
【人工智能项目】深度学习实现金融用户评论分类
【人工智能项目】深度学习实现金融用户评论分类任务说明本数据集包含金融行业用户评论信息,其中有大量长文本,根据评论识别所属金融业务,具体类别如下:0:消费贷款1:抵押2:信用卡3:债务催收4:信用报告5:学生贷款6:银行账户服务7:短期小额贷款8:汇款9:预付卡10:其他金融服务认识数据import pandas as pdtrain_df = pd.read_csv("train.csv")tes
·
【人工智能项目】深度学习实现金融用户评论分类

任务说明
本数据集包含金融行业用户评论信息,其中有大量长文本,根据评论识别所属金融业务,具体类别如下:
0:消费贷款
1:抵押
2:信用卡
3:债务催收
4:信用报告
5:学生贷款
6:银行账户服务
7:短期小额贷款
8:汇款
9:预付卡
10:其他金融服务
认识数据
import pandas as pd
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")
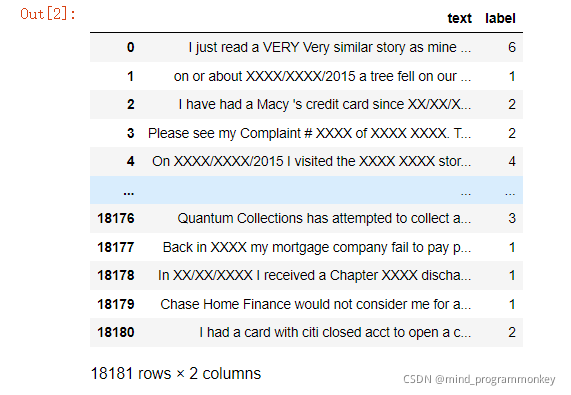
train_df
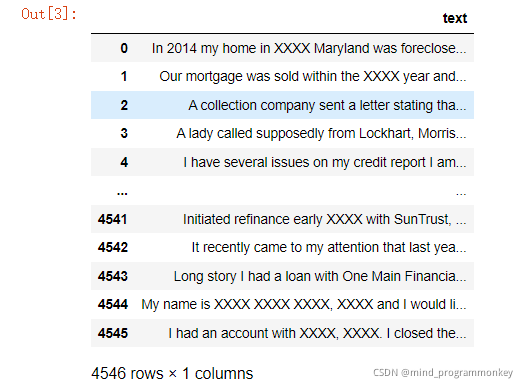
test_df
CatBoost分类
# 裸模86.9556,主要是认识一下俄罗斯很强大的学习模块Catboost
import pandas as pd
from catboost import CatBoostClassifier
import numpy as np
df1=pd.read_csv("./train.csv")
y = df1['label']
X_train = df1['text'].astype('str')
X_train=np.array(X_train)
df2=pd.read_csv("./test.csv")
X_test = df2['text'].astype('str')
X_test=np.array(X_test)
print(X_test.shape)
model = CatBoostClassifier(task_type='GPU')
model.fit(X_train, y,text_features=[0])
label=[]
for i in range(X_test.shape[0]):
label.append(model.predict([X_test[i]])[0])
dataframe = pd.DataFrame({'index':range(X_test.shape[0]),'label':label})
dataframe.to_csv("submisson.csv",index=False,header=False,sep=',')
SimpleTransformer模型训练预测
import warnings
warnings.simplefilter('ignore')
import numpy as np
import pandas as pd
from simpletransformers.classification import ClassificationModel
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
train.columns = ['text', 'labels']
train.head()

train_args={
'sliding_window': True,
'reprocess_input_data': True,
'overwrite_output_dir': True,
'logging_steps': 5,
'stride': 0.6,
'max_seq_length': 256,
"fp16":False,
'num_train_epochs': 5,
"train_batch_size":1,
"gradient_accumulation_steps":32
}
model = ClassificationModel('roberta', 'roberta-base', num_labels=11, args=train_args)
model.train_model(train)
predictions, _ = model.predict([row['text'] for _, row in test.iterrows()])
pd.DataFrame({'ID': test.index, 'labels': predictions}).to_csv('submission_roberta-large.csv', index=False, header=False)
小结
本次用机器学习的方法实现nlp相关的评论分类工作,那下次见!!!

一站式 AI 云服务平台
更多推荐

 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)