在 15 分钟时有人仍然在麦克风前醒着。
24kHz 的高保真声音
早期版本和大多数开放 TTS 型号以 16kHz 运行。它适用于手机或低档扬声器,但对于任何严肃的事情来说却不适用。
Higgs Audio V2 的输出频率为 24kHz,这是您佩戴实际耳机时耳朵想要的。更好的清晰度、更丰富的高音、更少的数字伪影。区别很微妙,但一旦你听到了,你就无法忘记它。
像语言模型一样构建
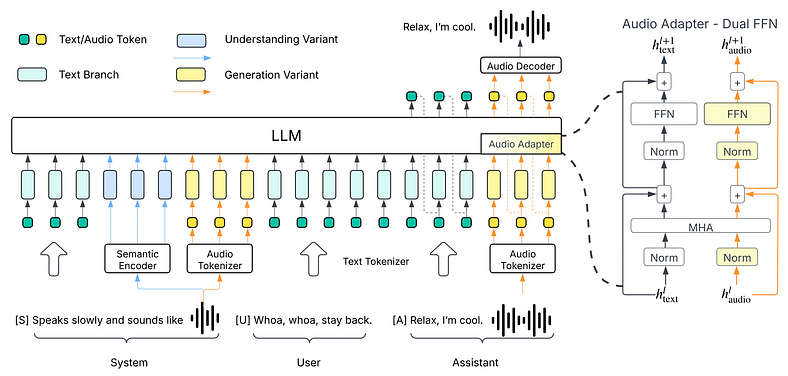
这不仅仅是在句子之上扩展的音频。Higgs Audio V2 的接线方式类似于 LLM,它理解它所说内容的上下文。
核心是一个大型语言模型,与音频分词器配对,它不仅可以切碎单词,还可以处理语义(所说的内容)和声学(听起来如何)。两者使用双 FFN 架构并行处理。这只是意味着它不必在聪明和听起来不错之间做出选择。它可以做到这两点。
基准
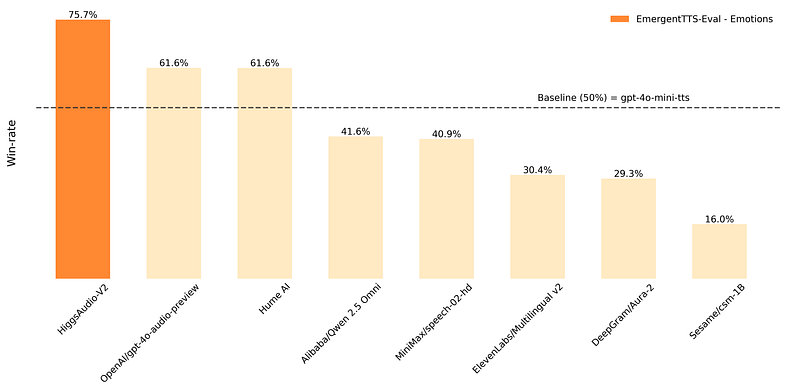
以下是它的叠加方式:
- 情感演讲胜率75.7%超过GPT-4o-mini-tts
- 55.7% 的问题语调胜率
- 在多项测试(Seed-TTS Eval、Emotional Speech Dataset)中优于 ElevenLabs、Deepgram 和 Qwen 2.5
在多说话人对话基准测试中,它比其他任何开源产品都具有更低的单词错误率和更好的语音分离。
它甚至可以唱歌
有一个演示,它用克隆的声音哼唱旋律。不是歌剧级别,但它可以在不说话的情况下保持音调和语气,甚至不说话,这是......以一种好的方式令人不安。
此外:它可以同时生成语音和背景音乐。想想旁白 + 环境配乐。没有缝合。只需一次通过。
它是免费的。
更重要的是:它是开源的。没有付费专区,没有等待名单,没有锁定在 API 后面的半生不熟的预览。您可以下载该模型,检查它,如果您便宜,可以在 Jetson Orin Nano 上运行它,或者如果您想要完整的 4090B 参数版本,则使用完整的 RTX 3。
该模型可以在下面免费测试
要使用的模型权重和代码如下
最后的思考
Higgs Audio V2 是我见过的第一个开源语音模型,它不仅能说得好,而且能说出真正的话。它有音调、时间、语调变化,感觉就像它意识到它所处的时刻。
你想构建一些听起来像是有脉搏的东西 播客、语音代理、音频剧、语言学习工具,也许只是一个人工智能角色,可以开一个玩笑,就像它是认真的一样,这就是要搞砸的那个。

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)