
大语言模型生成式AI学习笔记——1. 2.5LLM预训练和缩放法则——领域适配预训练及实例BloombergGPT
到目前为止,我强调了在开发应用程序时,你通常会与现有的大型语言模型(LLM)一起工作。这样可以节省大量时间,并能让你更快地获得一个可用的原型。然而,有一种情况下,你可能会发现有必要从头开始预训练自己的模型。如果你的目标领域使用了在日常语言中不常用的词汇和语言结构,你可能需要执行领域适应以获得良好的模型性能。例如,想象你是一个开发者,正在构建一个帮助律师和法律助理总结法律摘要的应用程序。法律写作使用
Pre-training for domain adaptation(领域适配预训练)
So far, I've emphasized that you'll generally work with an existing LLM as you develop your application. This saves you a lot of time and can get you to a working prototype much faster. However, there's one situation where you may find it necessary to pretrain your own model from scratch. If your target domain uses vocabulary and language structures that are not commonly used in day to day language. You may need to perform domain adaptation to achieve good model performance. For example, imagine you're a developer building an app to help lawyers and paralegals summarize legal briefs. Legal writing makes use of very specific terms like mens rea in the first example and res judicata in the second. These words are rarely used outside of the legal world, which means that they are unlikely to have appeared widely in the training text of existing LLMs. As a result, the models may have difficulty understanding these terms or using them correctly. Another issue is that legal language sometimes uses everyday words in a different context, like consideration in the third example. Which has nothing to do with being nice, but instead refers to the main element of a contract that makes the agreement enforceable.

For similar reasons, you may face challenges if you try to use an existing LLM in a medical application. Medical language contains many uncommon words to describe medical conditions and procedures. And these may not appear frequently in training datasets consisting of web scrapes and book texts. Some domains also use language in a highly idiosyncratic way. This last example of medical language may just look like a string of random characters, but it's actually a shorthand used by doctors to write prescriptions. This text has a very clear meaning to a pharmacist, take one tablet by mouth four times a day, after meals and at bedtime. Because models learn their vocabulary and understanding of language through the original pretraining task. Pretraining your model from scratch will result in better models for highly specialized domains like law, medicine, finance or science.

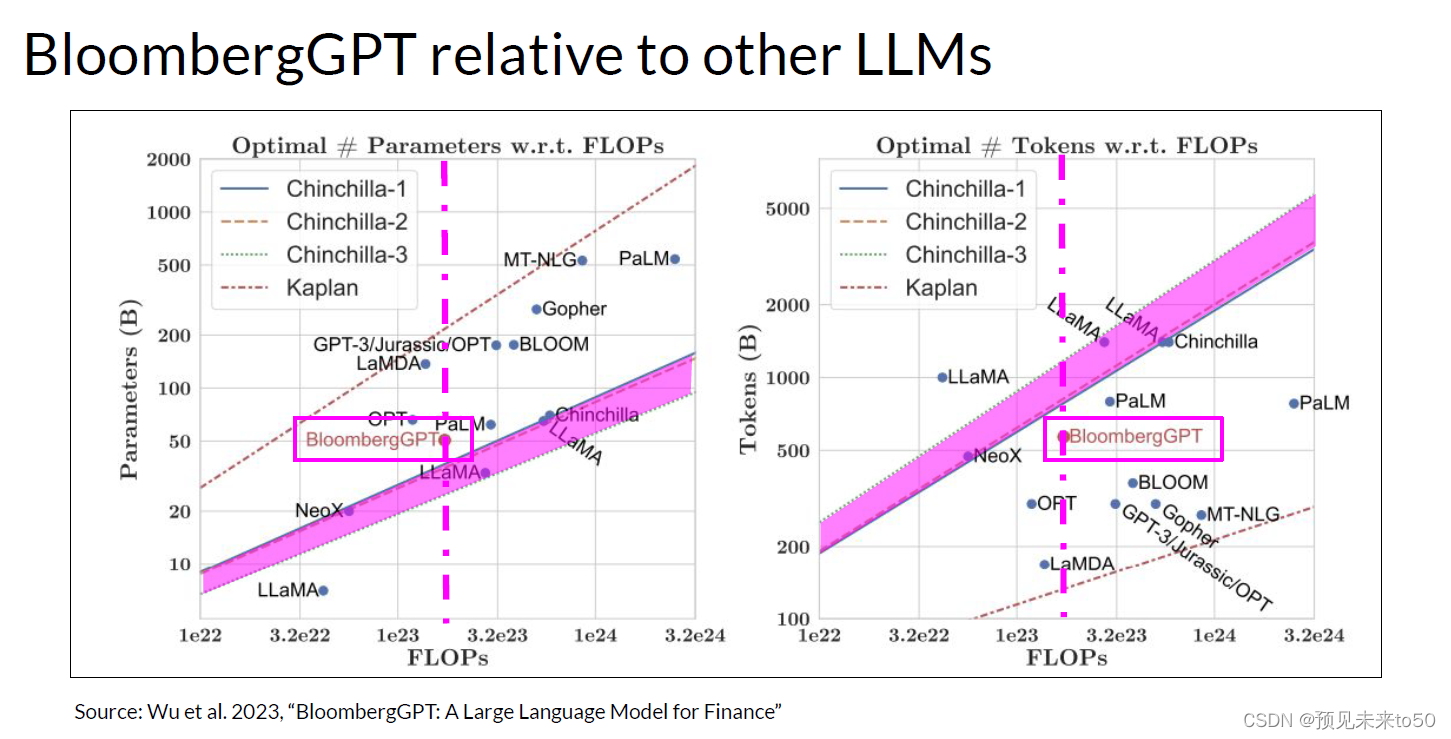
Now let's return to BloombergGPT, first announced in 2023 in a paper by Shijie Wu, Steven Lu, and colleagues at Bloomberg. BloombergGPT is an example of a large language model that has been pretrained for a specific domain, in this case, finance. The Bloomberg researchers chose to combine both finance data and general purpose tax data to pretrain a model that achieves Bestinclass results on financial benchmarks. While also maintaining competitive performance on general purpose LLM benchmarks. As such, the researchers chose data consisting of 51% financial data and 49% public data. In their paper, the Bloomberg researchers describe the model architecture in more detail. They also discuss how they started with a chinchilla scaling laws for guidance and where they had to make tradeoffs. These two graphs compare a number of LLMs, including BloombergGPT, to scaling laws that have been discussed by researchers. On the left, the diagonal lines trace the optimal model size in billions of parameters for a range of compute budgets. On the right, the lines trace the compute optimal training data set size measured in number of tokens. The dashed pink line on each graph indicates the compute budget that the Bloomberg team had available for training their new model. The pink shaded regions correspond to the compute optimal scaling loss determined in the Chinchilla paper. In terms of model size, you can see that BloombergGPT roughly follows the Chinchilla approach for the given compute budget of 1.3 million GPU hours, or roughly 230,000,000 petaflops. The model is only a little bit above the pink shaded region, suggesting the number of parameters is fairly close to optimal. However, the actual number of tokens used to pretrain BloombergGPT 569,000,000,000 is below the recommended Chinchilla value for the available compute budget. The smaller than optimal training data set is due to the limited availability of financial domain data. Showing that real world constraints may force you to make trade offs when pretraining your own models.
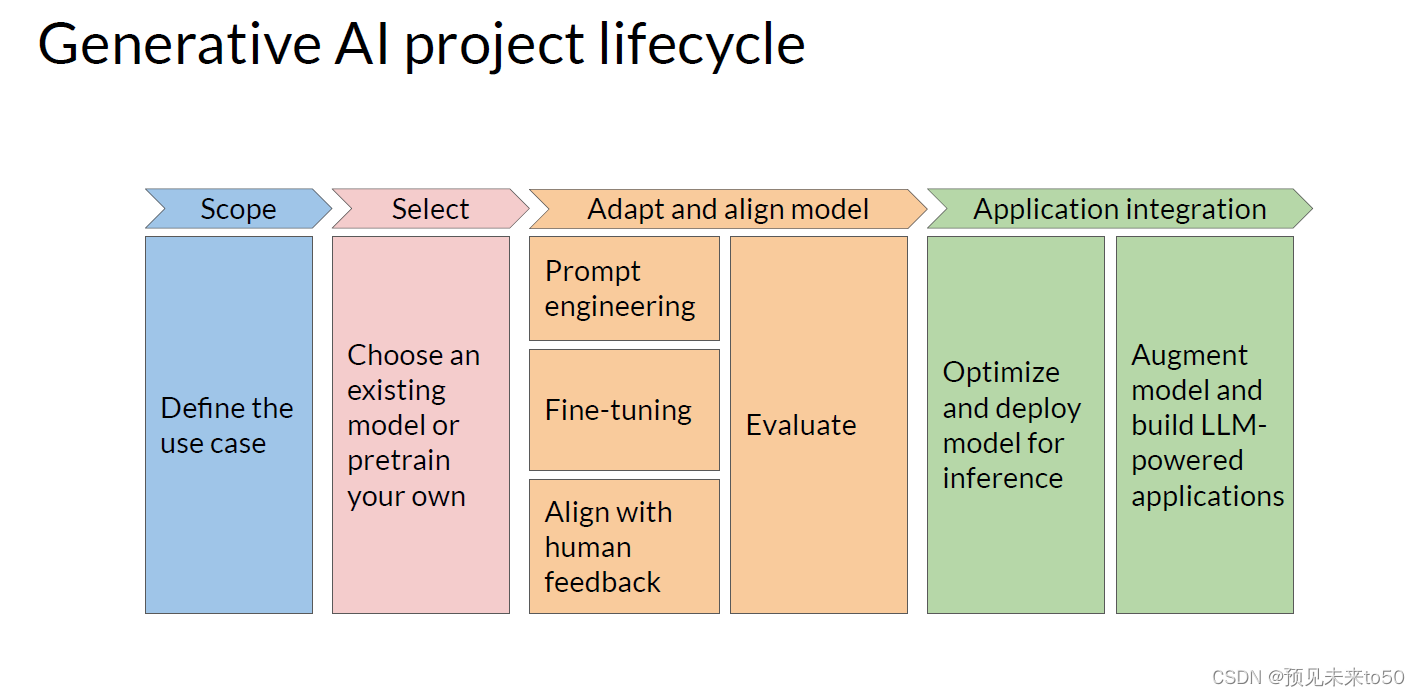
Congratulations on making it to the end of week one, you've covered a lot of ground, so let's take a minute to recap what you've seen. Mike walked you through some of the common use cases for LLMs, such as essay writing, dialogue summarization and translation. He then gave a detailed presentation of the transformer architecture that powers these models. And discussed some of the parameters you can use at inference time to influence the model's output. He wrapped up by introducing you to a generative AI project lifecycle that you can use to plan and guide your application development work. Next, you saw how models are trained on vast amounts of text data during an initial training phase called pretraining. This is where models develop their understanding of language. You explored some of the computational challenges of training these models, which are significant. In practice because of GPU memory limitations, you will almost always use some form of quantization when training your models. You finish the week with a discussion of scaling laws that have been discovered for LLMs and how they can be used to design compute optimal models. If you'd like to read more of the details, be sure to check out this week's reading exercises.
到目前为止,我强调了在开发应用程序时,你通常会与现有的大型语言模型(LLM)一起工作。这样可以节省大量时间,并能让你更快地获得一个可用的原型。然而,有一种情况下,你可能会发现有必要从头开始预训练自己的模型。如果你的目标领域使用了在日常语言中不常用的词汇和语言结构,你可能需要执行领域适应以获得良好的模型性能。例如,想象你是一个开发者,正在构建一个帮助律师和法律助理总结法律摘要的应用程序。法律写作使用非常特定的术语,如第一个示例中的"mens rea"和第二个示例中的"res judicata"。这些词在法律界之外很少使用,这意味着它们不太可能广泛出现在现有LLM的训练文本中。因此,模型可能难以理解这些术语或正确使用它们。另一个问题是,法律语言有时在日常语境中使用不同的上下文,如第三个示例中的"consideration"。这与友好无关,而是指使协议可执行的合同的主要元素。
由于类似的原因,如果你尝试在医疗应用程序中使用现有的LLM,你可能会遇到挑战。医学语言包含许多描述医疗状况和程序的不常见词汇。这些词汇可能不会频繁出现在由网络抓取和书籍文本组成的训练数据集中。一些领域还以高度特异的方式使用语言。这最后一个医学语言示例可能看起来像一串随机字符,但实际上是医生用来写处方的速记。这段文字对药剂师来说意思非常明确,饭后和睡前每天四次口服一片。因为模型通过原始预训练任务学习词汇和语言理解,从头开始预训练你的模型将会产生像法律、医学、金融或科学这样的高度专业化领域的更好模型。
现在让我们回到BloombergGPT,它是由Shijie Wu、Steven Lu和Bloomberg的同事在2023年的一篇论文中首次宣布的。BloombergGPT是为特定领域预训练的大型语言模型的一个例子,在这个案例中,是金融领域。Bloomberg的研究人员选择结合金融数据和通用税务数据来预训练一个在金融基准测试上达到最佳结果的模型。同时在通用LLM基准测试上也保持竞争力。因此,研究人员选择了由51%的金融数据和49%的公共数据组成的数据。在他们的论文中,Bloomberg的研究人员更详细地描述了模型架构。他们还讨论了如何以chinchilla规模法则为指导开始,以及他们不得不做出权衡的地方。这两张图表比较了包括BloombergGPT在内的多个LLM与研究人员讨论过的规模法则。左边,对角线追踪了一系列计算预算下以十亿参数为单位的最优模型大小。右边,线条追踪了以令牌数量衡量的计算最优训练数据集大小。每张图上的粉红色虚线表示Bloomberg团队用于训练他们新模型的计算预算。粉红色阴影区域对应于Chinchilla论文中确定的计算最优规模损失。在模型大小方面,你可以看到BloombergGPT大致遵循了给定计算预算130万GPU小时或大约2.3亿petaflops的Chinchilla方法。该模型仅略高于粉红色阴影区域,表明参数数量接近最优。然而,用于预训练BloombergGPT的实际令牌数量5690亿低于Chinchilla推荐值,这是由于金融领域数据的有限可用性。这表明现实世界的限制可能会迫使你在预训练自己的模型时做出权衡。
祝贺你完成了第一周的学习,你已经涵盖了很多内容,所以让我们花一点时间回顾你所看到的。Mike带你了解了一些常见的LLM用例,如作文写作、对话总结和翻译。然后他详细介绍了驱动这些模型的变压器架构。并讨论了一些你可以在推理时使用的参数来影响模型的输出。他最后介绍了一个生成性AI项目生命周期,你可以使用它来规划和指导你的应用开发工作。接下来,你看到了模型在称为预训练的初始训练阶段是如何在大量文本数据上进行训练的。这是模型发展语言理解能力的地方。你探讨了训练这些模型的一些计算挑战,这些挑战是显著的。实际上,由于GPU内存限制,你在训练模型时几乎总是会使用某种形式的量化。你以讨论LLM发现的缩放法则以及如何使用它们设计计算最优模型结束了本周的学习。如果你想阅读更多细节,请确保查看本周的阅读练习。
Domain-specific training: BloombergGPT(领域特定训练实例- BloombergGPT)
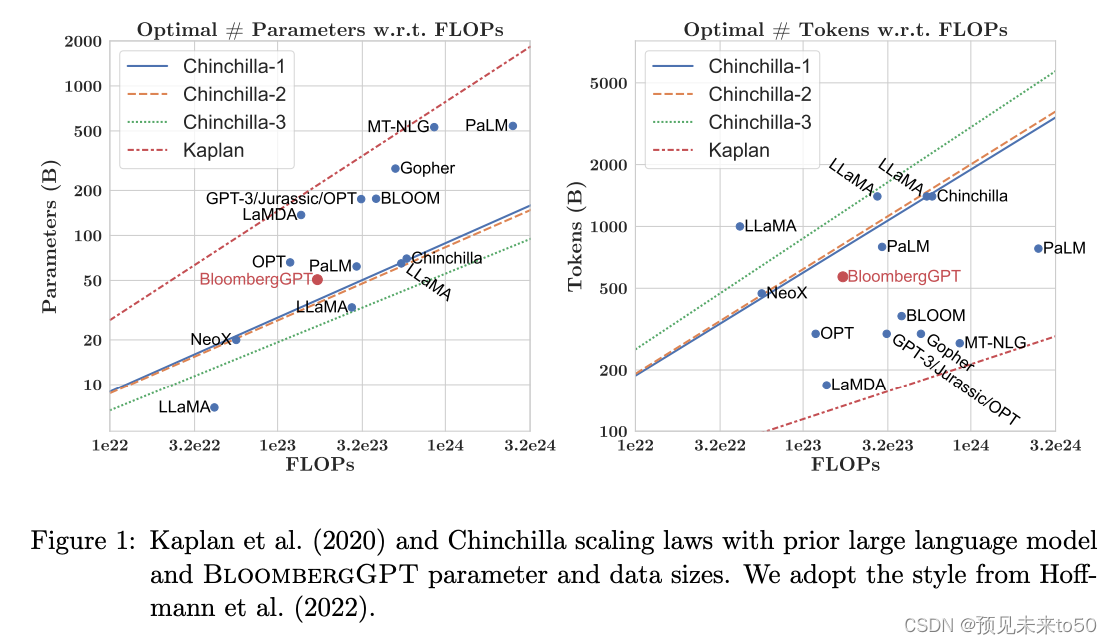
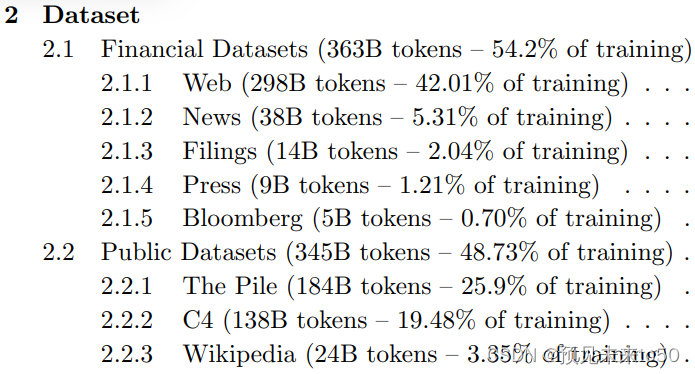
BloombergGPT, developed by Bloomberg, is a large Decoder-only language model. It underwent pre-training using an extensive financial dataset comprising news articles, reports, and market data, to increase its understanding of finance and enabling it to generate finance-related natural language text. The datasets are shown in the image above.
During the training of BloombergGPT, the authors used the Chinchilla Scaling Laws to guide the number of parameters in the model and the volume of training data, measured in tokens. The recommendations of Chinchilla are represented by the lines Chinchilla-1, Chinchilla-2 and Chinchilla-3 in the image, and we can see that BloombergGPT is close to it.
While the recommended configuration for the team’s available training compute budget was 50 billion parameters and 1.4 trillion tokens, acquiring 1.4 trillion tokens of training data in the finance domain proved challenging. Consequently, they constructed a dataset containing just 700 billion tokens, less than the compute-optimal value. Furthermore, due to early stopping, the training process terminated after processing 569 billion tokens.
The BloombergGPT project is a good illustration of pre-training a model for increased domain-specificity, and the challenges that may force trade-offs against compute-optimal model and training configurations.
You can read the BloombergGPT article here.
彭博社开发的BloombergGPT是一个大型的仅限解码器的语言模型。它通过使用广泛的金融数据集进行预训练,这些数据集包括新闻文章、报告和市场数据,以增强其对金融领域的理解,并使其能够生成与金融相关的自然语言文本。上述数据集如上图所示。
在BloombergGPT的训练过程中,作者们使用了Chinchilla规模定律来指导模型中的参数数量和训练数据的量(以tokens计)。Chinchilla的推荐配置在图中由Chinchilla-1、Chinchilla-2和Chinchilla-3线表示,我们可以看到BloombergGPT的配置接近这些推荐。
尽管对于团队可用的训练计算预算,推荐的配置是500亿个参数和1.4万亿个tokens,但在金融领域获取1.4万亿个tokens的训练数据被证明是具有挑战性的。因此,他们构建了一个仅包含7000亿个tokens的数据集,少于计算最优值。此外,由于提前终止,训练过程在处理了5690亿个tokens后结束。
BloombergGPT项目很好地说明了预训练模型以提高特定领域的专业性,以及可能迫使在实际配置中偏离计算最优模型和训练配置的挑战。
您可以在此处阅读BloombergGPT文章。

一站式 AI 云服务平台
更多推荐

 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)