
毕业设计:基于机器学习的苹果瑕疵识别分类算法 人工智能 深度学习 YOLO
毕业设计:苹果瑕疵识别分类算法构建一个包含多种瑕疵特征的自制数据集,并应用数据增强技术以丰富样本多样性,我们采用YOLOv5模型进行训练与优化。该算法能够有效识别不同类型的瑕疵,如斑点和裂痕,显著提高了检测效率和精度。涵盖了深度学习、机器学习、算法、人工智能、大数据、信息安全、推荐系统、目标检测等多个热门领域。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,毕业设计选题至关重要
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的苹果瑕疵识别分类算法
课题背景和意义
随着全球对水果质量要求的提高,苹果作为主要的水果品种之一,其外观质量直接影响消费者的购买决策。苹果的瑕疵,如斑点、裂痕、虫害和其他外观缺陷,不仅影响市场价值,还可能影响消费者的健康。因此,传统的人工检查方法效率低、成本高且容易受到人为因素的影响,无法满足大规模生产和分销的需求。利用深度学习算法,系统能够高效地提取图像特征,准确识别各种瑕疵,减少误判和漏判,提高水果的整体质量。
实现技术思路
一、 算法理论基础
1.1 支持向量机
支持向量机是一种有效的监督学习模型,主要用于分类和回归分析。其核心原理是通过寻找最优超平面,将数据集划分为不同类别,最大化类别间的间隔,从而增强模型的泛化能力。离决策边界最近的样本点称为支持向量,这些点对决策边界的构建起到关键作用。SVM还利用核技巧将数据映射到高维特征空间,使得原本不可分的数据在新空间中变得可分。通过优化目标函数,SVM能够有效求解支持向量和决策边界,实现高效的分类。
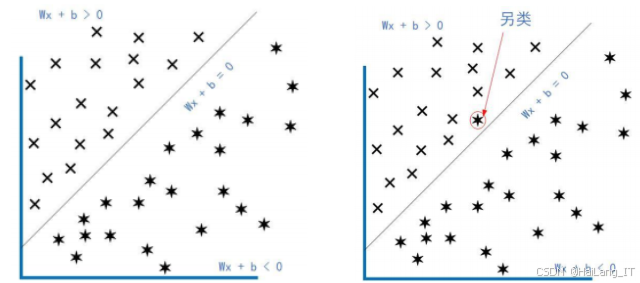
支持向量机(SVM)在苹果瑕疵识别系统中具有显著优势。首先,SVM在处理高维数据时表现出色,能够有效进行特征选择和分类,适应苹果瑕疵检测的复杂视觉任务。其次,SVM通过构建最大间隔超平面,增强了对噪声和异常值的鲁棒性,从而提高识别准确性。此外,SVM的灵活性体现在其可使用不同的核函数,以适应多种数据分布,进一步提升分类效果。它在小样本学习中的良好泛化能力使其适合处理样本不足的问题。最后,SVM模型的可解释性增强了用户对分类决策过程的理解,提高了系统的透明度。
1.2 目标检测
YOLOv5的网络结构由输入端、主干网络、特征融合网络和输出端四部分组成。
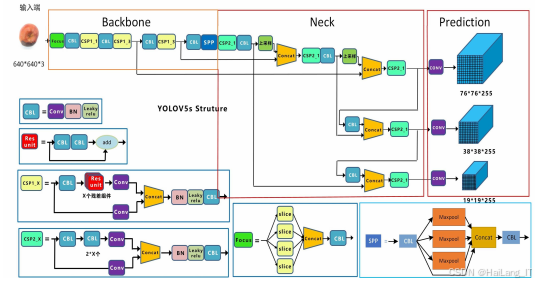
在输入端,采用Mosaic数据增强、自适应锚点计算和自适应图像缩放技术,其中Mosaic通过拼接四个图像来丰富数据集样本,自适应锚点计算则优化锚框设置以提高检测速度并降低计算量。主干网络(Backbone)负责特征提取,主要包括Focus和CSPNet结构。输入的苹果图像在Backbone中进行特征提取,生成有效的特征图层,提取的特征集合用于后续网络构建。Backbone设计中利用了残差网络(Residual),通过1x1卷积和3x3卷积实现高效特征提取,同时将输入和输出结合,使网络更具稳定性和表达能力。
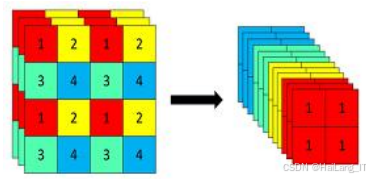
Backbone网络结构采用了Focus网络和CSPNet结构,以提高特征提取的效率。Focus网络通过对输入图像中每隔一个像素获取一个值,生成四个独立的特征层,并将这些层堆叠,从而将空间信息转换为通道信息,扩展输入通道四倍。这种设计减少了浮点运算量,同时保持了信息的完整性。CSPNet通过将堆叠的残差块分为两部分,一部分继续堆叠原始残差块,另一部分在少量加工后直接连接到末端,从而有效降低计算工作量且保证精度。
相关代码示例:
class YOLOv5(nn.Module):
def __init__(self, num_classes):
super(YOLOv5, self).__init__()
self.focus = Focus(3, 64)
self.backbone = nn.Sequential(
CSPBlock(64, 128),
CSPBlock(128, 256),
CSPBlock(256, 512)
)
self.neck = nn.Sequential(
nn.Conv2d(512, 256, kernel_size=1),
nn.Upsample(scale_factor=2),
nn.Conv2d(256, 128, kernel_size=1),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, kernel_size=1)
)
self.output = nn.Conv2d(64, num_classes, kernel_size=1)
def forward(self, x):
x = self.focus(x)
x = self.backbone(x)
x = self.neck(x)
return self.output(x)
# 示例用法
if __name__ == "__main__":
model = YOLOv5(num_classes=80) # 假设有80个类别
input_tensor = torch.randn(1, 3, 640, 640) # 输入尺寸为640x640
output = model(input_tensor)
print(output.shape)二、 数据集
2.1 数据集
由于现有的数据集无法满足需求,我决定亲自进行苹果瑕疵识别分类算法的数据集制作。为确保数据的多样性和真实性,我在不同的环境和条件下拍摄苹果图像,包括果园、市场以及人工照明下的室内场景。这一过程涉及多种光照、角度和距离的拍摄,以捕捉到各种瑕疵特征,如斑点、裂痕和虫害等。通过这种方式,我能够获得丰富的图像样本,确保数据集能够覆盖实际应用中可能遇到的各种情况,从而为苹果瑕疵识别提供坚实的数据基础。
在完成数据采集后,接下来的步骤是对图像进行详细标注。我使用专业的标注工具,对每张图像中的苹果瑕疵进行标识,包括瑕疵的类型和位置。这一过程要求高度的准确性和一致性,以确保每个样本的标注信息都能够真实反映其特征。我特别注意到不同瑕疵的细微差异,以便为后续的训练算法提供丰富的信息。这一高质量的标注数据集将为模型的训练和评估提供可靠支持,确保分类算法的有效性和准确性。
2.2 数据增强
数据增强是提升苹果瑕疵识别分类算法性能的重要技术,通过随机旋转、缩放、翻转、裁剪、亮度和对比度调整、加噪声、颜色抖动以及模糊处理等方法,能够有效扩展和丰富数据集。这些增强技术不仅增加了样本的多样性,帮助模型学习不同视角和条件下的瑕疵特征,还增强了模型的泛化能力和鲁棒性,从而提高了在实际应用中的识别准确性。
相关代码示例:
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据增强的转换
data_transforms = transforms.Compose([
transforms.RandomRotation(degrees=15), # 随机旋转
transforms.RandomResizedCrop(size=224, scale=(0.8, 1.0)), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2), # 颜色抖动
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 加载数据集
train_dataset = datasets.ImageFolder(root='path/to/your/dataset/train', transform=data_transforms)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
# 示例用法
for images, labels in train_loader:
# 在这里可以添加模型训练的代码
print(images.shape, labels.shape)
break # 仅打印一次输出三、实验及结果分析
3.1 实验环境搭建
深度学习框架为构建、训练、优化和推理深度神经网络提供了必要的基础工具,使开发者能够更高效地进行相关工作。这些框架不仅简化了复杂的计算过程,还提供了丰富的功能和灵活的接口,帮助开发者快速实现各种深度学习算法。在众多深度学习框架中,PyTorch因其高度的扩展性和可移植性而受到广泛欢迎,尤其在学术研究和工业应用中表现出色。它的动态计算图特性使得模型的调试和修改变得更加直观和方便,同时,PyTorch拥有一个活跃的开发者社区,提供了大量的资源和支持,极大地推动了深度学习的研究和应用。

3.2 模型训练
模型训练的流程通常包括以下几个步骤:
-
数据准备:加载并预处理数据,包括数据增强和划分训练集、验证集和测试集。
-
定义模型:选择合适的模型架构,并根据任务需求进行配置。
-
设置损失函数和优化器:选择适合的损失函数和优化算法,以指导模型的学习过程。
-
训练模型:通过多轮迭代(epoch),在训练集上训练模型,并在验证集上评估其性能。
-
保存模型:在训练完成后,保存模型的参数,以便后续使用和推理。
-
评估模型:在测试集上评估模型的最终性能,检查其泛化能力。
代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision import models
# 定义模型
model = models.resnet50(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(train_dataset.classes)) # 修改输出层以匹配类别数量
# 设置损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss / len(train_loader):.4f}')
# 验证模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Validation Accuracy: {100 * correct / total:.2f}%')
最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

一站式 AI 云服务平台
更多推荐
 31
31 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)