
【大模型入门】深入LLMs - 推荐一个可能是最好的大语言模型入门材料
摘要 本文是对Andrej Karpathy关于大语言模型(LLM)深度解析视频的导读。视频全面覆盖了LLM的核心原理,包括分词器(Tokenizer)如何将文字转换为模型输入、基础模型(Base model)的预训练过程、如何通过后训练(Post-training)优化模型性能、模型缺乏自我认知的特点,以及强化学习(RL)在提升模型推理能力(Reasoning)中的关键作用。文章特别指出,Kar
w## 前言
上一期我们介绍了DeepSeek。但如果你想了解大语言模型(Large Language Model,LLM)的原理,强烈推荐大家去看Andrej Karpathy长达三个半小时的大语言模型介绍视频:Deep Dive into LLMs like ChatGPT(原版在YouTube上,可以点击末尾的原文链接,或自行搜索,国内视频网站应该有不少搬运)。
- 只要你有一点数理或计算机基础,我想不到任何能比它更好的入门材料了;
- 即使对技术本身不感兴趣,这部视频能引导你更聪明地使用AI工具;
- 如果你是AI领域从业者,行业先驱对这个方向的理解也值得学习;
- 哪怕你是LLM专家,看Karpathy如何深入浅出地讲解复杂问题可能也有裨益。
珠玉在前,本文不会介绍LLM的原理,而是做个简单的“导读”。如果你:
- 经常看科普但搞不清各类术语,可以先看本文,验证视频是否覆盖你的知识盲区;
- 或是AI领域的从业者,可以轻松阅读本文,也许能为你提供一些新颖的角度。
关于Andrej Karpathy
他是:
- 斯坦福大学博士,AI领域著名华人学者李飞飞的高徒。
- OpenAI的联合创始人之一。
- 一度被马斯克招揽为特斯拉人工智能总监。
不过,他似乎对教育更感兴趣,经常更新AI的科普视频,获得广泛赞誉。近期也确实成立了一家AI教育公司。
内容简介
看完视频,回味时会发现Karpathy详略得当而生动具体地梳理了几乎所有初学者或行业外人士可能有的疑惑,比如:
- 文字是如何被转换为模型能识别的输入的?
- 研发出ChatGPT这样的模型要经历那些过程?
- 模型有时候为什么会胡说八道?
- 模型知道自己是谁吗?
- DeepSeek的“深度思考”是什么意思,模型是如何深度思考的?
同时,这部视频巧妙回避了所有难以理解的技术细节——这并不是偷懒或不得已而为之。恰恰相反,这源自视频高屋建瓴的视角。事实上,能敏锐地提出简单的好问题可能比通过技术细节攻坚克难更重要。
这里为你罗列下整部视频涉及的内容,看看有没有你感兴趣的。
"读到此处,你可能已经意识到:AI大模型的迭代速度远超想象,仅凭碎片化知识永远追不上技术浪潮在这里分享这份完整版的大模型 AI 学习资料,已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证!免费领取【保证100%免费】
Tokenizer
解决问题:
- 文字是如何转换为模型的输入的?
- DeepSeek等模型API按每一百万tokens来计费,token是什么意思?
技术角度,Karpathy用实例介绍了ChatGPT系列采用的Byte-Level BPE(Byte Pair Encoding。再次声明,本文不会越俎代庖介绍这些技术,如果你不知道BPE是什么,快去看视频吧!)。Byte-Level BPE可以很好地帮助LLM处理不同语言,及解决不认识的字等问题。
视频用到的很有用的工具:Tiktokenizer(https://tiktokenizer.vercel.app/)。可以直接看到一段话在输入模型前变成了什么样。
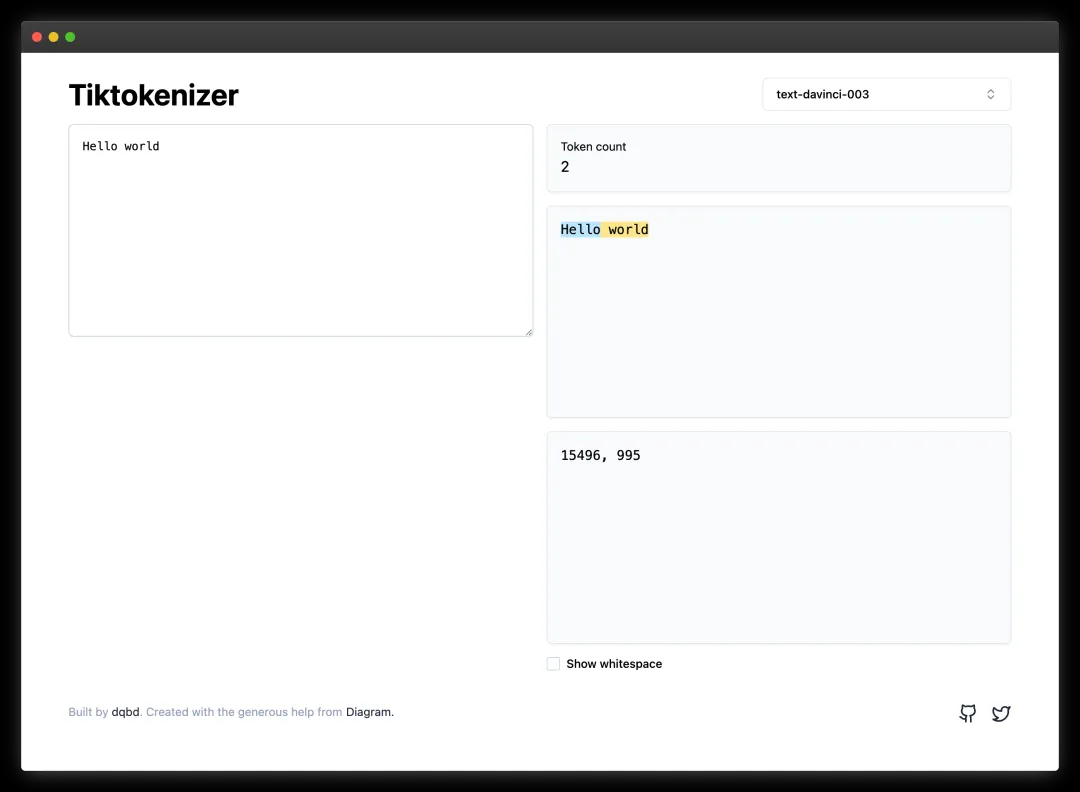
顺便也推荐下Hugging Face的一篇教程:Byte-Pair Encoding tokenization - Hugging Face NLP Course(https://huggingface.co/learn/nlp-course/en/chapter6/5)。
Inference
解决问题:
- LLM是如何运行的?
- 为什么每次答案都不太一样?
- 为什么LLM经常会出现幻觉?(典型场景:科研工作者抱怨LLM编造不存在的文献。)
看完这一段会有个大概的认知。
Base model和pre-training
Base model即经过pre-training但还没有微调的LLM,还不会像智能助手一样回答问题,但已经可以“续写”文字。
Karpathy早先在一个视频中将LLM比喻为压缩包,将所有网络文字打包到模型中。当时我还认为这是个差强人意的科普式比方,但在本次视频中,Karpathy做了个有趣的实验:将Zebra(斑马)的维基词条第一句话输入Llama-3.1(Meta开源的base model),模型竟然几乎一字不差地复述了词条接下来的内容。
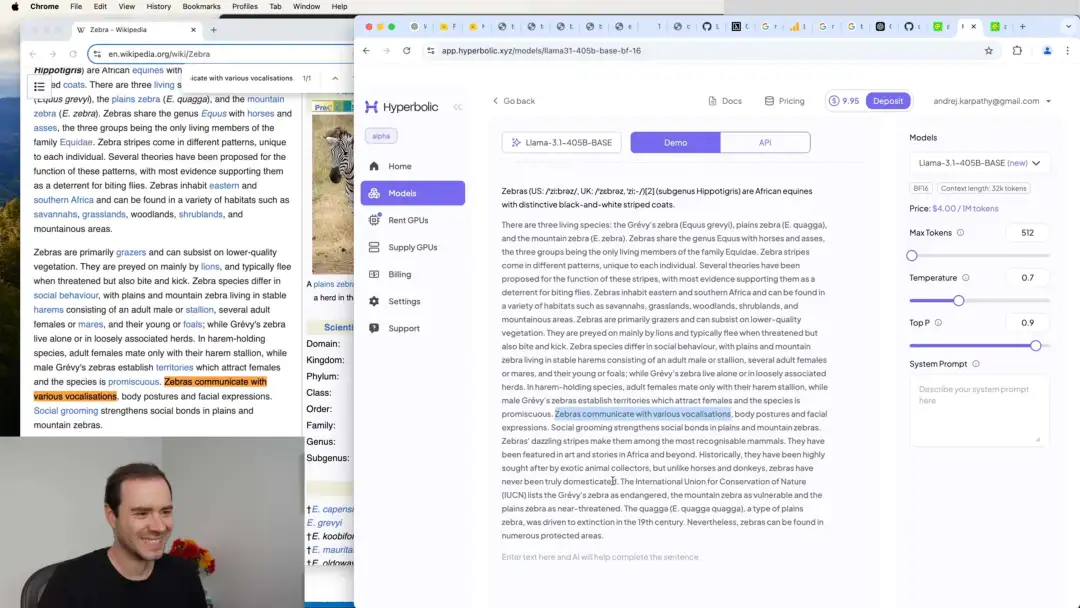
引申开,Karpathy介绍了模型的regurgitation(复述行为)和Hallucination(幻觉),还展示了如何使用few-shot prompting来让base model也学会回答问题。
这次,Karpathy直接将base model比喻为一个Internet Simulator,或者网络内容的“有损压缩”。
Post-training
有了base model,接下来的工作就是post-training,比如:
- 通过SFT(Supervised Fine-tuning)让模型学会对话;
- 减缓LLM的幻觉问题。
诸如SFT是什么,数据从哪里来,什么是合成数据,post-training和pre-training有哪些区别,如何减缓幻觉,甚至有哪些公开的数据集等问题,都将一一解答。
文献主要参考了OpenAI的Training language models to follow instructions with human feedback和Meta的The Llama 3 Herd of Models。
模型的自我认知
在DeepSeek爆火时,指责其蒸馏ChatGPT数据的说法甚嚣尘上。理由之一是DeepSeek经常称自己为ChatGPT。
这一段Karpathy强调了模型是没有自我认知的——它只是在复述训练数据中的内容,而网络上早已充满ChatGPT和人类的对话。
说到这里,我有一个设想:如果我们构造一个数据集,塞满1. 人类迄今为止所有的物理知识;2. 物理不及格的中学生的吐槽日记。经过长期训练,LLM能判断自己的物理水平吗?
Reasoning
上一篇推文大概介绍了DeepSeek的深度思考模式。而Karpathy的解释更直观:Models need token to think。他提出一个问题:

以上两个回答,哪个更好?
目前认为,右边更好。因为LLM是在不断预测下一个token,每输出一个token,数据就从模型里走一遍。而左边的回答先给出了答案,结果显然没有经过足够的迭代。Intermediate token越多,模型就被运行更多遍,得到的答案也可能更靠谱(Karpathy的原话是“spread out its computation over the tokens”)。
在DeepSeek-R1的论文中,我们可以看到它通过强化学习(Reinforcement Learning,RL),自己发现了通过增加输出token来解决问题的技巧(横坐标是训练步数,纵坐标是输出长度):
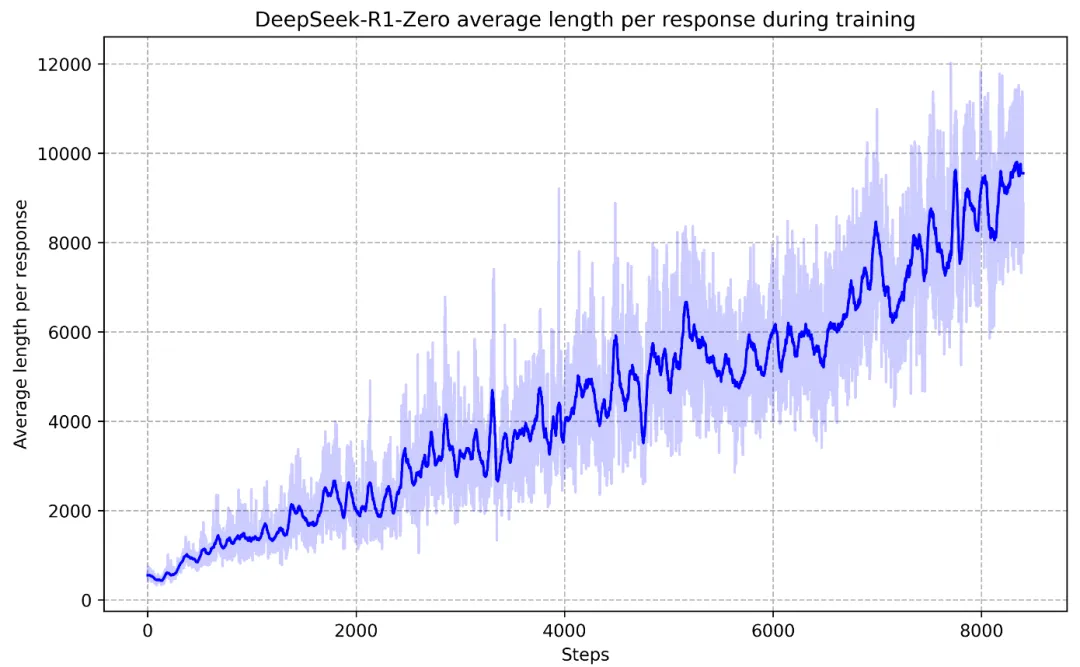
那什么是强化学习?原视频的比喻很精妙:
- Pre-training是让LLM读教科书;
- SFT是让LLM读满分试卷;
- RL是让LLM对照结果自己研究做题思路。
RLHF
LLM中,利用了强化学习的另一个方面是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),主要目的是让模型的回答更符合人类偏好。大名鼎鼎的论文Fine-Tuning Language Models from Human Preferences中核心的设计基本已囊括在视频中。
不过,Karpathy的观点是,RLHF仍只起到fine-tuning的作用,原因在视频中也有所阐述。与此不同,真正带来技术突破的RL,属于前文的Reasoning阶段,这也是DeepSeek-R1带来震动的原因之一。
下图来自DeepSeek-R1论文**。模型通过强化学习,来****到了“ana moment”——它学会了“reevaluate this step-by-step”。**

LLM的未来
Karpathy最后分享了一些对LLM未来发展方向的思考,这里简单复述下:
- Multimodal。我个人的理解是,这里的Multimodal指的是真正的融合。语言、音频、视频在当前技术下均被处理为token,一个支持不同格式输入token的大一统模型可能是未来的方向。
- Tasks和agents。如果你用过Cursor,会知道AI现在已经不仅可以对话,还可以完成任务,即tasks;甚至给他一个最终目标,它会自己决定逐步完成哪些任务,即agents。
- Pervasive,invisible。AI将融入方方面面,无处不在。
- Test-time Training。这是个非常有趣的方向。现在的AI,训练完成后不再“学习”,这与人类不同——当你在写代码时,不仅在“inference”,其实也在“train”,你可能学会了新的API,养成了新的编码习惯……你在工作中进步,而AI目前还不行。
讨论
回到本文最初的观点:即使这部视频的内容其实我基本已经掌握,但还是有不少收获。
作为一名科普向的公众号作者,感觉Karpathy将一个复杂概念娓娓道来的技巧十分惊艳。功利地说,如果你是一名AI领域的先行者,经常被请去给其他行业的人科普,Karpathy的系列视频绝对值得学(照)习(搬)……
这部视频的另一大特色是巧妙地结合了各种资源:
-
用Excalidraw代替幻灯片。内容非常精致。本号介绍Pangu Weather一文中的插图也用到了这个工具。
-
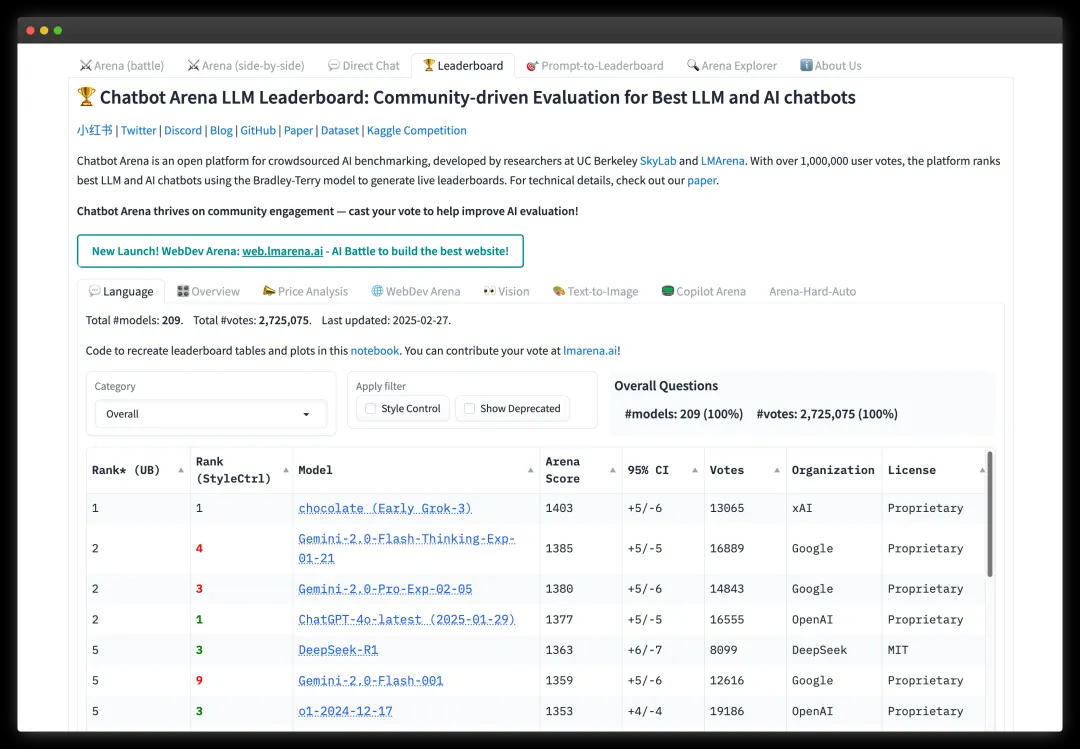
用大量可以在线测试LLM的服务来现场演示,使一些原理变得直观。(顺便介绍其中最有意思的一个资源,lmarena.ai。输入同一个问题,有两个匿名LLM回答,你可以选择哪个更好。因此这个服务也提供了基于”众包“的LLM排名。)
-
旁征博引。比如RL曾经在围棋AI AlphaGo中大放异彩,Karpathy用此来说明,RL可以让模型自己探索胜利路线,不受supervised learning的束缚。
-
甚至Karpathy还介绍了几篇文献,但只是翻出几个片段或插图,并深入浅出地与视频内容结合,甚至让你有种看了一张图就读懂了一篇文献的错觉。
本文发出前,Karpathy又更新了……这次的标题直接是“How I use LLMs”,介绍了他如何使用LLM协助工作。一起学习吧!
看到这里,你已经清晰认知到:
✅ AI大模型正在重构全球科技产业格局
✅ 掌握核心技术者将享受的行业高薪资基准
✅ 碎片化学习正在吞噬90%开发者的竞争力
但问题来了——如何将这份认知转化为实实在在的职场资本?
🔥 你需要的不是更多资料,而是经过验证的「加速器」
这份由十年大厂专家淬炼的**【AI大模型全栈突围工具包】**,正是破解以下困局的密钥
🌟什么是AI大模型
AI大模型是指使用大规模数据和强大的计算能力训练出来的人工智能模型。
这些模型通常具有高度的准确性和泛化能力,可以应用于各种领域,如自然语言处理*、图像识别、*语音识别等。

🛠️ 为什么要学AI大模型
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
🌰大模型岗位需求
大模型时代,企业对人才的需求变了,AI相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
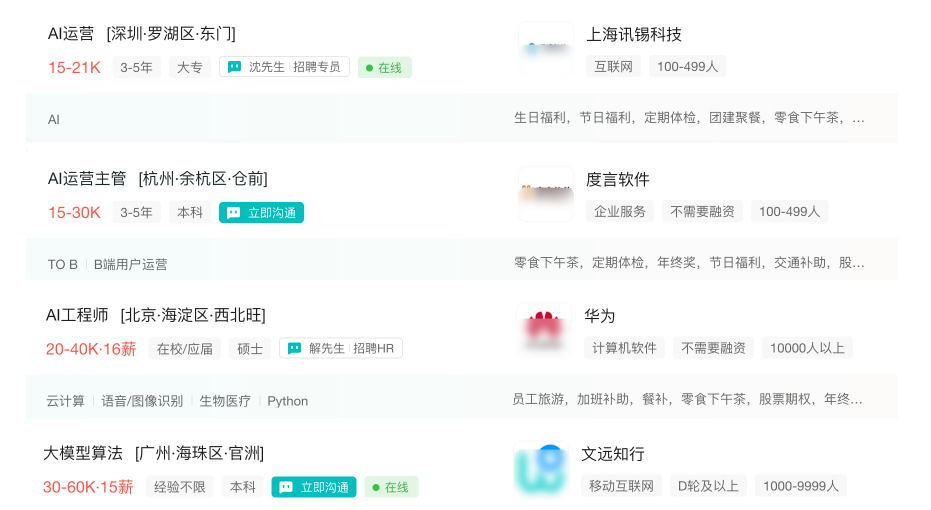
💡掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
🚀如何学习AI 大模型
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的课程资料免费分享,需要的同学扫码领取!
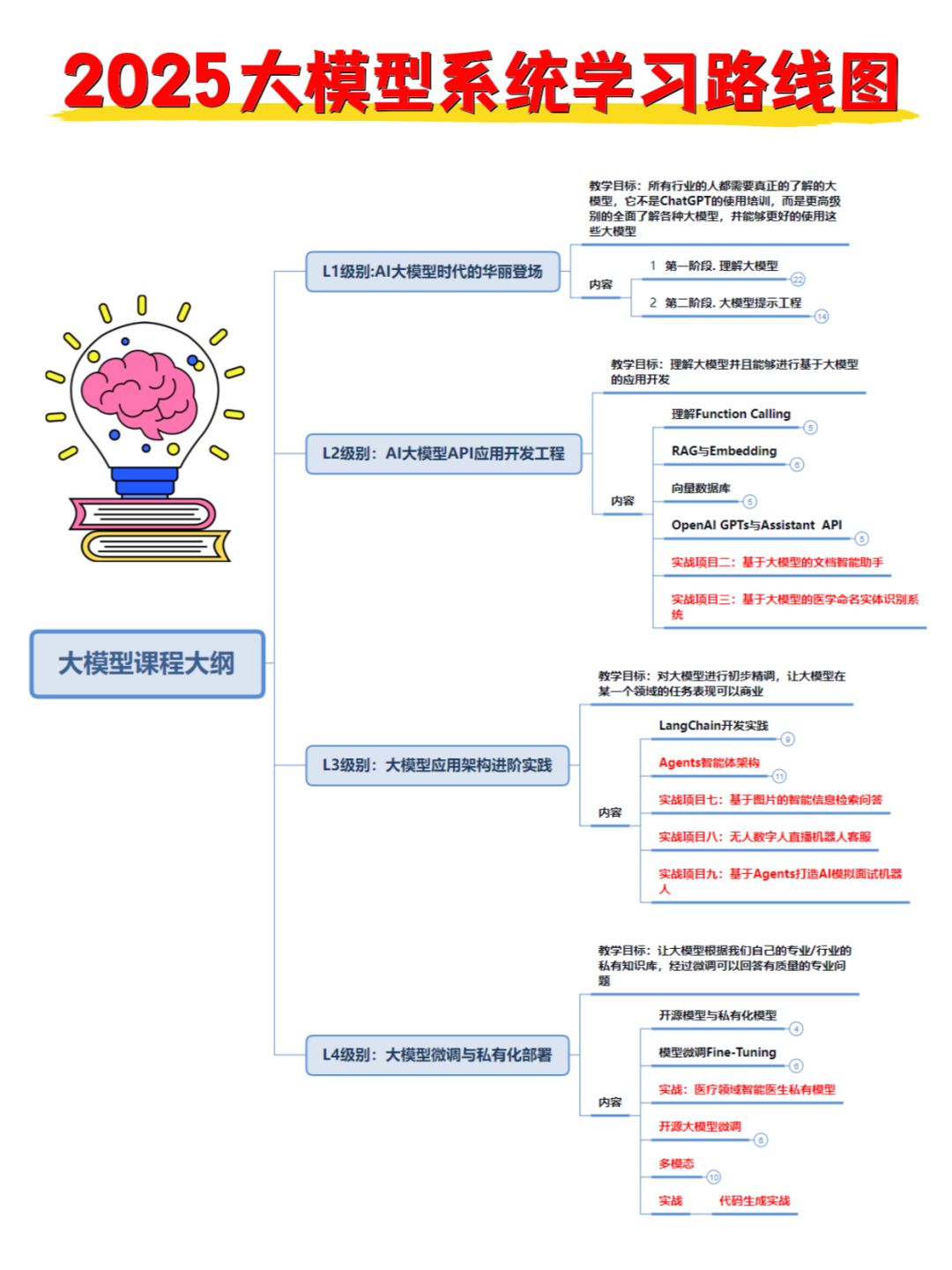
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我帮你准备了详细的学习成长路线图&学习规划。大家跟着这个大的方向学习准没问题。如果你真心想要学AI大型模型,请认真看完这一篇干货!
👉2.AI大模型教学视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩**(文末免费领取)**

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(文末免费领取)

👉4.LLM大模型开源教程👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末免费领取)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。 (文末免费领取)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(文末免费领取)

🏅学会后的收获:
- 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
- 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
- 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
- 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的大模型 AI 学习资料已经整理好,朋友们如果需要可以微信扫描下方我的二维码免费领取

一站式 AI 云服务平台
更多推荐



 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)