
Ryzen AI:大语言模型例程测试
Ryzen AI:大语言模型例程测试
环境要求
- win11
- git
- Ryzen AI
下载Llama2模型
我了解到的Llama2模型的下载有两种方式,一种是官方申请,然后使用脚本下载,另一种是通过huggingface下载。下面将对两种方式进行阐述。
官网下载
官网申请
通过官网填写表单申请,内容可以随便填,但注意地区不要选择China,否则会直接报错。之后会向你的邮箱中发送一个连接,这个链接在下载的时候会用到。
得到下载脚本文件
在拿到链接后,我们还不能直接下载,需要使用llama提供的下载脚本进行下载,这个脚本在llama的github网站上有,单独将其下载下来即可。
git bash配置
但是我们下载得到的是.sh脚本,它是linux平台的脚本文件,windows下不可直接执行。因此我们可以借助git的bash环境来进行下载(前提是电脑中已安装git软件)。
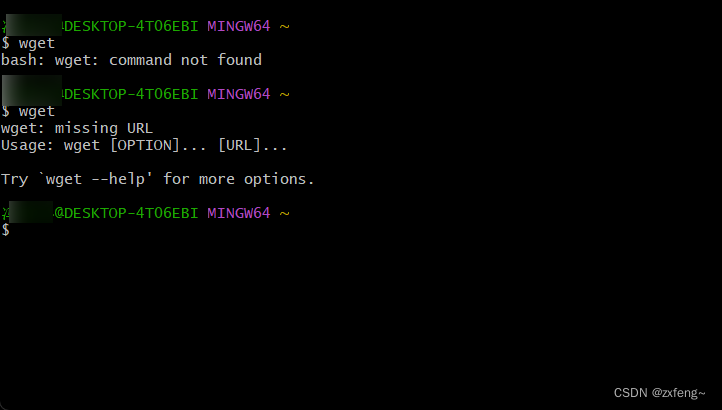
在github的描述中我们可以看到,该脚本文件的运行还需要依赖wget和md5sum两个工具。其中bash已经带有md5sum,我们还需要另外安装wget工具。具体方法如下:
- 首先需要在wget网站上下载对应平台的wget.exe文件。
- 将下载得到的wget.exe文件复制到git安装目录的“\mingw64\bin\”子目录下。
下载模型
在晚上以上步骤后,我们就能够在git bash中运行download.sh脚本进行模型的下载了。在下载的过程中需要提供之前我们邮箱中收到的链接。具体下载流程我没截图,按照脚本的提示一步步来就好啦!这里我只下载了7b和7b-chat模型,因为后面可能到。
在下载完成后,我们得到的是原始模型文件,如果要使用Ryzen AI对其进行量化,则还需要对模型进行转换,该步骤我将在后文中进行阐述。
huggingface下载
由于我没用到这种下载方式,因此在这里不做过多阐述,免得给大家挖坑。
其中需要注意的是下载huggingface的模型文件时需要设置TOKEN环境变量,否则会提示没有权限。具体方法如下:
- 首先在网站的个人中心找到Access Tokens,添加具有read权限的token
- 设置环境变量。注意cmd和terminal设置环境变量的方式不同
- $env:HUGGING_FACE_HUB_TOKEN=“****************” (terminal)
- set HUGGING_FACE_HUB_TOKEN=**************** (cmd)
Ryzen AI transformers环境配置
注意:官方的教程需要使用cmd,不能使用terminal,否则环境变量设置会有问题。
Setup Transformers
- 下载RyzenAI-SW
首先我们需要将github上的RyzenAI-SW克隆到本地,并安装配置其中“example\transformers”下的虚拟环境。
git clone https://github.com/amd/RyzenAI-SW.git
cd RyzenAI-SW\example\transformers
conda env create --file=env.yaml
conda activate ryzenai-transformers
- 下载AWQ Model zoo提供的预权重。(不知道不下载有什么影响,建议还是下载一下)
cd .\RyzenAI-SW
git lfs install
cd .\example\transformers\ext
git clone https://huggingface.co/datasets/mit-han-lab/awq-model-zoo awq_cache
- 设置环境变量
由于脚本中设置环境使用的是set命令,该命令在terminal里不起作用。如果是在terminal环境中,下一步pip安装的时候会报错。不过应该也可以参考前面设置Huggingface Token时的命令,我还没进行尝试。
cd ..\
setup.bat
- 安装依赖包
运行下面这个命令将会在python环境中安装名为RyzenAI的包。这个包不能单独使用,如果使用的话还需要进行第三步的设置环境变量,否则在导入包的时候会报错。
pip install ops\cpp --force-reinstall
由于我们使用的Llama2使用的是pytorch,因此我们跳过安装onnx环境步骤。
Llama 2 - Pytorch
通过以上的步骤,我们就已经完成运行Llama2的所有前置步骤啦。下面就能够开始进行我们的模型量化和部署测试了。
组织模型文件
由于我是从官网获取链接下载的模型,因此模型木能够直接使用,需要先进行转换。
首先,我们需要在transformers文件夹下新建llama-2-wts文件夹和llama-2-wts-hf文件夹。其中llama-2-wts文件夹用于存放我们下载的原始模型,llama-2-wts-hf文件夹用于存放下一步我们转换得到的模型.。之后将我们下载的模型文件放入llama-2-wts文件夹中,并将其中的模型文件夹名称改为7B。(我这里使用的是7B-chat,因此我的7B文件夹是7B-chat更改过来的)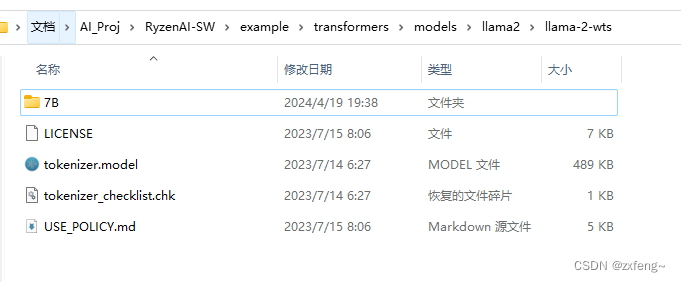
模型转换
执行如下语句对模型进行转换,其中C:\Users\zxfeng.conda\envs\ryzenai-transformers需要修改为你自己的ryzenai-transformers虚拟环境安装的目录。
python C:\Users\zxfeng\.conda\envs\ryzenai-transformers\Lib\site-packages\transformers\models\llama\convert_llama_weights_to_hf.py --input_dir ./llama-2-wts/ --model_size 7B --output_dir ./llama-2-wts-hf/7B
转换完成后,就能够在llama-2-wts-hf文件夹下看到对应的模型了。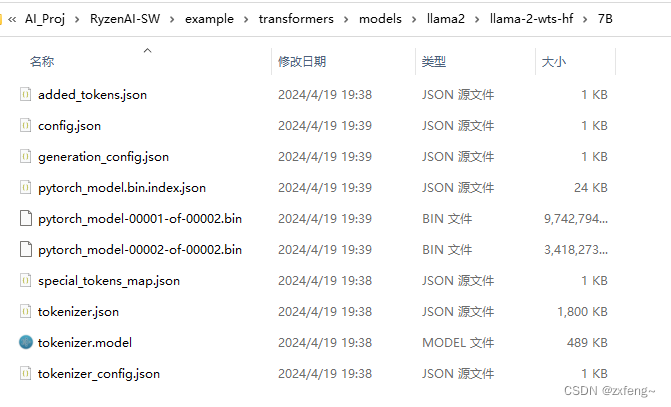
模型量化
官方提供了多种的量化方式,分别如下:
4-bit AWQ
#AWQ - lm_head runs in BF16
python run_awq.py --w_bit 4 --task quantize
#AWQ - lm_head runs in BF16
python run_awq.py --w_bit 4 --task quantize --flash_attention
#AWQ + Quantize lm_head
python run_awq.py --w_bit 4 --task quantize --lm_head
#AWQ + Quantize lm_head
python run_awq.py --w_bit 4 --task quantize --lm_head --flash_attention
3-bit AWQ
#AWQ - lm_head runs in BF16
python run_awq.py --w_bit 3 --task quantize
#AWQ - lm_head runs in BF16
python run_awq.py --w_bit 3 --task quantize --flash_attention
#AWQ + Quantize lm_head
python run_awq.py --w_bit 3 --task quantize --lm_head
#AWQ + Quantize lm_head
python run_awq.py --w_bit 3 --task quantize --lm_head --flash_attention
量化完成后会在llama2文件夹下生成相应的权重文件。
模型测试
量化完成后,我们就能够对量化后得到的模型进行测试啦!
python run_awq.py --task decode --target aie --w_bit 4
****************************************
prompt: What is the meaning of life?
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
response: What is the meaning of life? This is a question that has puzzled philosophers, theologians, scientists, and many others for
****************************************
prompt: Tell me something you don't know.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
response: Tell me something you don't know.
The only thing I can think of is that I don't know how to make you disappear
****************************************
*

一站式 AI 云服务平台
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)