
【人工智能项目】Bert实现阅读理解
【人工智能项目】Bert实现阅读理解相信大家在学生时代,语文考试中有这样一种类型的题:阅读理解。首先给你一段材料,然后根据上述材料回到问题。有这么经历的同学们,就很容易理解本次任务,就是根据给出的材料,回答相应问题。本次主要是通过github中已存有的源码进行训练并测试给出答案。数据集本次所用的数据集大致格式如下:实验环境本次的实验环境还是一如既往一往情深的选用了google colab。主要是当
·
【人工智能项目】Bert实现阅读理解

相信大家在学生时代,语文考试中有这样一种类型的题:阅读理解。首先给你一段材料,然后根据上述材料回到问题。
有这么经历的同学们,就很容易理解本次任务,就是根据给出的材料,回答相应问题。本次主要是通过github中已存有的源码进行训练并测试给出答案。
数据集
本次所用的数据集大致格式如下:
实验环境
本次的实验环境还是一如既往一往情深的选用了google colab。主要是当时疫情期间做的项目,没卡用。
!nvidia-smi
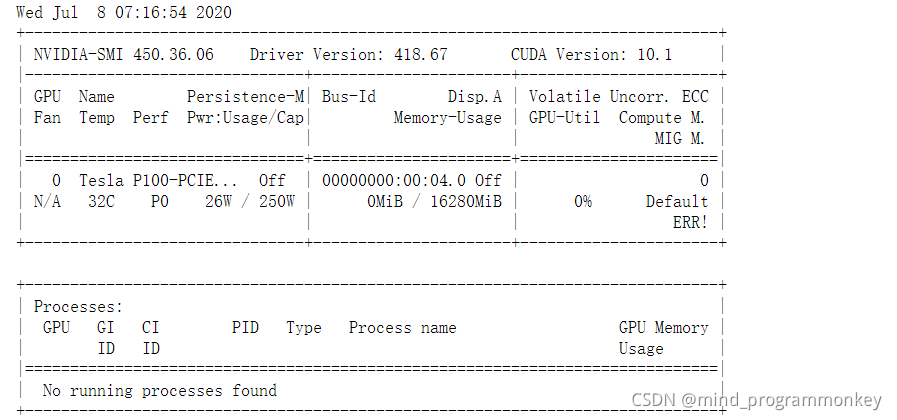
本次训练源码以及预训练模型
# 从这里面找模型替换 https://github.com/ymcui/Chinese-BERT-wwm
!wget https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
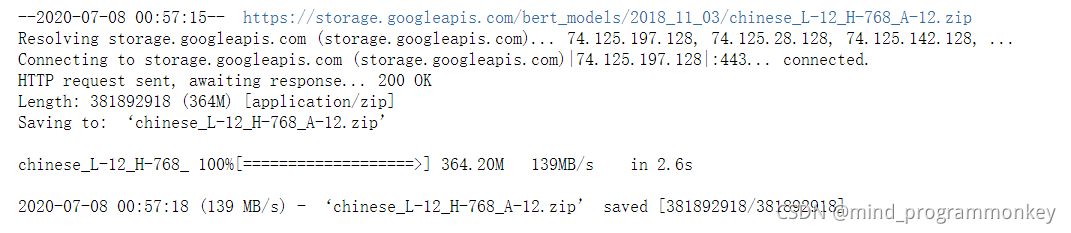
!unzip chinese_L-12_H-768_A-12.zip

# 本次代码
!git clone https://github.com/caldreaming/CAIL.git

安装本次所需的模块
!mv CAIL/* .
!pip install -r bert/requirements.txt
!pip install tensorflow-gpu==1.13.1
!pip install keras==2.2.4

!pip install numpy==1.17.4
训练
!python bert/run_cail_with_yorn.py \
--vocab_file=chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=chinese_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=chinese_L-12_H-768_A-12/bert_model.ckpt \
--do_train=True \
--train_file=./big_train_data.json \
--train_batch_size=8 \
--learning_rate=3e-5 \
--num_train_epochs=7.0 \
--max_seq_length=512 \
--output_dir=output/cail_yorn/
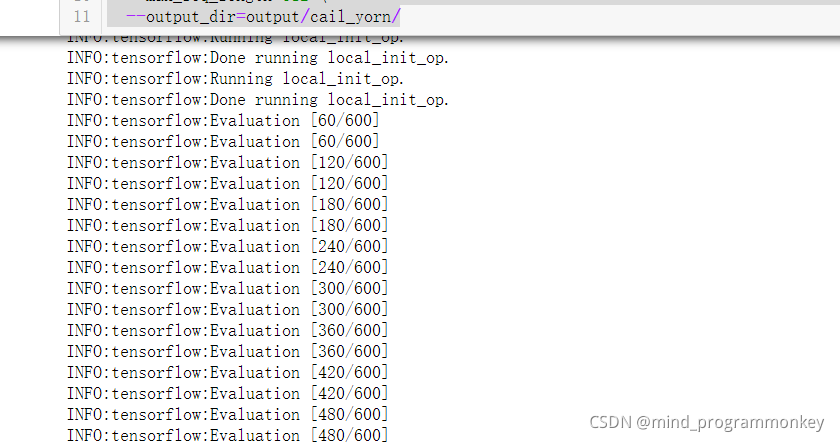
测试
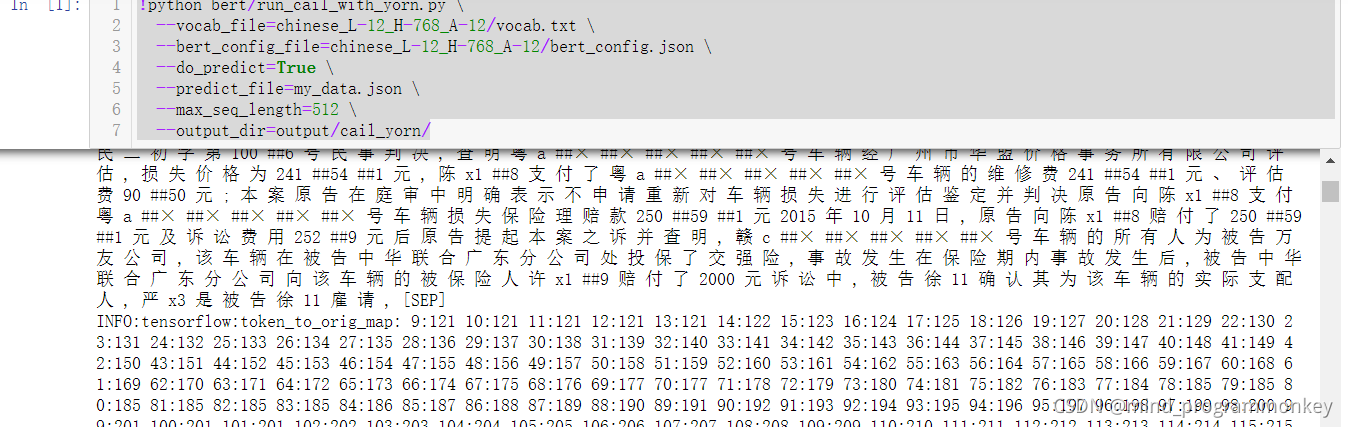
!python bert/run_cail_with_yorn.py \
--vocab_file=chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=chinese_L-12_H-768_A-12/bert_config.json \
--do_predict=True \
--predict_file=my_data.json \
--max_seq_length=512 \
--output_dir=output/cail_yorn/
生成的结果文件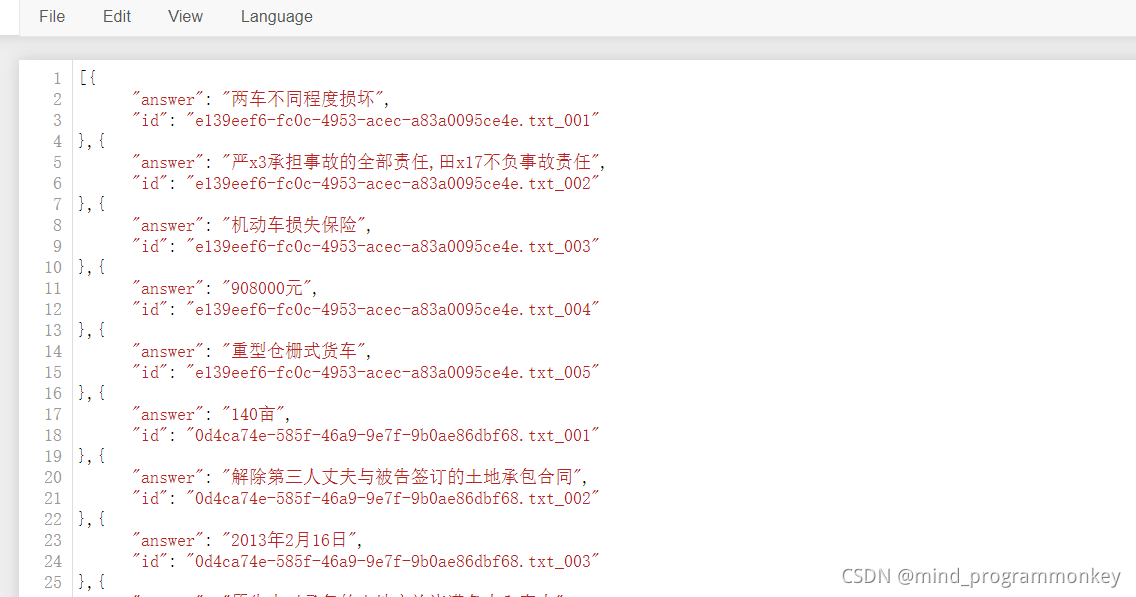
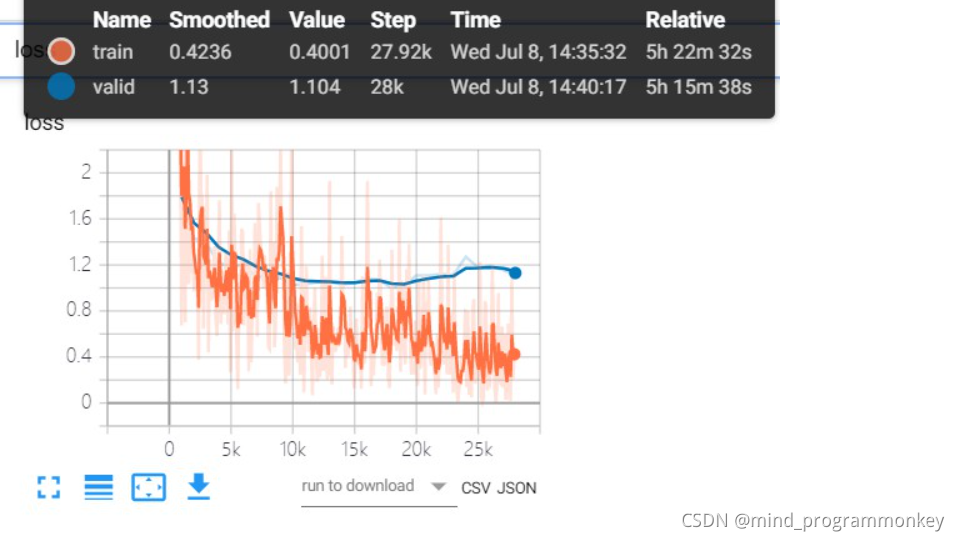
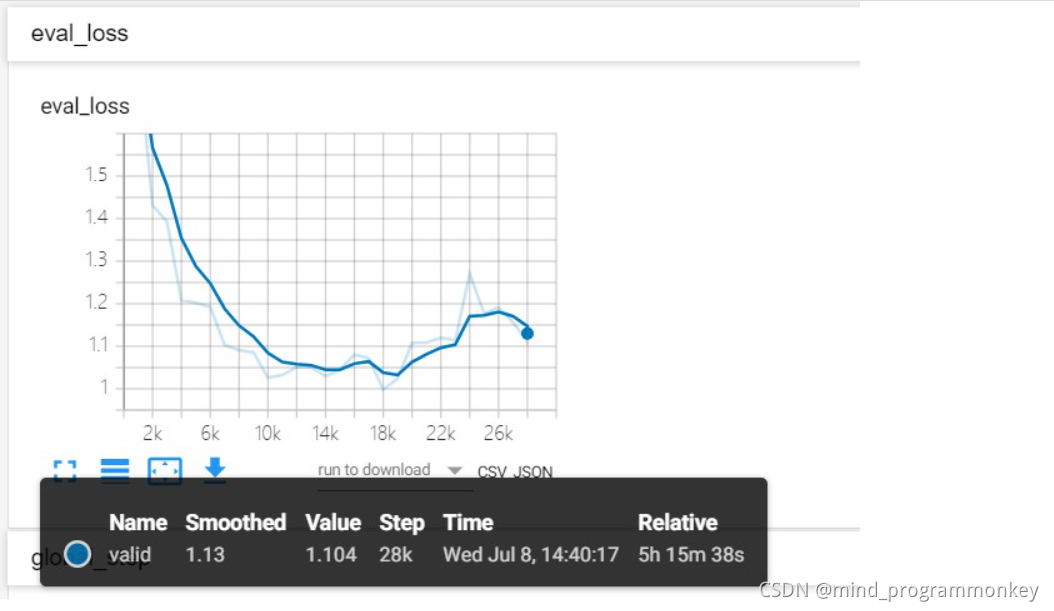
小结
点赞评论收藏走起来瓷们!!!

一站式 AI 云服务平台
更多推荐

 0
0 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)