
大语言模型---第五章 有监督微调
有监督微调(Supervised Finetuning SFT)指令微调(Instruction Tunning)是指在已经训练好的语言模型基础上,通过使用有标注的特定任务数据进行进一步的微调,从而使得模型具备遵循指令的能力大模型的提示学习,语境学习能力-->高效模型微调及大语言上下文窗口扩展方法-->指令数据的一般格式与构建方式和有监督微调的代码实践1)提示学习和语境学习提示学习(Prompt-
有监督微调(Supervised Finetuning SFT)指令微调(Instruction Tunning)是指在已经训练好的语言模型基础上,通过使用有标注的特定任务数据进行进一步的微调,从而使得模型具备遵循指令的能力
大模型的提示学习,语境学习能力-->高效模型微调及大语言上下文窗口扩展方法-->指令数据的一般格式与构建方式和有监督微调的代码实践
1)提示学习和语境学习
提示学习(Prompt-based Learning)不同于传统的监督学习,它直接利用了在大量原始文本上进
行预训练的语言模型,并通过定义一个新的提示函数,使得该模型能够执行小样本甚至零样本学
习,以适应仅有少量标注或没有标注数据的新场景。
流程 原始输入x-->模板-->带有一些未填充槽文本提示x‘提示添加-->语言模型-->概率答案搜索-->最终预测标签y’答案映射
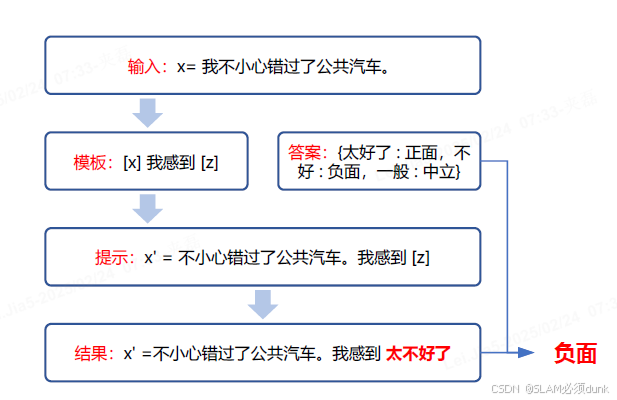
语境学习(Incontext Learning, ICL),也称上下文学习,是指模型可以从上下文中的几个例子中学习:向模型输入特定任务的一些具体例子(也称示例(Demonstration))以及要测试的样例,模型可以根据给定的示例续写出测试样例的答案。
语境学习优势:1自然语言编写,提供可解释性界面来与大语言模型进行交互,2)无需更新参数,降低使得大模型适应新的任务计算成本
2)高效模型微调
LoRA(Low-Rank Adaptation of Large Language Models)可以在缩减训练参数量和GPU显存占用同时,使训练后的模型具有与全量微调相当的性能。
基于参数更新量即便投影到较小的子空间中,也不会影响学习的有效性这个理论,提出规定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变量。

其他方法:
微调适配器(Adapter)-->分别对Transformer层中自注意力模块与多层感知(MLP)模块,在其与其之后的残差连接之间添加适配器层(Adapter layer)作为可训练参数,缺点,其变体会增加网络深度,从而在模型推理时带来额外的时间开销。
前缀微调(Prefix Tuning)-->在输入序列前缀添加连续可微的软件提示作为可训练参数,缺点,由于模型可接受的最大输入长度是有限的,随着软提示参数量增多,实际输入序列的最大长度也会相应减小,影响模型性能,这使得前缀微调的模型性能并非随着可训练参数量单调上升。
LoRA性能均相当且优于上述俩种方法:
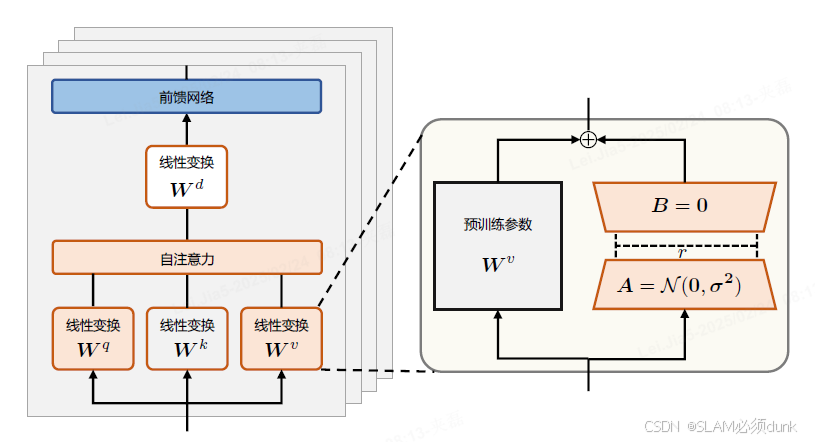
基于LoRA算法给所有的低秩矩阵指定了唯一的秩,从而忽略了不同模块、不同层的参数对于微调
特定任务的重要性差异,所以又提出了 AdaLoRA方式,即在微调过程中根据各权重矩阵对下游任务的重要性动态调整秩的大小,用以进一步减少可训练参数量的同时保持或提高性能。
为了达到降秩且最小化目标矩阵与原矩阵差异的目的,常用的方法是对原矩阵进行奇异值分
解并裁去较小的奇异值。
举例阐述上述内容:

QLoRA并没有对LoRA 的逻辑作出修改,而是通过将预训练模型量化为4-bit 以进一步节
省计算开销, QLoRA(Quantized Low-Rank Adaptation)是一种高效的模型微调方法,特别适合在资源有限的情况下对大型语言模型(LLM)进行微调。它结合了量化(Quantization)和低秩适应(LoRA,Low-Rank Adaptation)技术,通过量化模型参数和引入低秩矩阵来减少计算资源和内存的消耗,同时保持模型的性能。
QLoRA 的主要技术为:(1)新的数据类型4-bit NormalFloat(NF4);(2)双重量化(DoubleQuantization);(3)分页优化器(Paged Optimizers)。其中分页优化器指在训练过程中显存不足时自动将优化器状态移至内存,需要更新优化器状态时再加载回来。
QLoRA 的工作原理
QLoRA 的核心思想是通过量化和低秩适应来减少模型的内存占用和计算量。具体来说:
-
量化(Quantization):将模型参数从高精度(如 32 位浮点数)压缩到低精度(如 4 位或 8 位整数),从而显著减少模型的内存占用和计算量。
-
低秩适应(LoRA):在模型的某些层中引入低秩矩阵,通过训练这些低秩矩阵来调整模型的行为,而不是更新整个模型的参数。
3. 量化技术
量化技术是 QLoRA 的关键技术之一,它通过将模型参数从高精度压缩到低精度来减少内存需求。具体来说:
-
absmax(XFP32):这是浮点数张量中绝对值最大的元素,用来衡量数据的动态范围。
absmax是一种常用的缩放方法,通过取最大绝对值来估算数据的幅度。 -
分块 k 位量化:将张量分成 k 个块,每个块都有独立的量化常数,从而解决模型参数的极大极小值问题。这种方法不仅减少了核之间的通信,还可以实现更好的并行性,并充分利用硬件的多核能力。
假设我们有一个预训练的大型语言模型(如 LLaMA 或 T5),我们希望在资源有限的情况下对其进行微调。
-
量化模型:
-
将预训练模型的参数从 32 位浮点数量化为 4 位 NormalFloat (NF4)。例如,一个 13B 参数的模型,经过 4 位量化后,内存占用可以从几十 GB 降低到几 GB。
-
-
引入低秩适应(LoRA):
-
在模型的某些层中引入低秩矩阵 A 和 B,使得权重更新 ΔW=BA。通过训练这些低秩矩阵,而不是更新整个模型的参数,从而减少内存和计算资源的消耗。
-
-
微调模型:
-
使用 QLoRA 微调模型,只需训练低秩矩阵 A 和 B,而不是整个模型的参数。例如,使用 QLoRA 微调一个 65B 参数的模型,只需在单个 GPU 上进行 24 小时的训练,就能在 Vicuna 基准测试中优于所有之前公开发布的模型,达到 ChatGPT 性能水平的 99.3%。
-
3)模型上下文窗口扩展
a)增加上下文窗口的微调:采用直接的方式,即通过使用一个更长的上下文窗口来微调现有的预训练Transformer,以适应长文本建模需求
b)位置编码:改进的位置编码,如ALiBi、LeX等能够实现一定程度上的长度外推。这意味着它们可以在短的上下文窗口上进行训练,在长的上下文窗口上进行推理。
ALiBi并不在Embedding 层添加位置编码,而在Softmax 的结果后添加一个静态的不可学习的偏置项:
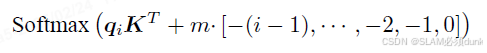
其中m 是对于不同注意力头设置的斜率值,对于n个注意头,斜率集是从2^(-8/n),
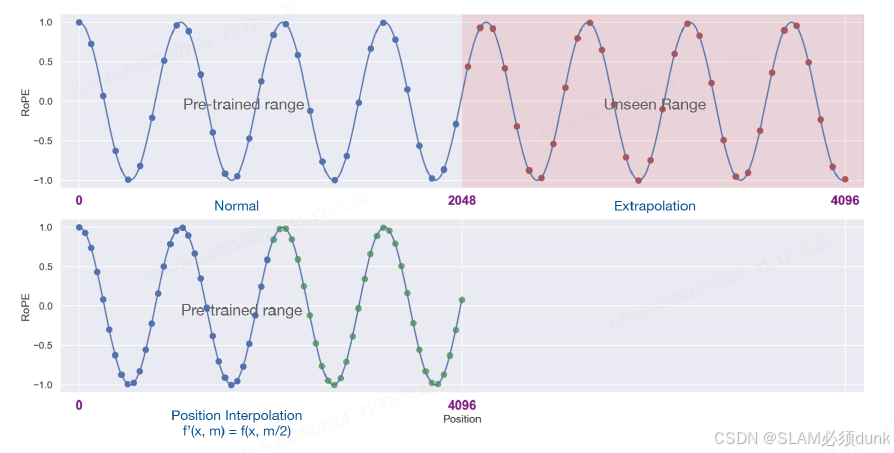
c)插值法:将超出上下文窗口的位置编码通过插值法压缩到预训练的上下文窗口中。
不同的预训练大语言模型使用了不同的位置编码,修改位置编码意味着重新训练,因此对于
已训练的模型,通过修改位置编码扩展上下文窗口大小的适用性仍然有限.
直接缩小位置索引,使最大位置索引与预训练阶段的上下文窗口限制相匹配.
4)指令数据构建
指令数据的质量会直接影响到有监督微调的最终效果,所以指令数据的构建应当是一个非常
精细的过程。从获得来源上来看,构建指令数据的方法可以分为手动构建指令和利用大模型的生
成能力自动构建指令两种。
指令数据的质量和多样性通常被认为是衡量指令数据的俩个重要维度。
Self-instruct 数据生成过程是一个迭代引导算法,
生成任务指令-->确定指令是否代表分类任务-->生成任务输入和输出-->过滤低质量数据
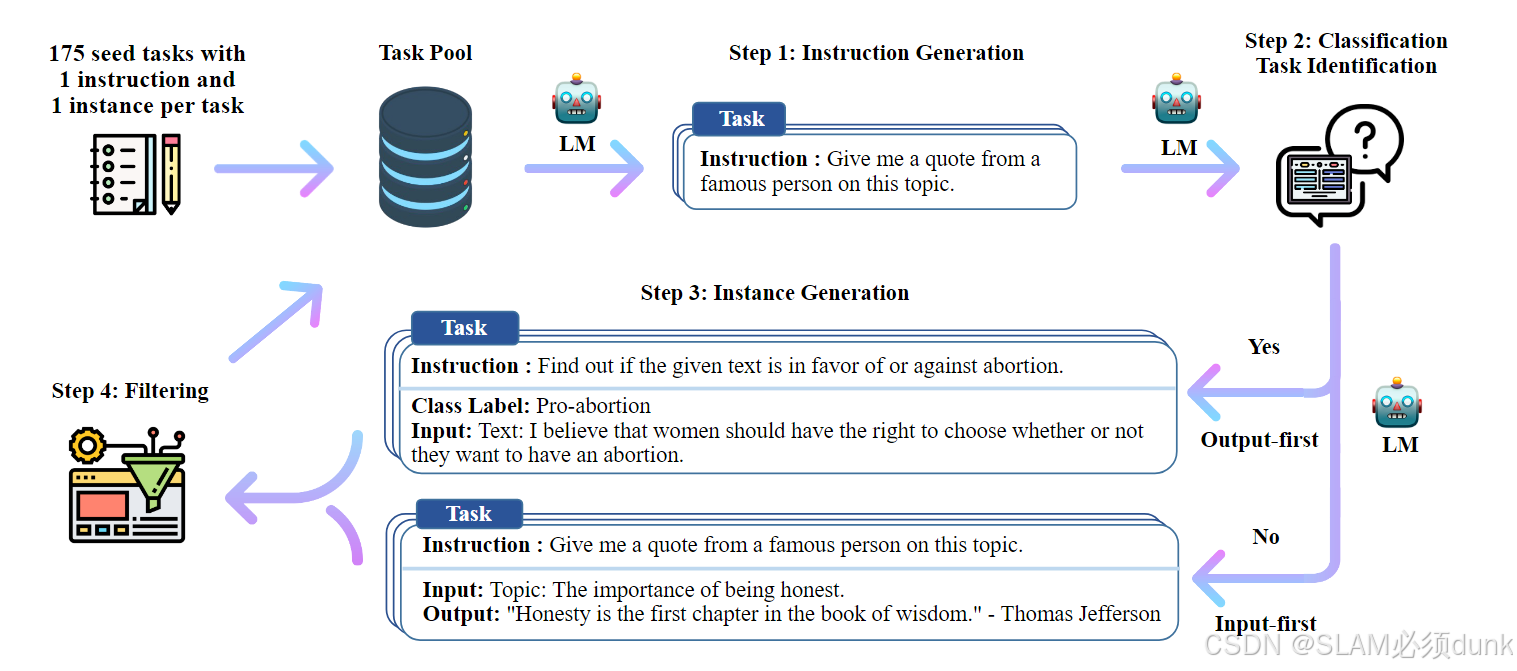
开源指令数据集 按照指令任务的类型划分,可以分为传统NLP 任务指令和通用对话指令两类
5)DeepSeed-Chat SFT 实践
包含3个步骤,1)监督微调(SFT),2)奖励模型微调(RW),3)RLHF训练,利用ProximalPolicyOptimization(PPO)算法,根据RW模型的奖励反馈进一步微调SFT模型
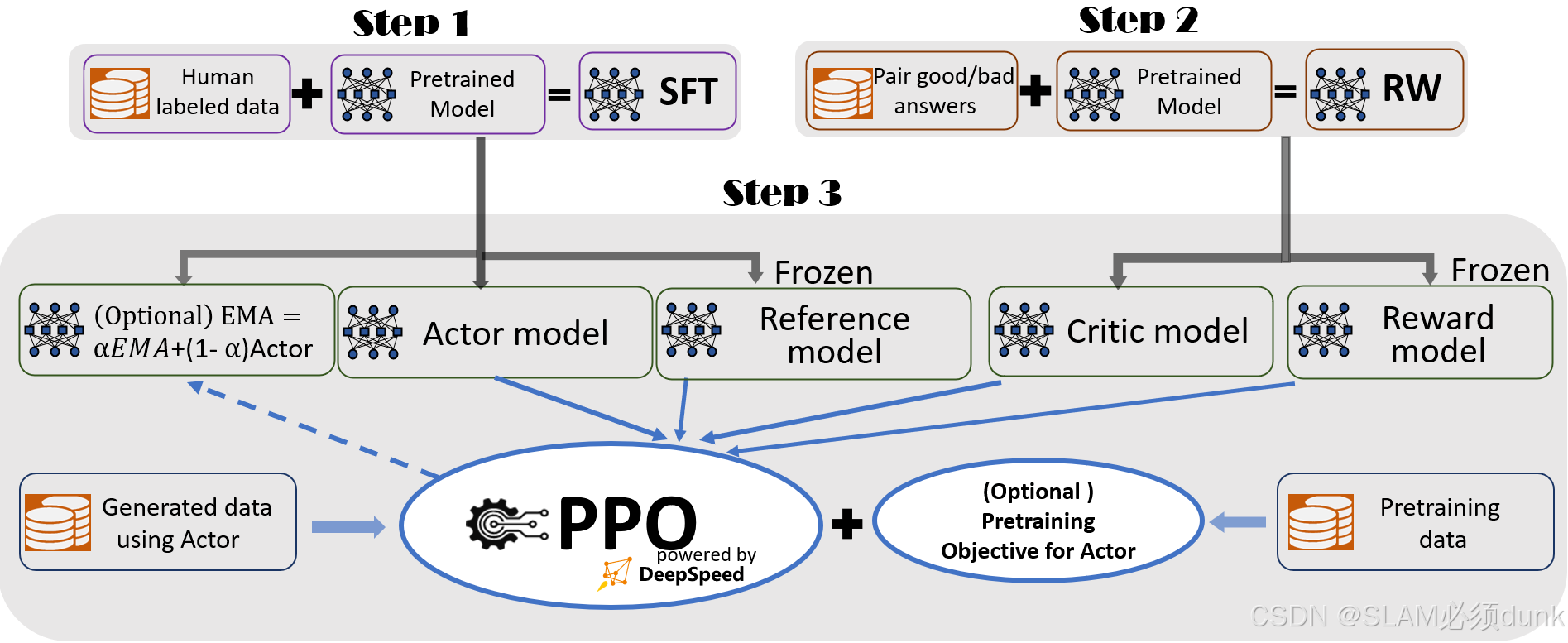
一个基于强化学习(Reinforcement Learning, RL)的模型训练流程,特别是使用了近端策略优化(Proximal Policy Optimization, PPO)算法。一个基于强化学习的模型训练流程,结合了监督式微调和奖励加权,使用 PPO 算法进行训练。通过生成数据和奖励模型的反馈,不断优化行动者模型,使其在特定任务上表现更好。
Step 1: Supervised Fine-Tuning (SFT)
-
Human labeled data:人类标注的数据,通常用于监督学习。
-
Pretrained Model:预训练模型,通常是在大规模数据上预训练的模型。
-
SFT:监督式微调(Supervised Fine-Tuning),将人类标注的数据和预训练模型结合,进行微调。
Step 2: Reward Weighting (RW)
-
Pair good/bad answers:成对的好/坏答案,用于训练奖励模型。
-
Pretrained Model:预训练模型。
-
RW:奖励加权(Reward Weighting),通过成对的好/坏答案和预训练模型,生成奖励模型。
Step 3: PPO Training
-
Actor Model:行动者模型,用于生成动作(如生成文本)。
-
Reference Model:参考模型,用于提供参考输出。
-
Critic Model:评论家模型,用于评估行动者模型的输出。
-
Reward Model:奖励模型,用于计算奖励值。
-
PPO:近端策略优化算法,用于训练行动者模型。
-
Generated data using Actor:使用行动者模型生成的数据。
-
Pretraining data:预训练数据,用于预训练行动者模型


a)数据预处理
-
SFT:使用
prompt和chosen进行监督式微调,训练模型生成高质量的响应。 -
RM:使用
prompt、chosen和rejected进行奖励模型的微调,训练模型区分高质量和低质量的响应。
典型的样本格式:
| prompt | chosen | rejected |
|---|---|---|
| 人口最多的国家 | 中国是人口最多的国家。 | 美国是人口最多的国家。 |

b)自定义模型
需要注意模型路径,tokenizer ,数据路径,
c)模型训练
当训练开始进行时,会进行一次评估计算出困惑度ppl(Perplexity)。然后开始进行训练,在
每一个epoch 结束后都会进行一次评估,ppl 也会随着训练的进行逐步下降
d)模型推理

一站式 AI 云服务平台
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)