
智能文档抽取系统:成为企业数字化转型的基础能力
在数字化浪潮席卷全球的今天,各类组织每天产生和接收的海量文档中蕴含着宝贵的业务信息。然而,这些信息大多以非结构化或半结构化的形式存在,如PDF报告、扫描图像、电子邮件、合同文本等。智能文档抽取技术应运而生,成为连接非结构化数据与可操作洞察的关键桥梁。
在数字化浪潮席卷全球的今天,各类组织每天产生和接收的海量文档中蕴含着宝贵的业务信息。然而,这些信息大多以非结构化或半结构化的形式存在,如PDF报告、扫描图像、电子邮件、合同文本等。智能文档抽取技术应运而生,成为连接非结构化数据与可操作洞察的关键桥梁。

智能文档抽取技术的工作原理
智能文档抽取技术是一种融合多种人工智能技术的解决方案,其核心工作流程可分为以下几个阶段:
- 文档预处理阶段 格式转换:将PDF、图像等格式转换为可处理的统一格式 图像增强:对扫描文档进行去噪、纠偏、对比度调整等操作 文档结构分析:识别文档的物理布局和逻辑结构(标题、段落、表格等)
- 内容识别与提取阶段 光学字符识别(OCR):将图像中的文字转换为机器可读文本 自然语言处理(NLP):理解文本的语义和上下文关系 计算机视觉:识别文档中的图表、印章、签名等非文本元素
- 数据标准化与输出阶段 实体识别:提取人名、地点、日期、金额等关键信息 关系抽取:确定不同实体之间的关联 数据验证:通过规则引擎或机器学习模型验证提取结果的准确性 结构化输出:将提取的信息转换为JSON、XML或直接写入数据库
技术难点与挑战
尽管智能文档抽取技术已取得显著进展,但仍面临诸多挑战:
- 文档多样性带来的挑战 布局复杂性:处理多栏、嵌套表格、不规则排版的文档 质量差异性:应对低分辨率扫描、模糊、倾斜、遮挡等问题 领域特异性:不同行业(如医疗、法律、金融)文档具有独特术语和结构
- 语义理解深度问题 专业术语和领域特定缩写的准确理解 隐含上下文关系的捕捉(如跨文档引用)
- 动态适应需求 文档模板随时间演变的跟踪适应 处理部分结构化和完全非结构化 混合内容小样本情况下的快速领域适应
- 系统集成与性能平衡 大规模文档处理的吞吐量与延迟优化 与企业现有系统的无缝集成 敏感数据的隐私保护与合规性
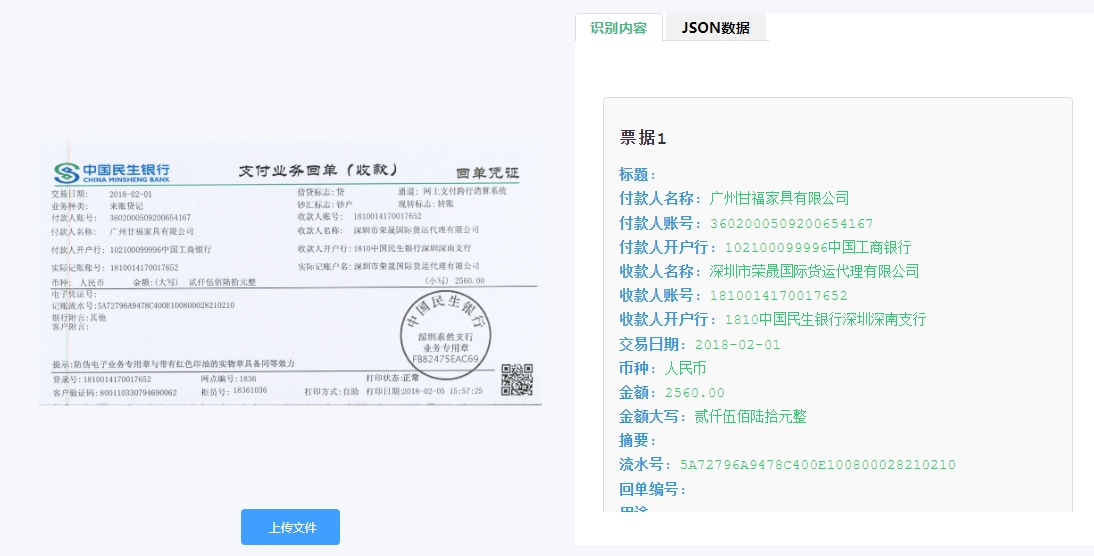
智能文档抽取技术的功能特点:
- 多格式兼容性 支持PDF(文本型和扫描型)、Word、Excel、PPT、图像(JPG、PNG等)、电子邮件等多种格式能够处理混合格式 文档,如包含嵌入式表格和图像的PDF
- 自适应学习能力 通过持续学习优化抽取准确率 支持少量样本的快速领域适配 自动识别新文档类型并调整处理策略
- 上下文感知理解 理解文档整体语境以消除歧义 识别跨页、跨栏的关联信息 处理多语言混合文档
- 智能质量控制 实时置信度评分 自动标记低置信度提取项供人工复核 提供可视化验证界面
- 高度可配置性 基于GUI的规则配置界面 支持预定义和自定义模板 灵活的输出格式和集成选项
智能文档抽取技术的应用场景
金融与保险领域
自动化贷款申请处理:从收入证明、银行对账单中提取关键财务数据
保险理赔自动化:快速解析医疗报告、事故证明等
支持文件合规监控:从合同和交易文档中识别潜在风险条款
法律与合规领域
合同分析:提取关键条款、义务和日期信息
尽职调查:快速分析大量法律文档
法规遵从:监控文档是否符合最新法律法规
政府与公共服务
证件信息自动录入:处理身份证、护照、驾驶证等
表格处理:自动化税务申报、补贴申请等流程
历史档案数字化:转换和提取珍贵历史记录中的信息
供应链与物流
发票和采购订单处理:自动化数据录入和核对
运单分析:提取货物信息、路线和时效数据
供应商文档管理:快速审核资质证明和合规文件
随着人工智能技术的持续进步,特别是大语言模型和计算机视觉技术的融合,文档抽取的准确率和适用范围将不断扩大。智能文档抽取技术正在重塑企业处理信息的方式,将人力从繁琐的手工数据录入中解放出来,同时显著提高了数据处理的速度和准确性。未来,智能文档处理将成为企业数字化转型的基础能力,为知识管理和决策支持提供强大助力。
文章为本人原创,禁止转载,如有疑问请致邮:721251757@qq.com

一站式 AI 云服务平台
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)