
人工智能的演进:从概念到现实
人工智能(Artificial Intelligence,AI)是指由人类制造的系统或机器所表现出的智能。它的核心目标是让计算机像人类一样进行"思考"、学习、推理、感知和决策。简而言之,AI就是赋予机器模仿人类智能行为的能力。AI的发展可以简要概括为:AI 1.0是"人教机器",AI 2.0是"机器学人",而未来的AI 3.0将是"类人智能"。从基于规则的系统到数据驱动的深度学习,再到未来可能出现
引言
人工智能(AI)已经从科幻小说中的概念逐渐成为我们日常生活的一部分。从ChatGPT到自动驾驶,从智能客服到图像识别,AI技术正在深刻地改变我们的生活方式和工作方式。本文将带您深入了解AI的本质、发展历程以及未来趋势,并通过实际代码案例展示AI技术在不同领域的应用。
什么是人工智能?
人工智能(Artificial Intelligence,AI)是指由人类制造的系统或机器所表现出的智能。它的核心目标是让计算机像人类一样进行"思考"、学习、推理、感知和决策。简而言之,AI就是赋予机器模仿人类智能行为的能力。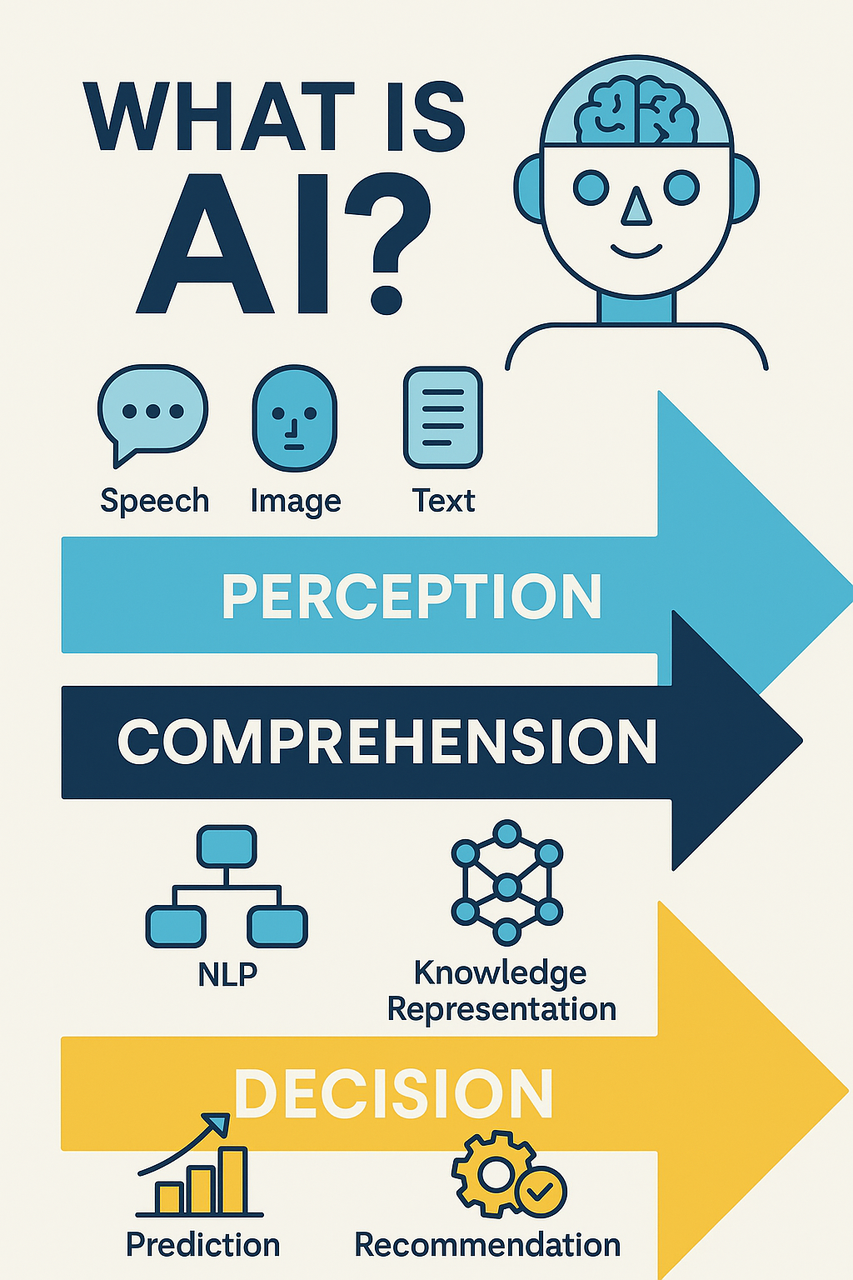
AI的主要功能
- 自然语言处理(NLP):使机器能够理解、解释和生成人类语言,如语音识别、文本理解和聊天机器人。
- 计算机视觉:让机器"看懂"图像或视频,如人脸识别和图像分类。
- 机器学习:通过数据训练模型,使机器能够自我改进。
- 专家系统:模仿人类专家解决专业问题。
- 自动规划与决策:用于自动驾驶、智能调度等场景。
- 机器人技术:使机器具备感知和行动能力,完成特定任务。
AI的类型
- 弱人工智能(Narrow AI):专注于完成单一任务,如推荐算法和图像识别。目前我们接触到的绝大多数AI系统都属于这一类别。
- 强人工智能(General AI):具备像人类一样的综合智能,能够理解、学习和应用各种认知能力,目前仍处于研究阶段。
- 超级人工智能(Super AI):理论上超越人类的智能,具有自我意识和情感,目前仅存在于设想中,也是许多科幻作品的主题。
AI的发展历史
萌芽期(1950s-1970s)
- 1950年:艾伦·图灵提出著名的"图灵测试",首次为判断机器是否具有智能提供了标准。
- 1956年:达特茅斯会议上,约翰·麦卡锡首次提出"人工智能"这一术语,标志着人工智能成为一门正式学科。
- 1966年:ELIZA程序问世,这是一个模拟心理治疗师的早期自然语言处理系统。
探索期(1970s-1980s)
- 1972年:MYCIN专家系统开发,用于诊断血液感染疾病,但依赖人工规则,缺乏自学习能力。
- 1980年前后:由于计算资源有限和技术瓶颈,AI研究热情减退,这一时期被称为"第一次AI寒冬"。
复兴期(1980s-1990s)
- 1986年:反向传播算法的普及使神经网络理论重现关注。
- 1997年:IBM的深蓝超级计算机战胜国际象棋世界冠军卡斯帕罗夫,成为里程碑事件。
- 1990年代末:硬件限制和实际应用有限,导致"第二次AI寒冬"。
爆发期(2010s至今)
- 2012年:AlexNet在ImageNet图像识别竞赛中以压倒性优势获胜,标志着深度学习时代的到来。
- 2016年:AlphaGo击败世界围棋冠军李世石,展示了AI在复杂战略游戏中的能力。
- 2018年:BERT模型发布,革新了自然语言处理领域。
- 2022年:ChatGPT发布,大型语言模型进入公众视野,AI应用进入爆发期。
AI的典型应用与代码案例
1. 自然语言处理(NLP)
现代NLP技术使机器能够理解、分析和生成人类语言。以下是使用Python和Transformers库进行情感分析的简单示例:
from transformers import pipeline
# 初始化情感分析pipeline
sentiment_analyzer = pipeline("sentiment-analysis")
# 分析文本情感
text = "人工智能技术的发展让我非常兴奋!"
result = sentiment_analyzer(text)
print(f"文本: {text}")
print(f"情感: {result[0]['label']}, 置信度: {result[0]['score']:.4f}")
NLP技术的应用场景:
- 智能客服和聊天机器人
- 自动生成文本内容
- 情感分析和舆情监控
- 搜索引擎的语义理解
- 多语言翻译
2. 计算机视觉
计算机视觉让机器能够"看懂"图像和视频。以下是使用Python和OpenCV进行人脸检测的示例:
import cv2
import numpy as np
# 加载人脸检测器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 读取图像
image = cv2.imread('example.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
# 在检测到的人脸周围绘制矩形
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 显示结果
cv2.imshow('人脸检测结果', image)
cv2.waitKey()
计算机视觉的应用场景:
- 人脸识别和验证
- 自动驾驶中的物体检测
- 医疗影像诊断
- 工业质检
- 安防监控
3. 机器学习分类算法
以下是使用Python和Scikit-learn库实现简单的垃圾邮件分类器:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report
# 加载数据(假设已有标记好的邮件数据集)
data = pd.read_csv('emails.csv')
X = data['email_text']
y = data['is_spam'] # 1表示垃圾邮件,0表示正常邮件
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征提取:将文本转换为词频向量
vectorizer = CountVectorizer()
X_train_vectors = vectorizer.fit_transform(X_train)
X_test_vectors = vectorizer.transform(X_test)
# 训练朴素贝叶斯分类器
classifier = MultinomialNB()
classifier.fit(X_train_vectors, y_train)
# 预测并评估
y_pred = classifier.predict(X_test_vectors)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"准确率: {accuracy:.4f}")
print("分类报告:\n", report)
4. 深度学习与神经网络
以下是使用TensorFlow/Keras构建简单神经网络进行手写数字识别的示例:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 数据预处理
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# 构建CNN模型
model = keras.Sequential(
[
layers.InputLayer(input_shape=(28, 28, 1)),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(10, activation="softmax"),
]
)
# 编译模型
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=5, validation_split=0.1)
# 评估模型
score = model.evaluate(x_test, y_test)
print(f"测试集准确率: {score[1]:.4f}")
5. 推荐系统
以下是一个基于协同过滤的简单推荐系统实现:
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 假设的用户-物品评分矩阵
ratings = pd.DataFrame({
'user_id': [1, 1, 1, 2, 2, 3, 3, 3, 3],
'item_id': [101, 102, 103, 101, 103, 101, 102, 103, 104],
'rating': [5, 3, 4, 3, 5, 4, 5, 5, 3]
})
# 创建用户-物品矩阵
user_item_matrix = ratings.pivot(index='user_id', columns='item_id', values='rating').fillna(0)
# 计算用户之间的相似度
user_similarity = cosine_similarity(user_item_matrix)
user_similarity_df = pd.DataFrame(user_similarity, index=user_item_matrix.index, columns=user_item_matrix.index)
# 为用户生成推荐
def recommend_items(user_id, user_item_matrix, user_similarity_df, n_recommendations=3):
# 获取该用户尚未评分的物品
user_ratings = user_item_matrix.loc[user_id]
unrated_items = user_ratings[user_ratings == 0].index
# 计算预测评分
recommendations = {}
for item in unrated_items:
# 找出评价过该物品的用户
users_rated_item = user_item_matrix[item][user_item_matrix[item] > 0].index
if len(users_rated_item) > 0:
# 计算加权评分
item_rating_sum = 0
similarity_sum = 0
for other_user in users_rated_item:
if other_user != user_id:
similarity = user_similarity_df.loc[user_id, other_user]
item_rating = user_item_matrix.loc[other_user, item]
item_rating_sum += similarity * item_rating
similarity_sum += similarity
if similarity_sum > 0:
predicted_rating = item_rating_sum / similarity_sum
recommendations[item] = predicted_rating
# 排序并返回前N个推荐
sorted_recommendations = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)
return sorted_recommendations[:n_recommendations]
# 为用户1生成推荐
recommendations = recommend_items(1, user_item_matrix, user_similarity_df)
print(f"为用户1推荐的物品: {recommendations}")
#结果
# 为用户1推荐的物品: [(104, 3.0)]
AI的算法原理
传统机器学习算法
这些算法通常依赖特征工程:
- 决策树(Decision Tree):通过分支结构表示决策和结果。
- 随机森林(Random Forest):集成多个决策树的结果,提高准确性和防止过拟合。
- 支持向量机(SVM):寻找能够最大化分类边界的超平面。
- K-近邻(KNN):基于最近邻居的分类算法。
- 朴素贝叶斯(Naive Bayes):基于贝叶斯定理的概率分类器。
- 逻辑回归(Logistic Regression):用于预测二元输出的概率模型。
深度学习(Deep Learning)
使用神经网络进行特征提取与预测:
- 多层感知机(MLP):基础的前馈神经网络。
- 卷积神经网络(CNN):特别适用于图像处理,通过卷积层提取空间特征。
- 循环神经网络(RNN)与LSTM:适用于时间序列与文本处理,能处理序列数据。
- Transformer:当前主流的NLP架构,如BERT、GPT系列,通过自注意力机制处理序列数据。
- 生成对抗网络(GAN):包含生成器和判别器的网络结构,用于图像生成、风格迁移等。
强化学习(Reinforcement Learning)
让AI通过"试错"来学习,主要应用于需要连续决策的场景:
- Q-learning:基于值函数的强化学习算法。
- 深度Q网络(DQN):结合深度学习与Q-learning。
- 策略梯度法:直接优化策略的方法。
- Actor-Critic:结合值函数与策略梯度的混合方法。
AI的演进:从1.0到2.0 下一个3.0
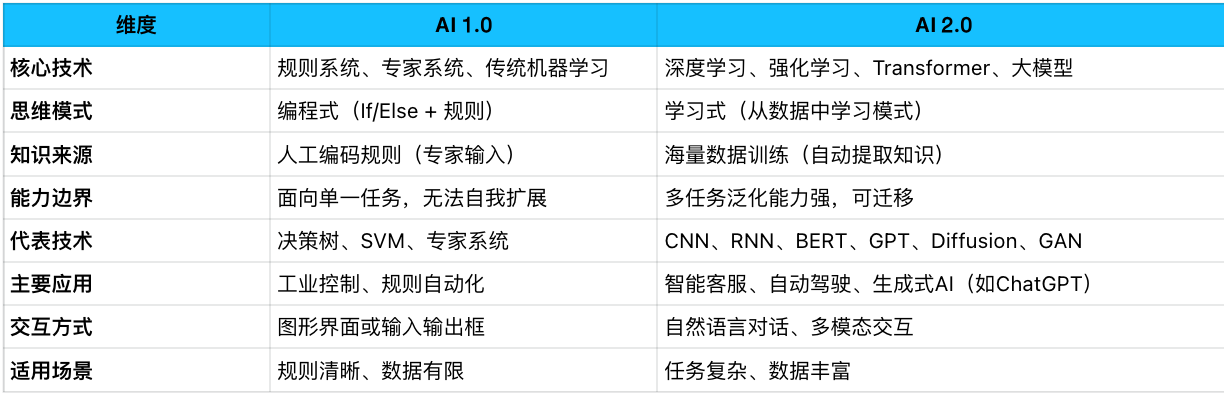
AI 1.0(基于规则的系统)
- 定义:指人工智能的早期阶段,主要基于人工设定的规则和逻辑。
- 代表产品:专家系统、基于规则的分类器
- 特点:需要人工编写规则,缺乏自适应性,只能处理特定领域问题
示例:基于规则的专家系统
# 基于规则的简单医疗诊断系统
def medical_diagnosis(symptoms):
if "发热" in symptoms and "咳嗽" in symptoms and "疲劳" in symptoms:
return "可能是感冒或流感,建议休息并多喝水"
elif "头痛" in symptoms and "恶心" in symptoms:
return "可能是偏头痛,建议在安静环境休息"
elif "腹痛" in symptoms and "腹泻" in symptoms:
return "可能是肠胃炎,建议清淡饮食"
else:
return "症状不明确,请咨询医生"
# 使用示例
patient_symptoms = ["发热", "咳嗽", "喉咙痛"]
diagnosis = medical_diagnosis(patient_symptoms)
print(diagnosis)
AI 2.0(数据驱动的机器学习)
- 定义:指人工智能技术的现代阶段,以深度学习、大数据和云计算的兴起为标志。
- 代表产品:ChatGPT、DALL-E、Midjourney等大型模型
- 特点:基于大规模数据训练,能自我学习和适应,处理能力大幅提高
示例:使用Transformer模型进行文本生成
from transformers import GPT2LMHeadModel, BertTokenizer
import torch
# 加载轻量中文模型和分词器
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
model.eval()
# 设置 pad_token(必须手动设置)
tokenizer.pad_token = '[PAD]'
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
model.resize_token_embeddings(len(tokenizer))
model.config.pad_token_id = tokenizer.convert_tokens_to_ids('[PAD]')
# 准备中文输入
input_text = "人工智能正在改变"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
attention_mask = input_ids.ne(tokenizer.pad_token_id).long() # ✅ 现在不会报错了!
# 生成文本
with torch.no_grad():
output = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_length=50,
num_return_sequences=1,
temperature=0.7,
top_k=50,
top_p=0.95,
do_sample=True,
pad_token_id=tokenizer.pad_token_id
)
# 解码输出
generated_text = tokenizer.decode(
output[0],
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)
print("====== 中文生成结果 ======")
print(generated_text)

展望AI 3.0(通用人工智能)
Artificial General Intelligence (AGI),不少专家将通用人工智能视为AI 3.0的目标阶段,具备:
- 真正的"自我意识"
- "自主学习"能力
- "跨模态理解"能力
- 多模态融合(图像+文本+语音+视频)
- 自我反思与规划能力
- 多智能体协作
未来可能的AGI架构示例(概念性):
# 这是一个概念性的代码,展示AGI可能的系统组件
class AGISystem:
def __init__(self):
self.perception_modules = {
"vision": VisionModule(),
"language": LanguageModule(),
"audio": AudioModule(),
"physical": PhysicalSensorModule()
}
self.reasoning_engine = ReasoningEngine()
self.memory = {
"short_term": ShortTermMemory(),
"long_term": LongTermMemory(),
"episodic": EpisodicMemory()
}
self.learning_system = ContinualLearningSystem()
self.self_reflection = SelfReflectionModule()
self.planning = HierarchicalPlanningSystem()
def perceive(self, inputs):
"""处理多模态输入"""
perceptions = {}
for modality, data in inputs.items():
if modality in self.perception_modules:
perceptions[modality] = self.perception_modules[modality].process(data)
return perceptions
def think(self, perceptions):
"""高级认知处理"""
# 更新短期记忆
self.memory["short_term"].update(perceptions)
# 检索相关长期记忆
relevant_knowledge = self.memory["long_term"].retrieve(perceptions)
# 推理与决策
reasoning_results = self.reasoning_engine.reason(
perceptions,
self.memory["short_term"].get_state(),
relevant_knowledge
)
# 自我反思
reflection = self.self_reflection.reflect(reasoning_results)
# 规划行动
action_plan = self.planning.create_plan(reasoning_results, reflection)
return action_plan
def learn(self, experience):
"""从经验中学习"""
self.learning_system.learn_from_experience(experience)
self.memory["episodic"].store(experience)
# 定期整合到长期记忆
if self.learning_system.should_consolidate():
new_knowledge = self.learning_system.extract_knowledge()
self.memory["long_term"].integrate(new_knowledge)
def act(self, action_plan):
"""执行行动计划"""
results = {}
for action_type, action in action_plan.items():
# 执行相应的动作
results[action_type] = self._execute_action(action_type, action)
# 记录经验
experience = {
"perceptions": self.memory["short_term"].get_state(),
"actions": action_plan,
"results": results
}
self.learn(experience)
return results
人工智能的伦理与挑战
当前AI面临的挑战
- 数据隐私问题:AI系统需要大量数据训练,可能涉及个人隐私。
- 算法偏见:模型可能继承训练数据中的偏见,导致不公平的结果。
- 安全风险:恶意使用AI可能导致深度伪造、自动化网络攻击等问题。
- 就业影响:自动化可能取代部分工作岗位,需要社会适应。
- 解释性问题:复杂AI模型通常是"黑盒",难以解释其决策过程。
应对策略
- 透明度:开发可解释的AI系统,增强决策透明度。
- 公平性:减少算法偏见,确保AI系统公平对待不同群体。
- 隐私保护:使用联邦学习、差分隐私等技术保护用户数据。
- 安全框架:建立AI安全评估框架,防范潜在风险。
- 持续教育:帮助人们适应AI时代,学习与AI协作的技能。
总结
AI的发展可以简要概括为:AI 1.0是"人教机器",AI 2.0是"机器学人",而未来的AI 3.0将是"类人智能"。从基于规则的系统到数据驱动的深度学习,再到未来可能出现的通用人工智能,AI技术正在以前所未有的速度发展。
随着技术的不断进步,人工智能将继续深刻地改变我们的生活和工作方式,创造无限可能。同时,我们也需要重视AI发展过程中可能出现的伦理问题和社会挑战,在享受技术便利的同时,确保AI的发展朝着有益于人类的方向前进。
作为技术从业者或普通用户,了解AI的基本概念、发展趋势以及应用场景,将帮助我们更好地适应和利用这一技术浪潮,在AI时代把握机遇,迎接挑战。

一站式 AI 云服务平台
更多推荐



 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)